
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Este tutorial contiene una introducción a las incrustaciones de palabras. Entrenará sus propias incrustaciones de palabras utilizando un modelo Keras simple para una tarea de clasificación de sentimientos y luego las visualizará en el proyector de incrustaciones (que se muestra en la imagen a continuación).

Representar texto como números
Los modelos de aprendizaje automático toman vectores (matrices de números) como entrada. Cuando trabaje con texto, lo primero que debe hacer es pensar en una estrategia para convertir cadenas en números (o "vectorizar" el texto) antes de enviarlo al modelo. En esta sección, verá tres estrategias para hacerlo.
Codificaciones one-hot
Como primera idea, puede codificar "one-hot" cada palabra en su vocabulario. Considere la oración "El gato se sentó en la alfombra". El vocabulario (o palabras únicas) en esta oración es (cat, mat, on, sat, the). Para representar cada palabra, creará un vector cero con una longitud igual al vocabulario, luego colocará un uno en el índice que corresponda a la palabra. Este enfoque se muestra en el siguiente diagrama.
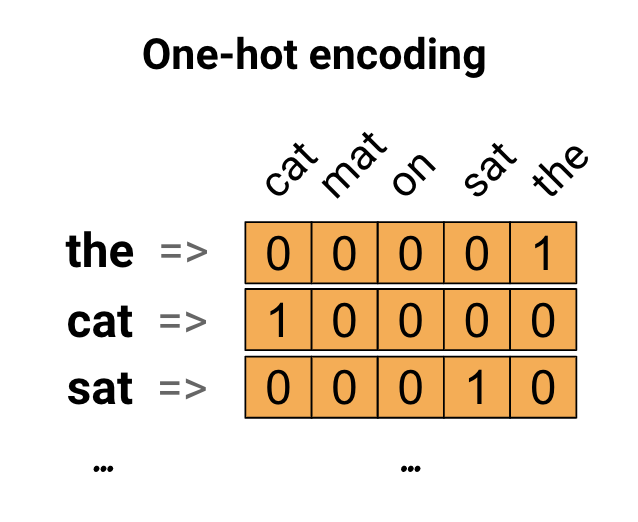
Para crear un vector que contenga la codificación de la oración, puede concatenar los vectores one-hot para cada palabra.
Codifique cada palabra con un número único
Un segundo enfoque que puede probar es codificar cada palabra usando un número único. Continuando con el ejemplo anterior, puede asignar 1 a "gato", 2 a "tapete", y así sucesivamente. Luego podría codificar la oración "El gato se sentó en la alfombra" como un vector denso como [5, 1, 4, 3, 5, 2]. Este enfoque es eficiente. En lugar de un vector disperso, ahora tiene uno denso (donde todos los elementos están llenos).
Sin embargo, hay dos desventajas en este enfoque:
La codificación de enteros es arbitraria (no captura ninguna relación entre palabras).
Una codificación de enteros puede ser difícil de interpretar para un modelo. Un clasificador lineal, por ejemplo, aprende un solo peso para cada característica. Debido a que no existe una relación entre la similitud de dos palabras cualesquiera y la similitud de sus codificaciones, esta combinación de característica y peso no es significativa.
incrustaciones de palabras
Las incrustaciones de palabras nos brindan una manera de usar una representación densa y eficiente en la que palabras similares tienen una codificación similar. Es importante destacar que no tiene que especificar esta codificación a mano. Una incrustación es un vector denso de valores de punto flotante (la longitud del vector es un parámetro que especifica). En lugar de especificar los valores para la incrustación manualmente, son parámetros entrenables (pesos aprendidos por el modelo durante el entrenamiento, de la misma manera que un modelo aprende los pesos de una capa densa). Es común ver incrustaciones de palabras de 8 dimensiones (para conjuntos de datos pequeños), hasta 1024 dimensiones cuando se trabaja con conjuntos de datos grandes. Una incrustación de mayor dimensión puede capturar relaciones detalladas entre palabras, pero requiere más datos para aprender.
