
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Este tutorial demuestra la clasificación de texto a partir de archivos de texto sin formato almacenados en el disco. Entrenará un clasificador binario para realizar un análisis de opinión en un conjunto de datos de IMDB. Al final del cuaderno, hay un ejercicio que puede probar, en el que entrenará un clasificador de varias clases para predecir la etiqueta de una pregunta de programación en Stack Overflow.
import matplotlib.pyplot as plt
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import losses
print(tf.__version__)
2.8.0-rc1
Análisis de los sentimientos
Este cuaderno entrena un modelo de análisis de opiniones para clasificar las reseñas de películas como positivas o negativas , según el texto de la reseña. Este es un ejemplo de clasificación binaria —o de dos clases—, un tipo de problema de aprendizaje automático importante y ampliamente aplicable.
Utilizará el conjunto de datos de reseñas de películas grandes que contiene el texto de 50 000 reseñas de películas de la base de datos de películas de Internet . Estos se dividen en 25 000 revisiones para capacitación y 25 000 revisiones para pruebas. Los conjuntos de entrenamiento y prueba están equilibrados , lo que significa que contienen la misma cantidad de reseñas positivas y negativas.
Descargue y explore el conjunto de datos de IMDB
Descarguemos y extraigamos el conjunto de datos, luego exploremos la estructura del directorio.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 6s 0us/step 84140032/84125825 [==============================] - 6s 0us/stepde posición5
os.listdir(dataset_dir)
['test', 'README', 'imdbEr.txt', 'imdb.vocab', 'train']
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['neg', 'urls_neg.txt', 'unsup', 'unsupBow.feat', 'urls_unsup.txt', 'urls_pos.txt', 'labeledBow.feat', 'pos']
Los aclImdb/train/pos y aclImdb/train/neg contienen muchos archivos de texto, cada uno de los cuales es una reseña de una sola película. Echemos un vistazo a uno de ellos.
sample_file = os.path.join(train_dir, 'pos/1181_9.txt')
with open(sample_file) as f:
print(f.read())
Rachel Griffiths writes and directs this award winning short film. A heartwarming story about coping with grief and cherishing the memory of those we've loved and lost. Although, only 15 minutes long, Griffiths manages to capture so much emotion and truth onto film in the short space of time. Bud Tingwell gives a touching performance as Will, a widower struggling to cope with his wife's death. Will is confronted by the harsh reality of loneliness and helplessness as he proceeds to take care of Ruth's pet cow, Tulip. The film displays the grief and responsibility one feels for those they have loved and lost. Good cinematography, great direction, and superbly acted. It will bring tears to all those who have lost a loved one, and survived.
Cargue el conjunto de datos
A continuación, cargará los datos del disco y los preparará en un formato adecuado para el entrenamiento. Para hacerlo, utilizará la útil utilidad text_dataset_from_directory , que espera una estructura de directorios de la siguiente manera.
main_directory/
...class_a/
......a_text_1.txt
......a_text_2.txt
...class_b/
......b_text_1.txt
......b_text_2.txt
Para preparar un conjunto de datos para la clasificación binaria, necesitará dos carpetas en el disco, correspondientes a class_a y class_b . Estas serán las reseñas positivas y negativas de películas, que se pueden encontrar en aclImdb/train/pos y aclImdb/train/neg . Como el conjunto de datos de IMDB contiene carpetas adicionales, las eliminará antes de usar esta utilidad.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
A continuación, utilizará la utilidad text_dataset_from_directory para crear un tf.data.Dataset etiquetado. tf.data es una poderosa colección de herramientas para trabajar con datos.
Al ejecutar un experimento de aprendizaje automático, se recomienda dividir el conjunto de datos en tres divisiones: entrenamiento , validación y prueba .
El conjunto de datos de IMDB ya se ha dividido en entrenamiento y prueba, pero carece de un conjunto de validación. Vamos a crear un conjunto de validación usando una división 80:20 de los datos de entrenamiento usando el argumento validation_split a continuación.
batch_size = 32
seed = 42
raw_train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training.
