
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Ten samouczek zawiera wprowadzenie do osadzania słów. Wytrenujesz własne osadzanie słów przy użyciu prostego modelu Keras dla zadania klasyfikacji tonacji, a następnie zwizualizujesz je w projektorze osadzania (pokazanym na poniższym obrazku).

Reprezentowanie tekstu w postaci liczb
Modele uczenia maszynowego przyjmują wektory (tablice liczb) jako dane wejściowe. Podczas pracy z tekstem pierwszą rzeczą, którą musisz zrobić, jest opracowanie strategii konwersji ciągów na liczby (lub „wektoryzacji” tekstu) przed wprowadzeniem go do modelu. W tej sekcji przyjrzysz się trzem strategiom, jak to zrobić.
Jeden gorący kodowanie
Jako pierwszy pomysł możesz zakodować każde słowo w swoim słowniku „na gorąco”. Rozważ zdanie „Kot usiadł na macie”. Słownictwo (lub unikalne słowa) w tym zdaniu to (kot, mata, on, sat, the). Aby przedstawić każde słowo, utworzysz wektor zerowy o długości równej słownictwu, a następnie umieścisz w indeksie jedynkę, która odpowiada temu słowu. To podejście pokazano na poniższym diagramie.
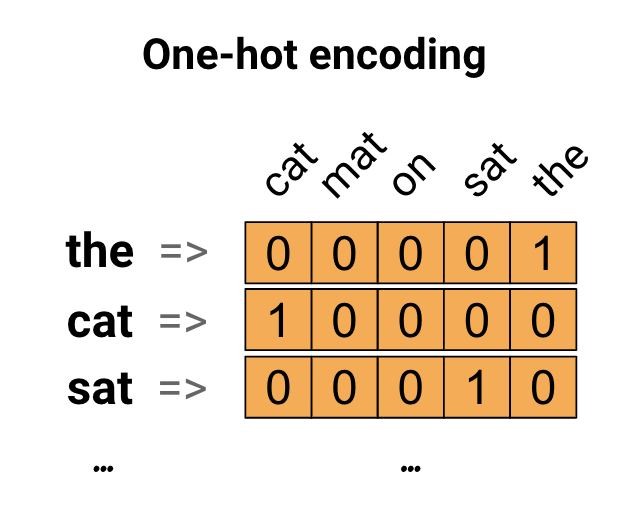
Aby utworzyć wektor, który zawiera kodowanie zdania, możesz połączyć wektory z jednym gorącym elementem dla każdego słowa.
Zakoduj każde słowo unikalnym numerem
Drugim podejściem, które możesz wypróbować, jest zakodowanie każdego słowa przy użyciu unikalnej liczby. Kontynuując powyższy przykład, możesz przypisać 1 do „kot”, 2 do „mat” i tak dalej. Możesz wtedy zakodować zdanie „Kot usiadł na macie” jako gęsty wektor, taki jak [5, 1, 4, 3, 5, 2]. Takie podejście jest efektywne. Zamiast rzadkiego wektora masz teraz gęsty (gdzie wszystkie elementy są pełne).
Istnieją jednak dwie wady tego podejścia:
Kodowanie liczb całkowitych jest dowolne (nie obejmuje żadnego związku między słowami).
Interpretacja kodowania liczb całkowitych może być wyzwaniem dla modelu. Na przykład klasyfikator liniowy uczy się pojedynczej wagi dla każdej cechy. Ponieważ nie ma związku między podobieństwem dowolnych dwóch słów a podobieństwem ich kodowania, ta kombinacja wagi funkcji nie ma znaczenia.
Osadzanie słów
Osadzanie słów daje nam sposób na użycie wydajnej, gęstej reprezentacji, w której podobne słowa mają podobne kodowanie. Co ważne, nie musisz ręcznie określać tego kodowania. Osadzanie to gęsty wektor wartości zmiennoprzecinkowych (długość wektora jest parametrem, który określasz). Zamiast ręcznie określać wartości dla osadzania, są to parametry możliwe do trenowania (wagi nauczone przez model podczas uczenia, w ten sam sposób, w jaki model uczy się wag dla gęstej warstwy). Podczas pracy z dużymi zestawami danych często można zobaczyć osadzania słów, które są 8-wymiarowe (w przypadku małych zestawów danych), do 1024-wymiarów. Osadzanie w wyższych wymiarach może uchwycić szczegółowe relacje między słowami, ale wymaga więcej danych do nauczenia.