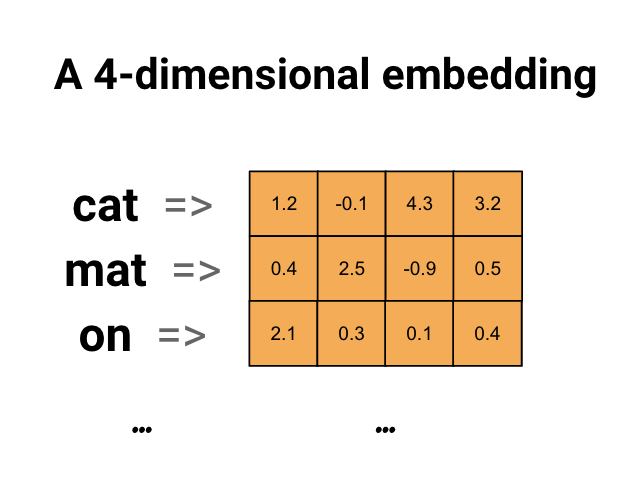
Arriba hay un diagrama para una palabra incrustada. Cada palabra se representa como un vector de 4 dimensiones de valores de punto flotante. Otra forma de pensar en una incrustación es como una "tabla de búsqueda". Después de aprender estos pesos, puede codificar cada palabra buscando el vector denso al que corresponde en la tabla.
Configuración
import io
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Embedding, GlobalAveragePooling1D
from tensorflow.keras.layers import TextVectorization
Descargar el conjunto de datos de IMDb
Utilizará el conjunto de datos de revisión de películas grandes a lo largo del tutorial. Entrenará un modelo de clasificador de opiniones en este conjunto de datos y, en el proceso, aprenderá incrustaciones desde cero. Para obtener más información sobre cómo cargar un conjunto de datos desde cero, consulte el tutorial Cargar texto .
Descargue el conjunto de datos usando la utilidad de archivo Keras y eche un vistazo a los directorios.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1.tar.gz", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
os.listdir(dataset_dir)
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 7s 0us/step 84140032/84125825 [==============================] - 7s 0us/step ['test', 'imdb.vocab', 'imdbEr.txt', 'train', 'README']
Echa un vistazo al directorio train/ . Tiene carpetas pos y neg con reseñas de películas etiquetadas como positivas y negativas respectivamente. Utilizará las revisiones de las carpetas pos y neg para entrenar un modelo de clasificación binaria.
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['urls_pos.txt', 'urls_unsup.txt', 'urls_neg.txt', 'pos', 'unsup', 'unsupBow.feat', 'neg', 'labeledBow.feat']
El directorio train también tiene carpetas adicionales que deben eliminarse antes de crear un conjunto de datos de entrenamiento.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Luego, cree un tf.data.Dataset usando tf.keras.utils.text_dataset_from_directory . Puede leer más sobre el uso de esta utilidad en este tutorial de clasificación de texto .
Utilice el directorio de train para crear conjuntos de datos de entrenamiento y validación con una división del 20 % para la validación.
batch_size = 1024
seed = 123
train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='training', seed=seed)
val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='validation', seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training. Found 25000 files belonging to 2 classes. Using 5000 files for validation.
Eche un vistazo a algunas reseñas de películas y sus etiquetas (1: positive, 0: negative) del conjunto de datos del tren.
