
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Ten samouczek przedstawia klasyfikację tekstu, zaczynając od zwykłych plików tekstowych przechowywanych na dysku. Nauczysz klasyfikatora binarnego, aby przeprowadzał analizę tonacji w zestawie danych IMDB. Na końcu zeszytu jest ćwiczenie do wypróbowania, w którym nauczysz klasyfikatora wieloklasowego, aby przewidywał tag dla pytania programistycznego na Stack Overflow.
import matplotlib.pyplot as plt
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import losses
print(tf.__version__)
2.8.0-rc1
Analiza sentymentu
Ten notatnik szkoli model analizy nastrojów, aby klasyfikować recenzje filmów jako pozytywne lub negatywne , na podstawie tekstu recenzji. Jest to przykład klasyfikacji binarnej — lub dwuklasowej — ważnego i szeroko stosowanego rodzaju problemu uczenia maszynowego.
Użyjesz zbioru danych recenzji dużych filmów , który zawiera tekst 50 000 recenzji filmów z internetowej bazy danych filmów . Są one podzielone na 25 000 recenzji do szkolenia i 25 000 recenzji do testów. Zestawy szkoleniowe i testowe są zrównoważone , co oznacza, że zawierają równą liczbę pozytywnych i negatywnych recenzji.
Pobierz i poznaj zbiór danych IMDB
Pobierzmy i wyodrębnijmy zestaw danych, a następnie zbadajmy strukturę katalogów.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 6s 0us/step 84140032/84125825 [==============================] - 6s 0us/step
os.listdir(dataset_dir)
['test', 'README', 'imdbEr.txt', 'imdb.vocab', 'train']
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['neg', 'urls_neg.txt', 'unsup', 'unsupBow.feat', 'urls_unsup.txt', 'urls_pos.txt', 'labeledBow.feat', 'pos']
aclImdb/train/pos i aclImdb/train/neg zawierają wiele plików tekstowych, z których każdy jest pojedynczym przeglądem filmu. Przyjrzyjmy się jednemu z nich.
sample_file = os.path.join(train_dir, 'pos/1181_9.txt')
with open(sample_file) as f:
print(f.read())
Rachel Griffiths writes and directs this award winning short film. A heartwarming story about coping with grief and cherishing the memory of those we've loved and lost. Although, only 15 minutes long, Griffiths manages to capture so much emotion and truth onto film in the short space of time. Bud Tingwell gives a touching performance as Will, a widower struggling to cope with his wife's death. Will is confronted by the harsh reality of loneliness and helplessness as he proceeds to take care of Ruth's pet cow, Tulip. The film displays the grief and responsibility one feels for those they have loved and lost. Good cinematography, great direction, and superbly acted. It will bring tears to all those who have lost a loved one, and survived.
Załaduj zbiór danych
Następnie załadujesz dane z dysku i przygotujesz je do formatu odpowiedniego do treningu. Aby to zrobić, użyjesz przydatnego narzędzia text_dataset_from_directory , które oczekuje następującej struktury katalogów.
main_directory/
...class_a/
......a_text_1.txt
......a_text_2.txt
...class_b/
......b_text_1.txt
......b_text_2.txt
Aby przygotować zestaw danych do klasyfikacji binarnej, potrzebujesz dwóch folderów na dysku, odpowiadających class_a i class_b . Będą to pozytywne i negatywne recenzje filmów, które można znaleźć w aclImdb/train/pos i aclImdb/train/neg . Ponieważ zbiór danych IMDB zawiera dodatkowe foldery, usuniesz je przed użyciem tego narzędzia.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Następnie użyjesz narzędzia text_dataset_from_directory , aby utworzyć etykietę tf.data.Dataset . tf.data to potężny zbiór narzędzi do pracy z danymi.
Podczas przeprowadzania eksperymentu uczenia maszynowego najlepszym sposobem jest podzielenie zestawu danych na trzy części: trenowanie , weryfikację i testowanie .
Zbiór danych IMDB został już podzielony na pociąg i test, ale brakuje w nim zestawu walidacyjnego. Utwórzmy zestaw walidacyjny, używając podziału 80:20 danych uczących, używając poniższego argumentu validation_split .
batch_size = 32
seed = 42
raw_train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training.