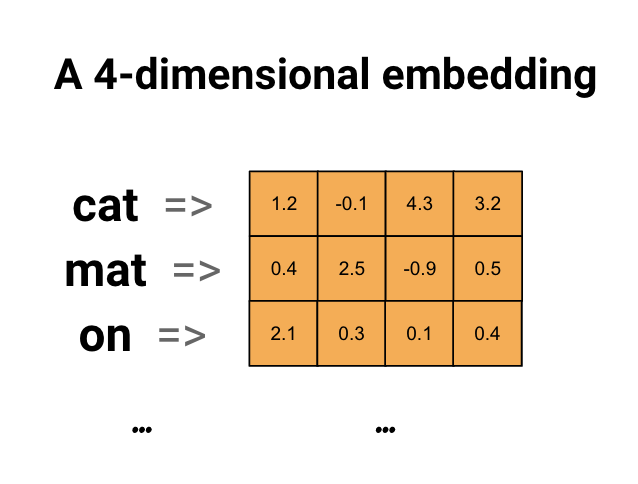
Powyżej znajduje się schemat osadzania słów. Każde słowo jest reprezentowane jako 4-wymiarowy wektor wartości zmiennoprzecinkowych. Innym sposobem myślenia o osadzeniu jest „tabela przeglądowa”. Po nauczeniu się tych wag możesz zakodować każde słowo, wyszukując gęsty wektor, któremu odpowiada w tabeli.
Ustawiać
import io
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Embedding, GlobalAveragePooling1D
from tensorflow.keras.layers import TextVectorization
Pobierz zbiór danych IMDb
W tym samouczku będziesz korzystać z zestawu danych przeglądu dużego filmu . Będziesz trenował model klasyfikatora sentymentu na tym zestawie danych i w trakcie tego procesu nauczysz się osadzania od podstaw. Aby dowiedzieć się więcej o ładowaniu zestawu danych od podstaw, zobacz samouczek Ładowanie tekstu .
Pobierz zestaw danych za pomocą narzędzia Keras do plików i spójrz na katalogi.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1.tar.gz", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
os.listdir(dataset_dir)
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 7s 0us/step 84140032/84125825 [==============================] - 7s 0us/step ['test', 'imdb.vocab', 'imdbEr.txt', 'train', 'README']
Spójrz na katalog train/ . Posiada foldery pos i neg z recenzjami filmów odpowiednio oznaczonymi jako pozytywne i negatywne. Użyjesz recenzji z folderów pos i neg , aby wytrenować binarny model klasyfikacji.
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['urls_pos.txt', 'urls_unsup.txt', 'urls_neg.txt', 'pos', 'unsup', 'unsupBow.feat', 'neg', 'labeledBow.feat']
Katalog train zawiera również dodatkowe foldery, które należy usunąć przed utworzeniem zestawu danych szkoleniowych.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Następnie utwórz tf.data.Dataset przy użyciu tf.keras.utils.text_dataset_from_directory . Więcej informacji na temat korzystania z tego narzędzia można znaleźć w tym samouczku klasyfikacji tekstu .
Użyj katalogu train , aby utworzyć zestawy danych pociągów i walidacji z podziałem 20% na potrzeby walidacji.
batch_size = 1024
seed = 123
train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='training', seed=seed)
val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='validation', seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training. Found 25000 files belonging to 2 classes. Using 5000 files for validation.
Spójrz na kilka recenzji filmów i ich etykiety (1: positive, 0: negative) ze zbioru danych pociągu.
