
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Ce didacticiel illustre la classification de texte à partir de fichiers de texte brut stockés sur disque. Vous formerez un classificateur binaire pour effectuer une analyse des sentiments sur un ensemble de données IMDB. À la fin du bloc-notes, vous trouverez un exercice à essayer, dans lequel vous apprendrez à un classificateur multiclasse à prédire la balise d'une question de programmation sur Stack Overflow.
import matplotlib.pyplot as plt
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import losses
print(tf.__version__)
2.8.0-rc1
Analyse des sentiments
Ce bloc-notes entraîne un modèle d'analyse des sentiments pour classer les critiques de films comme positives ou négatives , en fonction du texte de la critique. Il s'agit d'un exemple de classification binaire - ou à deux classes -, un type de problème d'apprentissage automatique important et largement applicable.
Vous utiliserez l' ensemble de données Large Movie Review qui contient le texte de 50 000 critiques de films de la base de données de films Internet . Ceux-ci sont divisés en 25 000 avis pour la formation et 25 000 avis pour les tests. Les ensembles de formation et de test sont équilibrés , ce qui signifie qu'ils contiennent un nombre égal d'avis positifs et négatifs.
Téléchargez et explorez le jeu de données IMDB
Téléchargeons et extrayons le jeu de données, puis explorons la structure du répertoire.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 6s 0us/step 84140032/84125825 [==============================] - 6s 0us/step
os.listdir(dataset_dir)
['test', 'README', 'imdbEr.txt', 'imdb.vocab', 'train']
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['neg', 'urls_neg.txt', 'unsup', 'unsupBow.feat', 'urls_unsup.txt', 'urls_pos.txt', 'labeledBow.feat', 'pos']
Les aclImdb/train/pos et aclImdb/train/neg contiennent de nombreux fichiers texte, dont chacun est une critique de film unique. Jetons un coup d'œil à l'un d'eux.
sample_file = os.path.join(train_dir, 'pos/1181_9.txt')
with open(sample_file) as f:
print(f.read())
Rachel Griffiths writes and directs this award winning short film. A heartwarming story about coping with grief and cherishing the memory of those we've loved and lost. Although, only 15 minutes long, Griffiths manages to capture so much emotion and truth onto film in the short space of time. Bud Tingwell gives a touching performance as Will, a widower struggling to cope with his wife's death. Will is confronted by the harsh reality of loneliness and helplessness as he proceeds to take care of Ruth's pet cow, Tulip. The film displays the grief and responsibility one feels for those they have loved and lost. Good cinematography, great direction, and superbly acted. It will bring tears to all those who have lost a loved one, and survived.
Charger le jeu de données
Ensuite, vous allez charger les données hors disque et les préparer dans un format adapté à la formation. Pour ce faire, vous utiliserez l'utilitaire utile text_dataset_from_directory , qui attend une structure de répertoires comme suit.
main_directory/
...class_a/
......a_text_1.txt
......a_text_2.txt
...class_b/
......b_text_1.txt
......b_text_2.txt
Pour préparer un jeu de données pour la classification binaire, vous aurez besoin de deux dossiers sur le disque, correspondant à class_a et class_b . Ce seront les critiques de films positives et négatives, qui peuvent être trouvées dans aclImdb/train/pos et aclImdb/train/neg . Comme l'ensemble de données IMDB contient des dossiers supplémentaires, vous les supprimerez avant d'utiliser cet utilitaire.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Ensuite, vous utiliserez l'utilitaire text_dataset_from_directory pour créer un tf.data.Dataset étiqueté. tf.data est une puissante collection d'outils pour travailler avec des données.
Lors de l'exécution d'une expérience d'apprentissage automatique, il est recommandé de diviser votre ensemble de données en trois parties : train , validation et test .
L'ensemble de données IMDB a déjà été divisé en train et test, mais il manque un ensemble de validation. Créons un ensemble de validation en utilisant une répartition 80:20 des données d'apprentissage en utilisant l'argument validation_split ci-dessous.
batch_size = 32
seed = 42
raw_train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training.
