
| | |  Voir sur GitHub Voir sur GitHub | | |
Ce didacticiel contient un code complet pour affiner BERT afin d'effectuer une analyse des sentiments sur un ensemble de données de critiques de films IMDB en texte brut. En plus de la formation d'un modèle, vous apprendrez à prétraiter le texte dans un format approprié.
Dans ce cahier, vous allez :
- Charger le jeu de données IMDB
- Charger un modèle BERT à partir de TensorFlow Hub
- Construisez votre propre modèle en combinant BERT avec un classificateur
- Entraînez votre propre modèle, en ajustant BERT dans le cadre de cela
- Enregistrez votre modèle et utilisez-le pour classer des phrases
Si vous êtes nouveau à travailler avec l'ensemble de données IMDB, s'il vous plaît voir le classement de texte de base pour plus de détails.
À propos de BERT
BERT et d' autres architectures de codeur de transformateur ont été un grand succès sur une variété de tâches en PNL (traitement du langage naturel). Ils calculent des représentations vectorielles dans l'espace du langage naturel qui peuvent être utilisées dans des modèles d'apprentissage en profondeur. La famille de modèles BERT utilise l'architecture de l'encodeur Transformer pour traiter chaque jeton de texte d'entrée dans le contexte complet de tous les jetons avant et après, d'où le nom : Représentations d'encodeur bidirectionnel de Transformers.
Les modèles BERT sont généralement pré-formés sur un grand corpus de texte, puis affinés pour des tâches spécifiques.
Installer
# A dependency of the preprocessing for BERT inputspip install -q -U tensorflow-text
Vous utiliserez l'optimiseur de AdamW tensorflow / modèles .
pip install -q tf-models-official
import os
import shutil
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_text as text
from official.nlp import optimization # to create AdamW optimizer
import matplotlib.pyplot as plt
tf.get_logger().setLevel('ERROR')
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py:119: PkgResourcesDeprecationWarning: 0.18ubuntu0.18.04.1 is an invalid version and will not be supported in a future release PkgResourcesDeprecationWarning,
Analyse des sentiments
Ce portable forme un modèle d'analyse des sentiments pour classer les critiques de films comme positifs ou négatifs, sur la base du texte de l'examen.
Vous utiliserez le Grand Film Review Dataset qui contient le texte de 50.000 critiques de films de la Internet Movie Database .
Télécharger le jeu de données IMDB
Téléchargeons et extrayons l'ensemble de données, puis explorons la structure du répertoire.
url = 'https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz'
dataset = tf.keras.utils.get_file('aclImdb_v1.tar.gz', url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
train_dir = os.path.join(dataset_dir, 'train')
# remove unused folders to make it easier to load the data
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 7s 0us/step 84140032/84125825 [==============================] - 7s 0us/step
Ensuite, vous utiliserez l' text_dataset_from_directory utilitaire pour créer une étiquette tf.data.Dataset .
L'ensemble de données IMDB a déjà été divisé en train et test, mais il manque un ensemble de validation. Créons un ensemble de validation à l' aide d' une 80:20 division des données de formation en utilisant le validation_split arguments ci - dessous.
AUTOTUNE = tf.data.AUTOTUNE
batch_size = 32
seed = 42
raw_train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
class_names = raw_train_ds.class_names
train_ds = raw_train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
Found 25000 files belonging to 2 classes. Using 20000 files for training. Found 25000 files belonging to 2 classes. Using 5000 files for validation. Found 25000 files belonging to 2 classes.
Jetons un œil à quelques critiques.
