
Un exemple de composant clé de TensorFlow Extended
 Voir la source sur GitHub
Voir la source sur GitHubCet exemple de bloc-notes Colab illustre comment la validation des données TensorFlow (TFDV) peut être utilisée pour étudier et visualiser votre ensemble de données. Cela inclut l'examen des statistiques descriptives, la déduction d'un schéma, la recherche et la correction des anomalies, et la vérification de la dérive et de l'asymétrie dans notre ensemble de données. Il est important de comprendre les caractéristiques de votre jeu de données, y compris la façon dont il peut changer au fil du temps dans votre pipeline de production. Il est également important de rechercher les anomalies dans vos données et de comparer vos ensembles de données d'entraînement, d'évaluation et de diffusion pour vous assurer qu'ils sont cohérents.
Nous utiliserons les données de l'ensemble de données Taxi Trips publié par la ville de Chicago.
En savoir plus sur l'ensemble de données dans Google BigQuery . Explorez l'ensemble de données complet dans l'interface utilisateur de BigQuery .
Les colonnes de l'ensemble de données sont :
| zone de ramassage_communautaire | tarif | voyage_début_mois |
| trip_start_hour | trip_start_day | trip_start_timestamp |
| pick_latitude | ramassage_longitude | dropoff_latitude |
| dropoff_longitude | trip_miles | pickup_census_tract |
| dropoff_census_tract | type de paiement | entreprise |
| trip_seconds | dropoff_community_area | des astuces |
Installer et importer des packages
Installez les packages pour TensorFlow Data Validation.
Mettre à jour le pip
Pour éviter la mise à niveau de Pip dans un système lors d'une exécution locale, vérifiez que nous exécutons Colab. Les systèmes locaux peuvent bien sûr être mis à niveau séparément.
try:
import colab
!pip install --upgrade pip
except:
pass
Installer les packages de validation des données
Installez les packages et les dépendances TensorFlow Data Validation, ce qui prend quelques minutes. Vous pouvez voir des avertissements et des erreurs concernant des versions de dépendance incompatibles, que vous résoudrez dans la section suivante.
print('Installing TensorFlow Data Validation')
!pip install --upgrade 'tensorflow_data_validation[visualization]<2'
Importer TensorFlow et recharger les packages mis à jour
L'étape précédente met à jour les packages par défaut dans l'environnement Gooogle Colab. Vous devez donc recharger les ressources du package pour résoudre les nouvelles dépendances.
import pkg_resources
import importlib
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
Vérifiez les versions de TensorFlow et de la validation des données avant de continuer.
import tensorflow as tf
import tensorflow_data_validation as tfdv
print('TF version:', tf.__version__)
print('TFDV version:', tfdv.version.__version__)
TF version: 2.7.0 TFDV version: 1.5.0
Charger le jeu de données
Nous allons télécharger notre jeu de données depuis Google Cloud Storage.
import os
import tempfile, urllib, zipfile
# Set up some globals for our file paths
BASE_DIR = tempfile.mkdtemp()
DATA_DIR = os.path.join(BASE_DIR, 'data')
OUTPUT_DIR = os.path.join(BASE_DIR, 'chicago_taxi_output')
TRAIN_DATA = os.path.join(DATA_DIR, 'train', 'data.csv')
EVAL_DATA = os.path.join(DATA_DIR, 'eval', 'data.csv')
SERVING_DATA = os.path.join(DATA_DIR, 'serving', 'data.csv')
# Download the zip file from GCP and unzip it
zip, headers = urllib.request.urlretrieve('https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip')
zipfile.ZipFile(zip).extractall(BASE_DIR)
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R {os.path.join(BASE_DIR, 'data')}
Here's what we downloaded: /tmp/tmp_waiqx43/data: eval serving train /tmp/tmp_waiqx43/data/eval: data.csv /tmp/tmp_waiqx43/data/serving: data.csv /tmp/tmp_waiqx43/data/train: data.csv
Calculer et visualiser des statistiques
Nous allons d'abord utiliser tfdv.generate_statistics_from_csv pour calculer les statistiques de nos données d'apprentissage. (ignorez les avertissements accrocheurs)
TFDV peut calculer des statistiques descriptives qui fournissent un aperçu rapide des données en termes d'entités présentes et de formes de leurs distributions de valeurs.