for text_batch, label_batch in train_ds.take(1):
for i in range(5):
print(label_batch[i].numpy(), text_batch.numpy()[i])
0 b"Oh My God! Please, for the love of all that is holy, Do Not Watch This Movie! It it 82 minutes of my life I will never get back. Sure, I could have stopped watching half way through. But I thought it might get better. It Didn't. Anyone who actually enjoyed this movie is one seriously sick and twisted individual. No wonder us Australians/New Zealanders have a terrible reputation when it comes to making movies. Everything about this movie is horrible, from the acting to the editing. I don't even normally write reviews on here, but in this case I'll make an exception. I only wish someone had of warned me before I hired this catastrophe" 1 b'This movie is SOOOO funny!!! The acting is WONDERFUL, the Ramones are sexy, the jokes are subtle, and the plot is just what every high schooler dreams of doing to his/her school. I absolutely loved the soundtrack as well as the carefully placed cynicism. If you like monty python, You will love this film. This movie is a tad bit "grease"esk (without all the annoying songs). The songs that are sung are likable; you might even find yourself singing these songs once the movie is through. This musical ranks number two in musicals to me (second next to the blues brothers). But please, do not think of it as a musical per say; seeing as how the songs are so likable, it is hard to tell a carefully choreographed scene is taking place. I think of this movie as more of a comedy with undertones of romance. You will be reminded of what it was like to be a rebellious teenager; needless to say, you will be reminiscing of your old high school days after seeing this film. Highly recommended for both the family (since it is a very youthful but also for adults since there are many jokes that are funnier with age and experience.' 0 b"Alex D. Linz replaces Macaulay Culkin as the central figure in the third movie in the Home Alone empire. Four industrial spies acquire a missile guidance system computer chip and smuggle it through an airport inside a remote controlled toy car. Because of baggage confusion, grouchy Mrs. Hess (Marian Seldes) gets the car. She gives it to her neighbor, Alex (Linz), just before the spies turn up. The spies rent a house in order to burglarize each house in the neighborhood until they locate the car. Home alone with the chicken pox, Alex calls 911 each time he spots a theft in progress, but the spies always manage to elude the police while Alex is accused of making prank calls. The spies finally turn their attentions toward Alex, unaware that he has rigged devices to cleverly booby-trap his entire house. Home Alone 3 wasn't horrible, but probably shouldn't have been made, you can't just replace Macauley Culkin, Joe Pesci, or Daniel Stern. Home Alone 3 had some funny parts, but I don't like when characters are changed in a movie series, view at own risk." 0 b"There's a good movie lurking here, but this isn't it. The basic idea is good: to explore the moral issues that would face a group of young survivors of the apocalypse. But the logic is so muddled that it's impossible to get involved.<br /><br />For example, our four heroes are (understandably) paranoid about catching the mysterious airborne contagion that's wiped out virtually all of mankind. Yet they wear surgical masks some times, not others. Some times they're fanatical about wiping down with bleach any area touched by an infected person. Other times, they seem completely unconcerned.<br /><br />Worse, after apparently surviving some weeks or months in this new kill-or-be-killed world, these people constantly behave like total newbs. They don't bother accumulating proper equipment, or food. They're forever running out of fuel in the middle of nowhere. They don't take elementary precautions when meeting strangers. And after wading through the rotting corpses of the entire human race, they're as squeamish as sheltered debutantes. You have to constantly wonder how they could have survived this long... and even if they did, why anyone would want to make a movie about them.<br /><br />So when these dweebs stop to agonize over the moral dimensions of their actions, it's impossible to take their soul-searching seriously. Their actions would first have to make some kind of minimal sense.<br /><br />On top of all this, we must contend with the dubious acting abilities of Chris Pine. His portrayal of an arrogant young James T Kirk might have seemed shrewd, when viewed in isolation. But in Carriers he plays on exactly that same note: arrogant and boneheaded. It's impossible not to suspect that this constitutes his entire dramatic range.<br /><br />On the positive side, the film *looks* excellent. It's got an over-sharp, saturated look that really suits the southwestern US locale. But that can't save the truly feeble writing nor the paper-thin (and annoying) characters. Even if you're a fan of the end-of-the-world genre, you should save yourself the agony of watching Carriers." 0 b'I saw this movie at an actual movie theater (probably the \\(2.00 one) with my cousin and uncle. We were around 11 and 12, I guess, and really into scary movies. I remember being so excited to see it because my cool uncle let us pick the movie (and we probably never got to do that again!) and sooo disappointed afterwards!! Just boring and not scary. The only redeeming thing I can remember was Corky Pigeon from Silver Spoons, and that wasn\'t all that great, just someone I recognized. I\'ve seen bad movies before and this one has always stuck out in my mind as the worst. This was from what I can recall, one of the most boring, non-scary, waste of our collective \\)6, and a waste of film. I have read some of the reviews that say it is worth a watch and I say, "Too each his own", but I wouldn\'t even bother. Not even so bad it\'s good.'
