
| | |  Voir la source sur GitHub Voir la source sur GitHub |
L'API tf.data vous permet de créer des pipelines d'entrée complexes à partir de pièces simples et réutilisables. Par exemple, le pipeline d'un modèle d'image peut agréger des données à partir de fichiers dans un système de fichiers distribué, appliquer des perturbations aléatoires à chaque image et fusionner des images sélectionnées au hasard dans un lot pour la formation. Le pipeline d'un modèle de texte peut impliquer l'extraction de symboles à partir de données textuelles brutes, leur conversion en identifiants intégrés avec une table de recherche et le regroupement de séquences de différentes longueurs. L'API tf.data permet de gérer de grandes quantités de données, de lire à partir de différents formats de données et d'effectuer des transformations complexes.
L'API tf.data introduit une abstraction tf.data.Dataset qui représente une séquence d'éléments, dans laquelle chaque élément se compose d'un ou plusieurs composants. Par exemple, dans un pipeline d'images, un élément peut être un exemple d'apprentissage unique, avec une paire de composants tensoriels représentant l'image et son étiquette.
Il existe deux manières distinctes de créer un jeu de données :
Une source de données construit un
Datasetà partir de données stockées en mémoire ou dans un ou plusieurs fichiers.Une transformation de données construit un ensemble de données à partir d'un ou plusieurs objets
tf.data.Dataset.
import tensorflow as tf
import pathlib
import os
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
np.set_printoptions(precision=4)
Mécanique de base
Pour créer un pipeline d'entrée, vous devez commencer par une source de données . Par exemple, pour construire un Dataset à partir de données en mémoire, vous pouvez utiliser tf.data.Dataset.from_tensors() ou tf.data.Dataset.from_tensor_slices() . Alternativement, si vos données d'entrée sont stockées dans un fichier au format TFRecord recommandé, vous pouvez utiliser tf.data.TFRecordDataset() .
Une fois que vous avez un objet Dataset , vous pouvez le transformer en un nouveau Dataset en enchaînant les appels de méthode sur l'objet tf.data.Dataset . Par exemple, vous pouvez appliquer des transformations par élément telles que Dataset.map() et des transformations multi-éléments telles que Dataset.batch() . Voir la documentation de tf.data.Dataset pour une liste complète des transformations.
L'objet Dataset est un itérable Python. Cela permet de consommer ses éléments à l'aide d'une boucle for :
dataset = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1])
dataset
<TensorSliceDataset element_spec=TensorSpec(shape=(), dtype=tf.int32, name=None)>
for elem in dataset:
print(elem.numpy())
8 3 0 8 2 1
Ou en créant explicitement un itérateur Python en utilisant iter et en consommant ses éléments en utilisant next :
it = iter(dataset)
print(next(it).numpy())
8
Alternativement, les éléments de l'ensemble de données peuvent être consommés à l'aide de la transformation de reduce , qui réduit tous les éléments pour produire un seul résultat. L'exemple suivant illustre comment utiliser la transformation de reduce pour calculer la somme d'un ensemble de données d'entiers.
print(dataset.reduce(0, lambda state, value: state + value).numpy())
22
Structure du jeu de données
Un jeu de données produit une séquence d' éléments , où chaque élément est la même structure (imbriquée) de composants . Les composants individuels de la structure peuvent être de n'importe quel type représentable par tf.TypeSpec , y compris tf.Tensor , tf.sparse.SparseTensor , tf.RaggedTensor , tf.TensorArray ou tf.data.Dataset .
Les constructions Python pouvant être utilisées pour exprimer la structure (imbriquée) des éléments incluent tuple , dict , NamedTuple et OrderedDict . En particulier, la list n'est pas une construction valide pour exprimer la structure des éléments d'un ensemble de données. Cela est dû au fait que les premiers utilisateurs de tf.data étaient très attachés au fait que les entrées de list (par exemple, transmises à tf.data.Dataset.from_tensors ) étaient automatiquement emballées sous forme de tenseurs et que les sorties de list (par exemple, les valeurs de retour des fonctions définies par l'utilisateur) étaient contraintes dans un tuple . Par conséquent, si vous souhaitez qu'une entrée de list soit traitée comme une structure, vous devez la convertir en tuple et si vous souhaitez qu'une sortie de list soit un composant unique, vous devez alors l'emballer explicitement à l'aide tf.stack .
La propriété Dataset.element_spec vous permet d'inspecter le type de chaque composant d'élément. La propriété renvoie une structure imbriquée d'objets tf.TypeSpec , correspondant à la structure de l'élément, qui peut être un composant unique, un tuple de composants ou un tuple imbriqué de composants. Par example:
dataset1 = tf.data.Dataset.from_tensor_slices(tf.random.uniform([4, 10]))
dataset1.element_spec
TensorSpec(shape=(10,), dtype=tf.float32, name=None)
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2.element_spec
(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3.element_spec
(TensorSpec(shape=(10,), dtype=tf.float32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))
# Dataset containing a sparse tensor.
dataset4 = tf.data.Dataset.from_tensors(tf.SparseTensor(indices=[[0, 0], [1, 2]], values=[1, 2], dense_shape=[3, 4]))
dataset4.element_spec
SparseTensorSpec(TensorShape([3, 4]), tf.int32)
# Use value_type to see the type of value represented by the element spec
dataset4.element_spec.value_type
tensorflow.python.framework.sparse_tensor.SparseTensor
Les Dataset de jeu de données prennent en charge les jeux de données de n'importe quelle structure. Lors de l'utilisation des Dataset.map() et Dataset.filter() , qui appliquent une fonction à chaque élément, la structure de l'élément détermine les arguments de la fonction :
dataset1 = tf.data.Dataset.from_tensor_slices(
tf.random.uniform([4, 10], minval=1, maxval=10, dtype=tf.int32))
dataset1
<TensorSliceDataset element_spec=TensorSpec(shape=(10,), dtype=tf.int32, name=None)>
for z in dataset1:
print(z.numpy())
[3 3 7 5 9 8 4 2 3 7] [8 9 6 7 5 6 1 6 2 3] [9 8 4 4 8 7 1 5 6 7] [5 9 5 4 2 5 7 8 8 8]
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2
<TensorSliceDataset element_spec=(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))>
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3
<ZipDataset element_spec=(TensorSpec(shape=(10,), dtype=tf.int32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))>
for a, (b,c) in dataset3:
print('shapes: {a.shape}, {b.shape}, {c.shape}'.format(a=a, b=b, c=c))
shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,)
Lecture des données d'entrée
Consommer des tableaux NumPy
Voir Chargement de tableaux NumPy pour plus d'exemples.