for text_batch, label_batch in train_ds.take(1):
for i in range(3):
print(f'Review: {text_batch.numpy()[i]}')
label = label_batch.numpy()[i]
print(f'Label : {label} ({class_names[label]})')
Review: b'"Pandemonium" is a horror movie spoof that comes off more stupid than funny. Believe me when I tell you, I love comedies. Especially comedy spoofs. "Airplane", "The Naked Gun" trilogy, "Blazing Saddles", "High Anxiety", and "Spaceballs" are some of my favorite comedies that spoof a particular genre. "Pandemonium" is not up there with those films. Most of the scenes in this movie had me sitting there in stunned silence because the movie wasn\'t all that funny. There are a few laughs in the film, but when you watch a comedy, you expect to laugh a lot more than a few times and that\'s all this film has going for it. Geez, "Scream" had more laughs than this film and that was more of a horror film. How bizarre is that?<br /><br />*1/2 (out of four)' Label : 0 (neg) Review: b"David Mamet is a very interesting and a very un-equal director. His first movie 'House of Games' was the one I liked best, and it set a series of films with characters whose perspective of life changes as they get into complicated situations, and so does the perspective of the viewer.<br /><br />So is 'Homicide' which from the title tries to set the mind of the viewer to the usual crime drama. The principal characters are two cops, one Jewish and one Irish who deal with a racially charged area. The murder of an old Jewish shop owner who proves to be an ancient veteran of the Israeli Independence war triggers the Jewish identity in the mind and heart of the Jewish detective.<br /><br />This is were the flaws of the film are the more obvious. The process of awakening is theatrical and hard to believe, the group of Jewish militants is operatic, and the way the detective eventually walks to the final violent confrontation is pathetic. The end of the film itself is Mamet-like smart, but disappoints from a human emotional perspective.<br /><br />Joe Mantegna and William Macy give strong performances, but the flaws of the story are too evident to be easily compensated." Label : 0 (neg) Review: b'Great documentary about the lives of NY firefighters during the worst terrorist attack of all time.. That reason alone is why this should be a must see collectors item.. What shocked me was not only the attacks, but the"High Fat Diet" and physical appearance of some of these firefighters. I think a lot of Doctors would agree with me that,in the physical shape they were in, some of these firefighters would NOT of made it to the 79th floor carrying over 60 lbs of gear. Having said that i now have a greater respect for firefighters and i realize becoming a firefighter is a life altering job. The French have a history of making great documentary\'s and that is what this is, a Great Documentary.....' Label : 1 (pos) 2021-12-01 12:17:32.795514: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
Chargement de modèles depuis TensorFlow Hub
Ici, vous pouvez choisir le modèle BERT que vous allez charger à partir de TensorFlow Hub et le régler avec précision. Il existe plusieurs modèles BERT disponibles.
- BERT-Base , non tubé et sept autres modèles avec des poids formés libérés par les auteurs de l' ORET d' origine.
- Les petits BERT ont la même architecture générale mais moins et / ou petits blocs transformateurs, qui vous permet d' explorer des compromis entre la vitesse, la taille et la qualité.
- ALBERT : quatre tailles différentes de « Un Lite BERT » qui réduit la taille du modèle (mais pas le temps de calcul) en partageant les paramètres entre les couches.
- BERT experts : huit modèles qui ont tous l'architecture de base BERT , mais offrent un choix entre les différents domaines pré-formation, afin d' aligner plus étroitement avec la tâche cible.
- Electra a la même architecture que BERT (en trois tailles différentes), mais obtient une pré-formation comme un discriminateur dans un set-up qui ressemble à un réseau générative accusatoire (de GAN).
- BERT avec attention Talking Heads-et Gated GELU [ la base , grande ] a deux améliorations au cœur de l'architecture Transformer.
La documentation du modèle sur TensorFlow Hub contient plus de détails et de références à la littérature de recherche. Suivez les liens ci - dessus, ou cliquez sur l' tfhub.dev URL imprimée après la prochaine exécution de la cellule.
La suggestion est de commencer avec un petit BERT (avec moins de paramètres) car ils sont plus rapides à affiner. Si vous aimez un petit modèle mais avec une plus grande précision, ALBERT pourrait être votre prochaine option. Si vous souhaitez une précision encore meilleure, choisissez l'une des tailles BERT classiques ou leurs améliorations récentes comme Electra, Talking Heads ou un expert BERT.
Mis à part les modèles disponibles ci - dessous, il existe plusieurs versions des modèles qui sont plus grandes et peuvent donner une précision encore meilleure, mais ils sont trop gros pour être peaufiné sur un seul GPU. Vous serez en mesure de le faire sur les Solve tâches en utilisant COLLE BERT sur un colab TPU .
Vous verrez dans le code ci-dessous que changer l'URL tfhub.dev est suffisant pour essayer l'un de ces modèles, car toutes les différences entre eux sont encapsulées dans les SavedModels de TF Hub.