Configurar el conjunto de datos para el rendimiento
Estos son dos métodos importantes que debe usar al cargar datos para asegurarse de que la E/S no se bloquee.
.cache() mantiene los datos en la memoria después de que se cargan fuera del disco. Esto asegurará que el conjunto de datos no se convierta en un cuello de botella mientras entrena su modelo. Si su conjunto de datos es demasiado grande para caber en la memoria, también puede usar este método para crear un caché en disco de alto rendimiento, que es más eficiente para leer que muchos archivos pequeños.
.prefetch() superpone el preprocesamiento de datos y la ejecución del modelo durante el entrenamiento.
Puede obtener más información sobre ambos métodos, así como sobre cómo almacenar datos en caché en el disco en la guía de rendimiento de datos .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
Uso de la capa de incrustación
Keras facilita el uso de incrustaciones de palabras. Eche un vistazo a la capa de incrustación .
La capa de incrustación se puede entender como una tabla de búsqueda que mapea desde índices enteros (que representan palabras específicas) hasta vectores densos (sus incrustaciones). La dimensionalidad (o ancho) de la incrustación es un parámetro con el que puede experimentar para ver qué funciona bien para su problema, de la misma manera que experimentaría con la cantidad de neuronas en una capa Densa.
# Embed a 1,000 word vocabulary into 5 dimensions.
embedding_layer = tf.keras.layers.Embedding(1000, 5)
Cuando crea una capa de incrustación, los pesos para la incrustación se inicializan aleatoriamente (como cualquier otra capa). Durante el entrenamiento, se ajustan gradualmente mediante retropropagación. Una vez entrenadas, las incrustaciones de palabras aprendidas codificarán aproximadamente las similitudes entre las palabras (como se aprendieron para el problema específico en el que se entrenó su modelo).
Si pasa un entero a una capa de incrustación, el resultado reemplaza cada entero con el vector de la tabla de incrustación:
result = embedding_layer(tf.constant([1, 2, 3]))
result.numpy()
array([[ 0.01318491, -0.02219239, 0.024673 , -0.03208025, 0.02297195],
[-0.00726584, 0.03731754, -0.01209557, -0.03887399, -0.02407478],
[ 0.04477594, 0.04504738, -0.02220147, -0.03642888, -0.04688282]],
dtype=float32)
Para problemas de texto o secuencia, la capa Embedding toma un tensor 2D de números enteros, de forma (samples, sequence_length) , donde cada entrada es una secuencia de números enteros. Puede incrustar secuencias de longitud variable. Puede alimentar la capa de incrustación por encima de lotes con formas (32, 10) (lote de 32 secuencias de longitud 10) o (64, 15) (lote de 64 secuencias de longitud 15).
El tensor devuelto tiene un eje más que la entrada, los vectores de incrustación se alinean a lo largo del nuevo último eje. Pase un lote de entrada (2, 3) y la salida es (2, 3, N)
result = embedding_layer(tf.constant([[0, 1, 2], [3, 4, 5]]))
result.shape
TensorShape([2, 3, 5])
Cuando se le da un lote de secuencias como entrada, una capa de incrustación devuelve un tensor de coma flotante 3D, de forma (samples, sequence_length, embedding_dimensionality) . Para convertir esta secuencia de longitud variable en una representación fija, existe una variedad de enfoques estándar. Puede usar una capa RNN, de atención o de agrupación antes de pasarla a una capa densa. Este tutorial utiliza la agrupación porque es el más simple. El tutorial Clasificación de texto con RNN es un buen paso siguiente.
Preprocesamiento de texto
A continuación, defina los pasos de preprocesamiento del conjunto de datos necesarios para su modelo de clasificación de opiniones. Inicialice una capa de TextVectorization con los parámetros deseados para vectorizar reseñas de películas. Puede obtener más información sobre el uso de esta capa en el tutorial Clasificación de texto .