Jak widać powyżej, w folderze szkoleniowym znajduje się 25 000 przykładów, z których 80% (lub 20 000) wykorzystasz do szkolenia. Jak zobaczysz za chwilę, możesz trenować model, przekazując zbiór danych bezpośrednio do model.fit . Jeśli jesteś nowicjuszem w tf.data , możesz również iterować po zbiorze danych i wydrukować kilka przykładów w następujący sposób.
for text_batch, label_batch in raw_train_ds.take(1):
for i in range(3):
print("Review", text_batch.numpy()[i])
print("Label", label_batch.numpy()[i])
Review b'"Pandemonium" is a horror movie spoof that comes off more stupid than funny. Believe me when I tell you, I love comedies. Especially comedy spoofs. "Airplane", "The Naked Gun" trilogy, "Blazing Saddles", "High Anxiety", and "Spaceballs" are some of my favorite comedies that spoof a particular genre. "Pandemonium" is not up there with those films. Most of the scenes in this movie had me sitting there in stunned silence because the movie wasn\'t all that funny. There are a few laughs in the film, but when you watch a comedy, you expect to laugh a lot more than a few times and that\'s all this film has going for it. Geez, "Scream" had more laughs than this film and that was more of a horror film. How bizarre is that?<br /><br />*1/2 (out of four)' Label 0 Review b"David Mamet is a very interesting and a very un-equal director. His first movie 'House of Games' was the one I liked best, and it set a series of films with characters whose perspective of life changes as they get into complicated situations, and so does the perspective of the viewer.<br /><br />So is 'Homicide' which from the title tries to set the mind of the viewer to the usual crime drama. The principal characters are two cops, one Jewish and one Irish who deal with a racially charged area. The murder of an old Jewish shop owner who proves to be an ancient veteran of the Israeli Independence war triggers the Jewish identity in the mind and heart of the Jewish detective.<br /><br />This is were the flaws of the film are the more obvious. The process of awakening is theatrical and hard to believe, the group of Jewish militants is operatic, and the way the detective eventually walks to the final violent confrontation is pathetic. The end of the film itself is Mamet-like smart, but disappoints from a human emotional perspective.<br /><br />Joe Mantegna and William Macy give strong performances, but the flaws of the story are too evident to be easily compensated." Label 0 Review b'Great documentary about the lives of NY firefighters during the worst terrorist attack of all time.. That reason alone is why this should be a must see collectors item.. What shocked me was not only the attacks, but the"High Fat Diet" and physical appearance of some of these firefighters. I think a lot of Doctors would agree with me that,in the physical shape they were in, some of these firefighters would NOT of made it to the 79th floor carrying over 60 lbs of gear. Having said that i now have a greater respect for firefighters and i realize becoming a firefighter is a life altering job. The French have a history of making great documentary\'s and that is what this is, a Great Documentary.....' Label 1
Zwróć uwagę, że recenzje zawierają surowy tekst (z interpunkcją i okazjonalnymi znacznikami HTML, takimi jak <br/> ). W następnej sekcji pokażesz, jak sobie z nimi radzić.
Etykiety to 0 lub 1. Aby zobaczyć, które z nich odpowiadają pozytywnym i negatywnym recenzjom filmów, możesz sprawdzić właściwość class_names w zbiorze danych.
print("Label 0 corresponds to", raw_train_ds.class_names[0])
print("Label 1 corresponds to", raw_train_ds.class_names[1])
Label 0 corresponds to neg Label 1 corresponds to pos
Następnie utworzysz zestaw danych walidacyjnych i testowych. Do walidacji wykorzystasz pozostałe 5000 recenzji z zestawu szkoleniowego.
raw_val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
Found 25000 files belonging to 2 classes. Using 5000 files for validation.
raw_test_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
Found 25000 files belonging to 2 classes.
Przygotuj zbiór danych do szkolenia
Następnie standaryzujesz, tokenizujesz i wektoryzujesz dane za pomocą pomocnej warstwy tf.keras.layers.TextVectorization .
Standaryzacja odnosi się do wstępnego przetwarzania tekstu, zwykle w celu usunięcia interpunkcji lub elementów HTML w celu uproszczenia zestawu danych. Tokenizacja odnosi się do dzielenia ciągów na tokeny (na przykład dzielenia zdania na pojedyncze słowa poprzez dzielenie na białych znakach). Wektoryzacja odnosi się do konwersji tokenów na liczby, aby można je było wprowadzić do sieci neuronowej. Wszystkie te zadania można wykonać za pomocą tej warstwy.