En interne, TFDV utilise le cadre de traitement parallèle des données d' Apache Beam pour mettre à l'échelle le calcul des statistiques sur de grands ensembles de données. Pour les applications qui souhaitent s'intégrer plus profondément avec TFDV (par exemple, attacher la génération de statistiques à la fin d'un pipeline de génération de données), l'API expose également un Beam PTransform pour la génération de statistiques.
train_stats = tfdv.generate_statistics_from_csv(data_location=TRAIN_DATA)
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features. WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter. WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)`
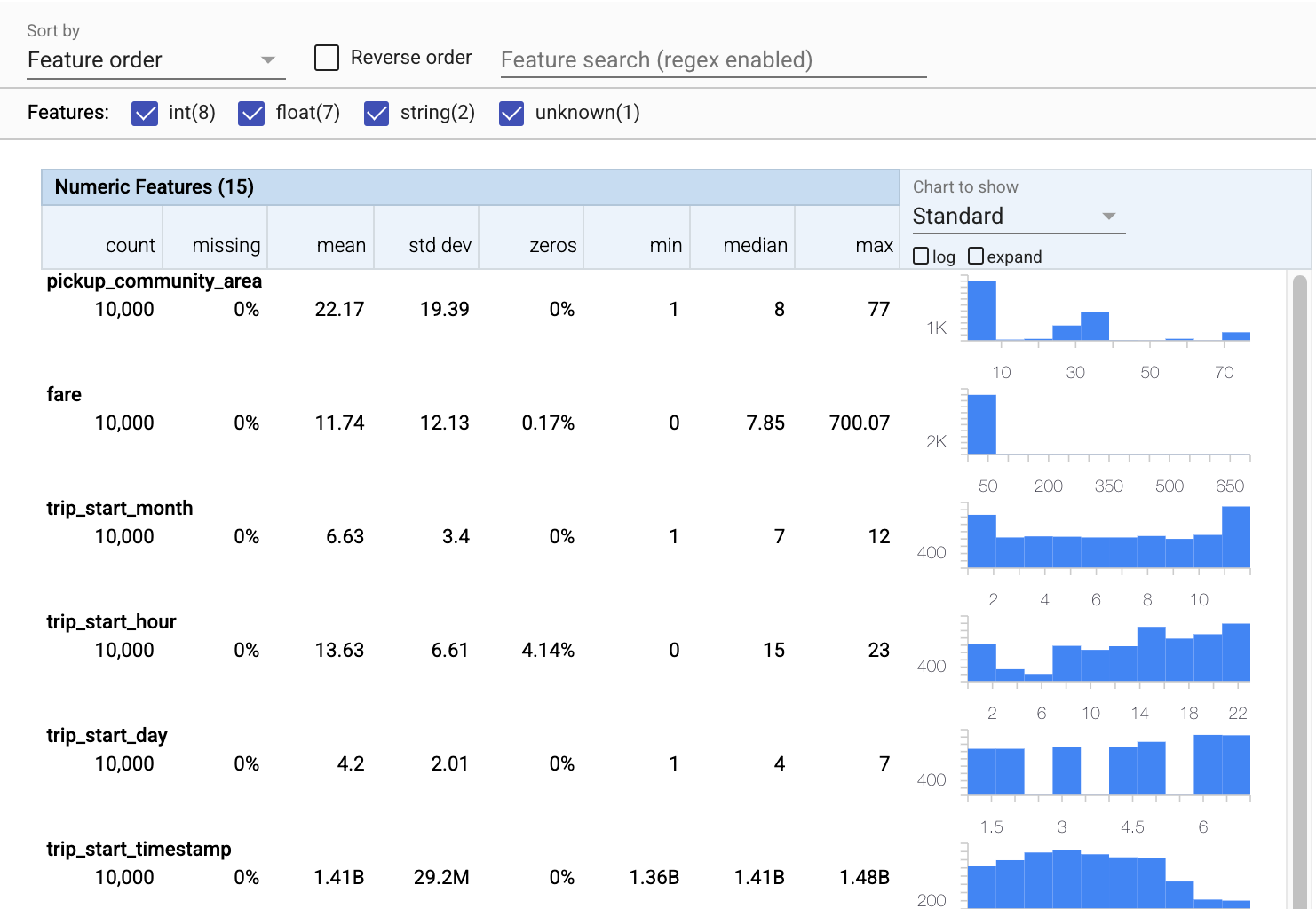
Utilisons maintenant tfdv.visualize_statistics , qui utilise Facets pour créer une visualisation succincte de nos données d'entraînement :
- Notez que les entités numériques et les entités catégorielles sont visualisées séparément et que des graphiques sont affichés montrant les distributions pour chaque entité.
