
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Lors de la construction des modèles d' apprentissage de la machine, vous devez choisir différents hyperparam'etres , tels que le taux d'abandon dans une couche ou le taux d'apprentissage. Ces décisions ont un impact sur les métriques du modèle, telles que la précision. Par conséquent, une étape importante du workflow d'apprentissage automatique consiste à identifier les meilleurs hyperparamètres pour votre problème, ce qui implique souvent une expérimentation. Ce processus est connu sous le nom d'« optimisation des hyperparamètres » ou de « réglage des hyperparamètres ».
Le tableau de bord HParams de TensorBoard fournit plusieurs outils pour vous aider dans ce processus d'identification de la meilleure expérience ou des ensembles d'hyperparamètres les plus prometteurs.
Ce tutoriel se concentrera sur les étapes suivantes :
- Configuration de l'expérience et résumé HParams
- Adapter les exécutions TensorFlow pour consigner les hyperparamètres et les métriques
- Démarrez les exécutions et enregistrez-les toutes sous un répertoire parent
- Visualisez les résultats dans le tableau de bord HParams de TensorBoard
Commencez par installer TF 2.0 et chargez l'extension TensorBoard pour notebook :
# Load the TensorBoard notebook extension
%load_ext tensorboard
# Clear any logs from previous runsrm -rf ./logs/
Importez TensorFlow et le plug-in TensorBoard HParams :
import tensorflow as tf
from tensorboard.plugins.hparams import api as hp
Télécharger le FashionMNIST ensemble de données et agrandissez:
fashion_mnist = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion_mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 8192/5148 [===============================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step
1. Configuration de l'expérience et résumé de l'expérience HParams
Expérimentez avec trois hyperparamètres dans le modèle :
- Nombre d'unités dans la première couche dense
- Taux d'abandon dans la couche d'abandon
- Optimiseur
Répertoriez les valeurs à essayer et enregistrez une configuration d'expérience sur TensorBoard. Cette étape est facultative : vous pouvez fournir des informations sur le domaine pour permettre un filtrage plus précis des hyperparamètres dans l'interface utilisateur et vous pouvez spécifier les métriques à afficher.
HP_NUM_UNITS = hp.HParam('num_units', hp.Discrete([16, 32]))
HP_DROPOUT = hp.HParam('dropout', hp.RealInterval(0.1, 0.2))
HP_OPTIMIZER = hp.HParam('optimizer', hp.Discrete(['adam', 'sgd']))
METRIC_ACCURACY = 'accuracy'
with tf.summary.create_file_writer('logs/hparam_tuning').as_default():
hp.hparams_config(
hparams=[HP_NUM_UNITS, HP_DROPOUT, HP_OPTIMIZER],
metrics=[hp.Metric(METRIC_ACCURACY, display_name='Accuracy')],
)
Si vous choisissez de sauter cette étape, vous pouvez utiliser un littéral de chaîne où vous utiliser autrement une HParam valeur: par exemple, hparams['dropout'] au lieu de hparams[HP_DROPOUT] .
2. Adapter les exécutions TensorFlow pour consigner les hyperparamètres et les métriques
Le modèle sera assez simple : deux couches denses avec une couche de décrochage entre elles. Le code d'entraînement vous semblera familier, bien que les hyperparamètres ne soient plus codés en dur. Au lieu de cela, les hyperparamètres sont fournis dans un hparams dictionnaire et utilisé tout au long de la fonction de formation:
def train_test_model(hparams):
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(hparams[HP_NUM_UNITS], activation=tf.nn.relu),
tf.keras.layers.Dropout(hparams[HP_DROPOUT]),
tf.keras.layers.Dense(10, activation=tf.nn.softmax),
])
model.compile(
optimizer=hparams[HP_OPTIMIZER],
loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
)
model.fit(x_train, y_train, epochs=1) # Run with 1 epoch to speed things up for demo purposes
_, accuracy = model.evaluate(x_test, y_test)
return accuracy
Pour chaque exécution, enregistrez un résumé hparams avec les hyperparamètres et la précision finale :
def run(run_dir, hparams):
with tf.summary.create_file_writer(run_dir).as_default():
hp.hparams(hparams) # record the values used in this trial
accuracy = train_test_model(hparams)
tf.summary.scalar(METRIC_ACCURACY, accuracy, step=1)
Lors de la formation de modèles Keras, vous pouvez utiliser des rappels au lieu de les écrire directement :
model.fit(
...,
callbacks=[
tf.keras.callbacks.TensorBoard(logdir), # log metrics
hp.KerasCallback(logdir, hparams), # log hparams
],
)
3. Démarrez les exécutions et enregistrez-les toutes sous un répertoire parent
Vous pouvez maintenant essayer plusieurs expériences, en entraînant chacune avec un ensemble différent d'hyperparamètres.