Como puede ver arriba, hay 25 000 ejemplos en la carpeta de capacitación, de los cuales usará el 80 % (o 20 000) para la capacitación. Como verá en un momento, puede entrenar un modelo pasando un conjunto de datos directamente a model.fit . Si es nuevo en tf.data , también puede iterar sobre el conjunto de datos e imprimir algunos ejemplos de la siguiente manera.
for text_batch, label_batch in raw_train_ds.take(1):
for i in range(3):
print("Review", text_batch.numpy()[i])
print("Label", label_batch.numpy()[i])
Review b'"Pandemonium" is a horror movie spoof that comes off more stupid than funny. Believe me when I tell you, I love comedies. Especially comedy spoofs. "Airplane", "The Naked Gun" trilogy, "Blazing Saddles", "High Anxiety", and "Spaceballs" are some of my favorite comedies that spoof a particular genre. "Pandemonium" is not up there with those films. Most of the scenes in this movie had me sitting there in stunned silence because the movie wasn\'t all that funny. There are a few laughs in the film, but when you watch a comedy, you expect to laugh a lot more than a few times and that\'s all this film has going for it. Geez, "Scream" had more laughs than this film and that was more of a horror film. How bizarre is that?<br /><br />*1/2 (out of four)' Label 0 Review b"David Mamet is a very interesting and a very un-equal director. His first movie 'House of Games' was the one I liked best, and it set a series of films with characters whose perspective of life changes as they get into complicated situations, and so does the perspective of the viewer.<br /><br />So is 'Homicide' which from the title tries to set the mind of the viewer to the usual crime drama. The principal characters are two cops, one Jewish and one Irish who deal with a racially charged area. The murder of an old Jewish shop owner who proves to be an ancient veteran of the Israeli Independence war triggers the Jewish identity in the mind and heart of the Jewish detective.<br /><br />This is were the flaws of the film are the more obvious. The process of awakening is theatrical and hard to believe, the group of Jewish militants is operatic, and the way the detective eventually walks to the final violent confrontation is pathetic. The end of the film itself is Mamet-like smart, but disappoints from a human emotional perspective.<br /><br />Joe Mantegna and William Macy give strong performances, but the flaws of the story are too evident to be easily compensated." Label 0 Review b'Great documentary about the lives of NY firefighters during the worst terrorist attack of all time.. That reason alone is why this should be a must see collectors item.. What shocked me was not only the attacks, but the"High Fat Diet" and physical appearance of some of these firefighters. I think a lot of Doctors would agree with me that,in the physical shape they were in, some of these firefighters would NOT of made it to the 79th floor carrying over 60 lbs of gear. Having said that i now have a greater respect for firefighters and i realize becoming a firefighter is a life altering job. The French have a history of making great documentary\'s and that is what this is, a Great Documentary.....' Label 1
Observe que las reseñas contienen texto sin formato (con signos de puntuación y etiquetas HTML ocasionales como <br/> ). Mostrará cómo manejarlos en la siguiente sección.
Las etiquetas son 0 o 1. Para ver cuáles corresponden a reseñas de películas positivas y negativas, puede verificar la propiedad class_names en el conjunto de datos.
print("Label 0 corresponds to", raw_train_ds.class_names[0])
print("Label 1 corresponds to", raw_train_ds.class_names[1])
Label 0 corresponds to neg Label 1 corresponds to pos
A continuación, creará un conjunto de datos de validación y prueba. Utilizará las 5000 revisiones restantes del conjunto de capacitación para la validación.
raw_val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
Found 25000 files belonging to 2 classes. Using 5000 files for validation.
raw_test_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
Found 25000 files belonging to 2 classes.
Preparar el conjunto de datos para el entrenamiento
A continuación, estandarizará, tokenizará y vectorizará los datos utilizando la útil capa tf.keras.layers.TextVectorization .
La estandarización se refiere al preprocesamiento del texto, generalmente para eliminar la puntuación o elementos HTML para simplificar el conjunto de datos. La tokenización se refiere a dividir cadenas en tokens (por ejemplo, dividir una oración en palabras individuales, dividiéndola en espacios en blanco). La vectorización se refiere a convertir tokens en números para que puedan alimentar una red neuronal. Todas estas tareas se pueden lograr con esta capa.