Choisissez un modèle BERT pour affiner
bert_model_name = 'small_bert/bert_en_uncased_L-4_H-512_A-8'
map_name_to_handle = {
'bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/3',
'bert_en_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_cased_L-12_H-768_A-12/3',
'bert_multi_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_multi_cased_L-12_H-768_A-12/3',
'small_bert/bert_en_uncased_L-2_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-128_A-2/1',
'small_bert/bert_en_uncased_L-2_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-256_A-4/1',
'small_bert/bert_en_uncased_L-2_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-512_A-8/1',
'small_bert/bert_en_uncased_L-2_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-768_A-12/1',
'small_bert/bert_en_uncased_L-4_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-128_A-2/1',
'small_bert/bert_en_uncased_L-4_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-256_A-4/1',
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1',
'small_bert/bert_en_uncased_L-4_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-768_A-12/1',
'small_bert/bert_en_uncased_L-6_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-128_A-2/1',
'small_bert/bert_en_uncased_L-6_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-256_A-4/1',
'small_bert/bert_en_uncased_L-6_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-512_A-8/1',
'small_bert/bert_en_uncased_L-6_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-768_A-12/1',
'small_bert/bert_en_uncased_L-8_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-128_A-2/1',
'small_bert/bert_en_uncased_L-8_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-256_A-4/1',
'small_bert/bert_en_uncased_L-8_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-512_A-8/1',
'small_bert/bert_en_uncased_L-8_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-768_A-12/1',
'small_bert/bert_en_uncased_L-10_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-128_A-2/1',
'small_bert/bert_en_uncased_L-10_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-256_A-4/1',
'small_bert/bert_en_uncased_L-10_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-512_A-8/1',
'small_bert/bert_en_uncased_L-10_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-768_A-12/1',
'small_bert/bert_en_uncased_L-12_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-128_A-2/1',
'small_bert/bert_en_uncased_L-12_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-256_A-4/1',
'small_bert/bert_en_uncased_L-12_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-512_A-8/1',
'small_bert/bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-768_A-12/1',
'albert_en_base':
'https://tfhub.dev/tensorflow/albert_en_base/2',
'electra_small':
'https://tfhub.dev/google/electra_small/2',
'electra_base':
'https://tfhub.dev/google/electra_base/2',
'experts_pubmed':
'https://tfhub.dev/google/experts/bert/pubmed/2',
'experts_wiki_books':
'https://tfhub.dev/google/experts/bert/wiki_books/2',
'talking-heads_base':
'https://tfhub.dev/tensorflow/talkheads_ggelu_bert_en_base/1',
}
map_model_to_preprocess = {
'bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'bert_en_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_cased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'bert_multi_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_multi_cased_preprocess/3',
'albert_en_base':
'https://tfhub.dev/tensorflow/albert_en_preprocess/3',
'electra_small':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'electra_base':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'experts_pubmed':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'experts_wiki_books':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'talking-heads_base':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
}
tfhub_handle_encoder = map_name_to_handle[bert_model_name]
tfhub_handle_preprocess = map_model_to_preprocess[bert_model_name]
print(f'BERT model selected : {tfhub_handle_encoder}')
print(f'Preprocess model auto-selected: {tfhub_handle_preprocess}')
BERT model selected : https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Preprocess model auto-selected: https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3
Le modèle de prétraitement
Les entrées de texte doivent être transformées en identifiants de jetons numériques et disposées en plusieurs Tensors avant d'être entrées dans BERT. TensorFlow Hub fournit un modèle de prétraitement correspondant pour chacun des modèles BERT décrits ci-dessus, qui implémente cette transformation à l'aide des opérations TF de la bibliothèque TF.text. Il n'est pas nécessaire d'exécuter du code Python pur en dehors de votre modèle TensorFlow pour prétraiter le texte.