Jak widzieliście powyżej, recenzje zawierają różne tagi HTML, takie jak <br /> . Te znaczniki nie zostaną usunięte przez domyślny standaryzator w warstwie TextVectorization (który domyślnie konwertuje tekst na małe litery i usuwa znaki interpunkcyjne, ale nie usuwa kodu HTML). Napiszesz niestandardową funkcję standaryzacji, aby usunąć kod HTML.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation),
'')
Następnie utworzysz warstwę TextVectorization . Użyjesz tej warstwy do standaryzacji, tokenizacji i wektoryzacji naszych danych. output_mode na int , aby tworzyć unikalne indeksy liczb całkowitych dla każdego tokena.
Pamiętaj, że używasz domyślnej funkcji podziału i niestandardowej funkcji standaryzacji zdefiniowanej powyżej. Zdefiniujesz również pewne stałe dla modelu, takie jak jawna maksymalna sequence_length , która spowoduje, że warstwa będzie wypełniać lub skracać sequence_length do dokładnie wartości długości_sekwencji.
max_features = 10000
sequence_length = 250
vectorize_layer = layers.TextVectorization(
standardize=custom_standardization,
max_tokens=max_features,
output_mode='int',
output_sequence_length=sequence_length)
Następnie wywołasz adapt , aby dopasować stan warstwy przetwarzania wstępnego do zestawu danych. Spowoduje to, że model zbuduje indeks ciągów do liczb całkowitych.
# Make a text-only dataset (without labels), then call adapt
train_text = raw_train_ds.map(lambda x, y: x)
vectorize_layer.adapt(train_text)
Utwórzmy funkcję, aby zobaczyć wynik użycia tej warstwy do wstępnego przetworzenia niektórych danych.
def vectorize_text(text, label):
text = tf.expand_dims(text, -1)
return vectorize_layer(text), label
# retrieve a batch (of 32 reviews and labels) from the dataset
text_batch, label_batch = next(iter(raw_train_ds))
first_review, first_label = text_batch[0], label_batch[0]
print("Review", first_review)
print("Label", raw_train_ds.class_names[first_label])
print("Vectorized review", vectorize_text(first_review, first_label))
Review tf.Tensor(b'Great movie - especially the music - Etta James - "At Last". This speaks volumes when you have finally found that special someone.', shape=(), dtype=string)
Label neg
Vectorized review (<tf.Tensor: shape=(1, 250), dtype=int64, numpy=
array([[ 86, 17, 260, 2, 222, 1, 571, 31, 229, 11, 2418,
1, 51, 22, 25, 404, 251, 12, 306, 282, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]])>, <tf.Tensor: shape=(), dtype=int32, numpy=0>)
Jak widać powyżej, każdy token został zastąpiony liczbą całkowitą. Możesz wyszukać token (łańcuch), któremu odpowiada każda liczba całkowita, wywołując .get_vocabulary() na warstwie.
print("1287 ---> ",vectorize_layer.get_vocabulary()[1287])
print(" 313 ---> ",vectorize_layer.get_vocabulary()[313])
print('Vocabulary size: {}'.format(len(vectorize_layer.get_vocabulary())))
1287 ---> silent 313 ---> night Vocabulary size: 10000
Jesteś już prawie gotowy do trenowania swojego modelu. Jako ostatni etap przetwarzania wstępnego zastosujesz utworzoną wcześniej warstwę TextVectorization do zestawu danych do pociągu, walidacji i testu.
train_ds = raw_train_ds.map(vectorize_text)
val_ds = raw_val_ds.map(vectorize_text)
test_ds = raw_test_ds.map(vectorize_text)
Skonfiguruj zbiór danych pod kątem wydajności
Są to dwie ważne metody, których należy użyć podczas ładowania danych, aby upewnić się, że operacje we/wy nie zostaną zablokowane.
.cache() przechowuje dane w pamięci po ich załadowaniu z dysku. Zapewni to, że zestaw danych nie stanie się wąskim gardłem podczas trenowania modelu. Jeśli zestaw danych jest zbyt duży, aby zmieścić się w pamięci, możesz również użyć tej metody, aby utworzyć wydajną pamięć podręczną na dysku, która jest bardziej wydajna do odczytu niż wiele małych plików.
.prefetch() nakłada się na wstępne przetwarzanie danych i wykonywanie modelu podczas uczenia.