for text_batch, label_batch in train_ds.take(1):
for i in range(5):
print(label_batch[i].numpy(), text_batch.numpy()[i])
0 b"Oh My God! Please, for the love of all that is holy, Do Not Watch This Movie! It it 82 minutes of my life I will never get back. Sure, I could have stopped watching half way through. But I thought it might get better. It Didn't. Anyone who actually enjoyed this movie is one seriously sick and twisted individual. No wonder us Australians/New Zealanders have a terrible reputation when it comes to making movies. Everything about this movie is horrible, from the acting to the editing. I don't even normally write reviews on here, but in this case I'll make an exception. I only wish someone had of warned me before I hired this catastrophe" 1 b'This movie is SOOOO funny!!! The acting is WONDERFUL, the Ramones are sexy, the jokes are subtle, and the plot is just what every high schooler dreams of doing to his/her school. I absolutely loved the soundtrack as well as the carefully placed cynicism. If you like monty python, You will love this film. This movie is a tad bit "grease"esk (without all the annoying songs). The songs that are sung are likable; you might even find yourself singing these songs once the movie is through. This musical ranks number two in musicals to me (second next to the blues brothers). But please, do not think of it as a musical per say; seeing as how the songs are so likable, it is hard to tell a carefully choreographed scene is taking place. I think of this movie as more of a comedy with undertones of romance. You will be reminded of what it was like to be a rebellious teenager; needless to say, you will be reminiscing of your old high school days after seeing this film. Highly recommended for both the family (since it is a very youthful but also for adults since there are many jokes that are funnier with age and experience.' 0 b"Alex D. Linz replaces Macaulay Culkin as the central figure in the third movie in the Home Alone empire. Four industrial spies acquire a missile guidance system computer chip and smuggle it through an airport inside a remote controlled toy car. Because of baggage confusion, grouchy Mrs. Hess (Marian Seldes) gets the car. She gives it to her neighbor, Alex (Linz), just before the spies turn up. The spies rent a house in order to burglarize each house in the neighborhood until they locate the car. Home alone with the chicken pox, Alex calls 911 each time he spots a theft in progress, but the spies always manage to elude the police while Alex is accused of making prank calls. The spies finally turn their attentions toward Alex, unaware that he has rigged devices to cleverly booby-trap his entire house. Home Alone 3 wasn't horrible, but probably shouldn't have been made, you can't just replace Macauley Culkin, Joe Pesci, or Daniel Stern. Home Alone 3 had some funny parts, but I don't like when characters are changed in a movie series, view at own risk." 0 b"There's a good movie lurking here, but this isn't it. The basic idea is good: to explore the moral issues that would face a group of young survivors of the apocalypse. But the logic is so muddled that it's impossible to get involved.<br /><br />For example, our four heroes are (understandably) paranoid about catching the mysterious airborne contagion that's wiped out virtually all of mankind. Yet they wear surgical masks some times, not others. Some times they're fanatical about wiping down with bleach any area touched by an infected person. Other times, they seem completely unconcerned.<br /><br />Worse, after apparently surviving some weeks or months in this new kill-or-be-killed world, these people constantly behave like total newbs. They don't bother accumulating proper equipment, or food. They're forever running out of fuel in the middle of nowhere. They don't take elementary precautions when meeting strangers. And after wading through the rotting corpses of the entire human race, they're as squeamish as sheltered debutantes. You have to constantly wonder how they could have survived this long... and even if they did, why anyone would want to make a movie about them.<br /><br />So when these dweebs stop to agonize over the moral dimensions of their actions, it's impossible to take their soul-searching seriously. Their actions would first have to make some kind of minimal sense.<br /><br />On top of all this, we must contend with the dubious acting abilities of Chris Pine. His portrayal of an arrogant young James T Kirk might have seemed shrewd, when viewed in isolation. But in Carriers he plays on exactly that same note: arrogant and boneheaded. It's impossible not to suspect that this constitutes his entire dramatic range.<br /><br />On the positive side, the film *looks* excellent. It's got an over-sharp, saturated look that really suits the southwestern US locale. But that can't save the truly feeble writing nor the paper-thin (and annoying) characters. Even if you're a fan of the end-of-the-world genre, you should save yourself the agony of watching Carriers." 0 b'I saw this movie at an actual movie theater (probably the \\(2.00 one) with my cousin and uncle. We were around 11 and 12, I guess, and really into scary movies. I remember being so excited to see it because my cool uncle let us pick the movie (and we probably never got to do that again!) and sooo disappointed afterwards!! Just boring and not scary. The only redeeming thing I can remember was Corky Pigeon from Silver Spoons, and that wasn\'t all that great, just someone I recognized. I\'ve seen bad movies before and this one has always stuck out in my mind as the worst. This was from what I can recall, one of the most boring, non-scary, waste of our collective \\)6, and a waste of film. I have read some of the reviews that say it is worth a watch and I say, "Too each his own", but I wouldn\'t even bother. Not even so bad it\'s good.'
