
| | |  Zobacz na GitHub Zobacz na GitHub | | |
Ten samouczek zawiera kompletny kod do precyzyjnego dostrojenia BERT w celu przeprowadzenia analizy tonacji w zestawie danych z recenzjami filmów IMDB w postaci zwykłego tekstu. Oprócz uczenia modelu dowiesz się, jak wstępnie przetworzyć tekst do odpowiedniego formatu.
W tym notatniku będziesz:
- Załaduj zbiór danych IMDB
- Załaduj model BERT z TensorFlow Hub
- Zbuduj własny model, łącząc BERT z klasyfikatorem
- Trenuj swój własny model, dostrajając w ramach tego BERT
- Zapisz swój model i użyj go do klasyfikowania zdań
Jeśli jesteś nowy w pracy z zestawu danych IMDB, proszę zobaczyć klasyfikację tekstu podstawowego więcej szczegółów.
O BERT
BERT i innych architektur Transformer enkodera były szalenie udany na różnych zadań w NLP (przetwarzanie języka naturalnego). Obliczają one reprezentacje języka naturalnego w przestrzeni wektorowej, które są odpowiednie do użycia w modelach głębokiego uczenia się. Rodzina modeli BERT wykorzystuje architekturę kodera Transformer do przetwarzania każdego tokena tekstu wejściowego w pełnym kontekście wszystkich tokenów przed i po, stąd nazwa: Bidirectional Encoder Representations from Transformers.
Modele BERT są zwykle wstępnie przeszkolone na dużym korpusie tekstu, a następnie dostrojone do określonych zadań.
Ustawiać
# A dependency of the preprocessing for BERT inputspip install -q -U tensorflow-text
Będziesz korzystać z optymalizatora AdamW z tensorflow / modeli .
pip install -q tf-models-official
import os
import shutil
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_text as text
from official.nlp import optimization # to create AdamW optimizer
import matplotlib.pyplot as plt
tf.get_logger().setLevel('ERROR')
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py:119: PkgResourcesDeprecationWarning: 0.18ubuntu0.18.04.1 is an invalid version and will not be supported in a future release PkgResourcesDeprecationWarning,
Analiza sentymentu
Ten notebook trenuje sentyment analizy modelu sklasyfikować recenzje filmów jako pozytywne lub negatywne, oparte na tekście przeglądu.
Będziesz korzystać z dużej Przegląd filmów zestawu danych , który zawiera tekst 50.000 recenzje filmów z Bazy Internet Movie .
Pobierz zbiór danych IMDB
Pobierzmy i wyodrębnijmy zestaw danych, a następnie zbadajmy strukturę katalogów.
url = 'https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz'
dataset = tf.keras.utils.get_file('aclImdb_v1.tar.gz', url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
train_dir = os.path.join(dataset_dir, 'train')
# remove unused folders to make it easier to load the data
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 7s 0us/step 84140032/84125825 [==============================] - 7s 0us/step
Następnie można użyć text_dataset_from_directory narzędzie do tworzenia oznaczony tf.data.Dataset .
Zbiór danych IMDB został już podzielony na pociąg i test, ale brakuje w nim zestawu walidacyjnego. Stwórzmy zestaw walidacji przy użyciu 80:20 podział danych treningowej za pomocą validation_split argumentu poniżej.
AUTOTUNE = tf.data.AUTOTUNE
batch_size = 32
seed = 42
raw_train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
class_names = raw_train_ds.class_names
train_ds = raw_train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
Found 25000 files belonging to 2 classes. Using 20000 files for training. Found 25000 files belonging to 2 classes. Using 5000 files for validation. Found 25000 files belonging to 2 classes.