Więcej informacji na temat obu metod oraz sposobu buforowania danych na dysku można znaleźć w przewodniku po wydajności danych .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
Stwórz model
Czas stworzyć swoją sieć neuronową:
embedding_dim = 16
model = tf.keras.Sequential([
layers.Embedding(max_features + 1, embedding_dim),
layers.Dropout(0.2),
layers.GlobalAveragePooling1D(),
layers.Dropout(0.2),
layers.Dense(1)])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 16) 160016
dropout (Dropout) (None, None, 16) 0
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dropout_1 (Dropout) (None, 16) 0
dense (Dense) (None, 1) 17
=================================================================
Total params: 160,033
Trainable params: 160,033
Non-trainable params: 0
_________________________________________________________________
Warstwy są układane w stos sekwencyjny, aby zbudować klasyfikator:
- Pierwsza warstwa to warstwa
Embedding. Ta warstwa pobiera recenzje zakodowane w liczbach całkowitych i wyszukuje wektor osadzenia dla każdego indeksu słów. Te wektory są uczone jako ciągi modelu. Wektory dodają wymiar do tablicy wyjściowej. Wynikowe wymiary to:(batch, sequence, embedding). Aby dowiedzieć się więcej o osadzaniach, zapoznaj się z samouczkiem dotyczącym osadzania słów . - Następnie warstwa
GlobalAveragePooling1Dzwraca wektor wyjściowy o stałej długości dla każdego przykładu, uśredniając wymiar sekwencji. Umożliwia to modelowi obsługę danych wejściowych o zmiennej długości w najprostszy możliwy sposób. - Ten wektor wyjściowy o stałej długości jest przesyłany przez w pełni połączoną warstwę (
Dense) z 16 ukrytymi jednostkami. - Ostatnia warstwa jest gęsto połączona z pojedynczym węzłem wyjściowym.
Funkcja strat i optymalizator
Model potrzebuje funkcji straty i optymalizatora do uczenia. Ponieważ jest to problem klasyfikacji binarnej, a model wyprowadza prawdopodobieństwo (warstwa z jedną jednostką z aktywacją sigmoidalną), użyjesz funkcji losses.BinaryCrossentropy loss function.
Teraz skonfiguruj model tak, aby używał optymalizatora i funkcji straty:
model.compile(loss=losses.BinaryCrossentropy(from_logits=True),
optimizer='adam',
metrics=tf.metrics.BinaryAccuracy(threshold=0.0))
Trenuj modelkę
Nauczysz model, przekazując obiekt dataset do metody fit.
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs)
Epoch 1/10 625/625 [==============================] - 4s 4ms/step - loss: 0.6644 - binary_accuracy: 0.6894 - val_loss: 0.6159 - val_binary_accuracy: 0.7696 Epoch 2/10 625/625 [==============================] - 2s 4ms/step - loss: 0.5494 - binary_accuracy: 0.8020 - val_loss: 0.4993 - val_binary_accuracy: 0.8226 Epoch 3/10 625/625 [==============================] - 2s 3ms/step - loss: 0.4450 - binary_accuracy: 0.8447 - val_loss: 0.4205 - val_binary_accuracy: 0.8466 Epoch 4/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3778 - binary_accuracy: 0.8659 - val_loss: 0.3740 - val_binary_accuracy: 0.8618 Epoch 5/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3357 - binary_accuracy: 0.8785 - val_loss: 0.3451 - val_binary_accuracy: 0.8678 Epoch 6/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3055 - binary_accuracy: 0.8885 - val_loss: 0.3260 - val_binary_accuracy: 0.8700 Epoch 7/10 625/625 [==============================] - 2s 3ms/step - loss: 0.2817 - binary_accuracy: 0.8971 - val_loss: 0.3126 - val_binary_accuracy: 0.8730 Epoch 8/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2616 - binary_accuracy: 0.9034 - val_loss: 0.3037 - val_binary_accuracy: 0.8754 Epoch 9/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2458 - binary_accuracy: 0.9110 - val_loss: 0.2965 - val_binary_accuracy: 0.8788 Epoch 10/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2319 - binary_accuracy: 0.9158 - val_loss: 0.2920 - val_binary_accuracy: 0.8792
Oceń model
Zobaczmy, jak sprawuje się model. Zwrócone zostaną dwie wartości. Strata (liczba, która reprezentuje nasz błąd, niższe wartości są lepsze) i dokładność.
loss, accuracy = model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
782/782 [==============================] - 2s 2ms/step - loss: 0.3104 - binary_accuracy: 0.8735 Loss: 0.3104138672351837 Accuracy: 0.873520016670227
To dość naiwne podejście osiąga dokładność około 86%.