- Notez que les entités avec des valeurs manquantes ou nulles affichent un pourcentage en rouge comme indicateur visuel qu'il peut y avoir des problèmes avec des exemples dans ces entités. Le pourcentage est le pourcentage d'exemples qui ont des valeurs manquantes ou nulles pour cette fonctionnalité.
- Notez qu'il n'y a pas d'exemples avec des valeurs pour
pickup_census_tract. C'est une opportunité de réduction de dimensionnalité ! - Essayez de cliquer sur "développer" au-dessus des graphiques pour modifier l'affichage
- Essayez de survoler les barres dans les graphiques pour afficher les plages et les nombres de compartiments
- Essayez de basculer entre les échelles logarithmique et linéaire, et remarquez comment l'échelle logarithmique révèle beaucoup plus de détails sur la caractéristique catégorielle
payment_type - Essayez de sélectionner "quantiles" dans le menu "Graphique à afficher" et passez la souris sur les marqueurs pour afficher les pourcentages de quantiles
# docs-infra: no-execute
tfdv.visualize_statistics(train_stats)
Déduire un schéma
Utilisons maintenant tfdv.infer_schema pour créer un schéma pour nos données. Un schéma définit les contraintes pour les données qui sont pertinentes pour le ML. Les exemples de contraintes incluent le type de données de chaque entité, qu'il soit numérique ou catégoriel, ou la fréquence de sa présence dans les données. Pour les caractéristiques catégorielles, le schéma définit également le domaine - la liste des valeurs acceptables. Étant donné que l'écriture d'un schéma peut être une tâche fastidieuse, en particulier pour les ensembles de données comportant de nombreuses fonctionnalités, TFDV fournit une méthode pour générer une version initiale du schéma basée sur les statistiques descriptives.
Obtenir le bon schéma est important car le reste de notre pipeline de production s'appuiera sur le schéma généré par TFDV pour être correct. Le schéma fournit également une documentation pour les données, et est donc utile lorsque différents développeurs travaillent sur les mêmes données. Utilisons tfdv.display_schema pour afficher le schéma déduit afin que nous puissions l'examiner.
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
Vérifier les données d'évaluation pour les erreurs
Jusqu'à présent, nous n'avons examiné que les données d'entraînement. Il est important que nos données d'évaluation soient cohérentes avec nos données d'entraînement, notamment qu'elles utilisent le même schéma. Il est également important que les données d'évaluation incluent des exemples d'à peu près les mêmes plages de valeurs pour nos caractéristiques numériques que nos données de formation, afin que notre couverture de la surface de perte pendant l'évaluation soit à peu près la même que pendant la formation. Il en est de même pour les caractéristiques catégorielles. Sinon, nous pouvons avoir des problèmes de formation qui ne sont pas identifiés lors de l'évaluation, car nous n'avons pas évalué une partie de notre surface de perte.