Rzućmy okiem na kilka recenzji.
for text_batch, label_batch in train_ds.take(1):
for i in range(3):
print(f'Review: {text_batch.numpy()[i]}')
label = label_batch.numpy()[i]
print(f'Label : {label} ({class_names[label]})')
Review: b'"Pandemonium" is a horror movie spoof that comes off more stupid than funny. Believe me when I tell you, I love comedies. Especially comedy spoofs. "Airplane", "The Naked Gun" trilogy, "Blazing Saddles", "High Anxiety", and "Spaceballs" are some of my favorite comedies that spoof a particular genre. "Pandemonium" is not up there with those films. Most of the scenes in this movie had me sitting there in stunned silence because the movie wasn\'t all that funny. There are a few laughs in the film, but when you watch a comedy, you expect to laugh a lot more than a few times and that\'s all this film has going for it. Geez, "Scream" had more laughs than this film and that was more of a horror film. How bizarre is that?<br /><br />*1/2 (out of four)' Label : 0 (neg) Review: b"David Mamet is a very interesting and a very un-equal director. His first movie 'House of Games' was the one I liked best, and it set a series of films with characters whose perspective of life changes as they get into complicated situations, and so does the perspective of the viewer.<br /><br />So is 'Homicide' which from the title tries to set the mind of the viewer to the usual crime drama. The principal characters are two cops, one Jewish and one Irish who deal with a racially charged area. The murder of an old Jewish shop owner who proves to be an ancient veteran of the Israeli Independence war triggers the Jewish identity in the mind and heart of the Jewish detective.<br /><br />This is were the flaws of the film are the more obvious. The process of awakening is theatrical and hard to believe, the group of Jewish militants is operatic, and the way the detective eventually walks to the final violent confrontation is pathetic. The end of the film itself is Mamet-like smart, but disappoints from a human emotional perspective.<br /><br />Joe Mantegna and William Macy give strong performances, but the flaws of the story are too evident to be easily compensated." Label : 0 (neg) Review: b'Great documentary about the lives of NY firefighters during the worst terrorist attack of all time.. That reason alone is why this should be a must see collectors item.. What shocked me was not only the attacks, but the"High Fat Diet" and physical appearance of some of these firefighters. I think a lot of Doctors would agree with me that,in the physical shape they were in, some of these firefighters would NOT of made it to the 79th floor carrying over 60 lbs of gear. Having said that i now have a greater respect for firefighters and i realize becoming a firefighter is a life altering job. The French have a history of making great documentary\'s and that is what this is, a Great Documentary.....' Label : 1 (pos) 2021-12-01 12:17:32.795514: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
Ładowanie modeli z TensorFlow Hub
Tutaj możesz wybrać, który model BERT załadujesz z TensorFlow Hub i dostroić. Dostępnych jest wiele modeli BERT.
- BERT-Base , nieobudowanego i siedem więcej modeli z przeszkolonych ciężarami uwalnianych przez pierwotnych autorów BERT.
- Małe Berts mają taką samą ogólną architekturę, ale mniej i / lub mniejszych bloków transformator, który pozwala badać kompromisów pomiędzy szybkością, wielkości i jakości.
- ALBERT : cztery różne rozmiary „lite BERT”, który redukuje rozmiar modelu (ale nie czas obliczeń) poprzez wymianę parametrów pomiędzy warstwami.
- BERT Eksperci : osiem modeli, które mają architekturę Bert-bazowy ale oferują wybór między różnymi domenami pre-szkoleniowych, aby ściślej wyrównać z zadaniem docelowym.
- Electra ma taką samą architekturę Bert (w trzech różnych rozmiarach), ale zostaje wstępnie przeszkolony jako dyskryminatora w zestawie-up, który przypomina Generative kontradyktoryjności Network (GAN).
- BERT z mówieniem głowic uwagę i Gated Gelu [ bazowej , duży ] posiada dwa ulepszenia do rdzenia architektury transformatora.
Dokumentacja modelowa na TensorFlow Hub zawiera więcej szczegółów i odniesień do literatury badawczej. Skorzystaj z linków powyżej, lub kliknij na tfhub.dev URL drukowanej po kolejnym wykonaniu komórki.