Pour plus de simplicité, utilisez une recherche par grille : essayez toutes les combinaisons des paramètres discrets et uniquement les limites inférieure et supérieure du paramètre à valeur réelle. Pour des scénarios plus complexes, il peut être plus efficace de choisir chaque valeur d'hyperparamètre au hasard (c'est ce qu'on appelle une recherche aléatoire). Il existe des méthodes plus avancées qui peuvent être utilisées.
Exécutez quelques expériences, qui prendront quelques minutes :
session_num = 0
for num_units in HP_NUM_UNITS.domain.values:
for dropout_rate in (HP_DROPOUT.domain.min_value, HP_DROPOUT.domain.max_value):
for optimizer in HP_OPTIMIZER.domain.values:
hparams = {
HP_NUM_UNITS: num_units,
HP_DROPOUT: dropout_rate,
HP_OPTIMIZER: optimizer,
}
run_name = "run-%d" % session_num
print('--- Starting trial: %s' % run_name)
print({h.name: hparams[h] for h in hparams})
run('logs/hparam_tuning/' + run_name, hparams)
session_num += 1
--- Starting trial: run-0
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 62us/sample - loss: 0.6872 - accuracy: 0.7564
10000/10000 [==============================] - 0s 35us/sample - loss: 0.4806 - accuracy: 0.8321
--- Starting trial: run-1
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9428 - accuracy: 0.6769
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6519 - accuracy: 0.7770
--- Starting trial: run-2
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 60us/sample - loss: 0.8158 - accuracy: 0.7078
10000/10000 [==============================] - 0s 36us/sample - loss: 0.5309 - accuracy: 0.8154
--- Starting trial: run-3
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 50us/sample - loss: 1.1465 - accuracy: 0.6019
10000/10000 [==============================] - 0s 36us/sample - loss: 0.7007 - accuracy: 0.7683
--- Starting trial: run-4
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 65us/sample - loss: 0.6178 - accuracy: 0.7849
10000/10000 [==============================] - 0s 38us/sample - loss: 0.4645 - accuracy: 0.8395
--- Starting trial: run-5
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 55us/sample - loss: 0.8989 - accuracy: 0.6896
10000/10000 [==============================] - 0s 37us/sample - loss: 0.6335 - accuracy: 0.7853
--- Starting trial: run-6
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 64us/sample - loss: 0.6404 - accuracy: 0.7782
10000/10000 [==============================] - 0s 37us/sample - loss: 0.4802 - accuracy: 0.8265
--- Starting trial: run-7
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9633 - accuracy: 0.6703
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6516 - accuracy: 0.7755
4. Visualisez les résultats dans le plugin HParams de TensorBoard
Le tableau de bord HParams peut maintenant être ouvert. Démarrez TensorBoard et cliquez sur "HParams" en haut.
