
注意: tf.debugging.experimental.enable_dump_debug_info() は実験的 API であるため、将来的に重要な変更が適用される場合があります。
TensorFlow プログラムでは NaN を伴う壊滅的なイベントによって、モデルのトレーニングプロセスが難化してしまうことが度々あります。こういったイベントの根源は、特に一般的でないサイズや複雑のモデルにおいてははっきりしないことが多々あります。この種のモデルの不具合をより簡単にデバッグするために、TensorBoard 2.3+(TensorFlow 2.3+ と併用)には Debugger V2 という特殊なダッシュボードが提供されています。ここでは、TensorFlow で記述されたニューラルネットワークにおける NaN を伴う実際のバグに対応しながら、このツールの使用方法を実演します。
このチュートリアルで説明する手法は、複雑なプログラムにおけるランタイムテンソル形状の検査といった、ほかの種類のデバッグ作業にも適用できます。このチュートリアルでは、比較的に多く発生する NaN の事象に焦点を当てています。
バグを観察する
TF2 プログラムのソースコードは GitHub で入手可能です。サンプルプログラムは tensorflow pip package(バージョン 2.3+)にもパッケージ化されており、次のようにして呼び出すことができます。
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2
この TF2 プログラムは多層パーセプトロン(MLP)を作成し、MNIST 画像を認識できるようにトレーニングします。この例では、カスタムレイヤー構造、損失関数、およびトレーニングループの定義に、意図的にTF2 の低レベル API を使用しています。tf.keras のように、使いやすくとも柔軟性にやや劣る API を使用するより、柔軟性がより高くてもエラーを生じやすいこの API を使う方が、NaN バグの確率が高くなるためです。
このプログラムは、トレーニングステップの終了ごとにテスト精度を出力します。最初のステップが終了した後に偶然に近いレベル(~0.1)でテスト精度が停滞する様子をコンソールで確認できます。これは、モデルのトレーニングに期待される動作ではまったくありません。ステップが増加するたびに徐々に 1.0(100%)に精度が近づいていく必要があります。
Accuracy at step 0: 0.216
Accuracy at step 1: 0.098
Accuracy at step 2: 0.098
Accuracy at step 3: 0.098
...