Sugeruje się, aby zacząć od małego BERT-a (z mniejszą liczbą parametrów), ponieważ są one szybsze w dostrajaniu. Jeśli lubisz mały model, ale z większą dokładnością, ALBERT może być twoją kolejną opcją. Jeśli chcesz jeszcze lepszej dokładności, wybierz jeden z klasycznych rozmiarów BERT lub ich najnowsze udoskonalenia, takie jak Electra, Talking Heads lub BERT Expert.
Oprócz modeli dostępnych poniżej, istnieje wiele wersji tych modeli, które są większe i mogą przynieść jeszcze większą dokładność, ale są one zbyt duże, aby być dostrojone na jednym GPU. Będziesz mógł to zrobić na rozwiązywać zadania z zastosowaniem BERT klej na colab TPU .
Zobaczysz w poniższym kodzie, że zmiana adresu URL tfhub.dev wystarczy, aby wypróbować którykolwiek z tych modeli, ponieważ wszystkie różnice między nimi są zawarte w SavedModels z TF Hub.
Wybierz model BERT do dostrojenia
bert_model_name = 'small_bert/bert_en_uncased_L-4_H-512_A-8'
map_name_to_handle = {
'bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/3',
'bert_en_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_cased_L-12_H-768_A-12/3',
'bert_multi_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_multi_cased_L-12_H-768_A-12/3',
'small_bert/bert_en_uncased_L-2_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-128_A-2/1',
'small_bert/bert_en_uncased_L-2_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-256_A-4/1',
'small_bert/bert_en_uncased_L-2_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-512_A-8/1',
'small_bert/bert_en_uncased_L-2_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-768_A-12/1',
'small_bert/bert_en_uncased_L-4_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-128_A-2/1',
'small_bert/bert_en_uncased_L-4_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-256_A-4/1',
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1',
'small_bert/bert_en_uncased_L-4_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-768_A-12/1',
'small_bert/bert_en_uncased_L-6_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-128_A-2/1',
'small_bert/bert_en_uncased_L-6_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-256_A-4/1',
'small_bert/bert_en_uncased_L-6_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-512_A-8/1',
'small_bert/bert_en_uncased_L-6_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-768_A-12/1',
'small_bert/bert_en_uncased_L-8_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-128_A-2/1',
'small_bert/bert_en_uncased_L-8_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-256_A-4/1',
'small_bert/bert_en_uncased_L-8_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-512_A-8/1',
'small_bert/bert_en_uncased_L-8_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-768_A-12/1',
'small_bert/bert_en_uncased_L-10_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-128_A-2/1',
'small_bert/bert_en_uncased_L-10_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-256_A-4/1',
'small_bert/bert_en_uncased_L-10_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-512_A-8/1',
'small_bert/bert_en_uncased_L-10_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-768_A-12/1',
'small_bert/bert_en_uncased_L-12_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-128_A-2/1',
'small_bert/bert_en_uncased_L-12_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-256_A-4/1',
'small_bert/bert_en_uncased_L-12_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-512_A-8/1',
'small_bert/bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-768_A-12/1',
'albert_en_base':
'https://tfhub.dev/tensorflow/albert_en_base/2',
'electra_small':
'https://tfhub.dev/google/electra_small/2',
'electra_base':
'https://tfhub.dev/google/electra_base/2',
'experts_pubmed':
'https://tfhub.dev/google/experts/bert/pubmed/2',
'experts_wiki_books':
'https://tfhub.dev/google/experts/bert/wiki_books/2',
'talking-heads_base':
'https://tfhub.dev/tensorflow/talkheads_ggelu_bert_en_base/1',
}
map_model_to_preprocess = {
'bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'bert_en_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_cased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'bert_multi_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_multi_cased_preprocess/3',
'albert_en_base':
'https://tfhub.dev/tensorflow/albert_en_preprocess/3',
'electra_small':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'electra_base':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'experts_pubmed':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'experts_wiki_books':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'talking-heads_base':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
}
tfhub_handle_encoder = map_name_to_handle[bert_model_name]
tfhub_handle_preprocess = map_model_to_preprocess[bert_model_name]
print(f'BERT model selected : {tfhub_handle_encoder}')
print(f'Preprocess model auto-selected: {tfhub_handle_preprocess}')
BERT model selected : https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Preprocess model auto-selected: https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3
Model przetwarzania wstępnego
Dane wejściowe tekstowe muszą zostać przekształcone w numeryczne identyfikatory tokenów i ułożone w kilka tensorów przed wprowadzeniem do BERT. TensorFlow Hub zapewnia pasujący model przetwarzania wstępnego dla każdego z omówionych powyżej modeli BERT, który implementuje tę transformację przy użyciu operacji TF z biblioteki TF.text. Nie jest konieczne uruchamianie czystego kodu Pythona poza modelem TensorFlow, aby wstępnie przetworzyć tekst.
