
| |
|
 GitHub でソースを表示 GitHub でソースを表示 |
機械学習では、何かを改善するには、それを測定できる必要があります。TensorBoard は機械学習ワークフローの際に必要な測定値と視覚化を提供するツールです。損失や精度などの実験メトリックのトラッキング、モデルグラフの視覚化、低次元空間への埋め込みの投影など、さまざまなことを行えます。
このクイックスタートでは、TensorBoard を素早く使用し始める方法を示します。このウェブサイトの他のガイドでは、ここには含まれていない具体的な機能について、より詳しく説明します。
# Load the TensorBoard notebook extension
%load_ext tensorboard
import tensorflow as tf
import datetime
# Clear any logs from previous runsrm -rf ./logs/
MNIST データセットを例として使用しながら、データを正規化し、画像を 10 個のクラスに分類する単純な Keras モデルを作成する関数を記述します。
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
def create_model():
return tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28), name='layers_flatten'),
tf.keras.layers.Dense(512, activation='relu', name='layers_dense'),
tf.keras.layers.Dropout(0.2, name='layers_dropout'),
tf.keras.layers.Dense(10, activation='softmax', name='layers_dense_2')
])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] - 0s 0us/step
Keras Model.fit() で TensorBoard を使用する
Keras の Model.fit() を使用すると、tf.keras.callbacks.TensorBoard コールバックによってログが作成され、保存されたこと保証できます。さらに、histogram_freq=1(デフォルトでは無効)でエポックごとにヒストグラム計算を行えます。
トレーニング実行を簡単に選択できるように、ログをタイムスタンプ付きのサブディレクトリに配置しましょう。
model = create_model()
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
log_dir = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
model.fit(x=x_train,
y=y_train,
epochs=5,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback])
Train on 60000 samples, validate on 10000 samples Epoch 1/5 60000/60000 [==============================] - 15s 246us/sample - loss: 0.2217 - accuracy: 0.9343 - val_loss: 0.1019 - val_accuracy: 0.9685 Epoch 2/5 60000/60000 [==============================] - 14s 229us/sample - loss: 0.0975 - accuracy: 0.9698 - val_loss: 0.0787 - val_accuracy: 0.9758 Epoch 3/5 60000/60000 [==============================] - 14s 231us/sample - loss: 0.0718 - accuracy: 0.9771 - val_loss: 0.0698 - val_accuracy: 0.9781 Epoch 4/5 60000/60000 [==============================] - 14s 227us/sample - loss: 0.0540 - accuracy: 0.9820 - val_loss: 0.0685 - val_accuracy: 0.9795 Epoch 5/5 60000/60000 [==============================] - 14s 228us/sample - loss: 0.0433 - accuracy: 0.9862 - val_loss: 0.0623 - val_accuracy: 0.9823 <tensorflow.python.keras.callbacks.History at 0x7fc8a5ee02e8>
コマンドラインから、またはノートブックエクスペリエンス内で TensorBoard を起動します。2 つのインターフェースはほぼ同じです。ノートブックでは、%tensorboard ラインマジックを使用しますが、コマンドラインでは同じコマンドを「%」をつけずに実行します。
%tensorboard --logdir logs/fit
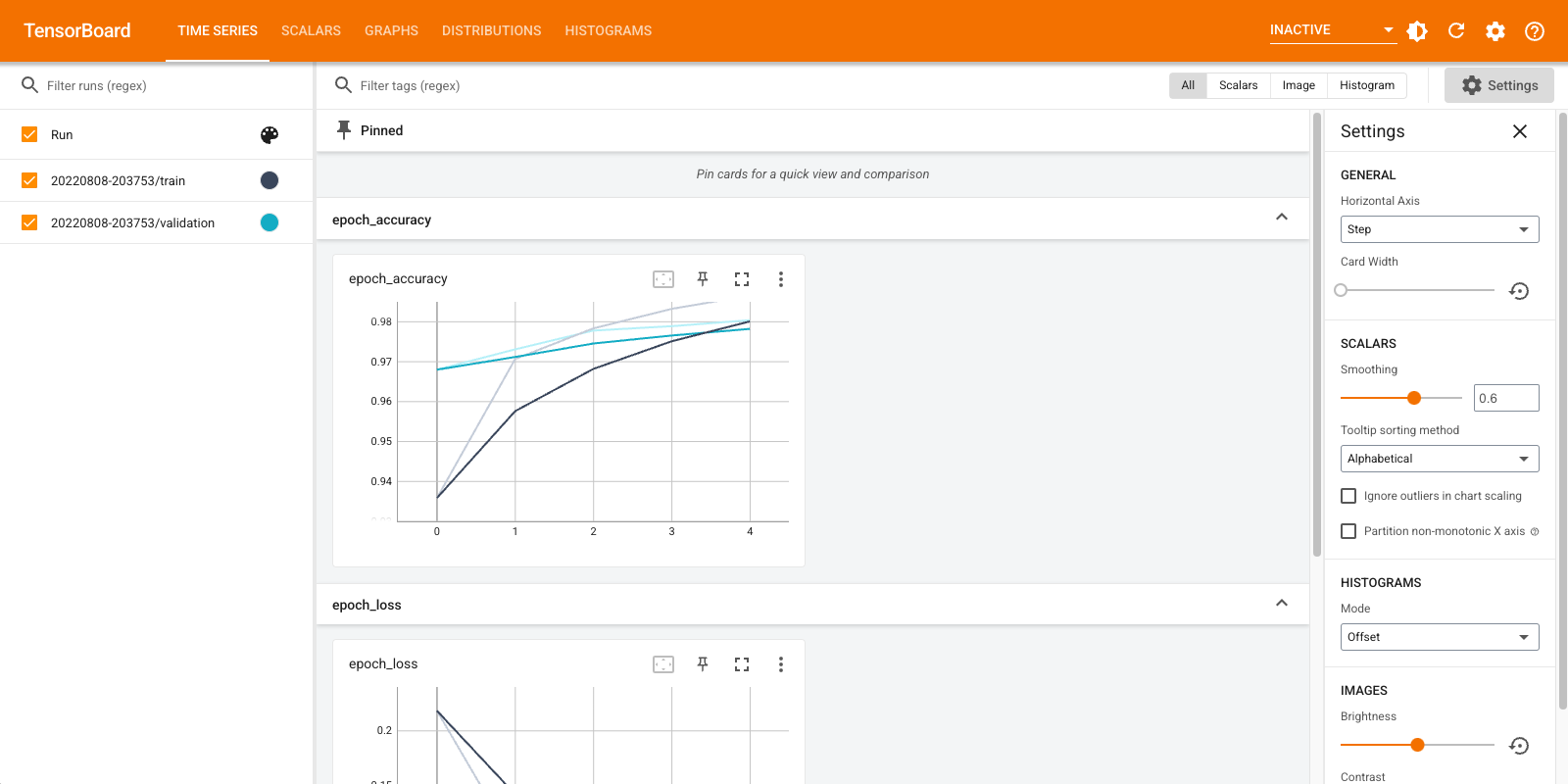
以下に、この例で作成される可視化の簡単な説明と、それが表示されるダッシュボード(トップナビゲーションバーのタブ)を示します。
- Scalars には、エポックごとの損失とメトリックの変化が示されます。これを使用して、トレーニング速度、学習率、およびその他のスカラー値をトラッキングすることもできます。Scalars は Time Series または Scalars ダッシュボードに表示されます。
- Graphs では、モデルを可視化できます。このケースではレイヤーの Keras グラフが示されており、正しく構築されていることが確認しやすくなります。Graphs は Graphs ダッシュボードに表示されます。
- Histograms と Distributions には、経時的なテンソルの分布が示されます。これは、重みとバイアスを可視化子、期待されるとおりに変化しているかを確認する上で役立ちます。Histograms は Time Series または Histograms ダッシュボードに表示されます。Distributions は Distributions ダッシュボードに表示されます。
ほかの種類のデータをログ記録すると、追加の TensorBoard ダッシュボードが自動的に有効化されます。たとえば、Keras TensorBoard コールバックの場合は、画像と埋め込みもログ記録することができます。TensorBoard で利用できるほかのダッシュボードを確認するには、右上の方にある「inactive」ドロップダウンをクリックしてください。
ほかのメソッドで TensorBoard を使用する
tf.GradientTape() などのメソッドでトレーニングする場合に必要な情報をログ記録するには、tf.summary を使用します。
上記と同じデータセットを使用しますが、tf.data.Dataset に変換して、バッチ機能を利用しましょう。
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
train_dataset = train_dataset.shuffle(60000).batch(64)
test_dataset = test_dataset.batch(64)
トレーニングコードは高度なクイックスタートチュートリアルの内容に従いますが、メトリックを TensorBoard にログ記録する方法が示されています。損失とオプティマイザを選択してください。
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()
トレーニング中の値を蓄積するために使用し、任意の時点でログ記録できるステートフルメトリックを作成します。