経験に基けば、この問題は NaN や無限大などの数値的不安定性に生じるものであることが推測されますが、これを証明するには、また数値的不安定性を生成している TensorFlow 演算(op
)を特定するには、どうすればよいのでしょうか。この疑問に
答えるために、Debugger V2 を使って不具合のあるプログラムを調べてみましょう。
TensorFlow コードに Debugger V2 を計装する
tf.debugging.experimental.enable_dump_debug_info() は Debugger V2 の API エントリポイントです。TF2 プログラムに 1 行のコードを計装します。たとえば、プログラムの先頭近くに以下に示す行を追加すると、ログディレクトリ(logdir)である /tmp/tfdbg2_logdir にデバッグ情報が書き出されます。デバッグ情報には、TensorFlow ランタイムに関するさまざまな側面が含まれます。TF2 では、Eager execution、@tf.function によるグラフの構築、グラフの実行、実行イベントによって生成されたテンソル値、そしてイベントのコードの位置(Python スタックトレース)の完全な履歴が含まれます。デバッグ情報が非常に豊富であるため、不明瞭なバグの原因を絞り込むことができます。
tf.debugging.experimental.enable_dump_debug_info(
"/tmp/tfdbg2_logdir",
tensor_debug_mode="FULL_HEALTH",
circular_buffer_size=-1)
tensor_debug_mode 引数は、Debugger V2 が各 Eager またはグラフ内のテンソルから抽出する情報を管理します。「FULL_HEALTH」は、各浮動小数点型テンソル(一般的によく見られる float32 やそれほど一般的でない bfloat16 dtype など)に関する次の情報をキャプチャするモードです。
- DType
- 階数
- 要素の総数
- 浮動小数点型要素の内訳: 負の有限(
-)、ゼロ(0)、正の有限(+)、負の無限大(-∞)、正の無限大(+∞)、NaN
「FULL_HEALTH」モードは、NaN と無限大が伴うバグのデバッグに最適なモードです。以下に、その他のサポートされている tensor_debug_mode を紹介します。
circular_buffer_size 引数は、logdir に保存されるテンソルイベント数を管理します。デフォルトは 1000 で、計装された TF2 プログラムが終了する前の最後の 1000 テンソルのみがディスクに保存されます。このため、デバッグデータの完全性が損なわれるため、デバッガのオーバーヘッドが緩和されるように設計されています。この例のように完全性を優先する場合は、この引数を負の値(この例では -1)に設定することで、循環バッファを無効にすることができます。