Comme vous pouvez le voir ci-dessus, il y a 25 000 exemples dans le dossier de formation, dont vous utiliserez 80 % (ou 20 000) pour la formation. Comme vous le verrez dans un instant, vous pouvez former un modèle en passant un jeu de données directement à model.fit . Si vous débutez avec tf.data , vous pouvez également parcourir l'ensemble de données et imprimer quelques exemples comme suit.
for text_batch, label_batch in raw_train_ds.take(1):
for i in range(3):
print("Review", text_batch.numpy()[i])
print("Label", label_batch.numpy()[i])
Review b'"Pandemonium" is a horror movie spoof that comes off more stupid than funny. Believe me when I tell you, I love comedies. Especially comedy spoofs. "Airplane", "The Naked Gun" trilogy, "Blazing Saddles", "High Anxiety", and "Spaceballs" are some of my favorite comedies that spoof a particular genre. "Pandemonium" is not up there with those films. Most of the scenes in this movie had me sitting there in stunned silence because the movie wasn\'t all that funny. There are a few laughs in the film, but when you watch a comedy, you expect to laugh a lot more than a few times and that\'s all this film has going for it. Geez, "Scream" had more laughs than this film and that was more of a horror film. How bizarre is that?<br /><br />*1/2 (out of four)' Label 0 Review b"David Mamet is a very interesting and a very un-equal director. His first movie 'House of Games' was the one I liked best, and it set a series of films with characters whose perspective of life changes as they get into complicated situations, and so does the perspective of the viewer.<br /><br />So is 'Homicide' which from the title tries to set the mind of the viewer to the usual crime drama. The principal characters are two cops, one Jewish and one Irish who deal with a racially charged area. The murder of an old Jewish shop owner who proves to be an ancient veteran of the Israeli Independence war triggers the Jewish identity in the mind and heart of the Jewish detective.<br /><br />This is were the flaws of the film are the more obvious. The process of awakening is theatrical and hard to believe, the group of Jewish militants is operatic, and the way the detective eventually walks to the final violent confrontation is pathetic. The end of the film itself is Mamet-like smart, but disappoints from a human emotional perspective.<br /><br />Joe Mantegna and William Macy give strong performances, but the flaws of the story are too evident to be easily compensated." Label 0 Review b'Great documentary about the lives of NY firefighters during the worst terrorist attack of all time.. That reason alone is why this should be a must see collectors item.. What shocked me was not only the attacks, but the"High Fat Diet" and physical appearance of some of these firefighters. I think a lot of Doctors would agree with me that,in the physical shape they were in, some of these firefighters would NOT of made it to the 79th floor carrying over 60 lbs of gear. Having said that i now have a greater respect for firefighters and i realize becoming a firefighter is a life altering job. The French have a history of making great documentary\'s and that is what this is, a Great Documentary.....' Label 1
Notez que les avis contiennent du texte brut (avec ponctuation et balises HTML occasionnelles comme <br/> ). Vous montrerez comment les gérer dans la section suivante.
Les étiquettes sont 0 ou 1. Pour voir lesquelles correspondent à des critiques de films positives et négatives, vous pouvez vérifier la propriété class_names sur l'ensemble de données.
print("Label 0 corresponds to", raw_train_ds.class_names[0])
print("Label 1 corresponds to", raw_train_ds.class_names[1])
Label 0 corresponds to neg Label 1 corresponds to pos
Ensuite, vous allez créer un jeu de données de validation et de test. Vous utiliserez les 5 000 avis restants de l'ensemble de formation pour validation.
raw_val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
Found 25000 files belonging to 2 classes. Using 5000 files for validation.
raw_test_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
Found 25000 files belonging to 2 classes.
Préparer l'ensemble de données pour la formation
Ensuite, vous allez standardiser, tokeniser et vectoriser les données à l'aide de la couche utile tf.keras.layers.TextVectorization .
La normalisation fait référence au prétraitement du texte, généralement pour supprimer la ponctuation ou les éléments HTML afin de simplifier l'ensemble de données. La tokenisation fait référence à la division de chaînes en jetons (par exemple, la division d'une phrase en mots individuels, en la divisant sur des espaces). La vectorisation fait référence à la conversion de jetons en nombres afin qu'ils puissent être introduits dans un réseau de neurones. Toutes ces tâches peuvent être accomplies avec cette couche.