# Define our metrics
train_loss = tf.keras.metrics.Mean('train_loss', dtype=tf.float32)
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('train_accuracy')
test_loss = tf.keras.metrics.Mean('test_loss', dtype=tf.float32)
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('test_accuracy')
トレーニングとテストの関数を定義します。
def train_step(model, optimizer, x_train, y_train):
with tf.GradientTape() as tape:
predictions = model(x_train, training=True)
loss = loss_object(y_train, predictions)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
train_loss(loss)
train_accuracy(y_train, predictions)
def test_step(model, x_test, y_test):
predictions = model(x_test)
loss = loss_object(y_test, predictions)
test_loss(loss)
test_accuracy(y_test, predictions)
logs ディレクトリに要約をディスクに書き込むためのサマリーライターをセットアップします。
current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
train_log_dir = 'logs/gradient_tape/' + current_time + '/train'
test_log_dir = 'logs/gradient_tape/' + current_time + '/test'
train_summary_writer = tf.summary.create_file_writer(train_log_dir)
test_summary_writer = tf.summary.create_file_writer(test_log_dir)
トレーニングを開始します。サマリーライターがディスクに要約を書き込めるように、tf.summary.scalar() を使用して、トレーニング/テスト中のメトリック(損失と精度)をログします。ログするメトリックとその頻度は、ユーザーが制御します。ほかの tf.summary 関数は、ほかの種類のデータのログに使用されます。
model = create_model() # reset our model
EPOCHS = 5
for epoch in range(EPOCHS):
for (x_train, y_train) in train_dataset:
train_step(model, optimizer, x_train, y_train)
with train_summary_writer.as_default():
tf.summary.scalar('loss', train_loss.result(), step=epoch)
tf.summary.scalar('accuracy', train_accuracy.result(), step=epoch)
for (x_test, y_test) in test_dataset:
test_step(model, x_test, y_test)
with test_summary_writer.as_default():
tf.summary.scalar('loss', test_loss.result(), step=epoch)
tf.summary.scalar('accuracy', test_accuracy.result(), step=epoch)