debug_mnist_v2 の例では、コマンドラインフラグを渡して enable_dump_debug_info() を呼び出します。デバッグ計装を有効にして、問題のある TF2 プログラムをもう一度実行するには、次のように行います。
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2 \
--dump_dir /tmp/tfdbg2_logdir --dump_tensor_debug_mode FULL_HEALTH
TensorBoard で Debugger V2 GUI を起動する
デバッガを計装してプログラムを実行すると、/tmp/tfdbg2_logdir に logdir が作成されます。TensorBoard を起動してこの logdir にポイントするには、次のように行います。
tensorboard --logdir /tmp/tfdbg2_logdir
ウェブブラウザで、http://localhost:6006 にある TensorBoard のページに移動します。「Debugger V2」プラグインはデフォルトで無効化されているため、右上の「無効化されているプラグイン」メニューから選択します。次のようなページが表示されます。
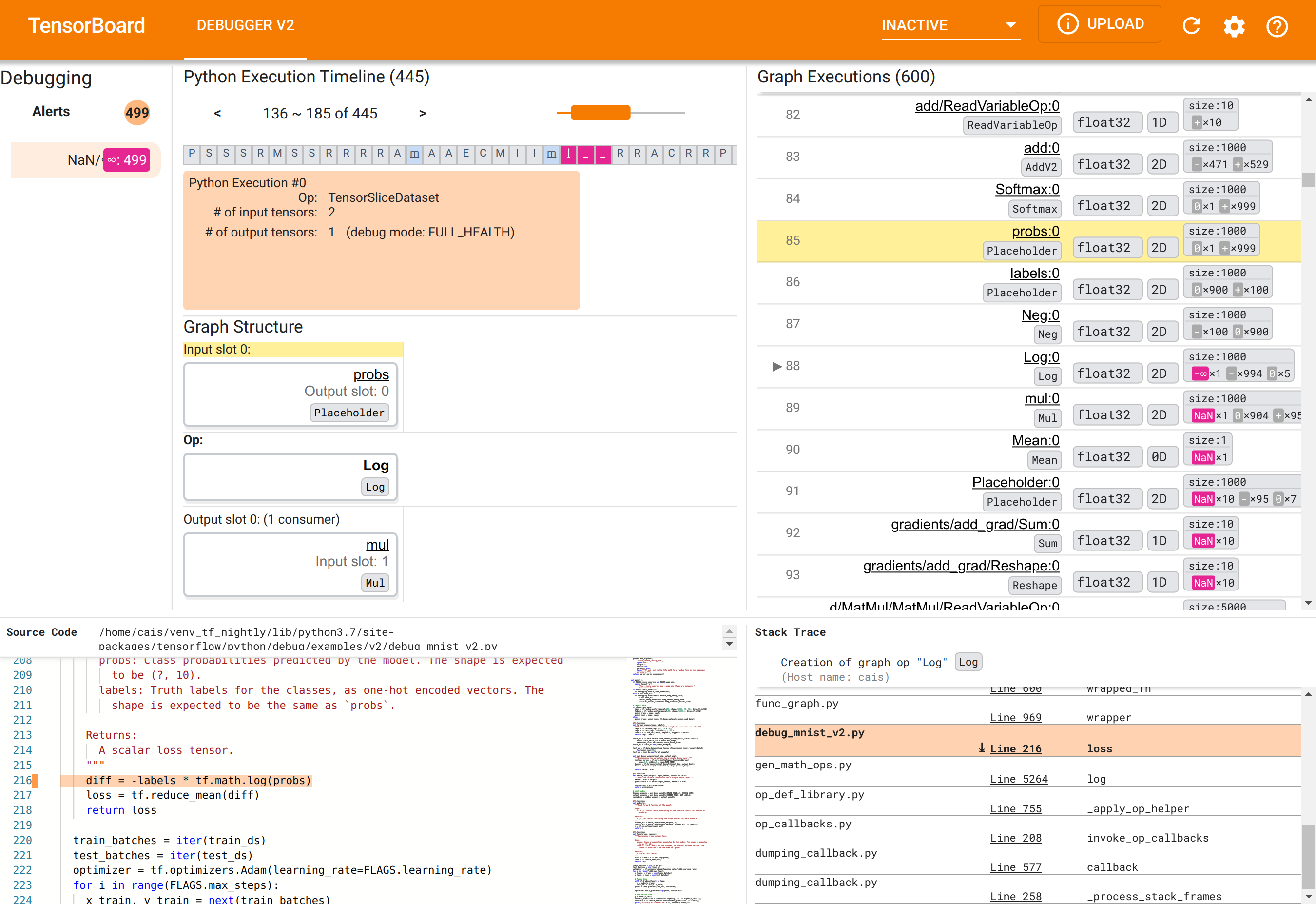
Debugger V2 を使用して、NaN の根源を特定する
TensorBoard の Debugger V2 GUI は、次の 6 つのセクションで編成されています。
- Alerts: 左上にある警告セクションには、計装された TensorFlow プログラムのデバッグデータのうち、デバッガが検出した「警告」イベントのリストが表示されます。各警告は、注意を必要とする特定の異常を示します。この例では、このセクションには 499 個の NaN/∞ イベントが鮮やかな赤ピンク色で表示されています。つまり、内部テンソル値に存在する NaN や無限大により、モデルが学習できないという疑念が確定されたことになります。この警告については、しばらくしてから詳しく見ることにします。
- Python Execution Timeline: 上中央セクションの上半分にあるのは Python 実行タイムラインのセクションです。ここには、演算とグラフの Eager execution の全履歴が示されます。タイムラインの各ボックスは、演算またはグラフ名の頭文字で見分けられるようになっています(「TensorSliceDataset」演算の場合は「T」、「model」