Stwórz wykres dokładności i strat w czasie
model.fit() zwraca obiekt History , który zawiera słownik ze wszystkim, co wydarzyło się podczas uczenia:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy'])
Istnieją cztery wpisy: po jednym dla każdej metryki monitorowanej podczas uczenia i walidacji. Możesz ich użyć do wykreślenia utraty uczenia się i walidacji w celu porównania, a także dokładności uczenia i walidacji:
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
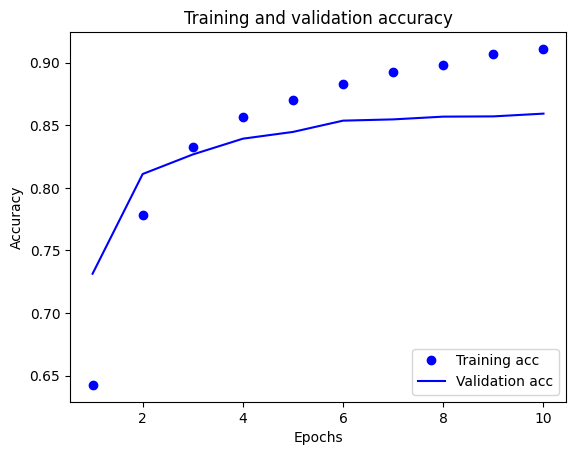
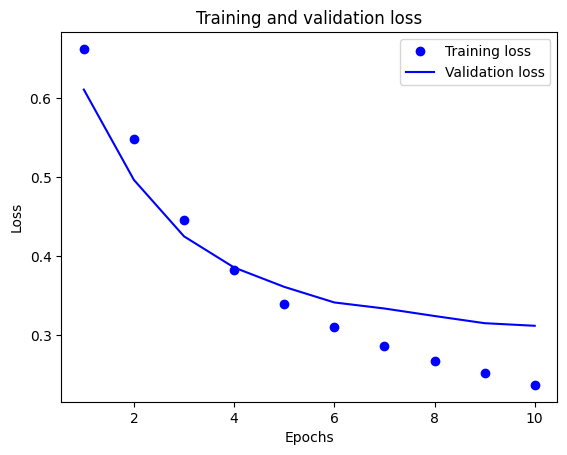
Na tym wykresie kropki reprezentują utratę i dokładność treningu, a linie ciągłe oznaczają utratę i dokładność walidacji.
Zauważ, że utrata treningu zmniejsza się z każdą epoką, a dokładność treningu wzrasta z każdą epoką. Jest to oczekiwane podczas korzystania z optymalizacji gradientu — powinno to minimalizować żądaną ilość w każdej iteracji.
Nie dotyczy to utraty i dokładności walidacji — wydaje się, że osiągają one szczyt przed dokładnością treningu. Jest to przykład nadmiernego dopasowania: model działa lepiej na danych uczących niż na danych, których nigdy wcześniej nie widział. Po tym punkcie model nadmiernie optymalizuje i uczy się reprezentacji specyficznych dla danych uczących, które nie są uogólniane na dane testowe.
W tym konkretnym przypadku można zapobiec nadmiernemu dopasowaniu, po prostu przerywając szkolenie, gdy dokładność walidacji już nie wzrasta. Jednym ze sposobów na to jest użycie wywołania zwrotnego tf.keras.callbacks.EarlyStopping .
Eksportuj model
W powyższym kodzie zastosowałeś warstwę TextVectorization do zestawu danych przed wprowadzeniem tekstu do modelu. Jeśli chcesz, aby Twój model mógł przetwarzać nieprzetworzone ciągi (na przykład, aby uprościć jego wdrażanie), możesz dołączyć warstwę TextVectorization do swojego modelu. Aby to zrobić, możesz utworzyć nowy model, korzystając z wag, które właśnie wytrenowałeś.
export_model = tf.keras.Sequential([
vectorize_layer,
model,
layers.Activation('sigmoid')
])
export_model.compile(
loss=losses.BinaryCrossentropy(from_logits=False), optimizer="adam", metrics=['accuracy']
)
# Test it with `raw_test_ds`, which yields raw strings
loss, accuracy = export_model.evaluate(raw_test_ds)
print(accuracy)
782/782 [==============================] - 3s 4ms/step - loss: 0.3104 - accuracy: 0.8735 0.873520016670227
Wnioskowanie o nowych danych
Aby uzyskać prognozy dla nowych przykładów, możesz po prostu wywołać model.predict() .
examples = [
"The movie was great!",
"The movie was okay.",
"The movie was terrible..."
