
Copyright 2021 Los autores de TF-Agents.
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Introducción
Este ejemplo muestra cómo entrenar a un refuerzan agente en el medio ambiente Cartpole usando la biblioteca TF-agentes, similar al tutorial DQN .
Lo guiaremos a través de todos los componentes en una tubería de aprendizaje reforzado (RL) para capacitación, evaluación y recopilación de datos.
Configuración
Si no ha instalado las siguientes dependencias, ejecute:
sudo apt-get updatesudo apt-get install -y xvfb ffmpeg freeglut3-devpip install 'imageio==2.4.0'pip install pyvirtualdisplaypip install tf-agents[reverb]pip install pyglet xvfbwrapper
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import numpy as np
import PIL.Image
import pyvirtualdisplay
import reverb
import tensorflow as tf
from tf_agents.agents.reinforce import reinforce_agent
from tf_agents.drivers import py_driver
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import py_tf_eager_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import trajectory
from tf_agents.utils import common
# Set up a virtual display for rendering OpenAI gym environments.
display = pyvirtualdisplay.Display(visible=0, size=(1400, 900)).start()
Hiperparámetros
env_name = "CartPole-v0" # @param {type:"string"}
num_iterations = 250 # @param {type:"integer"}
collect_episodes_per_iteration = 2 # @param {type:"integer"}
replay_buffer_capacity = 2000 # @param {type:"integer"}
fc_layer_params = (100,)
learning_rate = 1e-3 # @param {type:"number"}
log_interval = 25 # @param {type:"integer"}
num_eval_episodes = 10 # @param {type:"integer"}
eval_interval = 50 # @param {type:"integer"}
Medio ambiente
Los entornos en RL representan la tarea o problema que estamos tratando de resolver. Entornos estándar se pueden crear fácilmente en la TF-Agentes utilizando suites . Tenemos diferentes suites para la carga de los entornos de fuentes tales como el OpenAI gimnasia, Atari, Control de DM, etc., dado un nombre de entorno cadena.
Ahora carguemos el entorno CartPole desde la suite OpenAI Gym.
env = suite_gym.load(env_name)
Podemos renderizar este entorno para ver cómo se ve. Un poste de oscilación libre está sujeto a un carro. El objetivo es mover el carro hacia la derecha o hacia la izquierda para mantener el poste apuntando hacia arriba.
env.reset()
PIL.Image.fromarray(env.render())
El time_step = environment.step(action) declaración toma action en el entorno. El TimeStep tupla devuelta contiene próxima observación del medio ambiente y la recompensa por esa acción. El time_step_spec() y action_spec() métodos en el entorno devuelven las especificaciones (tipos, formas, límites) del time_step y action respectivamente.
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(4,), dtype=dtype('float32'), name='observation', minimum=[-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], maximum=[4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38])
Action Spec:
BoundedArraySpec(shape=(), dtype=dtype('int64'), name='action', minimum=0, maximum=1)
Entonces, vemos que la observación es una matriz de 4 flotadores: la posición y la velocidad del carro, y la posición angular y la velocidad del poste. Dado que sólo dos acciones son posibles (movimiento hacia la izquierda o mover hacia la derecha), el action_spec es un escalar que 0 significa "mover hacia la izquierda" y 1 significa "movimiento correcto."
time_step = env.reset()
print('Time step:')
print(time_step)
action = np.array(1, dtype=np.int32)
next_time_step = env.step(action)
print('Next time step:')
print(next_time_step)
Time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02284177, -0.04785635, 0.04171623, 0.04942273], dtype=float32),
'reward': array(0., dtype=float32),
'step_type': array(0, dtype=int32)})
Next time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02188464, 0.14664337, 0.04270469, -0.22981201], dtype=float32),
'reward': array(1., dtype=float32),
'step_type': array(1, dtype=int32)})
Normalmente creamos dos entornos: uno para la formación y otro para la evaluación. La mayoría de los ambientes están escritos en Python puro, pero pueden ser fácilmente convertidos a TensorFlow utilizando el TFPyEnvironment envoltura. API del entorno original utiliza matrices numpy, la TFPyEnvironment los convierte a / de Tensors para que usted pueda interactuar más fácilmente con las políticas y los agentes TensorFlow.
train_py_env = suite_gym.load(env_name)
eval_py_env = suite_gym.load(env_name)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
Agente
El algoritmo que utilizamos para resolver un problema de RL se representa como un Agent . Además del agente de reforzar, de TF-Agentes proporciona implementaciones estándar de una variedad de Agents tales como DQN , DDPG , TD3 , PPO y SAC .