Si toutes vos données d'entrée tiennent en mémoire, le moyen le plus simple de créer un Dataset à partir de celles-ci est de les convertir en objets tf.Tensor et d'utiliser Dataset.from_tensor_slices() .
train, test = tf.keras.datasets.fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step 40960/29515 [=========================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step 26435584/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 16384/5148 [===============================================================================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step 4431872/4422102 [==============================] - 0s 0us/step
images, labels = train
images = images/255
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
dataset
<TensorSliceDataset element_spec=(TensorSpec(shape=(28, 28), dtype=tf.float64, name=None), TensorSpec(shape=(), dtype=tf.uint8, name=None))>
Consommer des générateurs Python
Une autre source de données courante qui peut facilement être ingérée en tant que tf.data.Dataset est le générateur python.
def count(stop):
i = 0
while i<stop:
yield i
i += 1
for n in count(5):
print(n)
0 1 2 3 4
Le constructeur Dataset.from_generator convertit le générateur python en un tf.data.Dataset entièrement fonctionnel.
Le constructeur prend un appelable en entrée, pas un itérateur. Cela lui permet de redémarrer le générateur lorsqu'il atteint la fin. Il prend un argument facultatif args , qui est passé comme arguments de l'appelable.
L'argument output_types est requis car tf.data construit un tf.Graph interne et les bords du graphe nécessitent un tf.dtype .
ds_counter = tf.data.Dataset.from_generator(count, args=[25], output_types=tf.int32, output_shapes = (), )
for count_batch in ds_counter.repeat().batch(10).take(10):
print(count_batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] [0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24]
L'argument output_shapes n'est pas obligatoire mais est fortement recommandé car de nombreuses opérations TensorFlow ne prennent pas en charge les tenseurs avec un rang inconnu. Si la longueur d'un axe particulier est inconnue ou variable, définissez-la sur None dans output_shapes .
Il est également important de noter que les output_shapes et output_types suivent les mêmes règles d'imbrication que les autres méthodes d'ensemble de données.
Voici un exemple de générateur qui illustre les deux aspects, il renvoie des tuples de tableaux, où le deuxième tableau est un vecteur de longueur inconnue.
def gen_series():
i = 0
while True:
size = np.random.randint(0, 10)
yield i, np.random.normal(size=(size,))
i += 1
for i, series in gen_series():
print(i, ":", str(series))
if i > 5:
break
0 : [0.3939] 1 : [ 0.9282 -0.0158 1.0096 0.7155 0.0491 0.6697 -0.2565 0.487 ] 2 : [-0.4831 0.37 -1.3918 -0.4786 0.7425 -0.3299] 3 : [ 0.1427 -1.0438 0.821 -0.8766 -0.8369 0.4168] 4 : [-1.4984 -1.8424 0.0337 0.0941 1.3286 -1.4938] 5 : [-1.3158 -1.2102 2.6887 -1.2809] 6 : []
La première sortie est un int32 la seconde est un float32 .
Le premier élément est un scalaire, shape () , et le second est un vecteur de longueur inconnue, shape (None,)
ds_series = tf.data.Dataset.from_generator(
gen_series,
output_types=(tf.int32, tf.float32),
output_shapes=((), (None,)))
ds_series
<FlatMapDataset element_spec=(TensorSpec(shape=(), dtype=tf.int32, name=None), TensorSpec(shape=(None,), dtype=tf.float32, name=None))>
Maintenant, il peut être utilisé comme un tf.data.Dataset normal. Notez que lorsque vous regroupez un ensemble de données avec une forme variable, vous devez utiliser Dataset.padded_batch .
ds_series_batch = ds_series.shuffle(20).padded_batch(10)
ids, sequence_batch = next(iter(ds_series_batch))
print(ids.numpy())
print()
print(sequence_batch.numpy())
[ 8 10 18 1 5 19 22 17 21 25] [[-0.6098 0.1366 -2.15 -0.9329 0. 0. ] [ 1.0295 -0.033 -0.0388 0. 0. 0. ] [-0.1137 0.3552 0.4363 -0.2487 -1.1329 0. ] [ 0. 0. 0. 0. 0. 0. ] [-1.0466 0.624 -1.7705 1.4214 0.9143 -0.62 ] [-0.9502 1.7256 0.5895 0.7237 1.5397 0. ] [ 0.3747 1.2967 0. 0. 0. 0. ] [-0.4839 0.292 -0.7909 -0.7535 0.4591 -1.3952] [-0.0468 0.0039 -1.1185 -1.294 0. 0. ] [-0.1679 -0.3375 0. 0. 0. 0. ]]
Pour un exemple plus réaliste, essayez d'envelopper preprocessing.image.ImageDataGenerator en tant que tf.data.Dataset .
Téléchargez d'abord les données :
flowers = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz 228818944/228813984 [==============================] - 10s 0us/step 228827136/228813984 [==============================] - 10s 0us/step
Créer l' image.ImageDataGenerator
img_gen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255, rotation_range=20)
images, labels = next(img_gen.flow_from_directory(flowers))
Found 3670 images belonging to 5 classes.
print(images.dtype, images.shape)
print(labels.dtype, labels.shape)
float32 (32, 256, 256, 3) float32 (32, 5)
ds = tf.data.Dataset.from_generator(
lambda: img_gen.flow_from_directory(flowers),
output_types=(tf.float32, tf.float32),
output_shapes=([32,256,256,3], [32,5])
)
ds.element_spec
(TensorSpec(shape=(32, 256, 256, 3), dtype=tf.float32, name=None), TensorSpec(shape=(32, 5), dtype=tf.float32, name=None))
for images, label in ds.take(1):
print('images.shape: ', images.shape)
print('labels.shape: ', labels.shape)
Found 3670 images belonging to 5 classes. images.shape: (32, 256, 256, 3) labels.shape: (32, 5)
Consommer des données TFRecord
Voir Chargement de TFRecords pour un exemple de bout en bout.
L'API tf.data prend en charge une variété de formats de fichiers afin que vous puissiez traiter de grands ensembles de données qui ne tiennent pas en mémoire. Par exemple, le format de fichier TFRecord est un simple format binaire orienté enregistrement que de nombreuses applications TensorFlow utilisent pour les données de formation. La classe tf.data.TFRecordDataset vous permet de diffuser le contenu d'un ou plusieurs fichiers TFRecord dans le cadre d'un pipeline d'entrée.
Voici un exemple utilisant le fichier de test du FSNS.
# Creates a dataset that reads all of the examples from two files.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001 7905280/7904079 [==============================] - 1s 0us/step 7913472/7904079 [==============================] - 1s 0us/step
L'argument filenames de l'initialiseur TFRecordDataset peut être une chaîne, une liste de chaînes ou un tf.Tensor de chaînes. Par conséquent, si vous avez deux ensembles de fichiers à des fins de formation et de validation, vous pouvez créer une méthode de fabrique qui produit l'ensemble de données, en prenant les noms de fichiers comme argument d'entrée :
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
De nombreux projets TensorFlow utilisent des enregistrements tf.train.Example sérialisés dans leurs fichiers TFRecord. Ceux-ci doivent être décodés avant de pouvoir être inspectés :
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
parsed.features.feature['image/text']
bytes_list {
value: "Rue Perreyon"
}
Consommer des données textuelles
Voir Chargement de texte pour un exemple de bout en bout.
