
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
En apprentissage automatique, pour améliorer quelque chose, vous devez souvent être capable de le mesurer. TensorBoard est un outil permettant de fournir les mesures et les visualisations nécessaires au cours du workflow d'apprentissage automatique. Il permet de suivre les métriques d'expérience telles que la perte et la précision, de visualiser le graphique du modèle, de projeter les plongements dans un espace de dimension inférieure, et bien plus encore.
Ce guide de démarrage rapide montrera comment démarrer rapidement avec TensorBoard. Les autres guides de ce site Web fournissent plus de détails sur des fonctionnalités spécifiques, dont beaucoup ne sont pas incluses ici.
# Load the TensorBoard notebook extension
%load_ext tensorboard
import tensorflow as tf
import datetime
# Clear any logs from previous runsrm -rf ./logs/
Utilisation de l' MNIST ensemble de données comme l'exemple, normaliser les données et écrire une fonction qui crée un modèle simple Keras pour classer les images en 10 classes.
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
def create_model():
return tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] - 0s 0us/step
Utiliser TensorBoard avec Keras Model.fit()
Lors de la formation avec des Keras Model.fit () , en ajoutant le tf.keras.callbacks.TensorBoard rappel que les journaux sont assure créés et stockés. En outre, permettre histogramme calcul chaque époque avec histogram_freq=1 (ce qui est désactivée par défaut)
Placez les journaux dans un sous-répertoire horodaté pour permettre une sélection facile des différentes courses d'entraînement.
model = create_model()
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
log_dir = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
model.fit(x=x_train,
y=y_train,
epochs=5,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback])