Le modèle de prétraitement doit être celui référencé par la documentation du modèle BERT, que vous pouvez lire à l'URL imprimée ci-dessus. Pour les modèles BERT de la liste déroulante ci-dessus, le modèle de prétraitement est sélectionné automatiquement.
bert_preprocess_model = hub.KerasLayer(tfhub_handle_preprocess)
Essayons le modèle de prétraitement sur du texte et voyons le résultat :
text_test = ['this is such an amazing movie!']
text_preprocessed = bert_preprocess_model(text_test)
print(f'Keys : {list(text_preprocessed.keys())}')
print(f'Shape : {text_preprocessed["input_word_ids"].shape}')
print(f'Word Ids : {text_preprocessed["input_word_ids"][0, :12]}')
print(f'Input Mask : {text_preprocessed["input_mask"][0, :12]}')
print(f'Type Ids : {text_preprocessed["input_type_ids"][0, :12]}')
Keys : ['input_word_ids', 'input_mask', 'input_type_ids'] Shape : (1, 128) Word Ids : [ 101 2023 2003 2107 2019 6429 3185 999 102 0 0 0] Input Mask : [1 1 1 1 1 1 1 1 1 0 0 0] Type Ids : [0 0 0 0 0 0 0 0 0 0 0 0]
Comme vous pouvez le voir, maintenant vous avez les 3 sorties du pré - traitement qu'un modèle BERT utiliserait ( input_words_id , input_mask et input_type_ids ).
Quelques autres points importants :
- L'entrée est tronquée à 128 jetons. Le nombre de jetons peut être personnalisé, et vous pouvez voir plus de détails sur les résoudre des tâches en utilisant COLLE BERT sur un colab TPU .
- Les
input_type_idsn'ont une valeur (0) parce que c'est une seule entrée de la phrase. Pour une entrée à plusieurs phrases, il y aurait un numéro pour chaque entrée.
Étant donné que ce préprocesseur de texte est un modèle TensorFlow, il peut être inclus directement dans votre modèle.
Utilisation du modèle BERT
Avant de mettre BERT dans votre propre modèle, examinons ses sorties. Vous allez le charger à partir de TF Hub et voir les valeurs renvoyées.
bert_model = hub.KerasLayer(tfhub_handle_encoder)
bert_results = bert_model(text_preprocessed)
print(f'Loaded BERT: {tfhub_handle_encoder}')
print(f'Pooled Outputs Shape:{bert_results["pooled_output"].shape}')
print(f'Pooled Outputs Values:{bert_results["pooled_output"][0, :12]}')
print(f'Sequence Outputs Shape:{bert_results["sequence_output"].shape}')
print(f'Sequence Outputs Values:{bert_results["sequence_output"][0, :12]}')
Loaded BERT: https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Pooled Outputs Shape:(1, 512) Pooled Outputs Values:[ 0.76262873 0.99280983 -0.1861186 0.36673835 0.15233682 0.65504444 0.9681154 -0.9486272 0.00216158 -0.9877732 0.0684272 -0.9763061 ] Sequence Outputs Shape:(1, 128, 512) Sequence Outputs Values:[[-0.28946388 0.3432126 0.33231565 ... 0.21300787 0.7102078 -0.05771166] [-0.28742015 0.31981024 -0.2301858 ... 0.58455074 -0.21329722 0.7269209 ] [-0.66157013 0.6887685 -0.87432927 ... 0.10877253 -0.26173282 0.47855264] ... [-0.2256118 -0.28925604 -0.07064401 ... 0.4756601 0.8327715 0.40025353] [-0.29824278 -0.27473143 -0.05450511 ... 0.48849759 1.0955356 0.18163344] [-0.44378197 0.00930723 0.07223766 ... 0.1729009 1.1833246 0.07897988]]
Les modèles BERT retournent une carte avec 3 clés importantes: pooled_output , sequence_output , encoder_outputs :
-
pooled_outputreprésente chaque séquence d'entrée comme un tout. La forme est[batch_size, H]. Vous pouvez considérer cela comme une intégration pour l'ensemble de la critique du film. -
sequence_outputreprésente chaque jeton d' entrée dans le contexte. La forme est[batch_size, seq_length, H]. Vous pouvez considérer cela comme une intégration contextuelle pour chaque jeton de la critique de film. -
encoder_outputssont les activations intermédiaires desLblocs transformateur. les[batch_size, seq_length, 1024]0 <= i < Loutputs["encoder_outputs"][i]est un tenseur de forme[batch_size, seq_length, 1024]avec les sorties de la i-ième bloc de transformateur, pour0 <= i < L. La dernière valeur de la liste est égale àsequence_output.
Pour la mise au point que vous allez utiliser le pooled_output tableau.