De nombreux ensembles de données sont distribués sous la forme d'un ou de plusieurs fichiers texte. Le tf.data.TextLineDataset fournit un moyen simple d'extraire des lignes d'un ou plusieurs fichiers texte. Étant donné un ou plusieurs noms de fichiers, un TextLineDataset produira un élément de valeur chaîne par ligne de ces fichiers.
directory_url = 'https://storage.googleapis.com/download.tensorflow.org/data/illiad/'
file_names = ['cowper.txt', 'derby.txt', 'butler.txt']
file_paths = [
tf.keras.utils.get_file(file_name, directory_url + file_name)
for file_name in file_names
]
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/cowper.txt 819200/815980 [==============================] - 0s 0us/step 827392/815980 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/derby.txt 811008/809730 [==============================] - 0s 0us/step 819200/809730 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/butler.txt 811008/807992 [==============================] - 0s 0us/step 819200/807992 [==============================] - 0s 0us/step
dataset = tf.data.TextLineDataset(file_paths)
Voici les premières lignes du premier fichier :
for line in dataset.take(5):
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b'His wrath pernicious, who ten thousand woes' b"Caused to Achaia's host, sent many a soul" b'Illustrious into Ades premature,' b'And Heroes gave (so stood the will of Jove)'
Pour alterner les lignes entre les fichiers, utilisez Dataset.interleave . Cela facilite le mélange de fichiers. Voici les première, deuxième et troisième lignes de chaque traduction :
files_ds = tf.data.Dataset.from_tensor_slices(file_paths)
lines_ds = files_ds.interleave(tf.data.TextLineDataset, cycle_length=3)
for i, line in enumerate(lines_ds.take(9)):
if i % 3 == 0:
print()
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b"\xef\xbb\xbfOf Peleus' son, Achilles, sing, O Muse," b'\xef\xbb\xbfSing, O goddess, the anger of Achilles son of Peleus, that brought' b'His wrath pernicious, who ten thousand woes' b'The vengeance, deep and deadly; whence to Greece' b'countless ills upon the Achaeans. Many a brave soul did it send' b"Caused to Achaia's host, sent many a soul" b'Unnumbered ills arose; which many a soul' b'hurrying down to Hades, and many a hero did it yield a prey to dogs and'
Par défaut, un TextLineDataset produit chaque ligne de chaque fichier, ce qui peut ne pas être souhaitable, par exemple, si le fichier commence par une ligne d'en-tête ou contient des commentaires. Ces lignes peuvent être supprimées à l'aide des Dataset.skip() ou Dataset.filter() . Ici, vous sautez la première ligne, puis filtrez pour ne trouver que les survivants.
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
for line in titanic_lines.take(10):
print(line.numpy())
b'survived,sex,age,n_siblings_spouses,parch,fare,class,deck,embark_town,alone' b'0,male,22.0,1,0,7.25,Third,unknown,Southampton,n' b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'0,male,28.0,0,0,8.4583,Third,unknown,Queenstown,y' b'0,male,2.0,3,1,21.075,Third,unknown,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n'
def survived(line):
return tf.not_equal(tf.strings.substr(line, 0, 1), "0")
survivors = titanic_lines.skip(1).filter(survived)
for line in survivors.take(10):
print(line.numpy())
b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n' b'1,male,28.0,0,0,13.0,Second,unknown,Southampton,y' b'1,female,28.0,0,0,7.225,Third,unknown,Cherbourg,y' b'1,male,28.0,0,0,35.5,First,A,Southampton,y' b'1,female,38.0,1,5,31.3875,Third,unknown,Southampton,n'
Consommer des données CSV
Voir Loading CSV Files et Loading Pandas DataFrames pour plus d'exemples.
Le format de fichier CSV est un format populaire pour stocker des données tabulaires en texte brut.
Par example:
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
df = pd.read_csv(titanic_file)
df.head()
Si vos données tiennent en mémoire, la même méthode Dataset.from_tensor_slices fonctionne sur les dictionnaires, ce qui permet d'importer facilement ces données :
titanic_slices = tf.data.Dataset.from_tensor_slices(dict(df))
for feature_batch in titanic_slices.take(1):
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived' : 0 'sex' : b'male' 'age' : 22.0 'n_siblings_spouses': 1 'parch' : 0 'fare' : 7.25 'class' : b'Third' 'deck' : b'unknown' 'embark_town' : b'Southampton' 'alone' : b'n'
Une approche plus évolutive consiste à charger à partir du disque si nécessaire.
Le module tf.data fournit des méthodes pour extraire des enregistrements d'un ou plusieurs fichiers CSV conformes à la RFC 4180 .
La fonction experimental.make_csv_dataset est l'interface de haut niveau pour lire des ensembles de fichiers csv. Il prend en charge l'inférence de type de colonne et de nombreuses autres fonctionnalités, telles que le traitement par lots et le brassage, pour simplifier l'utilisation.
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived")
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
print("features:")
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [1 0 0 0] features: 'sex' : [b'female' b'female' b'male' b'male'] 'age' : [32. 28. 37. 50.] 'n_siblings_spouses': [0 3 0 0] 'parch' : [0 1 1 0] 'fare' : [13. 25.4667 29.7 13. ] 'class' : [b'Second' b'Third' b'First' b'Second'] 'deck' : [b'unknown' b'unknown' b'C' b'unknown'] 'embark_town' : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton'] 'alone' : [b'y' b'n' b'n' b'y']
Vous pouvez utiliser l'argument select_columns si vous n'avez besoin que d'un sous-ensemble de colonnes.