Para crear un agente de reforzar, en primer lugar hay un Actor Network que puede aprender a predecir la acción indicada una observación del entorno.
Podemos crear fácilmente un Actor Network utilizando las especificaciones de las observaciones y acciones. Podemos especificar las capas en la red que, en este ejemplo, es la fc_layer_params argumento establecido en una tupla de ints que representan los tamaños de cada capa oculta (véase la sección hiperparámetros arriba).
actor_net = actor_distribution_network.ActorDistributionNetwork(
train_env.observation_spec(),
train_env.action_spec(),
fc_layer_params=fc_layer_params)
También necesitamos un optimizer para entrenar la red que acabamos de crear, y una train_step_counter variable para llevar la cuenta de cuántas veces se ha actualizado la red.
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
train_step_counter = tf.Variable(0)
tf_agent = reinforce_agent.ReinforceAgent(
train_env.time_step_spec(),
train_env.action_spec(),
actor_network=actor_net,
optimizer=optimizer,
normalize_returns=True,
train_step_counter=train_step_counter)
tf_agent.initialize()
Políticas
En la carretera TF-agentes, políticas representan la noción estándar de las políticas en la vida real: dado un time_step producir una acción o una distribución más acciones. El método principal es policy_step = policy.action(time_step) , donde policy_step es una tupla llamado PolicyStep(action, state, info) . El policy_step.action es la action que debe aplicarse a la ambiente, state representa el estado de las políticas con estado (RNN) y info pueden contener información auxiliar tal como probabilidades de registro de las acciones.
Los agentes contienen dos políticas: la política principal que se usa para la evaluación / implementación (agent.policy) y otra política que se usa para la recopilación de datos (agent.collect_policy).
eval_policy = tf_agent.policy
collect_policy = tf_agent.collect_policy
Métricas y evaluación
La métrica más común utilizada para evaluar una póliza es el rendimiento promedio. El retorno es la suma de las recompensas obtenidas al ejecutar una política en un entorno para un episodio, y generalmente promediamos esto en unos pocos episodios. Podemos calcular la métrica de rendimiento promedio de la siguiente manera.
def compute_avg_return(environment, policy, num_episodes=10):
total_return = 0.0
for _ in range(num_episodes):
time_step = environment.reset()
episode_return = 0.0
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = environment.step(action_step.action)
episode_return += time_step.reward
total_return += episode_return
avg_return = total_return / num_episodes
return avg_return.numpy()[0]
# Please also see the metrics module for standard implementations of different
# metrics.
Búfer de reproducción
Con el fin de realizar un seguimiento de los datos recogidos en el medio ambiente, vamos a utilizar reverberación , un sistema de repetición eficiente, extensible y fácil de usar por Deepmind. Almacena datos de experiencia cuando recopilamos trayectorias y se consume durante el entrenamiento.
Este tampón de repetición se construye usando las características que describen los tensores que son para ser almacenados, que se pueden obtener a partir del agente utilizando tf_agent.collect_data_spec .
table_name = 'uniform_table'
replay_buffer_signature = tensor_spec.from_spec(
tf_agent.collect_data_spec)
replay_buffer_signature = tensor_spec.add_outer_dim(
replay_buffer_signature)
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1),
signature=replay_buffer_signature)
reverb_server = reverb.Server([table])
replay_buffer = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
table_name=table_name,
sequence_length=None,
local_server=reverb_server)
rb_observer = reverb_utils.ReverbAddEpisodeObserver(
replay_buffer.py_client,
table_name,
replay_buffer_capacity
)
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpem6la471. [reverb/cc/platform/tfrecord_checkpointer.cc:385] Loading latest checkpoint from /tmp/tmpem6la471 [reverb/cc/platform/default/server.cc:71] Started replay server on port 19822
Para la mayoría de los agentes, la collect_data_spec es una Trajectory llamado tupla que contiene la observación, acción, recompensar etc.