Comme vous l'avez vu ci-dessus, les avis contiennent diverses balises HTML comme <br /> . Ces balises ne seront pas supprimées par le standardiseur par défaut dans la couche TextVectorization (qui convertit le texte en minuscules et supprime la ponctuation par défaut, mais ne supprime pas le HTML). Vous écrirez une fonction de standardisation personnalisée pour supprimer le code HTML.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation),
'')
Ensuite, vous allez créer un calque TextVectorization . Vous utiliserez cette couche pour standardiser, tokeniser et vectoriser nos données. Vous définissez output_mode sur int pour créer des index entiers uniques pour chaque jeton.
Notez que vous utilisez la fonction de fractionnement par défaut et la fonction de normalisation personnalisée que vous avez définie ci-dessus. Vous définirez également certaines constantes pour le modèle, comme une sequence_length maximale explicite, qui amènera la couche à remplir ou tronquer les séquences à des valeurs exactes de sequence_length .
max_features = 10000
sequence_length = 250
vectorize_layer = layers.TextVectorization(
standardize=custom_standardization,
max_tokens=max_features,
output_mode='int',
output_sequence_length=sequence_length)
Ensuite, vous appellerez adapt pour adapter l'état de la couche de prétraitement à l'ensemble de données. Cela amènera le modèle à construire un index de chaînes en nombres entiers.
# Make a text-only dataset (without labels), then call adapt
train_text = raw_train_ds.map(lambda x, y: x)
vectorize_layer.adapt(train_text)
Créons une fonction pour voir le résultat de l'utilisation de cette couche pour prétraiter certaines données.
def vectorize_text(text, label):
text = tf.expand_dims(text, -1)
return vectorize_layer(text), label
# retrieve a batch (of 32 reviews and labels) from the dataset
text_batch, label_batch = next(iter(raw_train_ds))
first_review, first_label = text_batch[0], label_batch[0]
print("Review", first_review)
print("Label", raw_train_ds.class_names[first_label])
print("Vectorized review", vectorize_text(first_review, first_label))
Review tf.Tensor(b'Great movie - especially the music - Etta James - "At Last". This speaks volumes when you have finally found that special someone.', shape=(), dtype=string)
Label neg
Vectorized review (<tf.Tensor: shape=(1, 250), dtype=int64, numpy=
array([[ 86, 17, 260, 2, 222, 1, 571, 31, 229, 11, 2418,
1, 51, 22, 25, 404, 251, 12, 306, 282, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]])>, <tf.Tensor: shape=(), dtype=int32, numpy=0>)
Comme vous pouvez le voir ci-dessus, chaque jeton a été remplacé par un entier. Vous pouvez rechercher le jeton (chaîne) auquel correspond chaque entier en appelant .get_vocabulary() sur la couche.
print("1287 ---> ",vectorize_layer.get_vocabulary()[1287])
print(" 313 ---> ",vectorize_layer.get_vocabulary()[313])
print('Vocabulary size: {}'.format(len(vectorize_layer.get_vocabulary())))
1287 ---> silent 313 ---> night Vocabulary size: 10000
Vous êtes presque prêt à former votre modèle. En tant qu'étape finale de prétraitement, vous appliquerez la couche TextVectorization que vous avez créée précédemment à l'ensemble de données d'entraînement, de validation et de test.
train_ds = raw_train_ds.map(vectorize_text)
val_ds = raw_val_ds.map(vectorize_text)
test_ds = raw_test_ds.map(vectorize_text)
Configurer l'ensemble de données pour les performances
Ce sont deux méthodes importantes que vous devez utiliser lors du chargement des données pour vous assurer que les E/S ne deviennent pas bloquantes.
.cache() conserve les données en mémoire après leur chargement sur le disque. Cela garantira que l'ensemble de données ne devienne pas un goulot d'étranglement lors de la formation de votre modèle. Si votre jeu de données est trop volumineux pour tenir en mémoire, vous pouvez également utiliser cette méthode pour créer un cache sur disque performant, plus efficace à lire que de nombreux petits fichiers.
.prefetch() chevauche le prétraitement des données et l'exécution du modèle pendant la formation.