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived", select_columns=['class', 'fare', 'survived'])
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [0 1 1 0] 'fare' : [ 7.05 15.5 26.25 8.05] 'class' : [b'Third' b'Third' b'Second' b'Third']
Il existe également une classe experimental.CsvDataset de niveau inférieur qui fournit un contrôle plus fin. Il ne prend pas en charge l'inférence de type de colonne. Au lieu de cela, vous devez spécifier le type de chaque colonne.
titanic_types = [tf.int32, tf.string, tf.float32, tf.int32, tf.int32, tf.float32, tf.string, tf.string, tf.string, tf.string]
dataset = tf.data.experimental.CsvDataset(titanic_file, titanic_types , header=True)
for line in dataset.take(10):
print([item.numpy() for item in line])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 38.0, 1, 0, 71.2833, b'First', b'C', b'Cherbourg', b'n'] [1, b'female', 26.0, 0, 0, 7.925, b'Third', b'unknown', b'Southampton', b'y'] [1, b'female', 35.0, 1, 0, 53.1, b'First', b'C', b'Southampton', b'n'] [0, b'male', 28.0, 0, 0, 8.4583, b'Third', b'unknown', b'Queenstown', b'y'] [0, b'male', 2.0, 3, 1, 21.075, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 27.0, 0, 2, 11.1333, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 14.0, 1, 0, 30.0708, b'Second', b'unknown', b'Cherbourg', b'n'] [1, b'female', 4.0, 1, 1, 16.7, b'Third', b'G', b'Southampton', b'n'] [0, b'male', 20.0, 0, 0, 8.05, b'Third', b'unknown', b'Southampton', b'y']
Si certaines colonnes sont vides, cette interface de bas niveau vous permet de fournir des valeurs par défaut au lieu de types de colonnes.
%%writefile missing.csv
1,2,3,4
,2,3,4
1,,3,4
1,2,,4
1,2,3,
,,,
Writing missing.csv
# Creates a dataset that reads all of the records from two CSV files, each with
# four float columns which may have missing values.
record_defaults = [999,999,999,999]
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults)
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(4,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[1 2 3 4] [999 2 3 4] [ 1 999 3 4] [ 1 2 999 4] [ 1 2 3 999] [999 999 999 999]
Par défaut, un CsvDataset produit chaque colonne de chaque ligne du fichier, ce qui peut ne pas être souhaitable, par exemple si le fichier commence par une ligne d'en-tête qui doit être ignorée, ou si certaines colonnes ne sont pas requises dans l'entrée. Ces lignes et champs peuvent être supprimés avec les arguments header et select_cols respectivement.
# Creates a dataset that reads all of the records from two CSV files with
# headers, extracting float data from columns 2 and 4.
record_defaults = [999, 999] # Only provide defaults for the selected columns
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults, select_cols=[1, 3])
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(2,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[2 4] [2 4] [999 4] [2 4] [ 2 999] [999 999]
Consommer des ensembles de fichiers
Il existe de nombreux ensembles de données distribués sous la forme d'un ensemble de fichiers, où chaque fichier est un exemple.
flowers_root = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
flowers_root = pathlib.Path(flowers_root)
Le répertoire racine contient un répertoire pour chaque classe :
for item in flowers_root.glob("*"):
print(item.name)
sunflowers daisy LICENSE.txt roses tulips dandelion
Les fichiers de chaque répertoire de classe sont des exemples :
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/5018120483_cc0421b176_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/8642679391_0805b147cb_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/8266310743_02095e782d_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/13176521023_4d7cc74856_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/19437578578_6ab1b3c984.jpg'
Lisez les données à l'aide de la fonction tf.io.read_file et extrayez l'étiquette du chemin, renvoyant des paires (image, label) :
def process_path(file_path):
label = tf.strings.split(file_path, os.sep)[-2]
return tf.io.read_file(file_path), label
labeled_ds = list_ds.map(process_path)
for image_raw, label_text in labeled_ds.take(1):
print(repr(image_raw.numpy()[:100]))
print()
print(label_text.numpy())
b'\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x00\x00\x01\x00\x01\x00\x00\xff\xe2\x0cXICC_PROFILE\x00\x01\x01\x00\x00\x0cHLino\x02\x10\x00\x00mntrRGB XYZ \x07\xce\x00\x02\x00\t\x00\x06\x001\x00\x00acspMSFT\x00\x00\x00\x00IEC sRGB\x00\x00\x00\x00\x00\x00' b'daisy'
Regrouper les éléments de l'ensemble de données
Mise en lots simple
La forme la plus simple de traitement par lots empile n éléments consécutifs d'un ensemble de données en un seul élément. La transformation Dataset.batch() fait exactement cela, avec les mêmes contraintes que l'opérateur tf.stack() , appliquées à chaque composant des éléments : c'est-à-dire que pour chaque composant i , tous les éléments doivent avoir un tenseur de la même forme exacte.
inc_dataset = tf.data.Dataset.range(100)
dec_dataset = tf.data.Dataset.range(0, -100, -1)
dataset = tf.data.Dataset.zip((inc_dataset, dec_dataset))
batched_dataset = dataset.batch(4)
for batch in batched_dataset.take(4):
print([arr.numpy() for arr in batch])
[array([0, 1, 2, 3]), array([ 0, -1, -2, -3])] [array([4, 5, 6, 7]), array([-4, -5, -6, -7])] [array([ 8, 9, 10, 11]), array([ -8, -9, -10, -11])] [array([12, 13, 14, 15]), array([-12, -13, -14, -15])]
Alors que tf.data essaie de propager les informations de forme, les paramètres par défaut de Dataset.batch entraînent une taille de lot inconnue car le dernier lot peut ne pas être complet. Notez le None s dans la forme :
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.int64, name=None))>
Utilisez l'argument drop_remainder pour ignorer ce dernier lot et obtenir une propagation de forme complète :
batched_dataset = dataset.batch(7, drop_remainder=True)
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(7,), dtype=tf.int64, name=None), TensorSpec(shape=(7,), dtype=tf.int64, name=None))>
Tenseurs de dosage avec rembourrage
La recette ci-dessus fonctionne pour des tenseurs qui ont tous la même taille. Cependant, de nombreux modèles (par exemple, les modèles de séquence) fonctionnent avec des données d'entrée qui peuvent avoir une taille variable (par exemple, des séquences de différentes longueurs). Pour gérer ce cas, la transformation Dataset.padded_batch vous permet de grouper des tenseurs de forme différente en spécifiant une ou plusieurs dimensions dans lesquelles ils peuvent être remplis.
dataset = tf.data.Dataset.range(100)
dataset = dataset.map(lambda x: tf.fill([tf.cast(x, tf.int32)], x))
dataset = dataset.padded_batch(4, padded_shapes=(None,))
for batch in dataset.take(2):
print(batch.numpy())
print()
[[0 0 0] [1 0 0] [2 2 0] [3 3 3]] [[4 4 4 4 0 0 0] [5 5 5 5 5 0 0] [6 6 6 6 6 6 0] [7 7 7 7 7 7 7]]
La transformation Dataset.padded_batch vous permet de définir un remplissage différent pour chaque dimension de chaque composant, et il peut être de longueur variable (signifié par None dans l'exemple ci-dessus) ou de longueur constante. Il est également possible de remplacer la valeur de remplissage, qui est par défaut à 0.
Flux de travail de formation
Traitement de plusieurs époques
L'API tf.data propose deux méthodes principales pour traiter plusieurs époques des mêmes données.