Train on 60000 samples, validate on 10000 samples Epoch 1/5 60000/60000 [==============================] - 15s 246us/sample - loss: 0.2217 - accuracy: 0.9343 - val_loss: 0.1019 - val_accuracy: 0.9685 Epoch 2/5 60000/60000 [==============================] - 14s 229us/sample - loss: 0.0975 - accuracy: 0.9698 - val_loss: 0.0787 - val_accuracy: 0.9758 Epoch 3/5 60000/60000 [==============================] - 14s 231us/sample - loss: 0.0718 - accuracy: 0.9771 - val_loss: 0.0698 - val_accuracy: 0.9781 Epoch 4/5 60000/60000 [==============================] - 14s 227us/sample - loss: 0.0540 - accuracy: 0.9820 - val_loss: 0.0685 - val_accuracy: 0.9795 Epoch 5/5 60000/60000 [==============================] - 14s 228us/sample - loss: 0.0433 - accuracy: 0.9862 - val_loss: 0.0623 - val_accuracy: 0.9823 <tensorflow.python.keras.callbacks.History at 0x7fc8a5ee02e8>
Démarrez TensorBoard via la ligne de commande ou dans une expérience de bloc-notes. Les deux interfaces sont généralement les mêmes. Dans les ordinateurs portables, utilisez le %tensorboard magique ligne. Sur la ligne de commande, exécutez la même commande sans "%".
%tensorboard --logdir logs/fit
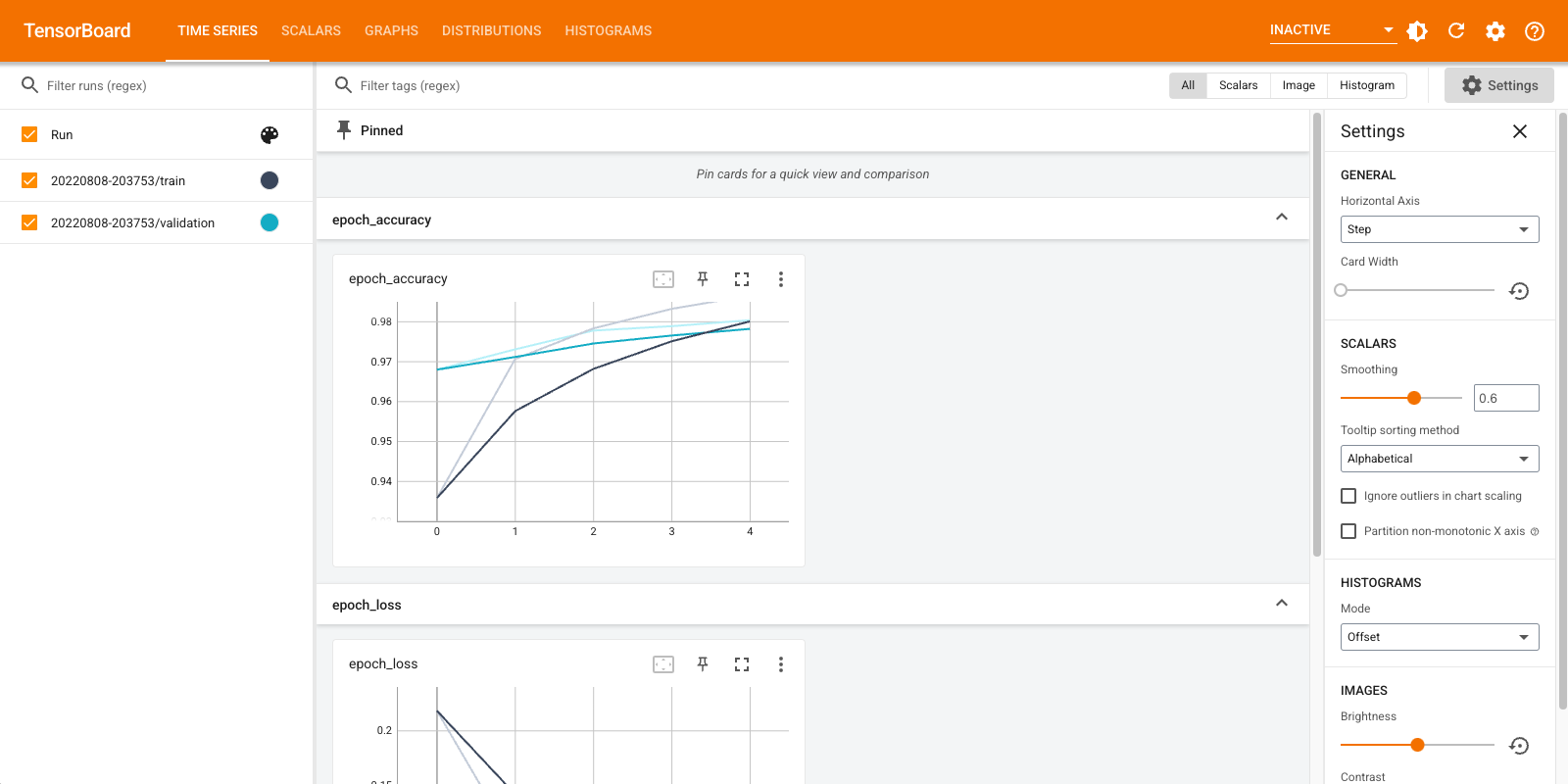
Un bref aperçu des tableaux de bord affichés (onglets dans la barre de navigation supérieure) :
- Le tableau de bord Scalaires montre comment la perte et les paramètres changent à chaque époque. Vous pouvez également l'utiliser pour suivre la vitesse d'entraînement, le taux d'apprentissage et d'autres valeurs scalaires.
- Le tableau de bord graphiques vous permet de visualiser votre modèle. Dans ce cas, le graphique Keras des couches s'affiche, ce qui peut vous aider à vous assurer qu'il est correctement construit.
- Les tableaux de bord et distributions Histogrammes montrent la distribution d'un Tensor au fil du temps. Cela peut être utile pour visualiser les poids et les biais et vérifier qu'ils changent de manière attendue.
Des plug-ins TensorBoard supplémentaires sont automatiquement activés lorsque vous enregistrez d'autres types de données. Par exemple, le rappel Keras TensorBoard vous permet également de consigner les images et les intégrations. Vous pouvez voir quels autres plugins sont disponibles dans TensorBoard en cliquant sur le menu déroulant "inactif" en haut à droite.
Utiliser TensorBoard avec d'autres méthodes
Lors de la formation avec des méthodes telles que tf.GradientTape() , l' utilisation tf.summary pour consigner les informations nécessaires.