# Create a custom standardization function to strip HTML break tags '<br />'.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation), '')
# Vocabulary size and number of words in a sequence.
vocab_size = 10000
sequence_length = 100
# Use the text vectorization layer to normalize, split, and map strings to
# integers. Note that the layer uses the custom standardization defined above.
# Set maximum_sequence length as all samples are not of the same length.
vectorize_layer = TextVectorization(
standardize=custom_standardization,
max_tokens=vocab_size,
output_mode='int',
output_sequence_length=sequence_length)
# Make a text-only dataset (no labels) and call adapt to build the vocabulary.
text_ds = train_ds.map(lambda x, y: x)
vectorize_layer.adapt(text_ds)
Crear un modelo de clasificación
Utilice la API secuencial de Keras para definir el modelo de clasificación de opiniones. En este caso se trata de un modelo de estilo "Bolsa continua de palabras".
- La capa
TextVectorizationtransforma cadenas en índices de vocabulario. Ya ha inicializadovectorize_layercomo una capa de TextVectorization y construyó su vocabulario llamando aadaptontext_ds. Ahora vectorize_layer se puede usar como la primera capa de su modelo de clasificación de extremo a extremo, alimentando cadenas transformadas en la capa de incrustación. La capa de
Embeddingtoma el vocabulario codificado en enteros y busca el vector de incrustación para cada índice de palabra. Estos vectores se aprenden a medida que el modelo se entrena. Los vectores agregan una dimensión a la matriz de salida. Las dimensiones resultantes son:(batch, sequence, embedding).La capa
GlobalAveragePooling1Ddevuelve un vector de salida de longitud fija para cada ejemplo promediando la dimensión de la secuencia. Esto permite que el modelo maneje entradas de longitud variable, de la manera más simple posible.El vector de salida de longitud fija se canaliza a través de una capa (
Dense) completamente conectada con 16 unidades ocultas.La última capa está densamente conectada con un solo nodo de salida.
embedding_dim=16
model = Sequential([
vectorize_layer,
Embedding(vocab_size, embedding_dim, name="embedding"),
GlobalAveragePooling1D(),
Dense(16, activation='relu'),
Dense(1)
])
Compilar y entrenar el modelo.
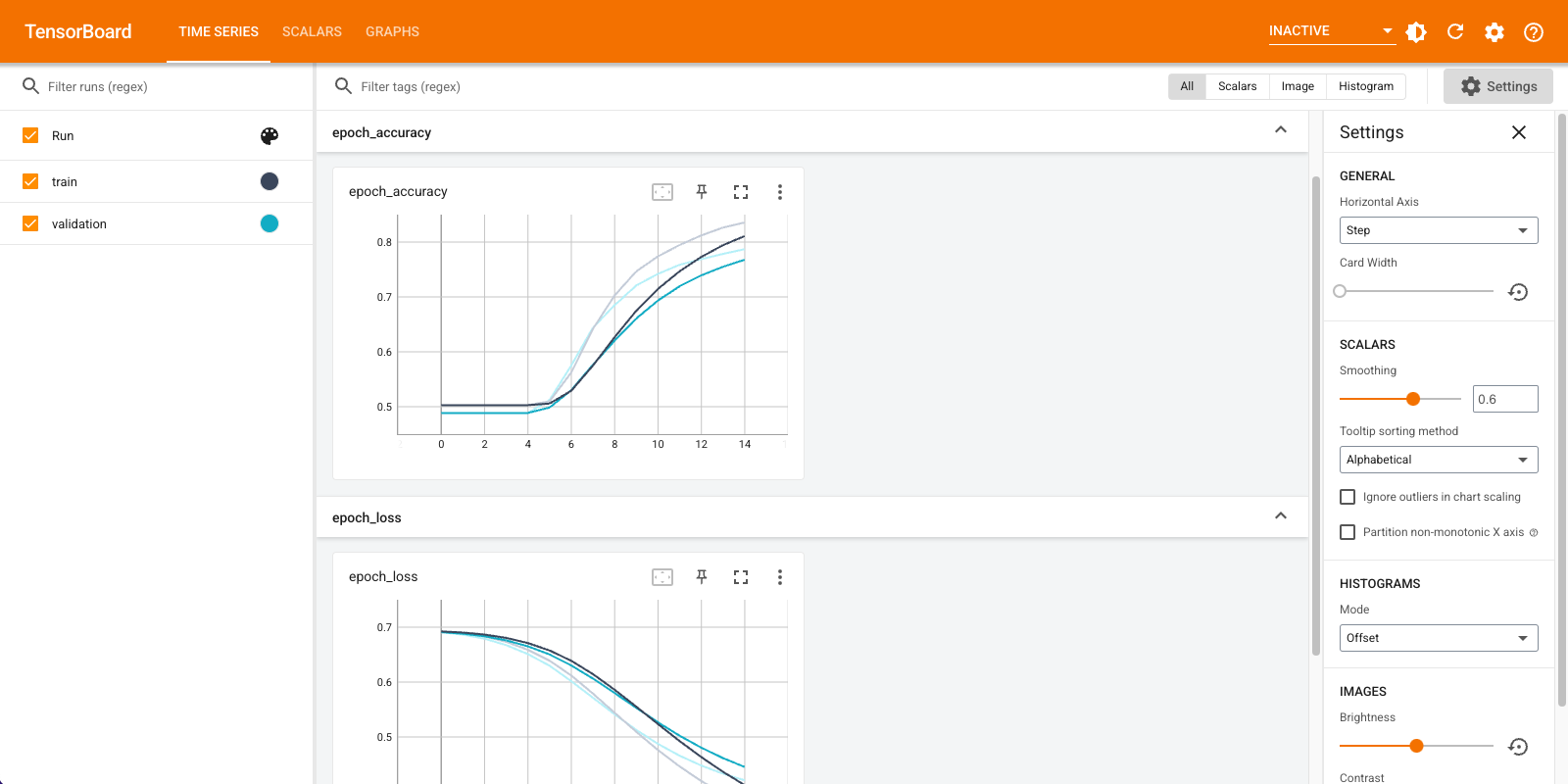
Utilizará TensorBoard para visualizar métricas, incluidas la pérdida y la precisión. Cree un tf.keras.callbacks.TensorBoard .