Le moyen le plus simple d'itérer sur un ensemble de données à plusieurs époques consiste à utiliser la transformation Dataset.repeat() . Tout d'abord, créez un jeu de données de données titanesques :
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
def plot_batch_sizes(ds):
batch_sizes = [batch.shape[0] for batch in ds]
plt.bar(range(len(batch_sizes)), batch_sizes)
plt.xlabel('Batch number')
plt.ylabel('Batch size')
L'application de la transformation Dataset.repeat() sans arguments répétera l'entrée indéfiniment.
La transformation Dataset.repeat concatène ses arguments sans signaler la fin d'une époque et le début de l'époque suivante. Pour cette raison, un Dataset.batch appliqué après Dataset.repeat produira des lots qui chevauchent les limites de l'époque :
titanic_batches = titanic_lines.repeat(3).batch(128)
plot_batch_sizes(titanic_batches)
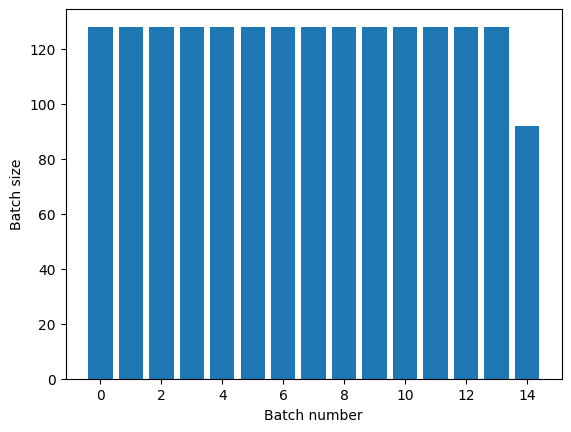
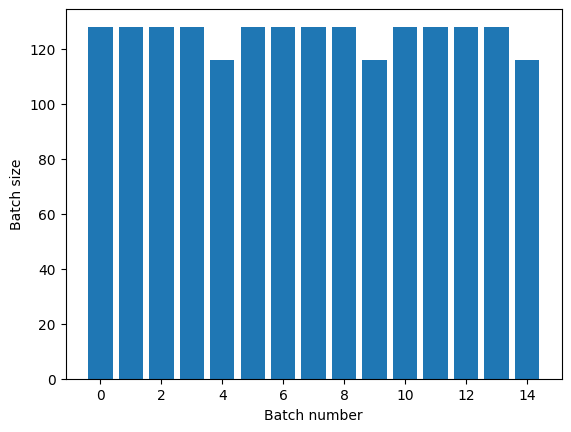
Si vous avez besoin d'une séparation claire des époques, placez Dataset.batch avant la répétition :
titanic_batches = titanic_lines.batch(128).repeat(3)
plot_batch_sizes(titanic_batches)
Si vous souhaitez effectuer un calcul personnalisé (par exemple pour collecter des statistiques) à la fin de chaque époque, il est plus simple de redémarrer l'itération de l'ensemble de données à chaque époque :
epochs = 3
dataset = titanic_lines.batch(128)
for epoch in range(epochs):
for batch in dataset:
print(batch.shape)
print("End of epoch: ", epoch)
(128,) (128,) (128,) (128,) (116,) End of epoch: 0 (128,) (128,) (128,) (128,) (116,) End of epoch: 1 (128,) (128,) (128,) (128,) (116,) End of epoch: 2
Mélange aléatoire des données d'entrée
La transformation Dataset.shuffle() maintient un tampon de taille fixe et choisit l'élément suivant de manière uniforme au hasard dans ce tampon.
Ajoutez un index à l'ensemble de données pour voir l'effet :
lines = tf.data.TextLineDataset(titanic_file)
counter = tf.data.experimental.Counter()
dataset = tf.data.Dataset.zip((counter, lines))
dataset = dataset.shuffle(buffer_size=100)
dataset = dataset.batch(20)
dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.string, name=None))>
Étant donné que buffer_size est de 100 et que la taille du lot est de 20, le premier lot ne contient aucun élément avec un index supérieur à 120.
n,line_batch = next(iter(dataset))
print(n.numpy())
[ 52 94 22 70 63 96 56 102 38 16 27 104 89 43 41 68 42 61 112 8]
Comme avec Dataset.batch , l'ordre relatif à Dataset.repeat est important.
Dataset.shuffle ne signale pas la fin d'une époque tant que le tampon de mélange n'est pas vide. Ainsi, un mélange placé avant une répétition affichera chaque élément d'une époque avant de passer à la suivante :
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.shuffle(buffer_size=100).batch(10).repeat(2)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(60).take(5):
print(n.numpy())
Here are the item ID's near the epoch boundary: [509 595 537 550 555 591 480 627 482 519] [522 619 538 581 569 608 531 558 461 496] [548 489 379 607 611 622 234 525] [ 59 38 4 90 73 84 27 51 107 12] [77 72 91 60 7 62 92 47 70 67]
shuffle_repeat = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f7e7061c650>
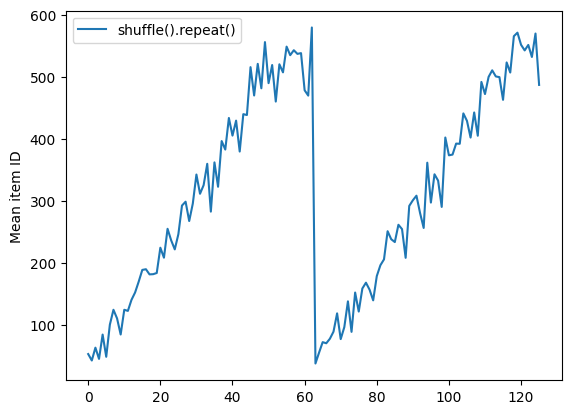
Mais une répétition avant un shuffle mélange les frontières de l'époque :
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.repeat(2).shuffle(buffer_size=100).batch(10)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(55).take(15):
print(n.numpy())
Here are the item ID's near the epoch boundary: [ 6 8 528 604 13 492 308 441 569 475] [ 5 626 615 568 20 554 520 454 10 607] [510 542 0 363 32 446 395 588 35 4] [ 7 15 28 23 39 559 585 49 252 556] [581 617 25 43 26 548 29 460 48 41] [ 19 64 24 300 612 611 36 63 69 57] [287 605 21 512 442 33 50 68 608 47] [625 90 91 613 67 53 606 344 16 44] [453 448 89 45 465 2 31 618 368 105] [565 3 586 114 37 464 12 627 30 621] [ 82 117 72 75 84 17 571 610 18 600] [107 597 575 88 623 86 101 81 456 102] [122 79 51 58 80 61 367 38 537 113] [ 71 78 598 152 143 620 100 158 133 130] [155 151 144 135 146 121 83 27 103 134]
repeat_shuffle = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.plot(repeat_shuffle, label="repeat().shuffle()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f7e706013d0>
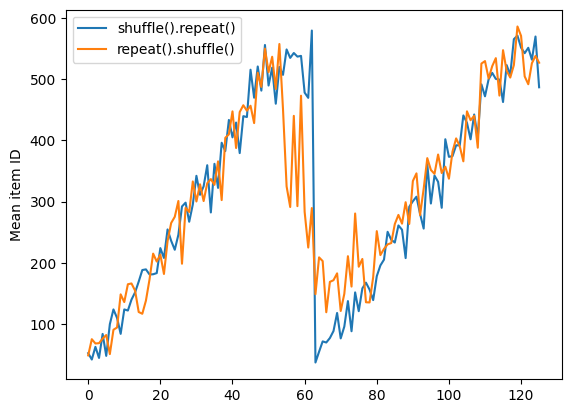
Prétraitement des données
La Dataset.map(f) produit un nouvel ensemble de données en appliquant une fonction donnée f à chaque élément de l'ensemble de données d'entrée. Il est basé sur la fonction map() qui est couramment appliquée aux listes (et autres structures) dans les langages de programmation fonctionnels. La fonction f prend les objets tf.Tensor qui représentent un seul élément dans l'entrée et renvoie les objets tf.Tensor qui représenteront un seul élément dans le nouvel ensemble de données. Son implémentation utilise les opérations TensorFlow standard pour transformer un élément en un autre.