%tensorboard --logdir logs/hparam_tuning
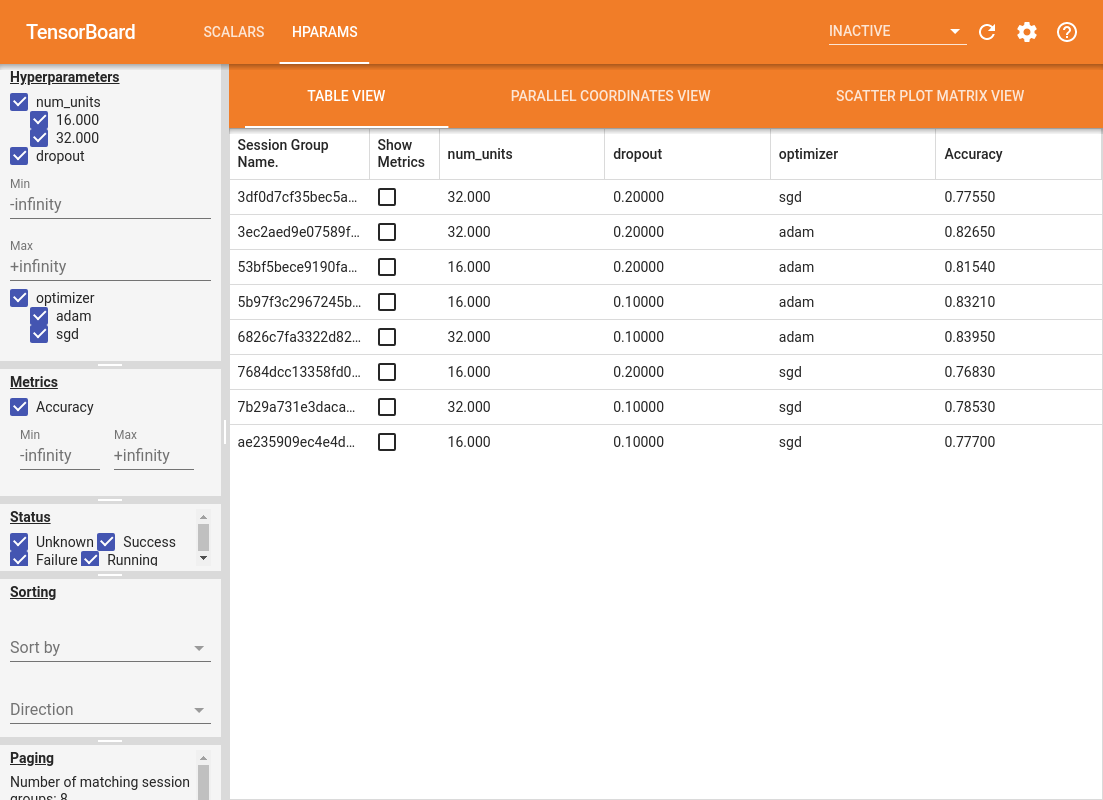
Le volet gauche du tableau de bord fournit des fonctionnalités de filtrage actives dans toutes les vues du tableau de bord HParams :
- Filtrer les hyperparamètres/métriques affichés dans le tableau de bord
- Filtrer quelles valeurs d'hyperparamètres/métriques sont affichées dans le tableau de bord
- Filtre sur l'état d'exécution (en cours d'exécution, succès, ...)
- Trier par hyperparamètre/métrique dans la vue tableau
- Nombre de groupes de sessions à afficher (utile pour la performance lorsqu'il y a beaucoup d'expériences)
Le tableau de bord HParams a trois vues différentes, avec diverses informations utiles :
- Le Tableau énumère les pistes, leurs hyperparam'etres et leurs paramètres.
- Le parallèle Coordonnées View affiche chaque course comme une ligne passant par un axe pour chaque hyperparemeter et métrique. Cliquez et faites glisser la souris sur n'importe quel axe pour marquer une région qui mettra en évidence uniquement les passages qui la traversent. Cela peut être utile pour identifier les groupes d'hyperparamètres les plus importants. Les axes eux-mêmes peuvent être réorganisés en les faisant glisser.
- Le nuage de points DEMONTRERAIT parcelles comparant chaque hyperparam'etre / métrique avec chaque mesure. Cela peut aider à identifier des corrélations. Cliquez et faites glisser pour sélectionner une région dans un tracé spécifique et mettez en surbrillance ces sessions dans les autres tracés.
Une ligne de tableau, une ligne de coordonnées parallèles et un marché de nuages de points peuvent être cliqués pour voir un graphique des métriques en fonction des étapes d'entraînement pour cette session (bien que dans ce didacticiel, une seule étape soit utilisée pour chaque exécution).