template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'
print (template.format(epoch+1,
train_loss.result(),
train_accuracy.result()*100,
test_loss.result(),
test_accuracy.result()*100))
# Reset metrics every epoch
train_loss.reset_states()
test_loss.reset_states()
train_accuracy.reset_states()
test_accuracy.reset_states()
Epoch 1, Loss: 0.24321186542510986, Accuracy: 92.84333801269531, Test Loss: 0.13006582856178284, Test Accuracy: 95.9000015258789 Epoch 2, Loss: 0.10446818172931671, Accuracy: 96.84833526611328, Test Loss: 0.08867532759904861, Test Accuracy: 97.1199951171875 Epoch 3, Loss: 0.07096975296735764, Accuracy: 97.80166625976562, Test Loss: 0.07875105738639832, Test Accuracy: 97.48999786376953 Epoch 4, Loss: 0.05380449816584587, Accuracy: 98.34166717529297, Test Loss: 0.07712937891483307, Test Accuracy: 97.56999969482422 Epoch 5, Loss: 0.041443776339292526, Accuracy: 98.71833038330078, Test Loss: 0.07514958828687668, Test Accuracy: 97.5
TensorBoard をもう一度開き、新しいログディレクトリにポイントします。また、TensorBoard を起動してトレーニングの経過を監視することもできます。
%tensorboard --logdir logs/gradient_tape
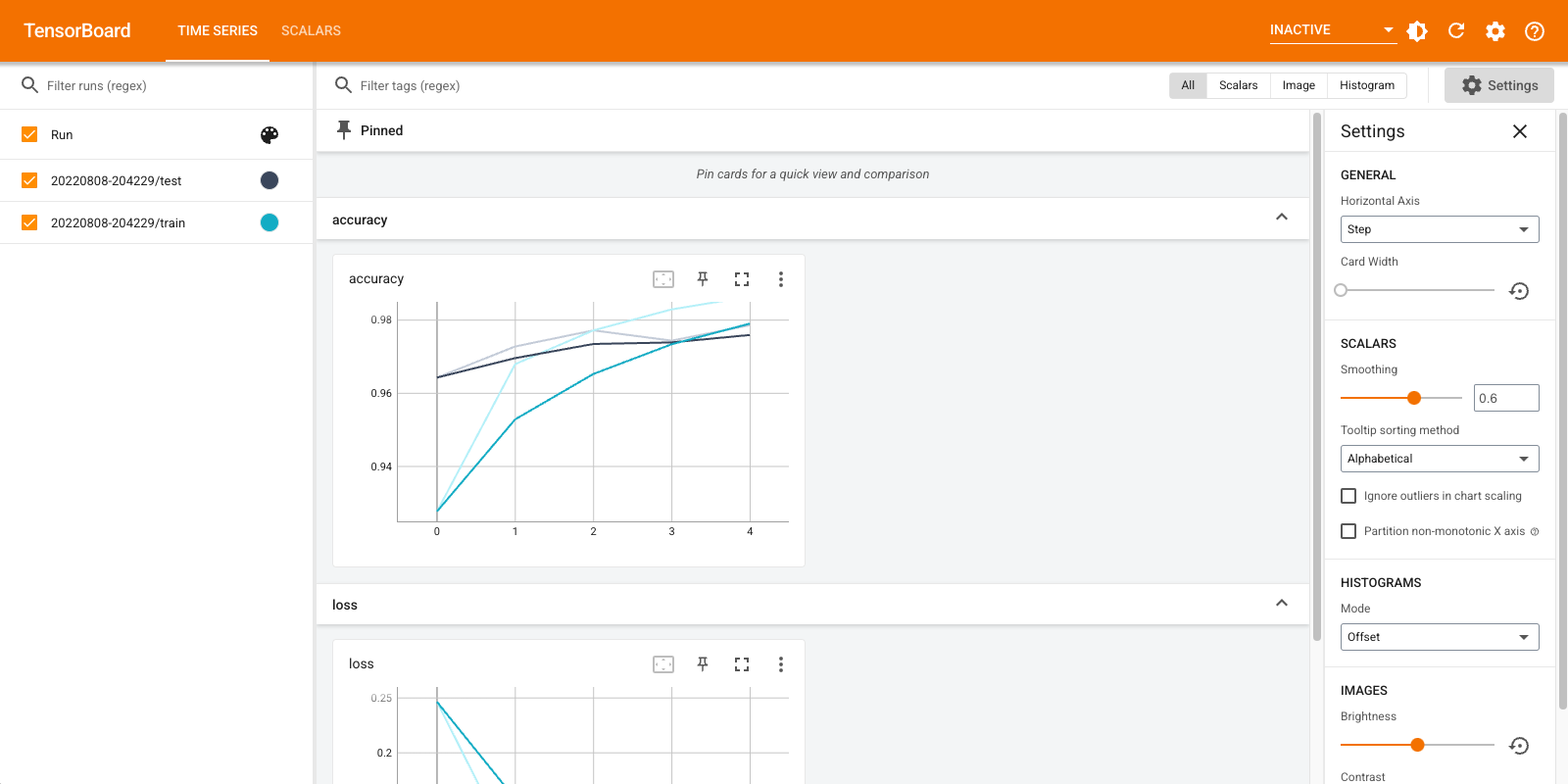
これで完了です!Keras コールバックと、ほかのカスタムシナリオで使用できる tf.summary を使って TensorBoardを使用する方法を確認しました。
TensorBoard.dev: ML 実験結果のホストと共有
TensorBoard.dev は無料の一般公開サービスで、TensorBoard ログをアップロードし、学術論文、ブログ投稿、ソーシャルメディアなどでの共有に使用するパーマリンクを取得することができます。このサービスにより、再現性と共同作業をさらに改善することができます。
TensorBoard.dev を使用するには、次のコマンドを実行してください。
!tensorboard dev upload \
--logdir logs/fit \
--name "(optional) My latest experiment" \
--description "(optional) Simple comparison of several hyperparameters" \
--one_shot
この呼び出しでは、パーセント記号(%)のプレフィクスを使って Colab マジックを呼び出すのではなく、感嘆符(!)をプレフィクスとしてシェルを呼び出していることに注意してください。コマンドラインからこのコマンドを呼び出す際は、いずれのプレフィクスも必要ありません。
こちらで例をご覧ください。
TensorBoard.dev の詳しい使用方法については、https://tensorboard.dev/#get-started をご覧ください。