Como vio anteriormente, las reseñas contienen varias etiquetas HTML como <br /> . Estas etiquetas no serán eliminadas por el estandarizador predeterminado en la capa TextVectorization (que convierte el texto a minúsculas y elimina la puntuación de forma predeterminada, pero no elimina HTML). Escribirá una función de estandarización personalizada para eliminar el HTML.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation),
'')
A continuación, creará una capa de TextVectorization . Utilizará esta capa para estandarizar, tokenizar y vectorizar nuestros datos. Establece el modo de output_mode en int para crear índices enteros únicos para cada token.
Tenga en cuenta que está utilizando la función de división predeterminada y la función de estandarización personalizada que definió anteriormente. También definirá algunas constantes para el modelo, como una sequence_length máxima explícita, que hará que la capa rellene o trunque las sequence_length a valores exactos de longitud_secuencia.
max_features = 10000
sequence_length = 250
vectorize_layer = layers.TextVectorization(
standardize=custom_standardization,
max_tokens=max_features,
output_mode='int',
output_sequence_length=sequence_length)
A continuación, llamará a adapt para ajustar el estado de la capa de preprocesamiento al conjunto de datos. Esto hará que el modelo genere un índice de cadenas a números enteros.
# Make a text-only dataset (without labels), then call adapt
train_text = raw_train_ds.map(lambda x, y: x)
vectorize_layer.adapt(train_text)
Vamos a crear una función para ver el resultado de usar esta capa para preprocesar algunos datos.
def vectorize_text(text, label):
text = tf.expand_dims(text, -1)
return vectorize_layer(text), label
# retrieve a batch (of 32 reviews and labels) from the dataset
text_batch, label_batch = next(iter(raw_train_ds))
first_review, first_label = text_batch[0], label_batch[0]
print("Review", first_review)
print("Label", raw_train_ds.class_names[first_label])
print("Vectorized review", vectorize_text(first_review, first_label))
Review tf.Tensor(b'Great movie - especially the music - Etta James - "At Last". This speaks volumes when you have finally found that special someone.', shape=(), dtype=string)
Label neg
Vectorized review (<tf.Tensor: shape=(1, 250), dtype=int64, numpy=
array([[ 86, 17, 260, 2, 222, 1, 571, 31, 229, 11, 2418,
1, 51, 22, 25, 404, 251, 12, 306, 282, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]])>, <tf.Tensor: shape=(), dtype=int32, numpy=0>)
Como puede ver arriba, cada token ha sido reemplazado por un número entero. Puede buscar el token (cadena) al que corresponde cada entero llamando a .get_vocabulary() en la capa.
print("1287 ---> ",vectorize_layer.get_vocabulary()[1287])
print(" 313 ---> ",vectorize_layer.get_vocabulary()[313])
print('Vocabulary size: {}'.format(len(vectorize_layer.get_vocabulary())))
1287 ---> silent 313 ---> night Vocabulary size: 10000
Está casi listo para entrenar a su modelo. Como paso final de preprocesamiento, aplicará la capa TextVectorization que creó anteriormente al conjunto de datos de entrenamiento, validación y prueba.
train_ds = raw_train_ds.map(vectorize_text)
val_ds = raw_val_ds.map(vectorize_text)
test_ds = raw_test_ds.map(vectorize_text)
Configurar el conjunto de datos para el rendimiento
Estos son dos métodos importantes que debe usar al cargar datos para asegurarse de que la E/S no se bloquee.
.cache() mantiene los datos en la memoria después de que se cargan fuera del disco. Esto asegurará que el conjunto de datos no se convierta en un cuello de botella mientras entrena su modelo. Si su conjunto de datos es demasiado grande para caber en la memoria, también puede usar este método para crear un caché en disco de alto rendimiento, que es más eficiente para leer que muchos archivos pequeños.
.prefetch() superpone el preprocesamiento de datos y la ejecución del modelo durante el entrenamiento.