Vous pouvez en savoir plus sur les deux méthodes, ainsi que sur la mise en cache des données sur le disque dans le guide des performances des données .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
Créer le modèle
Il est temps de créer votre réseau de neurones :
embedding_dim = 16
model = tf.keras.Sequential([
layers.Embedding(max_features + 1, embedding_dim),
layers.Dropout(0.2),
layers.GlobalAveragePooling1D(),
layers.Dropout(0.2),
layers.Dense(1)])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 16) 160016
dropout (Dropout) (None, None, 16) 0
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dropout_1 (Dropout) (None, 16) 0
dense (Dense) (None, 1) 17
=================================================================
Total params: 160,033
Trainable params: 160,033
Non-trainable params: 0
_________________________________________________________________
Les couches sont empilées séquentiellement pour construire le classifieur :
- La première couche est une couche d'
Embedding. Cette couche prend les révisions codées en nombres entiers et recherche un vecteur d'intégration pour chaque index de mots. Ces vecteurs sont appris au fur et à mesure que le modèle s'entraîne. Les vecteurs ajoutent une dimension au tableau de sortie. Les dimensions résultantes sont :(batch, sequence, embedding). Pour en savoir plus sur les intégrations, consultez le didacticiel sur l'intégration de mots . - Ensuite, une couche
GlobalAveragePooling1Drenvoie un vecteur de sortie de longueur fixe pour chaque exemple en faisant la moyenne sur la dimension de la séquence. Cela permet au modèle de gérer des entrées de longueur variable, de la manière la plus simple possible. - Ce vecteur de sortie de longueur fixe est acheminé via une couche entièrement connectée (
Dense) avec 16 unités cachées. - La dernière couche est densément connectée à un seul nœud de sortie.
Fonction de perte et optimiseur
Un modèle a besoin d'une fonction de perte et d'un optimiseur pour la formation. Puisqu'il s'agit d'un problème de classification binaire et que le modèle génère une probabilité (une couche à une seule unité avec une activation sigmoïde), vous utiliserez la fonction losses.BinaryCrossentropy loss.
Maintenant, configurez le modèle pour utiliser un optimiseur et une fonction de perte :
model.compile(loss=losses.BinaryCrossentropy(from_logits=True),
optimizer='adam',
metrics=tf.metrics.BinaryAccuracy(threshold=0.0))
Former le modèle
Vous entraînerez le modèle en transmettant l'objet de l'ensemble de dataset à la méthode d'ajustement.
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs)
Epoch 1/10 625/625 [==============================] - 4s 4ms/step - loss: 0.6644 - binary_accuracy: 0.6894 - val_loss: 0.6159 - val_binary_accuracy: 0.7696 Epoch 2/10 625/625 [==============================] - 2s 4ms/step - loss: 0.5494 - binary_accuracy: 0.8020 - val_loss: 0.4993 - val_binary_accuracy: 0.8226 Epoch 3/10 625/625 [==============================] - 2s 3ms/step - loss: 0.4450 - binary_accuracy: 0.8447 - val_loss: 0.4205 - val_binary_accuracy: 0.8466 Epoch 4/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3778 - binary_accuracy: 0.8659 - val_loss: 0.3740 - val_binary_accuracy: 0.8618 Epoch 5/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3357 - binary_accuracy: 0.8785 - val_loss: 0.3451 - val_binary_accuracy: 0.8678 Epoch 6/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3055 - binary_accuracy: 0.8885 - val_loss: 0.3260 - val_binary_accuracy: 0.8700 Epoch 7/10 625/625 [==============================] - 2s 3ms/step - loss: 0.2817 - binary_accuracy: 0.8971 - val_loss: 0.3126 - val_binary_accuracy: 0.8730 Epoch 8/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2616 - binary_accuracy: 0.9034 - val_loss: 0.3037 - val_binary_accuracy: 0.8754 Epoch 9/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2458 - binary_accuracy: 0.9110 - val_loss: 0.2965 - val_binary_accuracy: 0.8788 Epoch 10/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2319 - binary_accuracy: 0.9158 - val_loss: 0.2920 - val_binary_accuracy: 0.8792
Évaluer le modèle
Voyons comment le modèle fonctionne. Deux valeurs seront renvoyées. Perte (un nombre qui représente notre erreur, les valeurs inférieures sont meilleures) et précision.
loss, accuracy = model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
782/782 [==============================] - 2s 2ms/step - loss: 0.3104 - binary_accuracy: 0.8735 Loss: 0.3104138672351837 Accuracy: 0.873520016670227
Cette approche assez naïve permet d'atteindre une précision d'environ 86 %.