Cette section couvre des exemples courants d'utilisation de Dataset.map() .
Décodage des données d'image et redimensionnement
Lors de la formation d'un réseau de neurones sur des données d'images du monde réel, il est souvent nécessaire de convertir des images de différentes tailles en une taille commune, afin qu'elles puissent être regroupées en une taille fixe.
Reconstruisez l'ensemble de données des noms de fichiers de fleurs :
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
Écrivez une fonction qui manipule les éléments de l'ensemble de données.
# Reads an image from a file, decodes it into a dense tensor, and resizes it
# to a fixed shape.
def parse_image(filename):
parts = tf.strings.split(filename, os.sep)
label = parts[-2]
image = tf.io.read_file(filename)
image = tf.io.decode_jpeg(image)
image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.image.resize(image, [128, 128])
return image, label
Testez que cela fonctionne.
file_path = next(iter(list_ds))
image, label = parse_image(file_path)
def show(image, label):
plt.figure()
plt.imshow(image)
plt.title(label.numpy().decode('utf-8'))
plt.axis('off')
show(image, label)

Mappez-le sur l'ensemble de données.
images_ds = list_ds.map(parse_image)
for image, label in images_ds.take(2):
show(image, label)


Appliquer une logique Python arbitraire
Pour des raisons de performances, utilisez les opérations TensorFlow pour prétraiter vos données dans la mesure du possible. Cependant, il est parfois utile d'appeler des bibliothèques Python externes lors de l'analyse de vos données d'entrée. Vous pouvez utiliser l'opération tf.py_function() dans une transformation Dataset.map() .
Par exemple, si vous souhaitez appliquer une rotation aléatoire, le module tf.image n'a que tf.image.rot90 , ce qui n'est pas très utile pour l'augmentation d'image.
Pour démontrer tf.py_function , essayez d'utiliser la fonction scipy.ndimage.rotate à la place :
import scipy.ndimage as ndimage
def random_rotate_image(image):
image = ndimage.rotate(image, np.random.uniform(-30, 30), reshape=False)
return image
image, label = next(iter(images_ds))
image = random_rotate_image(image)
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

Pour utiliser cette fonction avec Dataset.map les mêmes mises en garde s'appliquent qu'avec Dataset.from_generator , vous devez décrire les formes et les types de retour lorsque vous appliquez la fonction :
def tf_random_rotate_image(image, label):
im_shape = image.shape
[image,] = tf.py_function(random_rotate_image, [image], [tf.float32])
image.set_shape(im_shape)
return image, label
rot_ds = images_ds.map(tf_random_rotate_image)
for image, label in rot_ds.take(2):
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).


Analyse des messages de tampon de protocole tf.Example
De nombreux pipelines d'entrée extraient les messages de tampon de protocole tf.train.Example à partir d'un format TFRecord. Chaque enregistrement tf.train.Example contient une ou plusieurs "fonctionnalités", et le pipeline d'entrée convertit généralement ces fonctionnalités en tenseurs.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
Vous pouvez travailler avec des protos tf.train.Example en dehors d'un tf.data.Dataset pour comprendre les données :
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
feature = parsed.features.feature
raw_img = feature['image/encoded'].bytes_list.value[0]
img = tf.image.decode_png(raw_img)
plt.imshow(img)
plt.axis('off')
_ = plt.title(feature["image/text"].bytes_list.value[0])

raw_example = next(iter(dataset))
def tf_parse(eg):
example = tf.io.parse_example(
eg[tf.newaxis], {
'image/encoded': tf.io.FixedLenFeature(shape=(), dtype=tf.string),
'image/text': tf.io.FixedLenFeature(shape=(), dtype=tf.string)
})
return example['image/encoded'][0], example['image/text'][0]
img, txt = tf_parse(raw_example)
print(txt.numpy())
print(repr(img.numpy()[:20]), "...")
b'Rue Perreyon' b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x02X' ...
decoded = dataset.map(tf_parse)
decoded
<MapDataset element_spec=(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.string, name=None))>
image_batch, text_batch = next(iter(decoded.batch(10)))
image_batch.shape
TensorShape([10])
Fenêtrage des séries chronologiques
Pour un exemple de série chronologique de bout en bout, voir : Prévision de séries chronologiques .
Les données de séries chronologiques sont souvent organisées avec l'axe du temps intact.
Utilisez un Dataset.range simple pour démontrer :
range_ds = tf.data.Dataset.range(100000)
En règle générale, les modèles basés sur ce type de données voudront une tranche de temps contiguë.