Pour explorer davantage les capacités du tableau de bord HParams, téléchargez un ensemble de journaux prégénérés avec plus d'expériences :
wget -q 'https://storage.googleapis.com/download.tensorflow.org/tensorboard/hparams_demo_logs.zip'unzip -q hparams_demo_logs.zip -d logs/hparam_demo
Affichez ces journaux dans TensorBoard :
%tensorboard --logdir logs/hparam_demo
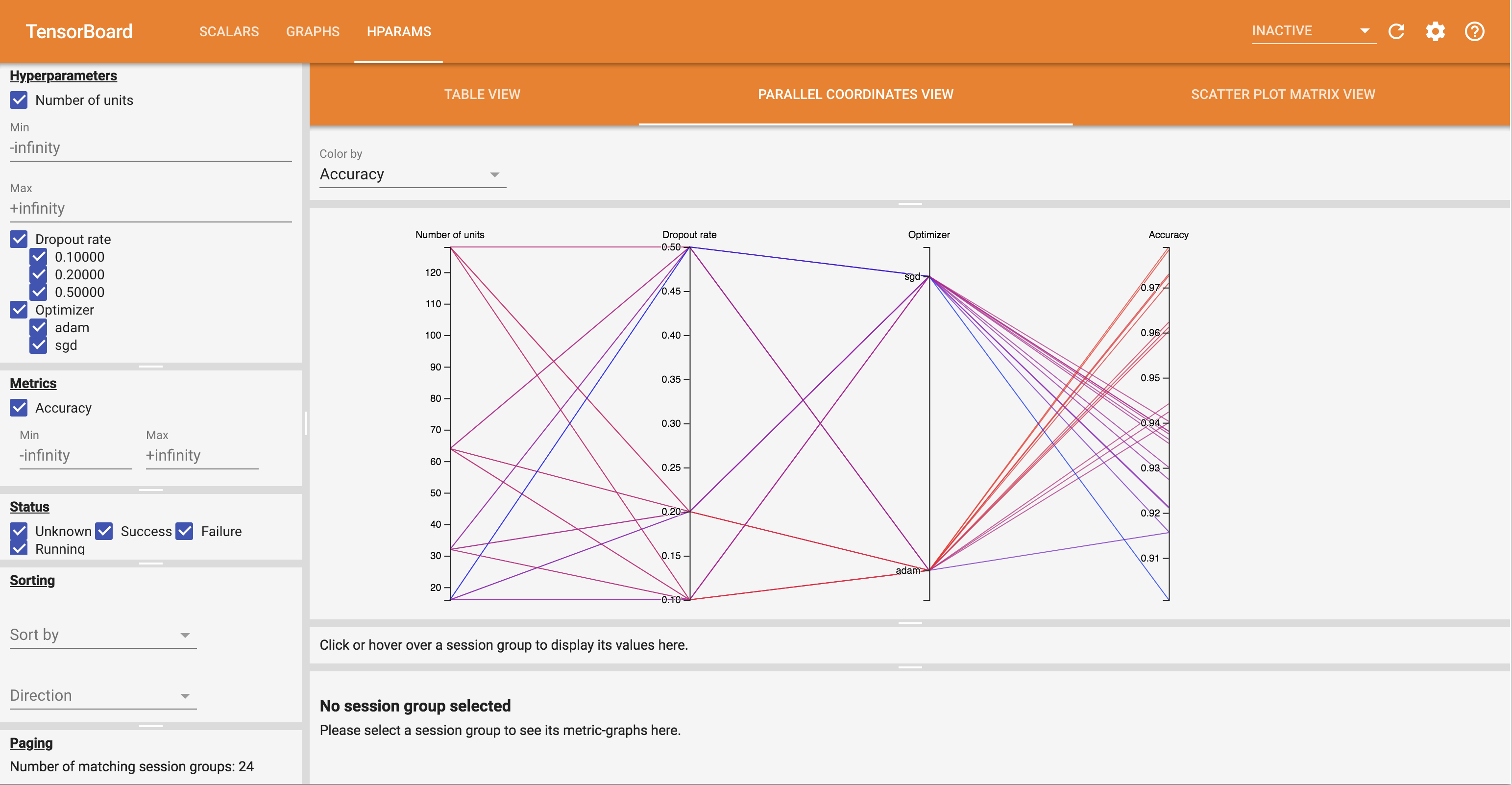
Vous pouvez essayer les différentes vues dans le tableau de bord HParams.
Par exemple, en accédant à la vue des coordonnées parallèles et en cliquant et en faisant glisser sur l'axe de précision, vous pouvez sélectionner les analyses avec la plus grande précision. Comme ces exécutions passent par « adam » dans l'axe de l'optimiseur, vous pouvez conclure que « adam » a obtenu de meilleurs résultats que « sgd » sur ces expériences.