Model przetwarzania wstępnego musi być tym, do którego odwołuje się dokumentacja modelu BERT, którą można przeczytać pod adresem URL wydrukowanym powyżej. W przypadku modeli BERT z powyższego menu rozwijanego model przetwarzania wstępnego jest wybierany automatycznie.
bert_preprocess_model = hub.KerasLayer(tfhub_handle_preprocess)
Wypróbujmy model przetwarzania wstępnego na jakimś tekście i zobaczmy wyniki:
text_test = ['this is such an amazing movie!']
text_preprocessed = bert_preprocess_model(text_test)
print(f'Keys : {list(text_preprocessed.keys())}')
print(f'Shape : {text_preprocessed["input_word_ids"].shape}')
print(f'Word Ids : {text_preprocessed["input_word_ids"][0, :12]}')
print(f'Input Mask : {text_preprocessed["input_mask"][0, :12]}')
print(f'Type Ids : {text_preprocessed["input_type_ids"][0, :12]}')
Keys : ['input_word_ids', 'input_mask', 'input_type_ids'] Shape : (1, 128) Word Ids : [ 101 2023 2003 2107 2019 6429 3185 999 102 0 0 0] Input Mask : [1 1 1 1 1 1 1 1 1 0 0 0] Type Ids : [0 0 0 0 0 0 0 0 0 0 0 0]
Jak widać, teraz masz 3 wyjścia z wyprzedzającym że model BERT użytkowania ( input_words_id , input_mask i input_type_ids ).
Kilka innych ważnych punktów:
- Dane wejściowe są obcinane do 128 tokenów. Liczba tokenów można dostosować i można zobaczyć więcej szczegółów na temat rozwiązać klej zadań wykorzystujących BERT na colab TPU .
- W
input_type_idsmieć jedną wartość (0) tylko dlatego, że jest to jedno wejście zdanie. W przypadku danych wejściowych z wieloma zdaniami będzie miała jedną liczbę dla każdego wejścia.
Ponieważ ten preprocesor tekstu jest modelem TensorFlow, można go dołączyć bezpośrednio do modelu.
Korzystanie z modelu BERT
Przed wprowadzeniem BERT do własnego modelu przyjrzyjmy się jego wynikom. Załadujesz go z TF Hub i zobaczysz zwrócone wartości.