Créer un graphique de précision et de perte au fil du temps
model.fit() renvoie un objet History qui contient un dictionnaire avec tout ce qui s'est passé pendant l'entraînement :
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy'])
Il y a quatre entrées : une pour chaque métrique surveillée pendant la formation et la validation. Vous pouvez les utiliser pour tracer la perte de formation et de validation à des fins de comparaison, ainsi que la précision de la formation et de la validation :
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
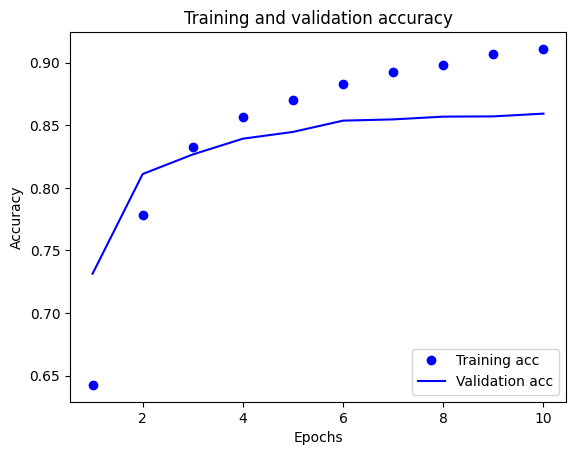
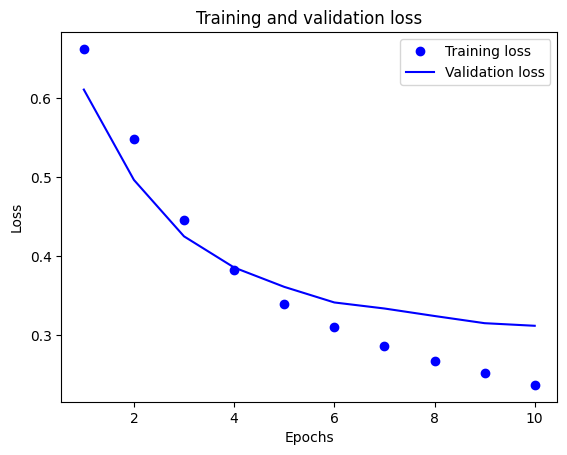
Dans ce graphique, les points représentent la perte d'apprentissage et la précision, et les lignes pleines représentent la perte de validation et la précision.
Notez que la perte d'entraînement diminue à chaque époque et que la précision de l'entraînement augmente à chaque époque. Ceci est attendu lors de l'utilisation d'une optimisation de descente de gradient - elle doit minimiser la quantité souhaitée à chaque itération.
Ce n'est pas le cas pour la perte de validation et la précision - elles semblent culminer avant la précision de la formation. Ceci est un exemple de surajustement : le modèle fonctionne mieux sur les données d'apprentissage que sur des données qu'il n'a jamais vues auparavant. Après ce point, le modèle sur-optimise et apprend des représentations spécifiques aux données d'apprentissage qui ne se généralisent pas aux données de test.
Dans ce cas particulier, vous pouvez éviter le surajustement en arrêtant simplement l'entraînement lorsque la précision de la validation n'augmente plus. Une façon de le faire est d'utiliser le rappel tf.keras.callbacks.EarlyStopping .
Exporter le modèle
Dans le code ci-dessus, vous avez appliqué la couche TextVectorization au jeu de données avant d'alimenter le modèle en texte. Si vous souhaitez rendre votre modèle capable de traiter des chaînes brutes (par exemple, pour simplifier son déploiement), vous pouvez inclure la couche TextVectorization dans votre modèle. Pour ce faire, vous pouvez créer un nouveau modèle en utilisant les poids que vous venez d'entraîner.
export_model = tf.keras.Sequential([
vectorize_layer,
model,
layers.Activation('sigmoid')
])
export_model.compile(
loss=losses.BinaryCrossentropy(from_logits=False), optimizer="adam", metrics=['accuracy']
)
# Test it with `raw_test_ds`, which yields raw strings
loss, accuracy = export_model.evaluate(raw_test_ds)
print(accuracy)
782/782 [==============================] - 3s 4ms/step - loss: 0.3104 - accuracy: 0.8735 0.873520016670227
Inférence sur de nouvelles données
Pour obtenir des prédictions pour de nouveaux exemples, vous pouvez simplement appeler model.predict() .
examples = [
"The movie was great!",
"The movie was okay.",
"The movie was terrible..."