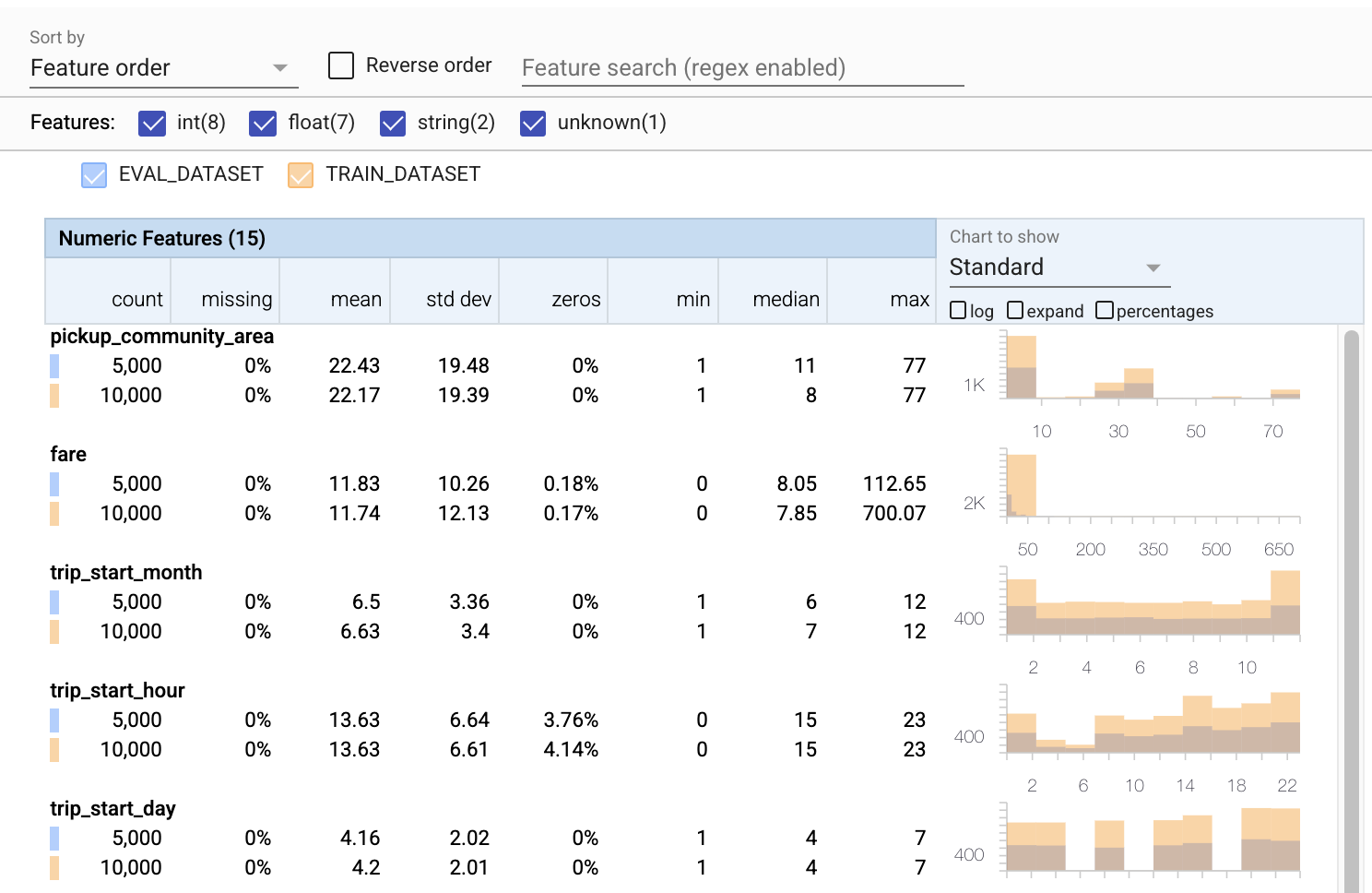
- Notez que chaque fonctionnalité inclut désormais des statistiques pour les ensembles de données d'entraînement et d'évaluation.
- Notez que les graphiques comportent désormais à la fois les ensembles de données d'entraînement et d'évaluation superposés, ce qui facilite leur comparaison.
- Notez que les graphiques incluent désormais une vue en pourcentages, qui peut être combinée avec le journal ou les échelles linéaires par défaut.