Recopilación de datos
A medida que REINFORCE aprende de episodios completos, definimos una función para recopilar un episodio utilizando la política de recopilación de datos dada y guardar los datos (observaciones, acciones, recompensas, etc.) como trayectorias en el búfer de repetición. Aquí estamos usando 'PyDriver' para ejecutar el ciclo de recolección de experiencias. Usted puede aprender más acerca controlador Agentes TF en nuestro tutorial de los conductores .
def collect_episode(environment, policy, num_episodes):
driver = py_driver.PyDriver(
environment,
py_tf_eager_policy.PyTFEagerPolicy(
policy, use_tf_function=True),
[rb_observer],
max_episodes=num_episodes)
initial_time_step = environment.reset()
driver.run(initial_time_step)
Entrenando al agente
El ciclo de entrenamiento implica tanto la recopilación de datos del entorno como la optimización de las redes del agente. A lo largo del camino, ocasionalmente evaluaremos la política del agente para ver cómo lo estamos haciendo.
Lo siguiente tardará unos 3 minutos en ejecutarse.
try:
%%time
except:
pass
# (Optional) Optimize by wrapping some of the code in a graph using TF function.
tf_agent.train = common.function(tf_agent.train)
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
returns = [avg_return]
for _ in range(num_iterations):
# Collect a few episodes using collect_policy and save to the replay buffer.
collect_episode(
train_py_env, tf_agent.collect_policy, collect_episodes_per_iteration)
# Use data from the buffer and update the agent's network.
iterator = iter(replay_buffer.as_dataset(sample_batch_size=1))
trajectories, _ = next(iterator)
train_loss = tf_agent.train(experience=trajectories)
replay_buffer.clear()
step = tf_agent.train_step_counter.numpy()
if step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, train_loss.loss))
if step % eval_interval == 0:
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
print('step = {0}: Average Return = {1}'.format(step, avg_return))
returns.append(avg_return)
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 25: loss = 0.8549901247024536 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 50: loss = 1.0025296211242676 step = 50: Average Return = 23.200000762939453 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 75: loss = 1.1377763748168945 step = 100: loss = 1.318871021270752 step = 100: Average Return = 159.89999389648438 step = 125: loss = 1.5053682327270508 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 150: loss = 0.8051948547363281 step = 150: Average Return = 184.89999389648438 step = 175: loss = 0.6872963905334473 step = 200: loss = 2.7238712310791016 step = 200: Average Return = 186.8000030517578 step = 225: loss = 0.7495002746582031 step = 250: loss = -0.3333401679992676 step = 250: Average Return = 200.0
Visualización
Parcelas
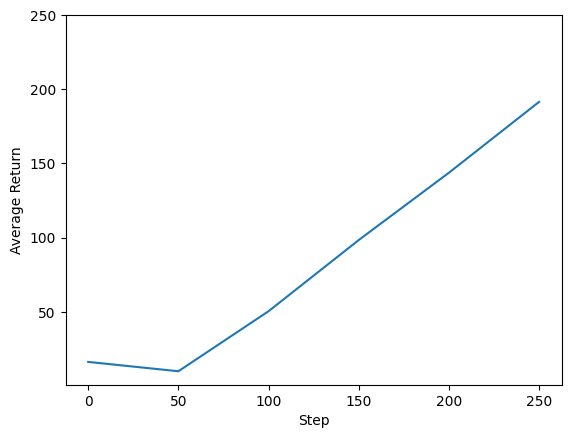
Podemos trazar el retorno frente a los pasos globales para ver el desempeño de nuestro agente. En Cartpole-v0 , el medio ambiente da una recompensa de 1 por cada paso de tiempo las estancias de polo, y dado que el número máximo de pasos es de 200, el rendimiento máximo posible es también 200.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim(top=250)
(-0.2349997997283939, 250.0)
Videos
Es útil visualizar el desempeño de un agente al representar el entorno en cada paso. Antes de hacer eso, primero creemos una función para incrustar videos en este colab.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
El siguiente código visualiza la política del agente para algunos episodios:
num_episodes = 3
video_filename = 'imageio.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_py_env.render())
while not time_step.is_last():
action_step = tf_agent.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_py_env.render())
embed_mp4(video_filename)
WARNING:root:IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (400, 600) to (400, 608) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to None (risking incompatibility). You may also see a FFMPEG warning concerning speedloss due to data not being aligned. [swscaler @ 0x5604d224f3c0] Warning: data is not aligned! This can lead to a speed loss