tf.functionの場合は「m」など)。このタイムラインのナビゲーションは、タイムラインの上にあるナビゲーションボタンとスクロールバーを使用します。 - Graph Execution : GUI の右上にあるグラフ実行セクションは、デバッグタスクの主役です。グラフ内で計算されたすべての浮動小数点 dtype テンソルの履歴が表示されます。
- Graph Structure(上中央の下半分にあるグラフ構造セクション)、Source Code(左下にあるソースコードセクション)、および Stack Trace(右下にあるスタックトレースセクション)は、最初は空の状態になっています。このコンテンツは、GUI を操作すると表示されるようになります。これら 3 つのセクションにもデバッグタスクの重要な役割があります。
UI の編成について理解したところで、次の手順により、NaN が出現した理由を調べることにしましょう。まず、Alerts セクションの NaN/∞ 警告をクリックします。すると、Graph Execution セクションにある 600 個のグラフテンソルのリストが自動的にスクロールし、88 番がフォーカスされます。これは、「Log:0」という、Log(自然対数)演算によって生成されたテンソルです。2D float32 テンソルの 1000 個の要素のうち、-∞ 要素が鮮やかな赤ピンク色で示されていますが、これが NaN または無限大を含んでいた TF2 プログラムのランタイム履歴の中でも最初のテンソルです。この前に計算されたテンソルには、NaN または ∞ は含まれていませんが、これ以降に計算された多くの(実にほとんどの)テンソルには NaN が含まれています。これは、Graph Execution リストを上下にスクロールすれば確認できます。このように観察することで、Log 演算が TF2 プログラムの数値的不安定性の原因であるという強力なヒントを得ることができます。
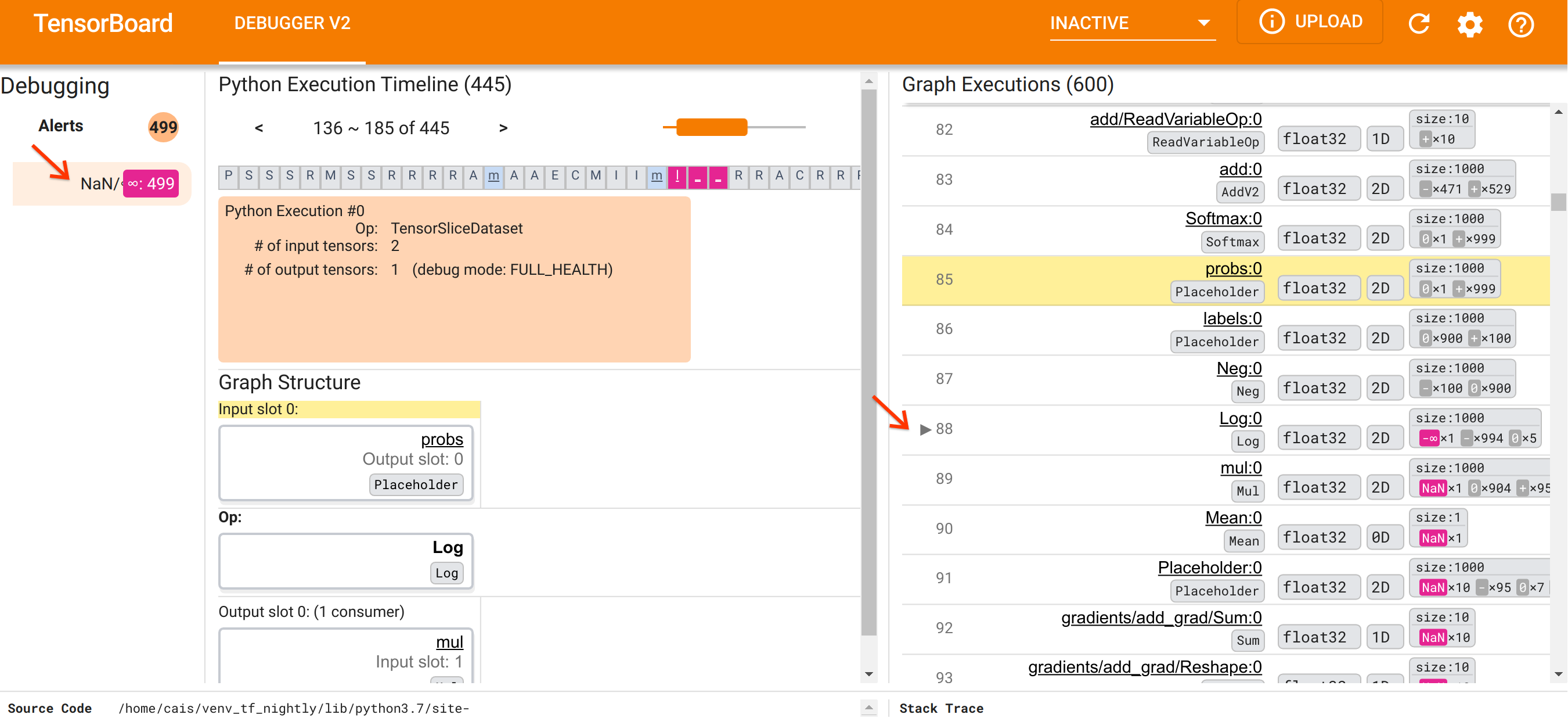
では、この Log 演算はなぜ -∞ を算出しているのでしょうか。この疑問に答えるには、演算への入力を調べる必要があります。テンソルの名前(Log:0)をクリックすると、Graph Structure セクションに、単純でありながら有益な、TensorFlow グラフの Log 演算周りの視覚化が表示されます。情報の流れの上から下の方向であることに注意してください。演算自体は中央に太字で示されています。そのすぐ上には、プレースホルダー演算が Log 演算に唯一の入力を提供していることがわかります。この probs プレースホルダが生成したテンソルは Graph Execution リストのどこにあるのでしょうか。視覚的な支援として黄色い背景色を使用すると、probs:0 テンソルが Log:0 テンソルの 2 行上、つまり行 85 にあることがわかります。