bert_model = hub.KerasLayer(tfhub_handle_encoder)
bert_results = bert_model(text_preprocessed)
print(f'Loaded BERT: {tfhub_handle_encoder}')
print(f'Pooled Outputs Shape:{bert_results["pooled_output"].shape}')
print(f'Pooled Outputs Values:{bert_results["pooled_output"][0, :12]}')
print(f'Sequence Outputs Shape:{bert_results["sequence_output"].shape}')
print(f'Sequence Outputs Values:{bert_results["sequence_output"][0, :12]}')
Loaded BERT: https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Pooled Outputs Shape:(1, 512) Pooled Outputs Values:[ 0.76262873 0.99280983 -0.1861186 0.36673835 0.15233682 0.65504444 0.9681154 -0.9486272 0.00216158 -0.9877732 0.0684272 -0.9763061 ] Sequence Outputs Shape:(1, 128, 512) Sequence Outputs Values:[[-0.28946388 0.3432126 0.33231565 ... 0.21300787 0.7102078 -0.05771166] [-0.28742015 0.31981024 -0.2301858 ... 0.58455074 -0.21329722 0.7269209 ] [-0.66157013 0.6887685 -0.87432927 ... 0.10877253 -0.26173282 0.47855264] ... [-0.2256118 -0.28925604 -0.07064401 ... 0.4756601 0.8327715 0.40025353] [-0.29824278 -0.27473143 -0.05450511 ... 0.48849759 1.0955356 0.18163344] [-0.44378197 0.00930723 0.07223766 ... 0.1729009 1.1833246 0.07897988]]
Modele BERT powrócić mapę z 3 ważnych klawiszy: pooled_output , sequence_output , encoder_outputs :
-
pooled_outputoznacza każdą sekwencję wejściowy jako całości. Kształt jest[batch_size, H]. Możesz myśleć o tym jako o osadzeniu całej recenzji filmu. -
sequence_outputoznacza każdy element wejściowy w tym kontekście. Kształt jest[batch_size, seq_length, H]. Możesz myśleć o tym jako o osadzeniu kontekstowym dla każdego tokena w recenzji filmu. -
encoder_outputspośrednimi są uruchomieniachLbloków transformatora.outputs["encoder_outputs"][i]jest tensora kształtu[batch_size, seq_length, 1024]z wyjścia i-tego bloku transformator dla0 <= i < L. Ostatnia wartość listy jest równasequence_output.
Do dostrajania masz zamiar użyć pooled_output tablicę.
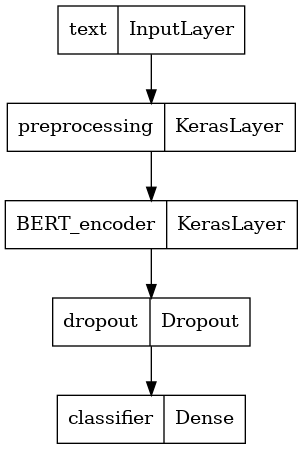
Zdefiniuj swój model
Stworzysz bardzo prosty, dostrojony model, z modelem przetwarzania wstępnego, wybranym modelem BERT, jedną warstwą Dense i Dropout.
def build_classifier_model():
text_input = tf.keras.layers.Input(shape=(), dtype=tf.string, name='text')
preprocessing_layer = hub.KerasLayer(tfhub_handle_preprocess, name='preprocessing')
encoder_inputs = preprocessing_layer(text_input)
encoder = hub.KerasLayer(tfhub_handle_encoder, trainable=True, name='BERT_encoder')
outputs = encoder(encoder_inputs)
net = outputs['pooled_output']
net = tf.keras.layers.Dropout(0.1)(net)
net = tf.keras.layers.Dense(1, activation=None, name='classifier')(net)
return tf.keras.Model(text_input, net)
Sprawdźmy, czy model działa z danymi wyjściowymi modelu przetwarzania wstępnego.
classifier_model = build_classifier_model()
bert_raw_result = classifier_model(tf.constant(text_test))
print(tf.sigmoid(bert_raw_result))
tf.Tensor([[0.6749899]], shape=(1, 1), dtype=float32)
Dane wyjściowe są oczywiście bez znaczenia, ponieważ model nie został jeszcze przeszkolony.
Przyjrzyjmy się budowie modelu.
tf.keras.utils.plot_model(classifier_model)
Szkolenie modelowe
Masz teraz wszystkie elementy do trenowania modelu, w tym moduł przetwarzania wstępnego, koder BERT, dane i klasyfikator.