L'approche la plus simple serait de regrouper les données :
Utilisation batch
batches = range_ds.batch(10, drop_remainder=True)
for batch in batches.take(5):
print(batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] [40 41 42 43 44 45 46 47 48 49]
Ou pour faire des prédictions denses une étape dans le futur, vous pouvez décaler les caractéristiques et les étiquettes d'une étape les unes par rapport aux autres :
def dense_1_step(batch):
# Shift features and labels one step relative to each other.
return batch[:-1], batch[1:]
predict_dense_1_step = batches.map(dense_1_step)
for features, label in predict_dense_1_step.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8] => [1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18] => [11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28] => [21 22 23 24 25 26 27 28 29]
Pour prédire une fenêtre entière au lieu d'un décalage fixe, vous pouvez diviser les lots en deux parties :
batches = range_ds.batch(15, drop_remainder=True)
def label_next_5_steps(batch):
return (batch[:-5], # Inputs: All except the last 5 steps
batch[-5:]) # Labels: The last 5 steps
predict_5_steps = batches.map(label_next_5_steps)
for features, label in predict_5_steps.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] => [25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] => [40 41 42 43 44]
Pour permettre un certain chevauchement entre les fonctionnalités d'un lot et les étiquettes d'un autre, utilisez Dataset.zip :
feature_length = 10
label_length = 3
features = range_ds.batch(feature_length, drop_remainder=True)
labels = range_ds.batch(feature_length).skip(1).map(lambda labels: labels[:label_length])
predicted_steps = tf.data.Dataset.zip((features, labels))
for features, label in predicted_steps.take(5):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12] [10 11 12 13 14 15 16 17 18 19] => [20 21 22] [20 21 22 23 24 25 26 27 28 29] => [30 31 32] [30 31 32 33 34 35 36 37 38 39] => [40 41 42] [40 41 42 43 44 45 46 47 48 49] => [50 51 52]
Utilisation window
Lors de l'utilisation Dataset.batch , il existe des situations où vous pouvez avoir besoin d'un contrôle plus précis. La méthode Dataset.window vous donne un contrôle total, mais nécessite quelques précautions : elle renvoie un Dataset of Datasets . Voir Structure du jeu de données pour plus de détails.
window_size = 5
windows = range_ds.window(window_size, shift=1)
for sub_ds in windows.take(5):
print(sub_ds)
<_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)>
La méthode Dataset.flat_map peut prendre un jeu de données de jeux de données et l'aplatir en un seul jeu de données :
for x in windows.flat_map(lambda x: x).take(30):
print(x.numpy(), end=' ')
0 1 2 3 4 1 2 3 4 5 2 3 4 5 6 3 4 5 6 7 4 5 6 7 8 5 6 7 8 9
Dans presque tous les cas, vous souhaiterez d' .batch l'ensemble de données :
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
for example in windows.flat_map(sub_to_batch).take(5):
print(example.numpy())
[0 1 2 3 4] [1 2 3 4 5] [2 3 4 5 6] [3 4 5 6 7] [4 5 6 7 8]
Maintenant, vous pouvez voir que l'argument shift contrôle le déplacement de chaque fenêtre.
En mettant cela ensemble, vous pourriez écrire cette fonction :
def make_window_dataset(ds, window_size=5, shift=1, stride=1):
windows = ds.window(window_size, shift=shift, stride=stride)
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
windows = windows.flat_map(sub_to_batch)
return windows
ds = make_window_dataset(range_ds, window_size=10, shift = 5, stride=3)
for example in ds.take(10):
print(example.numpy())
[ 0 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34 37] [15 18 21 24 27 30 33 36 39 42] [20 23 26 29 32 35 38 41 44 47] [25 28 31 34 37 40 43 46 49 52] [30 33 36 39 42 45 48 51 54 57] [35 38 41 44 47 50 53 56 59 62] [40 43 46 49 52 55 58 61 64 67] [45 48 51 54 57 60 63 66 69 72]
Ensuite, il est facile d'extraire les étiquettes, comme avant :
dense_labels_ds = ds.map(dense_1_step)
for inputs,labels in dense_labels_ds.take(3):
print(inputs.numpy(), "=>", labels.numpy())
[ 0 3 6 9 12 15 18 21 24] => [ 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29] => [ 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34] => [13 16 19 22 25 28 31 34 37]
Rééchantillonnage
Lorsque vous travaillez avec un jeu de données très déséquilibré en classe, vous pouvez souhaiter rééchantillonner le jeu de données. tf.data fournit deux méthodes pour ce faire. L'ensemble de données sur la fraude par carte de crédit est un bon exemple de ce type de problème.
zip_path = tf.keras.utils.get_file(
origin='https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip',
fname='creditcard.zip',
extract=True)
csv_path = zip_path.replace('.zip', '.csv')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip 69156864/69155632 [==============================] - 2s 0us/step 69165056/69155632 [==============================] - 2s 0us/step
creditcard_ds = tf.data.experimental.make_csv_dataset(
csv_path, batch_size=1024, label_name="Class",
# Set the column types: 30 floats and an int.
column_defaults=[float()]*30+[int()])
Maintenant, vérifiez la distribution des classes, elle est très asymétrique :
def count(counts, batch):
features, labels = batch
class_1 = labels == 1
class_1 = tf.cast(class_1, tf.int32)
class_0 = labels == 0
class_0 = tf.cast(class_0, tf.int32)
counts['class_0'] += tf.reduce_sum(class_0)
counts['class_1'] += tf.reduce_sum(class_1)
return counts
counts = creditcard_ds.take(10).reduce(
initial_state={'class_0': 0, 'class_1': 0},
reduce_func = count)
counts = np.array([counts['class_0'].numpy(),
counts['class_1'].numpy()]).astype(np.float32)
fractions = counts/counts.sum()
print(fractions)
[0.9956 0.0044]
Une approche courante de la formation avec un ensemble de données déséquilibré consiste à l'équilibrer. tf.data inclut quelques méthodes qui permettent ce workflow :
Échantillonnage des ensembles de données
Une approche pour rééchantillonner un jeu de données consiste à utiliser sample_from_datasets . Ceci est plus applicable lorsque vous avez un data.Dataset séparé pour chaque classe.
Ici, utilisez simplement le filtre pour les générer à partir des données de fraude par carte de crédit :
negative_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==0)
.repeat())
positive_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==1)
.repeat())
for features, label in positive_ds.batch(10).take(1):
print(label.numpy())
[1 1 1 1 1 1 1 1 1 1]
Pour utiliser tf.data.Dataset.sample_from_datasets , transmettez les ensembles de données et le poids de chacun :
balanced_ds = tf.data.Dataset.sample_from_datasets(
[negative_ds, positive_ds], [0.5, 0.5]).batch(10)
Maintenant, l'ensemble de données produit des exemples de chaque classe avec une probabilité de 50/50 :
for features, labels in balanced_ds.take(10):
print(labels.numpy())
[1 0 1 0 1 0 1 1 1 1] [0 0 1 1 0 1 1 1 1 1] [1 1 1 1 0 0 1 0 1 0] [1 1 1 0 1 0 0 1 1 1] [0 1 0 1 1 1 0 1 1 0] [0 1 0 0 0 1 0 0 0 0] [1 1 1 1 1 0 0 1 1 0] [0 0 0 1 0 1 1 1 0 0] [0 0 1 1 1 1 0 1 1 1] [1 0 0 1 1 1 1 0 1 1]
Rééchantillonnage de rejet
Un problème avec l'approche Dataset.sample_from_datasets ci-dessus est qu'elle nécessite un tf.data.Dataset séparé par classe. Vous pouvez utiliser Dataset.filter pour créer ces deux ensembles de données, mais cela entraîne le chargement de toutes les données deux fois.