]
export_model.predict(examples)
array([[0.60320234],
[0.4262717 ],
[0.34439093]], dtype=float32)
L'inclusion de la logique de prétraitement du texte dans votre modèle vous permet d'exporter un modèle pour la production, ce qui simplifie le déploiement et réduit le potentiel d' apprentissage/test de biais .
Il y a une différence de performances à garder à l'esprit lorsque vous choisissez où appliquer votre couche TextVectorization. L'utiliser en dehors de votre modèle vous permet d'effectuer un traitement CPU asynchrone et une mise en mémoire tampon de vos données lors de l'entraînement sur GPU. Donc, si vous formez votre modèle sur le GPU, vous voudrez probablement utiliser cette option pour obtenir les meilleures performances lors du développement de votre modèle, puis passez à l'inclusion de la couche TextVectorization dans votre modèle lorsque vous êtes prêt à préparer le déploiement. .
Consultez ce didacticiel pour en savoir plus sur l'enregistrement de modèles.
Exercice : classification multi-classes sur les questions Stack Overflow
Ce didacticiel a montré comment former un classificateur binaire à partir de zéro sur le jeu de données IMDB. En tant qu'exercice, vous pouvez modifier ce bloc-notes pour entraîner un classifieur multiclasse à prédire la balise d'une question de programmation sur Stack Overflow .
Un ensemble de données a été préparé pour vous, contenant le corps de plusieurs milliers de questions de programmation (par exemple, "Comment puis-je trier un dictionnaire par valeur en Python ?") Posté sur Stack Overflow. Chacun d'eux est étiqueté avec exactement une balise (soit Python, CSharp, JavaScript ou Java). Votre tâche consiste à prendre une question en entrée et à prédire la balise appropriée, dans ce cas, Python.
L'ensemble de données avec lequel vous travaillerez contient plusieurs milliers de questions extraites de l'ensemble de données public Stack Overflow beaucoup plus vaste sur BigQuery , qui contient plus de 17 millions de publications.
Après avoir téléchargé l'ensemble de données, vous constaterez qu'il a une structure de répertoire similaire à l'ensemble de données IMDB avec lequel vous avez travaillé précédemment :
train/
...python/
......0.txt
......1.txt
...javascript/
......0.txt
......1.txt
...csharp/
......0.txt
......1.txt
...java/
......0.txt
......1.txt
Pour terminer cet exercice, vous devez modifier ce bloc-notes pour qu'il fonctionne avec l'ensemble de données Stack Overflow en apportant les modifications suivantes :
En haut de votre bloc-notes, mettez à jour le code qui télécharge l'ensemble de données IMDB avec le code pour télécharger l'ensemble de données Stack Overflow qui a déjà été préparé. Comme l'ensemble de données Stack Overflow a une structure de répertoires similaire, vous n'aurez pas besoin d'apporter de nombreuses modifications.
Modifiez la dernière couche de votre modèle en
Dense(4), car il existe désormais quatre classes de sortie.Lors de la compilation du modèle, remplacez la perte par
tf.keras.losses.SparseCategoricalCrossentropy. Il s'agit de la fonction de perte correcte à utiliser pour un problème de classification multi-classes, lorsque les étiquettes de chaque classe sont des nombres entiers (dans ce cas, elles peuvent être 0, 1 , 2 ou 3 ). De plus, modifiez les métriques enmetrics=['accuracy'], car il s'agit d'un problème de classification multi-classes (tf.metrics.BinaryAccuracyn'est utilisé que pour les classificateurs binaires).Lors du traçage de la précision dans le temps, remplacez
binary_accuracyetval_binary_accuracyparaccuracyetval_accuracy, respectivement.Une fois ces modifications effectuées, vous pourrez former un classifieur multi-classes.
Apprendre plus
Ce didacticiel a introduit la classification de texte à partir de zéro. Pour en savoir plus sur le flux de travail de classification de texte en général, consultez le guide de classification de texte de Google Developers.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.