Skonfiguruj zbiór danych pod kątem wydajności
Są to dwie ważne metody, których należy użyć podczas ładowania danych, aby upewnić się, że operacje we/wy nie zostaną zablokowane.
.cache() przechowuje dane w pamięci po ich załadowaniu z dysku. Zapewni to, że zestaw danych nie stanie się wąskim gardłem podczas trenowania modelu. Jeśli zestaw danych jest zbyt duży, aby zmieścić się w pamięci, możesz również użyć tej metody, aby utworzyć wydajną pamięć podręczną na dysku, która jest bardziej wydajna do odczytu niż wiele małych plików.
.prefetch() nakłada się na wstępne przetwarzanie danych i wykonywanie modelu podczas uczenia.
Więcej informacji na temat obu metod oraz sposobu buforowania danych na dysku można znaleźć w przewodniku po wydajności danych .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
Korzystanie z warstwy osadzania
Keras ułatwia korzystanie z osadzania słów. Spójrz na warstwę Osadzanie .
Warstwa osadzania może być rozumiana jako tabela przeglądowa, która odwzorowuje indeksy liczb całkowitych (które oznaczają określone słowa) na gęste wektory (ich osadzenia). Wymiarowość (lub szerokość) osadzania jest parametrem, z którym możesz poeksperymentować, aby zobaczyć, co działa dobrze dla twojego problemu, podobnie jak eksperymentujesz z liczbą neuronów w warstwie Gęstej.
# Embed a 1,000 word vocabulary into 5 dimensions.
embedding_layer = tf.keras.layers.Embedding(1000, 5)
Podczas tworzenia warstwy osadzania wagi osadzania są inicjowane losowo (tak jak każda inna warstwa). Podczas treningu są one stopniowo dostosowywane poprzez wsteczną propagację. Po nauczeniu wyuczone osadzania słów będą z grubsza kodować podobieństwa między słowami (tak jak zostały nauczone dla konkretnego problemu, na którym trenowany jest twój model).
Jeśli przekażesz liczbę całkowitą do warstwy osadzania, wynik zastępuje każdą liczbę całkowitą wektorem z tabeli osadzania:
result = embedding_layer(tf.constant([1, 2, 3]))
result.numpy()
array([[ 0.01318491, -0.02219239, 0.024673 , -0.03208025, 0.02297195],
[-0.00726584, 0.03731754, -0.01209557, -0.03887399, -0.02407478],
[ 0.04477594, 0.04504738, -0.02220147, -0.03642888, -0.04688282]],
dtype=float32)
W przypadku problemów z tekstem lub sekwencją warstwa osadzania przyjmuje dwuwymiarowy tensor liczb całkowitych o kształcie (samples, sequence_length) , gdzie każdy wpis jest sekwencją liczb całkowitych. Może osadzać sekwencje o różnej długości. Do warstwy zatapialnej można było wprowadzać nad partiami o kształtach (32, 10) (partia 32 sekwencji o długości 10) lub (64, 15) (partia 64 sekwencji o długości 15).
Zwrócony tensor ma o jedną oś więcej niż wejście, wektory osadzenia są wyrównane wzdłuż nowej ostatniej osi. Podaj (2, 3) partię wejściową, a wyjście to (2, 3, N)
result = embedding_layer(tf.constant([[0, 1, 2], [3, 4, 5]]))
result.shape
TensorShape([2, 3, 5])
Po otrzymaniu partii sekwencji jako danych wejściowych warstwa osadzania zwraca tensor zmiennoprzecinkowy 3D o kształcie (samples, sequence_length, embedding_dimensionality) . Istnieje wiele standardowych podejść do konwersji z tej sekwencji o zmiennej długości do stałej reprezentacji. Możesz użyć warstwy RNN, uwagi lub puli przed przekazaniem jej do warstwy gęstej. Ten samouczek używa puli, ponieważ jest najprostszy. Dobrym następnym krokiem jest klasyfikacja tekstu z samouczkiem RNN .