Définir votre modèle
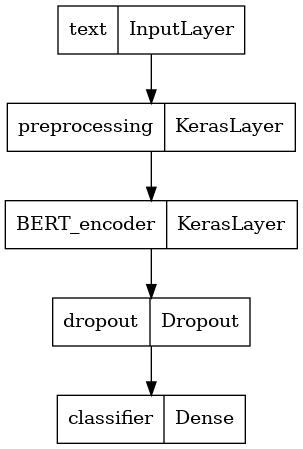
Vous allez créer un modèle affiné très simple, avec le modèle de prétraitement, le modèle BERT sélectionné, une couche Dense et une couche Dropout.
def build_classifier_model():
text_input = tf.keras.layers.Input(shape=(), dtype=tf.string, name='text')
preprocessing_layer = hub.KerasLayer(tfhub_handle_preprocess, name='preprocessing')
encoder_inputs = preprocessing_layer(text_input)
encoder = hub.KerasLayer(tfhub_handle_encoder, trainable=True, name='BERT_encoder')
outputs = encoder(encoder_inputs)
net = outputs['pooled_output']
net = tf.keras.layers.Dropout(0.1)(net)
net = tf.keras.layers.Dense(1, activation=None, name='classifier')(net)
return tf.keras.Model(text_input, net)
Vérifions que le modèle s'exécute avec la sortie du modèle de prétraitement.
classifier_model = build_classifier_model()
bert_raw_result = classifier_model(tf.constant(text_test))
print(tf.sigmoid(bert_raw_result))
tf.Tensor([[0.6749899]], shape=(1, 1), dtype=float32)
La sortie n'a pas de sens, bien sûr, car le modèle n'a pas encore été formé.
Examinons la structure du modèle.
tf.keras.utils.plot_model(classifier_model)
Formation de modèle
Vous disposez maintenant de toutes les pièces pour entraîner un modèle, y compris le module de prétraitement, l'encodeur BERT, les données et le classificateur.
Fonction de perte
Comme il s'agit d' un problème de classification binaire et le modèle génère une probabilité (une seule couche unité), vous utiliserez losses.BinaryCrossentropy fonction de perte.
loss = tf.keras.losses.BinaryCrossentropy(from_logits=True)
metrics = tf.metrics.BinaryAccuracy()
Optimiseur
Pour le réglage fin, utilisons le même optimiseur avec lequel BERT a été formé à l'origine : les " Moments adaptatifs " (Adam). Cet optimiseur minimise la perte de prédiction et fait régularisation par la désintégration de poids (pas en utilisant des moments), qui est également connu sous le nom AdamW .
Pour le taux d'apprentissage ( init_lr ), vous utiliserez le même calendrier que BERT pré-formation: décroissance linéaire d'un taux d'apprentissage théorique initiale, préfixé avec une phase d' échauffement linéaire sur la première tranche de 10% des étapes de formation ( num_warmup_steps ). Conformément à l'article du BERT, le taux d'apprentissage initial est plus faible pour le réglage fin (le meilleur de 5e-5, 3e-5, 2e-5).
epochs = 5
steps_per_epoch = tf.data.experimental.cardinality(train_ds).numpy()
num_train_steps = steps_per_epoch * epochs
num_warmup_steps = int(0.1*num_train_steps)
init_lr = 3e-5
optimizer = optimization.create_optimizer(init_lr=init_lr,
num_train_steps=num_train_steps,
num_warmup_steps=num_warmup_steps,
optimizer_type='adamw')
Chargement du modèle BERT et formation
Utilisation de la classifier_model vous avez créé précédemment, vous pouvez compiler le modèle avec la perte, métrique et optimiseur.