Funkcja strat
Ponieważ jest to binarny Problem klasyfikacji i model generuje prawdopodobieństwo (warstwa single-unit), będziesz używać losses.BinaryCrossentropy funkcji straty.
loss = tf.keras.losses.BinaryCrossentropy(from_logits=True)
metrics = tf.metrics.BinaryAccuracy()
Optymalizator
Aby dostroić, użyjmy tego samego optymalizatora, z którym BERT był pierwotnie szkolony: „Adaptive Moments” (Adam). Optymalizacja ta minimalizuje straty przewidywania i nie uzupełnienia przez rozkład masy (a nie za pomocą momentów), który jest również znany jako AdamW .
Dla szybkości uczenia się ( init_lr ), można użyć tego samego schematu jak BERT pre-szkolenia: liniowa rozpad hipotetycznego początkowej szybkości uczenia się, z prefiksem z liniowej fazy rozgrzewania nad pierwszym 10% szkolenia etapów ( num_warmup_steps ). Zgodnie z dokumentem BERT, początkowa szybkość uczenia się jest mniejsza w przypadku dostrajania (najlepsza z 5e-5, 3e-5, 2e-5).
epochs = 5
steps_per_epoch = tf.data.experimental.cardinality(train_ds).numpy()
num_train_steps = steps_per_epoch * epochs
num_warmup_steps = int(0.1*num_train_steps)
init_lr = 3e-5
optimizer = optimization.create_optimizer(init_lr=init_lr,
num_train_steps=num_train_steps,
num_warmup_steps=num_warmup_steps,
optimizer_type='adamw')
Wczytywanie modelu BERT i szkolenia
Korzystanie z classifier_model utworzoną wcześniej, można skompilować model ze stratą, metryczny i optymalizatora.
classifier_model.compile(optimizer=optimizer,
loss=loss,
metrics=metrics)
print(f'Training model with {tfhub_handle_encoder}')
history = classifier_model.fit(x=train_ds,
validation_data=val_ds,
epochs=epochs)
Training model with https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Epoch 1/5 625/625 [==============================] - 91s 138ms/step - loss: 0.4776 - binary_accuracy: 0.7513 - val_loss: 0.3791 - val_binary_accuracy: 0.8380 Epoch 2/5 625/625 [==============================] - 85s 136ms/step - loss: 0.3266 - binary_accuracy: 0.8547 - val_loss: 0.3659 - val_binary_accuracy: 0.8486 Epoch 3/5 625/625 [==============================] - 86s 138ms/step - loss: 0.2521 - binary_accuracy: 0.8928 - val_loss: 0.3975 - val_binary_accuracy: 0.8518 Epoch 4/5 625/625 [==============================] - 86s 137ms/step - loss: 0.1910 - binary_accuracy: 0.9269 - val_loss: 0.4180 - val_binary_accuracy: 0.8522 Epoch 5/5 625/625 [==============================] - 86s 137ms/step - loss: 0.1509 - binary_accuracy: 0.9433 - val_loss: 0.4641 - val_binary_accuracy: 0.8522
Oceń model
Zobaczmy, jak sprawuje się model. Zwrócone zostaną dwie wartości. Strata (liczba, która reprezentuje błąd, niższe wartości są lepsze) i dokładność.