行 85 の probs:0 テンソルの数値内訳をもっと注意して見てみると、それを消費する Log:0 が -∞ を生成している理由がわかります。probs:0 の 1000 個の要素のうち、1 つの要素に 0 の値があります。-∞ は自然対数 0 を計算した結果なのです! Log 演算が正の入力のみに公開されることを何らかの方法で確保すれば、NaN/∞ が起こらないようにすることができるでしょう。これは、プレースホルダー probs のテンソルでクリッピングを適用( tf.clip_by_value() を使用)して、達成できます。
バグの解決には近づいていますが、まだまだです。修正を適用するには、Python ソースコードで、Log 演算とプレースホルダ入力が発生した場所を知る必要があります。Debugger V2 には、グラフ演算と実行イベントをその源までトレースするための優れたサポートが提供されています。Graph Execution で Log:0 テンソルをクリックすると、Stack Trace セクションに Log 演算の作成の元のスタックトレースが表示されます。このスタックトレースには TensorFlow の内部コード(gen_math_ops.py や dumping_callback.py など)からの多くのフレームが含まれるため、ある程度大きくなりますが、これらのフレームの多くはデバッグタスクで無視できるものです。関心のあるフレームは、debug_mnist_v2.py(デバッグしようとしている Python ファイル)の行 216 です。「Line 204」をクリックすると、Source Code セクションに、対応するコード行のビューが表示されます。
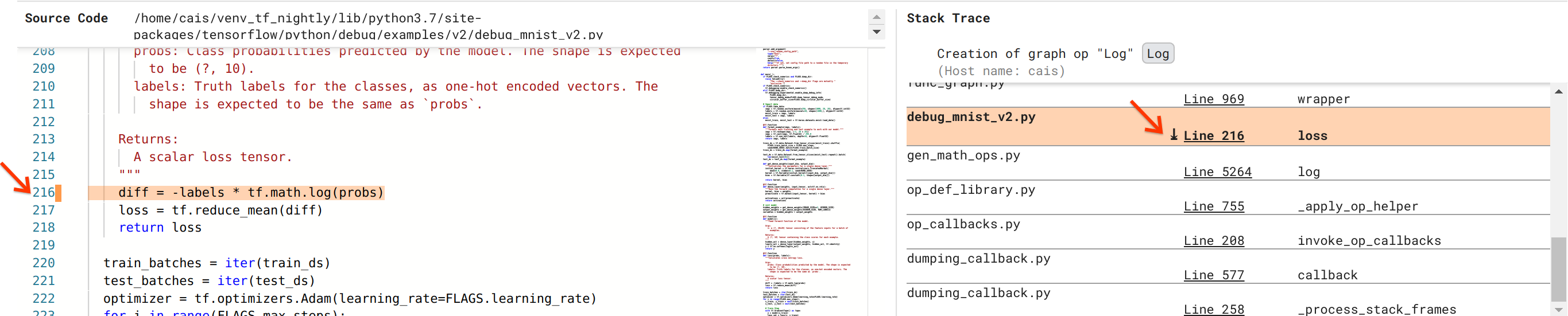
これでようやく、probs入力から問題のある Log 演算を作成したソースコードにたどり着けます。これは、@tf.function でデコレートされた、つまり TensorFlow グラフに変換されたカスタムカテゴリのクロスエントロピー損失関数です。プレースホルダ演算の probs は、損失関数の最初の入力引数に対応します。Log 演算は、tf.math.log() API 呼び出しで作成されています。
値をクリッピングする、このバグの修正は次のようになります。
diff = -(labels *
tf.math.log(tf.clip_by_value(probs), 1e-6, 1.))