Wstępne przetwarzanie tekstu
Następnie zdefiniuj kroki przetwarzania wstępnego zestawu danych wymagane dla modelu klasyfikacji opinii. Zainicjuj warstwę TextVectorization z żądanymi parametrami, aby wektoryzować recenzje filmów. Więcej informacji na temat korzystania z tej warstwy można znaleźć w samouczku Klasyfikacja tekstu .
# Create a custom standardization function to strip HTML break tags '<br />'.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation), '')
# Vocabulary size and number of words in a sequence.
vocab_size = 10000
sequence_length = 100
# Use the text vectorization layer to normalize, split, and map strings to
# integers. Note that the layer uses the custom standardization defined above.
# Set maximum_sequence length as all samples are not of the same length.
vectorize_layer = TextVectorization(
standardize=custom_standardization,
max_tokens=vocab_size,
output_mode='int',
output_sequence_length=sequence_length)
# Make a text-only dataset (no labels) and call adapt to build the vocabulary.
text_ds = train_ds.map(lambda x, y: x)
vectorize_layer.adapt(text_ds)
Utwórz model klasyfikacji
Użyj interfejsu API Keras Sequential , aby zdefiniować model klasyfikacji opinii. W tym przypadku jest to model w stylu „Continuous bag of words”.
- Warstwa
TextVectorizationprzekształca ciągi znaków w indeksy słownictwa. Zainicjowałeś jużvectorize_layerjako warstwę TextVectorization i zbudowałeś jej słownik, wywołującadaptnatext_ds. Teraz vectorize_layer może być używana jako pierwsza warstwa Twojego modelu klasyfikacji end-to-end, dostarczając przekształcone ciągi do warstwy osadzania. Warstwa
Embeddingpobiera słownictwo zakodowane w liczbach całkowitych i wyszukuje wektor osadzania dla każdego indeksu słów. Te wektory są uczone jako ciągi modelu. Wektory dodają wymiar do tablicy wyjściowej. Wynikowe wymiary to:(batch, sequence, embedding).Warstwa
GlobalAveragePooling1Dzwraca wektor wyjściowy o stałej długości dla każdego przykładu, uśredniając wymiar sekwencji. Umożliwia to modelowi obsługę danych wejściowych o zmiennej długości w najprostszy możliwy sposób.Wektor wyjściowy o stałej długości jest przesyłany przez w pełni połączoną warstwę (
Dense) z 16 ukrytymi jednostkami.Ostatnia warstwa jest gęsto połączona z pojedynczym węzłem wyjściowym.
embedding_dim=16
model = Sequential([
vectorize_layer,
Embedding(vocab_size, embedding_dim, name="embedding"),
GlobalAveragePooling1D(),
Dense(16, activation='relu'),
Dense(1)
])
Skompiluj i trenuj model
Użyjesz TensorBoard do wizualizacji wskaźników, w tym strat i dokładności. Utwórz tf.keras.callbacks.TensorBoard .
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir="logs")
Skompiluj i wytrenuj model za pomocą optymalizatora Adam i utraty BinaryCrossentropy .