Puede obtener más información sobre ambos métodos, así como sobre cómo almacenar datos en caché en el disco en la guía de rendimiento de datos .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
Crear el modelo
Es hora de crear tu red neuronal:
embedding_dim = 16
model = tf.keras.Sequential([
layers.Embedding(max_features + 1, embedding_dim),
layers.Dropout(0.2),
layers.GlobalAveragePooling1D(),
layers.Dropout(0.2),
layers.Dense(1)])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 16) 160016
dropout (Dropout) (None, None, 16) 0
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dropout_1 (Dropout) (None, 16) 0
dense (Dense) (None, 1) 17
=================================================================
Total params: 160,033
Trainable params: 160,033
Non-trainable params: 0
_________________________________________________________________
Las capas se apilan secuencialmente para construir el clasificador:
- La primera capa es una capa de
Embedding. Esta capa toma las revisiones codificadas con enteros y busca un vector de incrustación para cada índice de palabras. Estos vectores se aprenden a medida que el modelo se entrena. Los vectores agregan una dimensión a la matriz de salida. Las dimensiones resultantes son:(batch, sequence, embedding). Para obtener más información sobre incrustaciones, consulte el tutorial de incrustaciones de Word. - A continuación, una capa
GlobalAveragePooling1Ddevuelve un vector de salida de longitud fija para cada ejemplo promediando la dimensión de la secuencia. Esto permite que el modelo maneje entradas de longitud variable, de la manera más simple posible. - Este vector de salida de longitud fija se canaliza a través de una capa (
Dense) completamente conectada con 16 unidades ocultas. - La última capa está densamente conectada con un solo nodo de salida.
Función de pérdida y optimizador
Un modelo necesita una función de pérdida y un optimizador para el entrenamiento. Dado que se trata de un problema de clasificación binaria y el modelo genera una probabilidad (una capa de una sola unidad con una activación sigmoidea), utilizará la función de pérdida losses.BinaryCrossentropy .
Ahora, configure el modelo para usar un optimizador y una función de pérdida:
model.compile(loss=losses.BinaryCrossentropy(from_logits=True),
optimizer='adam',
metrics=tf.metrics.BinaryAccuracy(threshold=0.0))
entrenar al modelo
Entrenará el modelo pasando el objeto del dataset de datos al método de ajuste.
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs)
Epoch 1/10 625/625 [==============================] - 4s 4ms/step - loss: 0.6644 - binary_accuracy: 0.6894 - val_loss: 0.6159 - val_binary_accuracy: 0.7696 Epoch 2/10 625/625 [==============================] - 2s 4ms/step - loss: 0.5494 - binary_accuracy: 0.8020 - val_loss: 0.4993 - val_binary_accuracy: 0.8226 Epoch 3/10 625/625 [==============================] - 2s 3ms/step - loss: 0.4450 - binary_accuracy: 0.8447 - val_loss: 0.4205 - val_binary_accuracy: 0.8466 Epoch 4/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3778 - binary_accuracy: 0.8659 - val_loss: 0.3740 - val_binary_accuracy: 0.8618 Epoch 5/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3357 - binary_accuracy: 0.8785 - val_loss: 0.3451 - val_binary_accuracy: 0.8678 Epoch 6/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3055 - binary_accuracy: 0.8885 - val_loss: 0.3260 - val_binary_accuracy: 0.8700 Epoch 7/10 625/625 [==============================] - 2s 3ms/step - loss: 0.2817 - binary_accuracy: 0.8971 - val_loss: 0.3126 - val_binary_accuracy: 0.8730 Epoch 8/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2616 - binary_accuracy: 0.9034 - val_loss: 0.3037 - val_binary_accuracy: 0.8754 Epoch 9/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2458 - binary_accuracy: 0.9110 - val_loss: 0.2965 - val_binary_accuracy: 0.8788 Epoch 10/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2319 - binary_accuracy: 0.9158 - val_loss: 0.2920 - val_binary_accuracy: 0.8792
Evaluar el modelo
Veamos cómo se comporta el modelo. Se devolverán dos valores. Pérdida (un número que representa nuestro error, los valores más bajos son mejores) y precisión.
loss, accuracy = model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
782/782 [==============================] - 2s 2ms/step - loss: 0.3104 - binary_accuracy: 0.8735 Loss: 0.3104138672351837 Accuracy: 0.873520016670227
Este enfoque bastante ingenuo logra una precisión de alrededor del 86%.