- Notez que la moyenne et la médiane de
trip_milessont différentes pour les ensembles de données d'entraînement et d'évaluation. Cela causera-t-il des problèmes? - Wow, le nombre maximum
tipsest très différent pour la formation par rapport aux ensembles de données d'évaluation. Cela causera-t-il des problèmes? - Cliquez sur Développer sur le graphique Entités numériques et sélectionnez l'échelle logarithmique. Passez en revue la fonction
trip_secondset notez la différence dans le max. L'évaluation manquera-t-elle des parties de la surface de perte ?
# Compute stats for evaluation data
eval_stats = tfdv.generate_statistics_from_csv(data_location=EVAL_DATA)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
# docs-infra: no-execute
# Compare evaluation data with training data
tfdv.visualize_statistics(lhs_statistics=eval_stats, rhs_statistics=train_stats,
lhs_name='EVAL_DATASET', rhs_name='TRAIN_DATASET')
Vérifier les anomalies d'évaluation
Notre ensemble de données d'évaluation correspond-il au schéma de notre ensemble de données d'entraînement ? Ceci est particulièrement important pour les caractéristiques catégorielles, où nous voulons identifier la plage de valeurs acceptables.
# Check eval data for errors by validating the eval data stats using the previously inferred schema.
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema)
tfdv.display_anomalies(anomalies)
Correction des anomalies d'évaluation dans le schéma
Oups! Il semble que nous ayons de nouvelles valeurs pour l' company dans nos données d'évaluation, que nous n'avions pas dans nos données de formation. Nous avons également une nouvelle valeur pour payment_type . Celles-ci doivent être considérées comme des anomalies, mais ce que nous décidons de faire à leur sujet dépend de notre connaissance du domaine des données. Si une anomalie indique réellement une erreur de données, les données sous-jacentes doivent être corrigées. Sinon, nous pouvons simplement mettre à jour le schéma pour inclure les valeurs dans l'ensemble de données eval.
À moins de modifier notre ensemble de données d'évaluation, nous ne pouvons pas tout réparer, mais nous pouvons corriger des choses dans le schéma que nous sommes à l'aise d'accepter. Cela inclut l'assouplissement de notre vision de ce qui est et de ce qui n'est pas une anomalie pour des fonctionnalités particulières, ainsi que la mise à jour de notre schéma pour inclure les valeurs manquantes pour les fonctionnalités catégorielles. TFDV nous a permis de découvrir ce que nous devons corriger.
Faisons ces corrections maintenant, puis réexaminons une fois de plus.
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
Hé, regarde ça ! Nous avons vérifié que les données de formation et d'évaluation sont désormais cohérentes ! Merci TFDV ;)
Environnements de schéma
Nous avons également séparé un ensemble de données «servant» pour cet exemple, nous devons donc également le vérifier. Par défaut, tous les ensembles de données d'un pipeline doivent utiliser le même schéma, mais il existe souvent des exceptions. Par exemple, dans l'apprentissage supervisé, nous devons inclure des étiquettes dans notre ensemble de données, mais lorsque nous servons le modèle pour l'inférence, les étiquettes ne seront pas incluses. Dans certains cas, il est nécessaire d'introduire de légères variations de schéma.
Les environnements peuvent être utilisés pour exprimer de telles exigences. En particulier, les fonctionnalités du schéma peuvent être associées à un ensemble d'environnements à l'aide de default_environment , in_environment et not_in_environment .
Par exemple, dans cet ensemble de données, la fonctionnalité d' tips est incluse en tant qu'étiquette d'entraînement, mais elle est absente des données de diffusion. Sans environnement spécifié, il apparaîtra comme une anomalie.
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
Nous traiterons de la fonctionnalité de tips ci-dessous. Nous avons également une valeur INT dans nos secondes de trajet, là où notre schéma attendait un FLOAT. En nous faisant prendre conscience de cette différence, TFDV aide à découvrir les incohérences dans la manière dont les données sont générées pour la formation et le service. Il est très facile d'ignorer de tels problèmes jusqu'à ce que les performances du modèle en souffrent, parfois de manière catastrophique. Il peut s'agir ou non d'un problème important, mais dans tous les cas, cela devrait faire l'objet d'une enquête plus approfondie.