La méthode data.Dataset.rejection_resample peut être appliquée à un jeu de données pour le rééquilibrer, tout en ne le chargeant qu'une seule fois. Les éléments seront supprimés de l'ensemble de données pour atteindre l'équilibre.
data.Dataset.rejection_resample prend un argument class_func . Ce class_func est appliqué à chaque élément de l'ensemble de données et est utilisé pour déterminer à quelle classe appartient un exemple à des fins d'équilibrage.
Le but ici est d'équilibrer la distribution des étiquettes, et les éléments de creditcard_ds sont déjà des paires (features, label) . Ainsi, le class_func juste besoin de renvoyer ces étiquettes :
def class_func(features, label):
return label
La méthode de rééchantillonnage traite des exemples individuels, donc dans ce cas, vous devez unbatch l'ensemble de données avant d'appliquer cette méthode.
La méthode nécessite une distribution cible et éventuellement une estimation de distribution initiale comme entrées.
resample_ds = (
creditcard_ds
.unbatch()
.rejection_resample(class_func, target_dist=[0.5,0.5],
initial_dist=fractions)
.batch(10))
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/data/ops/dataset_ops.py:5797: Print (from tensorflow.python.ops.logging_ops) is deprecated and will be removed after 2018-08-20. Instructions for updating: Use tf.print instead of tf.Print. Note that tf.print returns a no-output operator that directly prints the output. Outside of defuns or eager mode, this operator will not be executed unless it is directly specified in session.run or used as a control dependency for other operators. This is only a concern in graph mode. Below is an example of how to ensure tf.print executes in graph mode:
La méthode de rejection_resample renvoie des paires (class, example) où la class est la sortie de class_func . Dans ce cas, l' example était déjà une paire (feature, label) , utilisez donc map pour supprimer la copie supplémentaire des étiquettes :
balanced_ds = resample_ds.map(lambda extra_label, features_and_label: features_and_label)
Maintenant, l'ensemble de données produit des exemples de chaque classe avec une probabilité de 50/50 :
for features, labels in balanced_ds.take(10):
print(labels.numpy())
Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] [0 1 1 1 0 1 1 0 1 1] [1 1 0 1 0 0 0 0 1 1] [1 1 1 1 0 0 0 0 1 1] [1 0 0 1 0 0 1 0 1 1] [1 0 0 0 0 1 0 0 0 0] [1 0 0 1 1 0 1 1 1 0] [1 1 0 0 0 0 0 0 0 1] [0 0 1 0 0 0 1 0 1 1] [0 1 0 1 0 1 0 0 0 1] [0 0 0 0 0 0 0 0 1 1]
Point de contrôle de l'itérateur
Tensorflow prend en charge la prise de points de contrôle afin que lorsque votre processus de formation redémarre, il puisse restaurer le dernier point de contrôle pour récupérer la majeure partie de sa progression. En plus de contrôler les variables de modèle, vous pouvez également contrôler la progression de l'itérateur de l'ensemble de données. Cela peut être utile si vous avez un jeu de données volumineux et que vous ne souhaitez pas recommencer le jeu de données depuis le début à chaque redémarrage. Notez cependant que les points de contrôle de l'itérateur peuvent être volumineux, car les transformations telles que la lecture shuffle et la prefetch nécessitent des éléments de mise en mémoire tampon dans l'itérateur.
Pour inclure votre itérateur dans un point de contrôle, passez l'itérateur au constructeur tf.train.Checkpoint .
range_ds = tf.data.Dataset.range(20)
iterator = iter(range_ds)
ckpt = tf.train.Checkpoint(step=tf.Variable(0), iterator=iterator)
manager = tf.train.CheckpointManager(ckpt, '/tmp/my_ckpt', max_to_keep=3)
print([next(iterator).numpy() for _ in range(5)])
save_path = manager.save()
print([next(iterator).numpy() for _ in range(5)])
ckpt.restore(manager.latest_checkpoint)
print([next(iterator).numpy() for _ in range(5)])
[0, 1, 2, 3, 4] [5, 6, 7, 8, 9] [5, 6, 7, 8, 9]
Utilisation de tf.data avec tf.keras
L'API tf.keras simplifie de nombreux aspects de la création et de l'exécution de modèles d'apprentissage automatique. Ses .fit() et .evaluate .evaluate() et .predict() prennent en charge les jeux de données comme entrées. Voici un jeu de données rapide et une configuration de modèle :
train, test = tf.keras.datasets.fashion_mnist.load_data()
images, labels = train
images = images/255.0
labels = labels.astype(np.int32)
fmnist_train_ds = tf.data.Dataset.from_tensor_slices((images, labels))
fmnist_train_ds = fmnist_train_ds.shuffle(5000).batch(32)
model = tf.keras.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Passer un ensemble de données de paires (feature, label) est tout ce qui est nécessaire pour Model.fit et Model.evaluate :
model.fit(fmnist_train_ds, epochs=2)
Epoch 1/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.5984 - accuracy: 0.7973 Epoch 2/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.4607 - accuracy: 0.8430 <keras.callbacks.History at 0x7f7e70283110>
Si vous passez un jeu de données infini, par exemple en appelant Dataset.repeat() , il vous suffit de passer également l'argument steps_per_epoch :
model.fit(fmnist_train_ds.repeat(), epochs=2, steps_per_epoch=20)
Epoch 1/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4574 - accuracy: 0.8672 Epoch 2/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4216 - accuracy: 0.8562 <keras.callbacks.History at 0x7f7e144948d0>
Pour l'évaluation, vous pouvez passer le nombre d'étapes d'évaluation :
loss, accuracy = model.evaluate(fmnist_train_ds)
print("Loss :", loss)
print("Accuracy :", accuracy)
1875/1875 [==============================] - 4s 2ms/step - loss: 0.4350 - accuracy: 0.8524 Loss : 0.4350026249885559 Accuracy : 0.8524333238601685
Pour les ensembles de données longs, définissez le nombre d'étapes à évaluer :
loss, accuracy = model.evaluate(fmnist_train_ds.repeat(), steps=10)
print("Loss :", loss)
print("Accuracy :", accuracy)
10/10 [==============================] - 0s 2ms/step - loss: 0.4345 - accuracy: 0.8687 Loss : 0.43447819352149963 Accuracy : 0.8687499761581421
Les étiquettes ne sont pas requises lors de l'appel Model.predict .
predict_ds = tf.data.Dataset.from_tensor_slices(images).batch(32)
result = model.predict(predict_ds, steps = 10)
print(result.shape)
(320, 10)
Mais les étiquettes sont ignorées si vous transmettez un ensemble de données les contenant :
result = model.predict(fmnist_train_ds, steps = 10)
print(result.shape)
(320, 10)