これで、TF2 の数値的不安定性が解決し、MLP のトレーニングが成功するようになります。数値的不安定性の修正アプローチとして、もう 1 つ、tf.keras.losses.CategoricalCrossentropy を使用する方法があります。
これで、Debugger V2 ツールを利用した、TF2 モデルのバグの観察からバグを修正するコードチェンジの特定までの道のりは終了です。このツールによって、計装された TF2 プログラムの Eager とグラフ実行に関する、テンソル値の数値要約や、演算とテンソル、および元のソースコード間の関連性などの完全な可視性を得ることができました。
Debugger V2 のハードウェア互換性
Debugger V2 は、CPU と GPU を含む、メインストリームのトレーニングハードウェアをサポートしています。tf.distributed.MirroredStrategy によるマルチ GPU トレーニングもサポートされています。TPU のサポートについては、まだ早期段階にあり、次のコード
tf.config.set_soft_device_placement(True)
を enable_dump_debug_info() を呼び出す前に呼び出す必要があります。TPU にはほかの制限もある可能性があります。Debugger V2 を使用中に問題に総具した場合は、GitHub 課題ページにバグを報告してください。
Debugger V2 の API 互換性
Debugger V2 は、TensorFlow のソフトウェアスタックでは比較的に低レベルに実装されているため、tf.keras、tf.data、および TensorFlow の低レベルの上に構築された API との互換性があります。また、TF1 との下位互換性も有していますが、Eager Execution Timeline は、TF1 プログラムによって生成されるデバッグの logdir が空になります。
API の使用に関するヒント
このデバッグ API に関してよく尋ねられる質問は、TensorFlow コードのどこに、enable_dump_debug_info() への呼び出しを挿入すべきか、ということです。通常、API は、TF2 プログラムのできるだけ先頭近くに、できれば Python インポート行とグラフの構築と実行の開始の間に呼び出す必要があります。こうすると、モデルとトレーニングを機能させるすべての演算とグラフを完全に網羅することができます。
現在サポートされている tensor_debug_modes は、NO_TENSOR、CURT_HEALTH、CONCISE_HEALTH、FULL_HEALTH、および SHAPE です。各テンソルから抽出されえる情報量やデバッグ対象のプログラムへのパフォーマンスのオーバーヘッド量は、モードによって異なります。詳細は、enable_dump_debug_info() のドキュメントの引数セクションをご覧ください。
パフォーマンスオーバーヘッド
デバッグ API では、計装された TensorFlow プログラムにパフォーマンスオーバーヘッドが生じます。個のオーバーヘッドは、tensor_debug_mode、ハードウェアの種類、および計装された TensorFlow プログラムの性質によって異なりますが、基準としては、GPU では NO_TENSOR モードの場合、バッチサイズ 64 の変換モデルのトレーニング中に、15% のオーバーヘッドが追加されます。ほかの tensor_debug_mode の場合のオーバーヘッドの割合は高くなる傾向にあり、CURT_HEALTH、CONCISE_HEALTH、FULL_HEALTH、および SHAPE モードでは約 50% 増となります。CPU ではやや低くなる傾向にあり、TPU では現時点では高くなる傾向にあります。
ほかの TensorFlow デバッグ API との関係
TensorFlow には、デバッグ用のほかのツールや API があり、API ドキュメントページの tf.debugging.* 名前空間で参照することができます。これらの API の中でも最も頻繁に使用されるのは tf.print() です。いつ Debugger V2 を使用し、いつ tf.print() を使用するのでしょうか。tf.print() は次のような場合に便利です。
- 出力するテンソルが明確に分かっている場合
tf.print()ステートメントを挿入するソースコードの箇所を明確に分かっている場合- そのようなテンソルの数が大きすぎない場合
ほかの場合(多数のテンソル値を調べる、TensorFlow の内部コードによって生成されたテンソル値を調べる、上記で示したように数値的不安定性の出所を突き止めるといった場合)には、Debugger V2 の方がデバッグを素早く実施できます。さらに、Debugger V2 では Eager とグラフテンソルの検査に使用するアプローチが統一されているだけでなく、tf.print() ではその機能外となるグラフ構造やコードの位置に関する情報も提供することができます
∞ と NaN を伴う問題をデバッグする上で使用できるもう 1 つの API に tf.debugging.enable_check_numerics() があります。enable_dump_debug_info() とは異なり、enable_check_numerics() はデバッグ情報をディスクに保存せず、TensorFlow ランタイム中に ∞ と NaN を監視することしか行いません。また、演算がそういった不正な数値を生成すると、元のコードでエラーも発行します。enable_dump_debug_info() に比べればパフォーマンスオーバーヘッドは低くなりますが、プログラムの実行履歴を完全にトレースすることはできません。また、Debugger V2 のようなグラフィカルユーザーインターフェースも提供されていません。