Cree un gráfico de precisión y pérdida a lo largo del tiempo
model.fit() devuelve un objeto de History que contiene un diccionario con todo lo que sucedió durante el entrenamiento:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy'])
Hay cuatro entradas: una para cada métrica monitoreada durante el entrenamiento y la validación. Puede usarlos para trazar la pérdida de entrenamiento y validación para comparar, así como la precisión del entrenamiento y la validación:
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
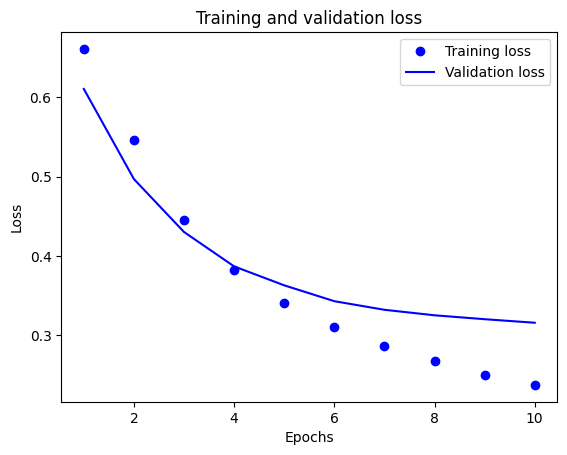
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
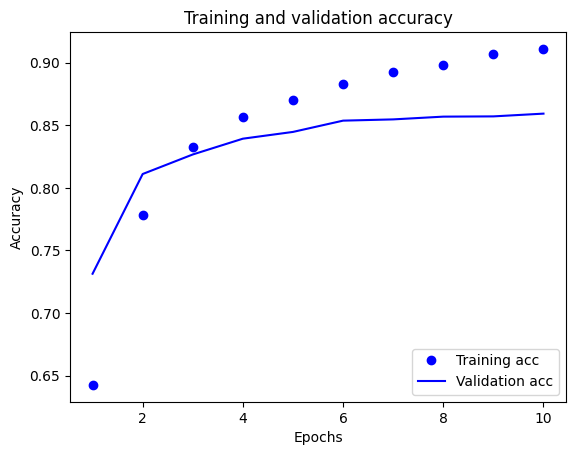
En este gráfico, los puntos representan la pérdida y la precisión del entrenamiento, y las líneas sólidas son la pérdida y la precisión de la validación.
Observe que la pérdida de entrenamiento disminuye con cada época y la precisión del entrenamiento aumenta con cada época. Esto se espera cuando se usa una optimización de descenso de gradiente: debería minimizar la cantidad deseada en cada iteración.
Este no es el caso de la pérdida de validación y la precisión: parecen alcanzar su punto máximo antes que la precisión del entrenamiento. Este es un ejemplo de sobreajuste: el modelo funciona mejor con los datos de entrenamiento que con los datos que nunca antes había visto. Después de este punto, el modelo sobreoptimiza y aprende representaciones específicas de los datos de entrenamiento que no se generalizan a los datos de prueba.
Para este caso particular, podría evitar el sobreajuste simplemente deteniendo el entrenamiento cuando la precisión de la validación ya no aumente. Una forma de hacerlo es utilizar la devolución de llamada tf.keras.callbacks.EarlyStopping .
Exportar el modelo
En el código anterior, aplicó la capa TextVectorization al conjunto de datos antes de enviar texto al modelo. Si desea que su modelo sea capaz de procesar cadenas sin formato (por ejemplo, para simplificar su implementación), puede incluir la capa TextVectorization dentro de su modelo. Para hacerlo, puedes crear un nuevo modelo usando los pesos que acabas de entrenar.
export_model = tf.keras.Sequential([
vectorize_layer,
model,
layers.Activation('sigmoid')
])
export_model.compile(
loss=losses.BinaryCrossentropy(from_logits=False), optimizer="adam", metrics=['accuracy']
)
# Test it with `raw_test_ds`, which yields raw strings
loss, accuracy = export_model.evaluate(raw_test_ds)
print(accuracy)
782/782 [==============================] - 3s 4ms/step - loss: 0.3104 - accuracy: 0.8735 0.873520016670227
Inferencia sobre nuevos datos
Para obtener predicciones para nuevos ejemplos, simplemente puede llamar a model.predict() .
examples = [
"The movie was great!",
"The movie was okay.",
"The movie was terrible..."