]
export_model.predict(examples)
array([[0.60320234],
[0.4262717 ],
[0.34439093]], dtype=float32)
Dołączenie logiki wstępnego przetwarzania tekstu do modelu umożliwia wyeksportowanie modelu do produkcji, co upraszcza wdrażanie i zmniejsza ryzyko pochylenia trenowania/testowania .
Przy wyborze miejsca zastosowania warstwy TextVectorization należy pamiętać o różnicy w wydajności. Używanie go poza modelem umożliwia asynchroniczne przetwarzanie procesora i buforowanie danych podczas uczenia na GPU. Jeśli więc trenujesz swój model na GPU, prawdopodobnie chcesz skorzystać z tej opcji, aby uzyskać najlepszą wydajność podczas opracowywania modelu, a następnie przełącz się na włączenie warstwy TextVectorization do modelu, gdy będziesz gotowy do przygotowania do wdrożenia .
Odwiedź ten samouczek , aby dowiedzieć się więcej o zapisywaniu modeli.
Ćwiczenie: klasyfikacja wieloklasowa na pytaniach Stack Overflow
W tym samouczku pokazano, jak nauczyć klasyfikatora binarnego od podstaw w zestawie danych IMDB. W ramach ćwiczenia możesz zmodyfikować ten notatnik, aby wytrenować klasyfikator wieloklasowy w celu przewidywania tagu pytania programistycznego w Stack Overflow .
Zestaw danych został przygotowany do użycia, zawierający treść kilku tysięcy pytań programistycznych (na przykład „Jak posortować słownik według wartości w Pythonie?”) przesłanych do Stack Overflow. Każdy z nich jest oznaczony dokładnie jednym tagiem (Python, CSharp, JavaScript lub Java). Twoim zadaniem jest wzięcie pytania jako danych wejściowych i przewidzenie odpowiedniego znacznika, w tym przypadku Pythona.
Zbiór danych, z którym będziesz pracować, zawiera kilka tysięcy pytań wyodrębnionych ze znacznie większego publicznego zbioru danych Stack Overflow w BigQuery , który zawiera ponad 17 milionów postów.
Po pobraniu zestawu danych okaże się, że ma on podobną strukturę katalogów do zestawu danych IMDB, z którym pracowałeś wcześniej:
train/
...python/
......0.txt
......1.txt
...javascript/
......0.txt
......1.txt
...csharp/
......0.txt
......1.txt
...java/
......0.txt
......1.txt
Aby ukończyć to ćwiczenie, należy zmodyfikować ten notatnik, aby działał z zestawem danych Stack Overflow, wprowadzając następujące modyfikacje:
W górnej części notesu zaktualizuj kod, który pobiera zestaw danych IMDB za pomocą kodu, aby pobrać zestaw danych przepełnienia stosu , który został już przygotowany. Ponieważ zestaw danych Stack Overflow ma podobną strukturę katalogów, nie będziesz musiał dokonywać wielu modyfikacji.
Zmodyfikuj ostatnią warstwę swojego modelu na
Dense(4), ponieważ istnieją teraz cztery klasy wyjściowe.Podczas kompilowania modelu zmień stratę na
tf.keras.losses.SparseCategoricalCrossentropy. Jest to właściwa funkcja straty do użycia w przypadku problemu klasyfikacji wieloklasowej, gdy etykiety dla każdej klasy są liczbami całkowitymi (w tym przypadku mogą to być 0, 1 , 2 lub 3 ). Ponadto zmień metryki nametrics=['accuracy'], ponieważ jest to problem klasyfikacji wieloklasowej (tf.metrics.BinaryAccuracyjest używany tylko w przypadku klasyfikatorów binarnych).Podczas wykreślania dokładności w czasie zmień
binary_accuracyival_binary_accuracyodpowiednio naaccuracyival_accuracy.Po wprowadzeniu tych zmian będzie można szkolić klasyfikatora wieloklasowego.
Uczyć się więcej
Ten samouczek wprowadził klasyfikację tekstu od podstaw. Aby ogólnie dowiedzieć się więcej o przepływie pracy klasyfikacji tekstu, zapoznaj się z przewodnikiem klasyfikacji tekstu dostępnym w witrynie Google Developers.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.