Utilisez le même jeu de données comme ci - dessus, mais le convertir en tf.data.Dataset pour tirer parti des capacités Batching:
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
train_dataset = train_dataset.shuffle(60000).batch(64)
test_dataset = test_dataset.batch(64)
Le code de formation suit le démarrage rapide avancé tutoriel, mais montre comment enregistrer des métriques à TensorBoard. Choisissez la perte et l'optimiseur :
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()
Créez des métriques avec état qui peuvent être utilisées pour accumuler des valeurs pendant l'entraînement et enregistrées à tout moment :
# Define our metrics
train_loss = tf.keras.metrics.Mean('train_loss', dtype=tf.float32)
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('train_accuracy')
test_loss = tf.keras.metrics.Mean('test_loss', dtype=tf.float32)
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('test_accuracy')
Définir les fonctions d'entraînement et de test :
def train_step(model, optimizer, x_train, y_train):
with tf.GradientTape() as tape:
predictions = model(x_train, training=True)
loss = loss_object(y_train, predictions)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
train_loss(loss)
train_accuracy(y_train, predictions)
def test_step(model, x_test, y_test):
predictions = model(x_test)
loss = loss_object(y_test, predictions)
test_loss(loss)
test_accuracy(y_test, predictions)
Configurez les rédacteurs de résumés pour écrire les résumés sur le disque dans un répertoire de journaux différent :
current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
train_log_dir = 'logs/gradient_tape/' + current_time + '/train'
test_log_dir = 'logs/gradient_tape/' + current_time + '/test'
train_summary_writer = tf.summary.create_file_writer(train_log_dir)
test_summary_writer = tf.summary.create_file_writer(test_log_dir)
Commence l'entraînement. Utilisez tf.summary.scalar() pour enregistrer des métriques (perte et précision) lors de la formation / test dans le cadre des écrivains sommaires pour écrire les résumés sur le disque. Vous avez le contrôle sur les métriques à enregistrer et à quelle fréquence le faire. Autres tf.summary fonctions permettent la connexion d' autres types de données.
model = create_model() # reset our model
EPOCHS = 5
for epoch in range(EPOCHS):
for (x_train, y_train) in train_dataset:
train_step(model, optimizer, x_train, y_train)
with train_summary_writer.as_default():
tf.summary.scalar('loss', train_loss.result(), step=epoch)
tf.summary.scalar('accuracy', train_accuracy.result(), step=epoch)
for (x_test, y_test) in test_dataset:
test_step(model, x_test, y_test)
with test_summary_writer.as_default():
tf.summary.scalar('loss', test_loss.result(), step=epoch)
tf.summary.scalar('accuracy', test_accuracy.result(), step=epoch)
template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'
print (template.format(epoch+1,
train_loss.result(),
train_accuracy.result()*100,
test_loss.result(),
test_accuracy.result()*100))
# Reset metrics every epoch
train_loss.reset_states()
test_loss.reset_states()
train_accuracy.reset_states()
test_accuracy.reset_states()
Epoch 1, Loss: 0.24321186542510986, Accuracy: 92.84333801269531, Test Loss: 0.13006582856178284, Test Accuracy: 95.9000015258789 Epoch 2, Loss: 0.10446818172931671, Accuracy: 96.84833526611328, Test Loss: 0.08867532759904861, Test Accuracy: 97.1199951171875 Epoch 3, Loss: 0.07096975296735764, Accuracy: 97.80166625976562, Test Loss: 0.07875105738639832, Test Accuracy: 97.48999786376953 Epoch 4, Loss: 0.05380449816584587, Accuracy: 98.34166717529297, Test Loss: 0.07712937891483307, Test Accuracy: 97.56999969482422 Epoch 5, Loss: 0.041443776339292526, Accuracy: 98.71833038330078, Test Loss: 0.07514958828687668, Test Accuracy: 97.5
Ouvrez à nouveau TensorBoard, cette fois en le pointant vers le nouveau répertoire de journaux. Nous aurions également pu démarrer TensorBoard pour surveiller la formation pendant qu'elle progresse.