Dans ce cas, nous pouvons convertir en toute sécurité les valeurs INT en FLOAT, nous voulons donc dire à TFDV d'utiliser notre schéma pour déduire le type. Faisons cela maintenant.
options = tfdv.StatsOptions(schema=schema, infer_type_from_schema=True)
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA, stats_options=options)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
Maintenant, nous avons juste la fonctionnalité tips (qui est notre étiquette) qui apparaît comme une anomalie ("Colonne abandonnée"). Bien sûr, nous ne nous attendons pas à avoir des étiquettes dans nos données de service, alors disons à TFDV d'ignorer cela.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
tfdv.display_anomalies(serving_anomalies_with_env)
Vérifier la dérive et l'inclinaison
En plus de vérifier si un jeu de données est conforme aux attentes définies dans le schéma, TFDV fournit également des fonctionnalités pour détecter la dérive et le biais. TFDV effectue cette vérification en comparant les statistiques des différents ensembles de données en fonction des comparateurs de dérive/inclinaison spécifiés dans le schéma.
Dérive
La détection de dérive est prise en charge pour les caractéristiques catégorielles et entre des plages de données consécutives (c'est-à-dire entre la plage N et la plage N+1), comme entre différents jours de données d'apprentissage. Nous exprimons la dérive en termes de distance L-infini , et vous pouvez définir la distance seuil de sorte que vous receviez des avertissements lorsque la dérive est supérieure à ce qui est acceptable. La définition de la distance correcte est généralement un processus itératif nécessitant une connaissance du domaine et une expérimentation.
Fausser
TFDV peut détecter trois types différents d'asymétrie dans vos données : l'asymétrie du schéma, l'asymétrie des fonctionnalités et l'asymétrie de la distribution.
Décalage du schéma
L'asymétrie du schéma se produit lorsque les données d'entraînement et de diffusion ne sont pas conformes au même schéma. Les données d'entraînement et de diffusion doivent respecter le même schéma. Tout écart attendu entre les deux (par exemple, la fonctionnalité d'étiquette n'étant présente que dans les données de formation, mais pas dans la diffusion) doit être spécifié via le champ des environnements dans le schéma.
Inclinaison de la fonction
L'asymétrie des caractéristiques se produit lorsque les valeurs de caractéristiques sur lesquelles un modèle s'entraîne sont différentes des valeurs de caractéristiques qu'il voit au moment de la diffusion. Par exemple, cela peut se produire lorsque :
- Une source de données qui fournit certaines valeurs de caractéristiques est modifiée entre la formation et la diffusion
- Il existe une logique différente pour générer des fonctionnalités entre la formation et la diffusion. Par exemple, si vous appliquez une transformation uniquement dans l'un des deux chemins de code.
Biais de distribution
L'asymétrie de distribution se produit lorsque la distribution de l'ensemble de données d'apprentissage est significativement différente de la distribution de l'ensemble de données de diffusion. L'une des principales causes de l'asymétrie de distribution est l'utilisation d'un code différent ou de sources de données différentes pour générer l'ensemble de données d'apprentissage. Une autre raison est un mécanisme d'échantillonnage défectueux qui choisit un sous-échantillon non représentatif des données de diffusion sur lequel s'entraîner.
# Add skew comparator for 'payment_type' feature.
payment_type = tfdv.get_feature(schema, 'payment_type')
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# Add drift comparator for 'company' feature.
company=tfdv.get_feature(schema, 'company')
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(train_stats, schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats)
tfdv.display_anomalies(skew_anomalies)
Dans cet exemple, nous constatons une certaine dérive, mais elle est bien inférieure au seuil que nous avons défini.