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=15,
callbacks=[tensorboard_callback])
Epoch 1/15 20/20 [==============================] - 2s 71ms/step - loss: 0.6910 - accuracy: 0.5028 - val_loss: 0.6878 - val_accuracy: 0.4886 Epoch 2/15 20/20 [==============================] - 1s 57ms/step - loss: 0.6838 - accuracy: 0.5028 - val_loss: 0.6791 - val_accuracy: 0.4886 Epoch 3/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6726 - accuracy: 0.5028 - val_loss: 0.6661 - val_accuracy: 0.4886 Epoch 4/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6563 - accuracy: 0.5028 - val_loss: 0.6481 - val_accuracy: 0.4886 Epoch 5/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6343 - accuracy: 0.5061 - val_loss: 0.6251 - val_accuracy: 0.5066 Epoch 6/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6068 - accuracy: 0.5634 - val_loss: 0.5982 - val_accuracy: 0.5762 Epoch 7/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5752 - accuracy: 0.6405 - val_loss: 0.5690 - val_accuracy: 0.6386 Epoch 8/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5412 - accuracy: 0.7036 - val_loss: 0.5390 - val_accuracy: 0.6850 Epoch 9/15 20/20 [==============================] - 1s 59ms/step - loss: 0.5064 - accuracy: 0.7479 - val_loss: 0.5106 - val_accuracy: 0.7222 Epoch 10/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4734 - accuracy: 0.7774 - val_loss: 0.4855 - val_accuracy: 0.7430 Epoch 11/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4432 - accuracy: 0.7971 - val_loss: 0.4636 - val_accuracy: 0.7570 Epoch 12/15 20/20 [==============================] - 1s 58ms/step - loss: 0.4161 - accuracy: 0.8155 - val_loss: 0.4453 - val_accuracy: 0.7674 Epoch 13/15 20/20 [==============================] - 1s 59ms/step - loss: 0.3921 - accuracy: 0.8304 - val_loss: 0.4303 - val_accuracy: 0.7780 Epoch 14/15 20/20 [==============================] - 1s 61ms/step - loss: 0.3711 - accuracy: 0.8398 - val_loss: 0.4181 - val_accuracy: 0.7884 Epoch 15/15 20/20 [==============================] - 1s 58ms/step - loss: 0.3524 - accuracy: 0.8493 - val_loss: 0.4082 - val_accuracy: 0.7948 <keras.callbacks.History at 0x7fca579745d0>
Dzięki takiemu podejściu model osiąga dokładność walidacji około 78% (należy zauważyć, że model jest przesadnie dopasowany, ponieważ dokładność uczenia jest wyższa).
Możesz zajrzeć do podsumowania modelu, aby dowiedzieć się więcej o każdej warstwie modelu.
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
text_vectorization (TextVec (None, 100) 0
torization)
embedding (Embedding) (None, 100, 16) 160000