loss, accuracy = classifier_model.evaluate(test_ds)
print(f'Loss: {loss}')
print(f'Accuracy: {accuracy}')
782/782 [==============================] - 61s 78ms/step - loss: 0.4495 - binary_accuracy: 0.8554 Loss: 0.4494614601135254 Accuracy: 0.8553599715232849
Wykreśl dokładność i straty w czasie
Opiera się na History obiektu zwróconego przez model.fit() . Możesz wykreślić utratę treningu i walidacji w celu porównania, a także dokładność treningu i walidacji:
history_dict = history.history
print(history_dict.keys())
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
fig = plt.figure(figsize=(10, 6))
fig.tight_layout()
plt.subplot(2, 1, 1)
# r is for "solid red line"
plt.plot(epochs, loss, 'r', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
# plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(epochs, acc, 'r', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy']) <matplotlib.legend.Legend at 0x7fee7cdb4450>
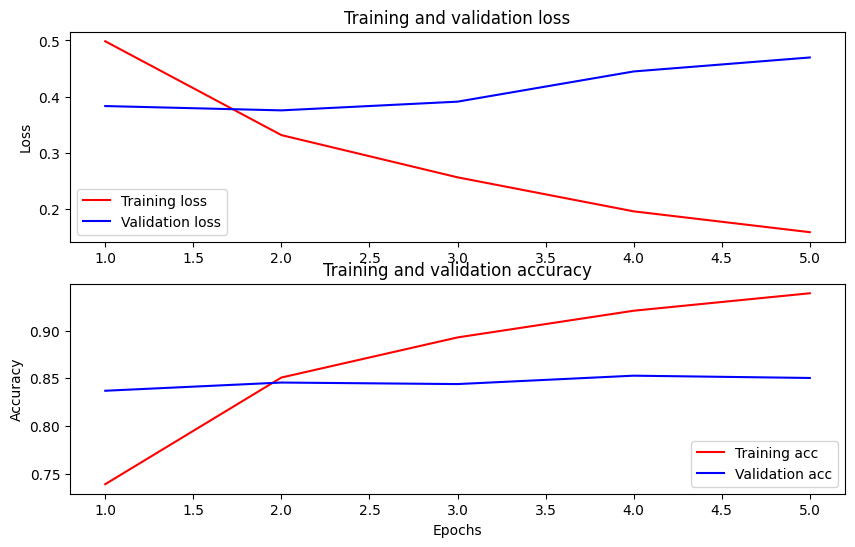
Na tym wykresie czerwone linie reprezentują stratę i dokładność treningu, a niebieskie linie to strata i dokładność walidacji.
Eksport do wnioskowania
Teraz wystarczy zapisać swój dopracowany model do późniejszego wykorzystania.
dataset_name = 'imdb'
saved_model_path = './{}_bert'.format(dataset_name.replace('/', '_'))
classifier_model.save(saved_model_path, include_optimizer=False)
2021-12-01 12:26:06.207608: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Found untraced functions such as restored_function_body, restored_function_body, restored_function_body, restored_function_body, restored_function_body while saving (showing 5 of 310). These functions will not be directly callable after loading.
Załadujmy ponownie model, aby można było go wypróbować razem z modelem, który wciąż jest w pamięci.
reloaded_model = tf.saved_model.load(saved_model_path)
Tutaj możesz przetestować swój model na dowolnym zdaniu, po prostu dodaj do zmiennej przykłady poniżej.
def print_my_examples(inputs, results):
result_for_printing = \
[f'input: {inputs[i]:<30} : score: {results[i][0]:.6f}'
for i in range(len(inputs))]
print(*result_for_printing, sep='\n')
print()
examples = [
'this is such an amazing movie!', # this is the same sentence tried earlier
'The movie was great!',
'The movie was meh.',
'The movie was okish.',
'The movie was terrible...'
]
reloaded_results = tf.sigmoid(reloaded_model(tf.constant(examples)))
original_results = tf.sigmoid(classifier_model(tf.constant(examples)))
print('Results from the saved model:')
print_my_examples(examples, reloaded_results)
print('Results from the model in memory:')
print_my_examples(examples, original_results)
Results from the saved model: input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622 Results from the model in memory: input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622
Jeśli chcesz korzystać z modelu na TF porcji , należy pamiętać, że będzie to zadzwoń do SavedModel przez jednego z jego nazwanych podpisów. W Pythonie możesz je przetestować w następujący sposób:
serving_results = reloaded_model \
.signatures['serving_default'](tf.constant(examples))
serving_results = tf.sigmoid(serving_results['classifier'])
print_my_examples(examples, serving_results)
input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622
Następne kroki
W następnym kroku, można spróbować rozwiązać zadania klej za pomocą BERT na tutorialu TPU , która biegnie na TPU i pokazuje, jak pracować z wieloma wejściami.