Geler le schéma
Maintenant que le schéma a été revu et organisé, nous allons le stocker dans un fichier pour refléter son état "gelé".
from tensorflow.python.lib.io import file_io
from google.protobuf import text_format
file_io.recursive_create_dir(OUTPUT_DIR)
schema_file = os.path.join(OUTPUT_DIR, 'schema.pbtxt')
tfdv.write_schema_text(schema, schema_file)
!cat {schema_file}
feature {
name: "pickup_community_area"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "fare"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_month"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_hour"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_day"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_timestamp"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_latitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_longitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_latitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "dropoff_longitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "trip_miles"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_census_tract"
type: BYTES
presence {
min_count: 0
}
}
feature {
name: "dropoff_census_tract"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "payment_type"
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
skew_comparator {
infinity_norm {
threshold: 0.01
}
}
shape {
dim {
size: 1
}
}
}
feature {
name: "company"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "company"
presence {
min_count: 1
}
distribution_constraints {
min_domain_mass: 0.9
}
drift_comparator {
infinity_norm {
threshold: 0.001
}
}
}
feature {
name: "trip_seconds"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_community_area"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "tips"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
not_in_environment: "SERVING"
shape {
dim {
size: 1
}
}
}
string_domain {
name: "payment_type"
value: "Cash"
value: "Credit Card"
value: "Dispute"
value: "No Charge"
value: "Pcard"
value: "Unknown"
value: "Prcard"
}
string_domain {
name: "company"
value: "0118 - 42111 Godfrey S.Awir"
value: "0694 - 59280 Chinesco Trans Inc"
value: "1085 - 72312 N and W Cab Co"
value: "2733 - 74600 Benny Jona"
value: "2809 - 95474 C & D Cab Co Inc."
value: "3011 - 66308 JBL Cab Inc."
value: "3152 - 97284 Crystal Abernathy"
value: "3201 - C&D Cab Co Inc"
value: "3201 - CID Cab Co Inc"
value: "3253 - 91138 Gaither Cab Co."
value: "3385 - 23210 Eman Cab"
value: "3623 - 72222 Arrington Enterprises"
value: "3897 - Ilie Malec"
value: "4053 - Adwar H. Nikola"
value: "4197 - 41842 Royal Star"
value: "4615 - 83503 Tyrone Henderson"
value: "4615 - Tyrone Henderson"
value: "4623 - Jay Kim"
value: "5006 - 39261 Salifu Bawa"
value: "5006 - Salifu Bawa"
value: "5074 - 54002 Ahzmi Inc"
value: "5074 - Ahzmi Inc"
value: "5129 - 87128"
value: "5129 - 98755 Mengisti Taxi"
value: "5129 - Mengisti Taxi"
value: "5724 - KYVI Cab Inc"
value: "585 - Valley Cab Co"
value: "5864 - 73614 Thomas Owusu"
value: "5864 - Thomas Owusu"
value: "5874 - 73628 Sergey Cab Corp."
value: "5997 - 65283 AW Services Inc."
value: "5997 - AW Services Inc."
value: "6488 - 83287 Zuha Taxi"
value: "6743 - Luhak Corp"
value: "Blue Ribbon Taxi Association Inc."
value: "C & D Cab Co Inc"
value: "Chicago Elite Cab Corp."
value: "Chicago Elite Cab Corp. (Chicago Carriag"
value: "Chicago Medallion Leasing INC"
value: "Chicago Medallion Management"
value: "Choice Taxi Association"
value: "Dispatch Taxi Affiliation"
value: "KOAM Taxi Association"
value: "Northwest Management LLC"
value: "Taxi Affiliation Services"
value: "Top Cab Affiliation"
}
default_environment: "TRAINING"
default_environment: "SERVING"
Quand utiliser TFDV
Il est facile de penser que TFDV ne s'applique qu'au début de votre pipeline de formation, comme nous l'avons fait ici, mais en fait, il a de nombreuses utilisations. En voici quelques autres :
- Valider de nouvelles données pour l'inférence afin de s'assurer que nous n'avons pas soudainement commencé à recevoir de mauvaises fonctionnalités
- Valider de nouvelles données pour l'inférence afin de s'assurer que notre modèle s'est entraîné sur cette partie de la surface de décision
- Valider nos données après les avoir transformées et avoir effectué l'ingénierie des fonctionnalités (probablement à l'aide de TensorFlow Transform ) pour nous assurer que nous n'avons rien fait de mal