]
export_model.predict(examples)
array([[0.60320234],
[0.4262717 ],
[0.34439093]], dtype=float32)
Incluir la lógica de preprocesamiento de texto dentro de su modelo le permite exportar un modelo para producción que simplifica la implementación y reduce el potencial de sesgo de entrenamiento/prueba .
Hay una diferencia de rendimiento a tener en cuenta al elegir dónde aplicar la capa TextVectorization. Usarlo fuera de su modelo le permite realizar procesamiento de CPU asíncrono y almacenamiento en búfer de sus datos cuando entrena en GPU. Por lo tanto, si está entrenando su modelo en la GPU, probablemente desee optar por esta opción para obtener el mejor rendimiento mientras desarrolla su modelo, luego cambie para incluir la capa TextVectorization dentro de su modelo cuando esté listo para prepararse para la implementación. .
Visite este tutorial para obtener más información sobre cómo guardar modelos.
Ejercicio: clasificación multiclase en preguntas de desbordamiento de pila
Este tutorial mostró cómo entrenar un clasificador binario desde cero en el conjunto de datos de IMDB. Como ejercicio, puede modificar este cuaderno para entrenar un clasificador multiclase para predecir la etiqueta de una pregunta de programación en Stack Overflow .
Se ha preparado un conjunto de datos para su uso que contiene el cuerpo de varios miles de preguntas de programación (por ejemplo, "¿Cómo puedo ordenar un diccionario por valor en Python?") publicado en Stack Overflow. Cada uno de estos está etiquetado con exactamente una etiqueta (ya sea Python, CSharp, JavaScript o Java). Su tarea es tomar una pregunta como entrada y predecir la etiqueta adecuada, en este caso, Python.
El conjunto de datos con el que trabajará contiene varios miles de preguntas extraídas del conjunto de datos público Stack Overflow mucho más grande en BigQuery , que contiene más de 17 millones de publicaciones.
Después de descargar el conjunto de datos, encontrará que tiene una estructura de directorios similar al conjunto de datos de IMDB con el que trabajó anteriormente:
train/
...python/
......0.txt
......1.txt
...javascript/
......0.txt
......1.txt
...csharp/
......0.txt
......1.txt
...java/
......0.txt
......1.txt
Para completar este ejercicio, debe modificar este cuaderno para que funcione con el conjunto de datos de desbordamiento de pila realizando las siguientes modificaciones:
En la parte superior de su cuaderno, actualice el código que descarga el conjunto de datos de IMDB con el código para descargar el conjunto de datos de Stack Overflow que ya se preparó. Como el conjunto de datos de Stack Overflow tiene una estructura de directorios similar, no necesitará realizar muchas modificaciones.
Modifique la última capa de su modelo a
Dense(4), ya que ahora hay cuatro clases de salida.Al compilar el modelo, cambie la pérdida a
tf.keras.losses.SparseCategoricalCrossentropy. Esta es la función de pérdida correcta para usar en un problema de clasificación de varias clases, cuando las etiquetas de cada clase son números enteros (en este caso, pueden ser 0, 1 , 2 o 3 ). Además, cambie las métricas ametrics=['accuracy'], ya que este es un problema de clasificación de varias clases (tf.metrics.BinaryAccuracysolo se usa para clasificadores binarios).Al trazar la precisión a lo largo del tiempo, cambie
binary_accuracyyval_binary_accuracyaaccuracyyval_accuracy, respectivamente.Una vez que se completen estos cambios, podrá entrenar un clasificador multiclase.
Aprendiendo más
Este tutorial introdujo la clasificación de texto desde cero. Para obtener más información sobre el flujo de trabajo de clasificación de texto en general, consulte la guía de clasificación de texto de Google Developers.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.