classifier_model.compile(optimizer=optimizer,
loss=loss,
metrics=metrics)
print(f'Training model with {tfhub_handle_encoder}')
history = classifier_model.fit(x=train_ds,
validation_data=val_ds,
epochs=epochs)
Training model with https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Epoch 1/5 625/625 [==============================] - 91s 138ms/step - loss: 0.4776 - binary_accuracy: 0.7513 - val_loss: 0.3791 - val_binary_accuracy: 0.8380 Epoch 2/5 625/625 [==============================] - 85s 136ms/step - loss: 0.3266 - binary_accuracy: 0.8547 - val_loss: 0.3659 - val_binary_accuracy: 0.8486 Epoch 3/5 625/625 [==============================] - 86s 138ms/step - loss: 0.2521 - binary_accuracy: 0.8928 - val_loss: 0.3975 - val_binary_accuracy: 0.8518 Epoch 4/5 625/625 [==============================] - 86s 137ms/step - loss: 0.1910 - binary_accuracy: 0.9269 - val_loss: 0.4180 - val_binary_accuracy: 0.8522 Epoch 5/5 625/625 [==============================] - 86s 137ms/step - loss: 0.1509 - binary_accuracy: 0.9433 - val_loss: 0.4641 - val_binary_accuracy: 0.8522
Évaluer le modèle
Voyons comment le modèle fonctionne. Deux valeurs seront renvoyées. Perte (un nombre qui représente l'erreur, les valeurs inférieures sont meilleures) et la précision.
loss, accuracy = classifier_model.evaluate(test_ds)
print(f'Loss: {loss}')
print(f'Accuracy: {accuracy}')
782/782 [==============================] - 61s 78ms/step - loss: 0.4495 - binary_accuracy: 0.8554 Loss: 0.4494614601135254 Accuracy: 0.8553599715232849
Tracez la précision et la perte au fil du temps
Sur la base de l' History objet retourné par model.fit() . Vous pouvez tracer la perte d'entraînement et de validation à des fins de comparaison, ainsi que la précision d'entraînement et de validation :
history_dict = history.history
print(history_dict.keys())
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
fig = plt.figure(figsize=(10, 6))
fig.tight_layout()
plt.subplot(2, 1, 1)
# r is for "solid red line"
plt.plot(epochs, loss, 'r', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
# plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(epochs, acc, 'r', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy']) <matplotlib.legend.Legend at 0x7fee7cdb4450>

Dans ce graphique, les lignes rouges représentent la perte et la précision de l'entraînement, et les lignes bleues représentent la perte et la précision de validation.
Exporter pour inférence
Il ne vous reste plus qu'à enregistrer votre modèle affiné pour une utilisation ultérieure.
dataset_name = 'imdb'
saved_model_path = './{}_bert'.format(dataset_name.replace('/', '_'))
classifier_model.save(saved_model_path, include_optimizer=False)
2021-12-01 12:26:06.207608: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Found untraced functions such as restored_function_body, restored_function_body, restored_function_body, restored_function_body, restored_function_body while saving (showing 5 of 310). These functions will not be directly callable after loading.
Rechargeons le modèle pour pouvoir l'essayer côte à côte avec le modèle encore en mémoire.
reloaded_model = tf.saved_model.load(saved_model_path)
Ici, vous pouvez tester votre modèle sur n'importe quelle phrase que vous voulez, ajoutez simplement à la variable d'exemples ci-dessous.
def print_my_examples(inputs, results):
result_for_printing = \
[f'input: {inputs[i]:<30} : score: {results[i][0]:.6f}'
for i in range(len(inputs))]
print(*result_for_printing, sep='\n')
print()
examples = [
'this is such an amazing movie!', # this is the same sentence tried earlier
'The movie was great!',
'The movie was meh.',
'The movie was okish.',
'The movie was terrible...'
]
reloaded_results = tf.sigmoid(reloaded_model(tf.constant(examples)))
original_results = tf.sigmoid(classifier_model(tf.constant(examples)))
print('Results from the saved model:')
print_my_examples(examples, reloaded_results)
print('Results from the model in memory:')
print_my_examples(examples, original_results)
Results from the saved model: input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622 Results from the model in memory: input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622
Si vous souhaitez utiliser votre modèle sur Serving TF , rappelez - vous qu'il appellera votre SavedModel par l' une de ses signatures nommées. En Python, vous pouvez les tester comme suit :
serving_results = reloaded_model \
.signatures['serving_default'](tf.constant(examples))
serving_results = tf.sigmoid(serving_results['classifier'])
print_my_examples(examples, serving_results)
input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622
Prochaines étapes
En tant que prochaine étape, vous pouvez résoudre les tâches de l' aide COLLE BERT sur un tutoriel TPU , qui fonctionne sur vous TPU et montre comment travailler avec plusieurs entrées.