%tensorboard --logdir logs/gradient_tape
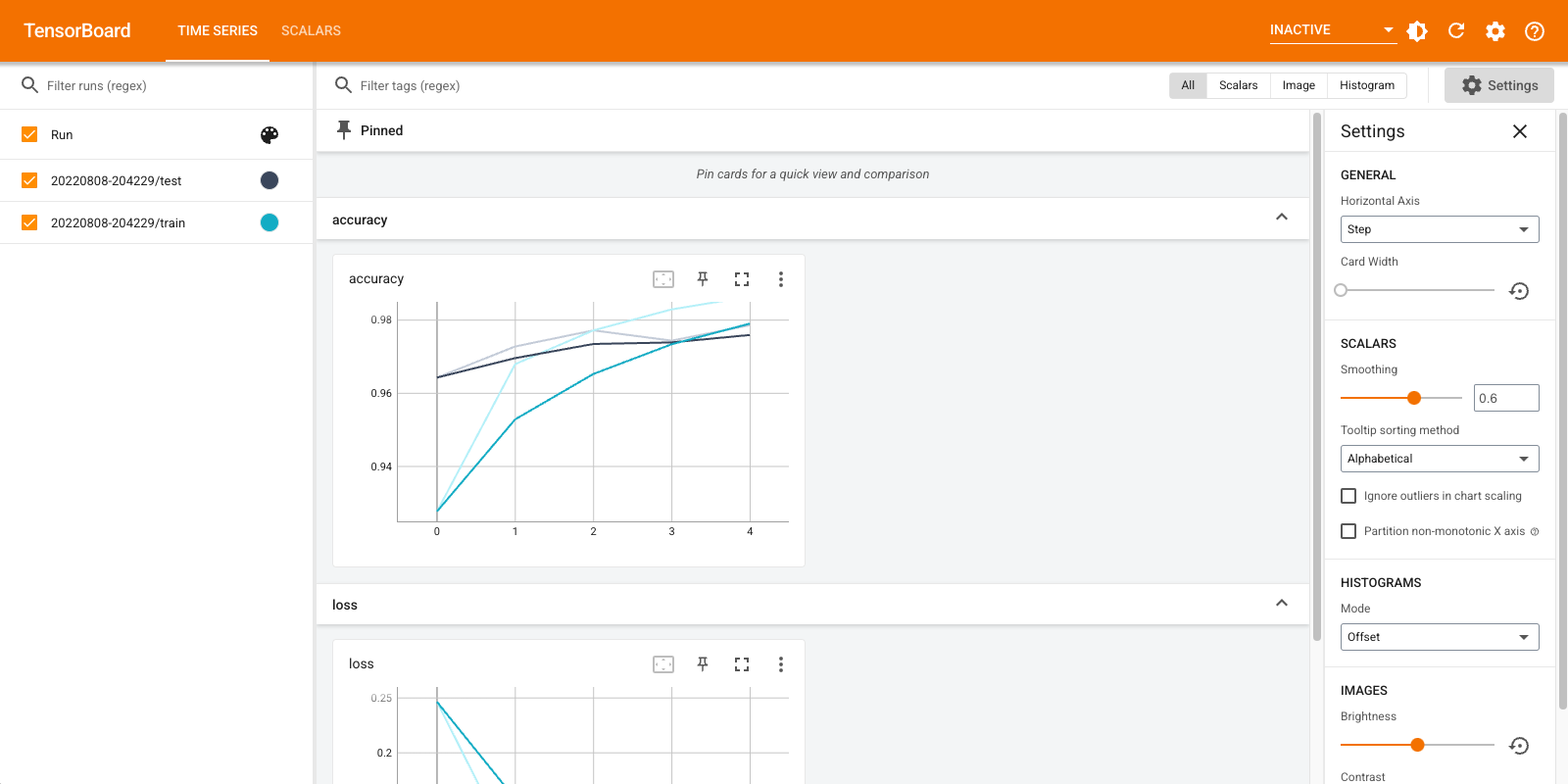
C'est ça! Vous avez vu comment utiliser TensorBoard à la fois par le rappel Keras et par tf.summary pour plus de scénarios personnalisés.
TensorBoard.dev : hébergez et partagez les résultats de vos expériences de ML
TensorBoard.dev est un service public gratuit qui vous permet de télécharger vos journaux TensorBoard et obtenez un lien permanent qui peut être partagé avec tout le monde dans les journaux académiques, blogs, médias sociaux, etc. Cela peut permettre une meilleure reproductibilité et la collaboration.
Pour utiliser TensorBoard.dev, exécutez la commande suivante :
!tensorboard dev upload \
--logdir logs/fit \
--name "(optional) My latest experiment" \
--description "(optional) Simple comparison of several hyperparameters" \
--one_shot
Notez que cette invocation utilise le préfixe d'exclamation ( ! ) Pour appeler le shell plutôt que le préfixe pour cent ( % de invoquer la magie de colab). Lors de l'appel de cette commande à partir de la ligne de commande, aucun préfixe n'est nécessaire.
Voir un exemple ici .
Pour plus de détails sur la façon d'utiliser TensorBoard.dev, voir https://tensorboard.dev/#get-started