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir="logs")
Compile y entrene el modelo con el optimizador de Adam y la pérdida BinaryCrossentropy .
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=15,
callbacks=[tensorboard_callback])
Epoch 1/15 20/20 [==============================] - 2s 71ms/step - loss: 0.6910 - accuracy: 0.5028 - val_loss: 0.6878 - val_accuracy: 0.4886 Epoch 2/15 20/20 [==============================] - 1s 57ms/step - loss: 0.6838 - accuracy: 0.5028 - val_loss: 0.6791 - val_accuracy: 0.4886 Epoch 3/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6726 - accuracy: 0.5028 - val_loss: 0.6661 - val_accuracy: 0.4886 Epoch 4/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6563 - accuracy: 0.5028 - val_loss: 0.6481 - val_accuracy: 0.4886 Epoch 5/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6343 - accuracy: 0.5061 - val_loss: 0.6251 - val_accuracy: 0.5066 Epoch 6/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6068 - accuracy: 0.5634 - val_loss: 0.5982 - val_accuracy: 0.5762 Epoch 7/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5752 - accuracy: 0.6405 - val_loss: 0.5690 - val_accuracy: 0.6386 Epoch 8/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5412 - accuracy: 0.7036 - val_loss: 0.5390 - val_accuracy: 0.6850 Epoch 9/15 20/20 [==============================] - 1s 59ms/step - loss: 0.5064 - accuracy: 0.7479 - val_loss: 0.5106 - val_accuracy: 0.7222 Epoch 10/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4734 - accuracy: 0.7774 - val_loss: 0.4855 - val_accuracy: 0.7430 Epoch 11/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4432 - accuracy: 0.7971 - val_loss: 0.4636 - val_accuracy: 0.7570 Epoch 12/15 20/20 [==============================] - 1s 58ms/step - loss: 0.4161 - accuracy: 0.8155 - val_loss: 0.4453 - val_accuracy: 0.7674 Epoch 13/15 20/20 [==============================] - 1s 59ms/step - loss: 0.3921 - accuracy: 0.8304 - val_loss: 0.4303 - val_accuracy: 0.7780 Epoch 14/15 20/20 [==============================] - 1s 61ms/step - loss: 0.3711 - accuracy: 0.8398 - val_loss: 0.4181 - val_accuracy: 0.7884 Epoch 15/15 20/20 [==============================] - 1s 58ms/step - loss: 0.3524 - accuracy: 0.8493 - val_loss: 0.4082 - val_accuracy: 0.7948 <keras.callbacks.History at 0x7fca579745d0>
Con este enfoque, el modelo alcanza una precisión de validación de alrededor del 78 % (tenga en cuenta que el modelo se está sobreajustando ya que la precisión del entrenamiento es mayor).