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dense (Dense) (None, 16) 272
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 160,289
Trainable params: 160,289
Non-trainable params: 0
_________________________________________________________________
Wizualizuj metryki modelu w TensorBoard.
#docs_infra: no_execute
%load_ext tensorboard
%tensorboard --logdir logs
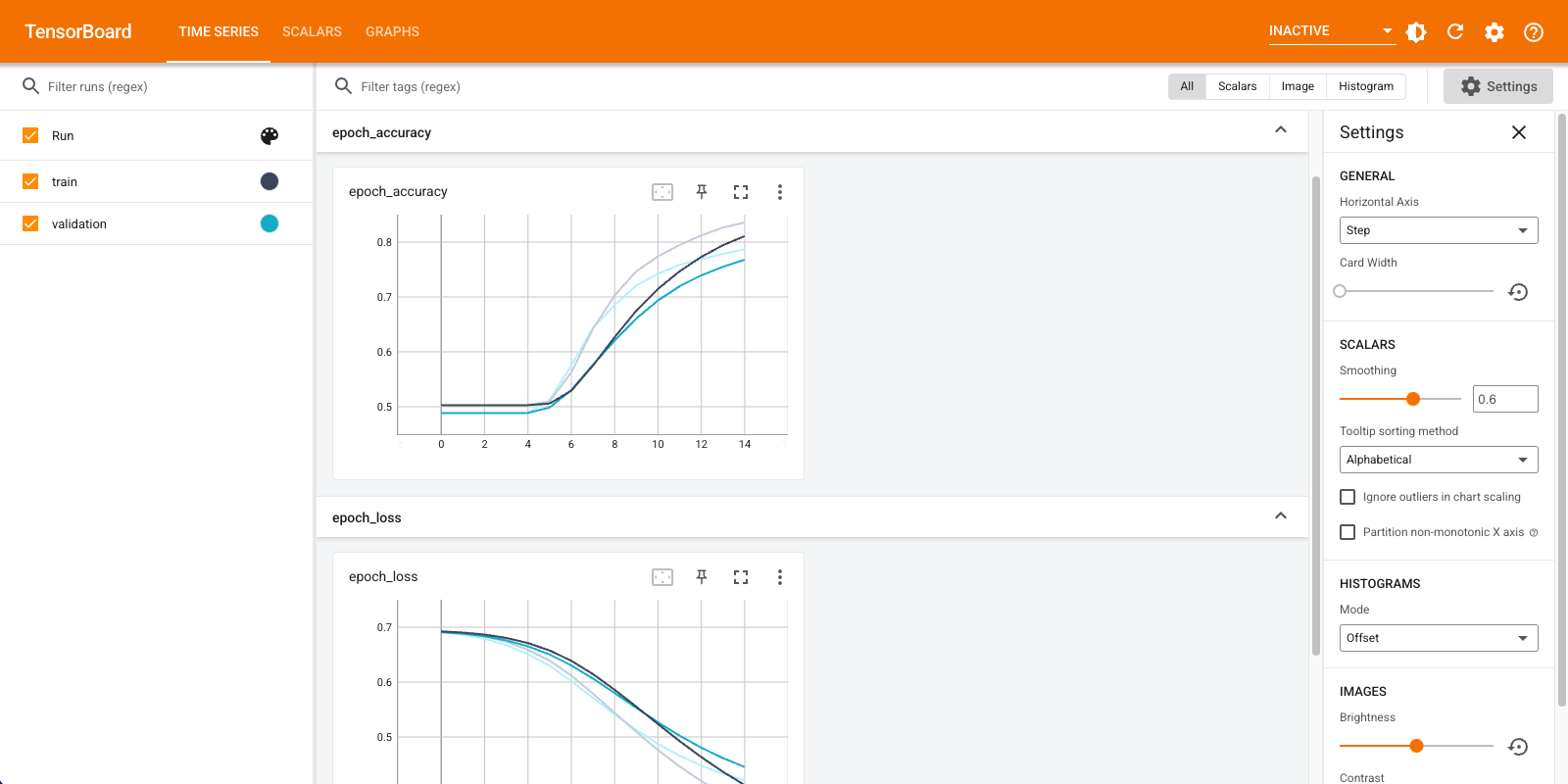
Pobierz wytrenowane osadzania słów i zapisz je na dysku
Następnie odzyskaj osadzenia słów nauczone podczas treningu. Osadzenia to wagi warstwy Osadzenia w modelu. Macierz wag ma kształt (vocab_size, embedding_dimension) .
Uzyskaj wagi z modelu za pomocą funkcji get_layer() i get_weights() . Funkcja get_vocabulary() udostępnia słownik do tworzenia pliku metadanych z jednym tokenem w wierszu.
weights = model.get_layer('embedding').get_weights()[0]
vocab = vectorize_layer.get_vocabulary()
Zapisz wagi na dysku. Aby użyć projektora do osadzania , prześlesz dwa pliki w formacie rozdzielanym tabulatorami: plik wektorów (zawierający osadzanie) i plik metadanych (zawierający słowa).
out_v = io.open('vectors.tsv', 'w', encoding='utf-8')
out_m = io.open('metadata.tsv', 'w', encoding='utf-8')
for index, word in enumerate(vocab):
if index == 0:
continue # skip 0, it's padding.
vec = weights[index]
out_v.write('\t'.join([str(x) for x in vec]) + "\n")
out_m.write(word + "\n")
out_v.close()
out_m.close()
Jeśli korzystasz z tego samouczka w Colaboratory , możesz użyć następującego fragmentu kodu, aby pobrać te pliki na komputer lokalny (lub użyć przeglądarki plików, Widok -> Spis treści -> Przeglądarka plików ).
try:
from google.colab import files
files.download('vectors.tsv')
files.download('metadata.tsv')
except Exception:
pass
Wizualizuj osadzenia
Aby zwizualizować osadzania, prześlij je do projektora osadzania.
Otwórz Projektor do osadzania (może to również działać w lokalnej instancji TensorBoard).
Kliknij „Załaduj dane”.
Prześlij dwa utworzone powyżej pliki:
vecs.tsvimeta.tsv.
Wytrenowane osadzenia będą teraz wyświetlane. Możesz wyszukiwać słowa, aby znaleźć ich najbliższych sąsiadów. Na przykład spróbuj wyszukać „piękne”. Możesz zobaczyć sąsiadów jak „wspaniali”.
Następne kroki
W tym samouczku pokazano, jak trenować i wizualizować osadzanie słów od podstaw na małym zestawie danych.
Aby nauczyć osadzania słów przy użyciu algorytmu Word2Vec, wypróbuj samouczek Word2Vec .
Aby dowiedzieć się więcej o zaawansowanym przetwarzaniu tekstu, zapoznaj się z modelem Transformer do rozumienia języka .