Puede consultar el resumen del modelo para obtener más información sobre cada capa del modelo.
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
text_vectorization (TextVec (None, 100) 0
torization)
embedding (Embedding) (None, 100, 16) 160000
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dense (Dense) (None, 16) 272
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 160,289
Trainable params: 160,289
Non-trainable params: 0
_________________________________________________________________
Visualiza las métricas del modelo en TensorBoard.
#docs_infra: no_execute
%load_ext tensorboard
%tensorboard --logdir logs
Recupere las incrustaciones de palabras entrenadas y guárdelas en el disco
A continuación, recupere las incrustaciones de palabras aprendidas durante el entrenamiento. Las incrustaciones son pesos de la capa de incrustación en el modelo. La matriz de ponderaciones tiene la forma (vocab_size, embedding_dimension) .
Obtenga los pesos del modelo usando get_layer() y get_weights() . La función get_vocabulary() proporciona el vocabulario para crear un archivo de metadatos con un token por línea.
weights = model.get_layer('embedding').get_weights()[0]
vocab = vectorize_layer.get_vocabulary()
Escriba los pesos en el disco. Para utilizar el proyector de incrustaciones , deberá cargar dos archivos en formato separado por tabulaciones: un archivo de vectores (que contiene la incrustación) y un archivo de metadatos (que contiene las palabras).
out_v = io.open('vectors.tsv', 'w', encoding='utf-8')
out_m = io.open('metadata.tsv', 'w', encoding='utf-8')
for index, word in enumerate(vocab):
if index == 0:
continue # skip 0, it's padding.
vec = weights[index]
out_v.write('\t'.join([str(x) for x in vec]) + "\n")
out_m.write(word + "\n")
out_v.close()
out_m.close()
Si está ejecutando este tutorial en Colaboratory , puede usar el siguiente fragmento para descargar estos archivos a su máquina local (o usar el explorador de archivos, Ver -> Tabla de contenido -> Explorador de archivos ).
try:
from google.colab import files
files.download('vectors.tsv')
files.download('metadata.tsv')
except Exception:
pass
Visualiza las incrustaciones
Para visualizar las incrustaciones, súbalas al proyector de incrustaciones.
Abra el proyector integrado (esto también se puede ejecutar en una instancia local de TensorBoard).
Haga clic en "Cargar datos".
Cargue los dos archivos que creó anteriormente:
vecs.tsvymeta.tsv.
Ahora se mostrarán las incrustaciones que ha entrenado. Puede buscar palabras para encontrar a sus vecinos más cercanos. Por ejemplo, intente buscar "hermoso". Es posible que vea vecinos como "maravilloso".
Próximos pasos
Este tutorial le ha mostrado cómo entrenar y visualizar incrustaciones de palabras desde cero en un pequeño conjunto de datos.
Para entrenar incrustaciones de palabras usando el algoritmo de Word2Vec, pruebe el tutorial de Word2Vec .
Para obtener más información sobre el procesamiento de texto avanzado, lea el modelo de Transformer para la comprensión del lenguaje .