
Copyright 2020 Les auteurs TF-Agents.
Commencer
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Installer
Si vous n'avez pas installé les dépendances suivantes, exécutez :
pip install tf-agents
Importations
import abc
import numpy as np
import tensorflow as tf
from tf_agents.agents import tf_agent
from tf_agents.drivers import driver
from tf_agents.environments import py_environment
from tf_agents.environments import tf_environment
from tf_agents.environments import tf_py_environment
from tf_agents.policies import tf_policy
from tf_agents.specs import array_spec
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
from tf_agents.trajectories import trajectory
from tf_agents.trajectories import policy_step
nest = tf.nest
introduction
Le problème du bandit multi-bras (MAB) est un cas particulier de l'apprentissage par renforcement : un agent collecte des récompenses dans un environnement en entreprenant certaines actions après avoir observé un certain état de l'environnement. La principale différence entre le RL général et le MAB est que dans le MAB, nous supposons que l'action entreprise par l'agent n'influence pas l'état suivant de l'environnement. Par conséquent, les agents ne modélisent pas les transitions d'état, n'attribuent pas de récompenses aux actions passées ou ne « planifient à l'avance » pour atteindre des états riches en récompenses.
Comme dans d' autres domaines de RL, l'objectif d'un agent MAB est de trouver une politique qui recueille comme récompense autant que possible. Ce serait cependant une erreur de toujours essayer d'exploiter l'action qui promet la plus haute récompense, car il y a alors une chance que nous manquions de meilleures actions si nous n'explorons pas suffisamment. Ceci est le principal problème à résoudre dans (MAB), souvent appelé le dilemme exploration-exploitation.
Environnements Bandit, les politiques et les agents du MAB se trouvent dans les sous - répertoires de tf_agents / bandits .
Environnements
Dans TF-agents, la classe d'environnement joue le rôle de donner des informations sur l'état actuel (ce qu'on appelle l' observation ou de contexte), recevant en entrée une action, d' effectuer une transition d'état, et délivrer en sortie une récompense. Cette classe s'occupe également de réinitialiser lorsqu'un épisode se termine, afin qu'un nouvel épisode puisse commencer. Ceci est réalisé en appelant une reset fonction lorsqu'un état est étiqueté comme « dernier » de l'épisode.
Pour plus de détails, voir le tutoriel de TF-agents .
Comme mentionné ci-dessus, le MAB diffère du RL général en ce que les actions n'influencent pas l'observation suivante. Une autre différence est que dans Bandits, il n'y a pas d'« épisodes » : chaque pas de temps commence par une nouvelle observation, indépendamment des pas de temps précédents.
Pour faire des observations sûres se trouvent indépendant et de faire abstraction du concept d'épisodes RL, nous présentons les sous - classes de PyEnvironment et TFEnvironment : BanditPyEnvironment et BanditTFEnvironment . Ces classes exposent deux fonctions membres privées qui restent à implémenter par l'utilisateur :
@abc.abstractmethod
def _observe(self):
et
@abc.abstractmethod
def _apply_action(self, action):
La _observe fonction renvoie une observation. Ensuite, la politique choisit une action basée sur cette observation. Le _apply_action reçoit cette action en tant qu'entrée, et renvoie la récompense correspondante. Ces fonctions membres privées sont appelées par les fonctions reset à step reset et step , respectivement.
class BanditPyEnvironment(py_environment.PyEnvironment):
def __init__(self, observation_spec, action_spec):
self._observation_spec = observation_spec
self._action_spec = action_spec
super(BanditPyEnvironment, self).__init__()
# Helper functions.
def action_spec(self):
return self._action_spec
def observation_spec(self):
return self._observation_spec
def _empty_observation(self):
return tf.nest.map_structure(lambda x: np.zeros(x.shape, x.dtype),
self.observation_spec())
# These two functions below should not be overridden by subclasses.
def _reset(self):
"""Returns a time step containing an observation."""
return ts.restart(self._observe(), batch_size=self.batch_size)
def _step(self, action):
"""Returns a time step containing the reward for the action taken."""
reward = self._apply_action(action)
return ts.termination(self._observe(), reward)
# These two functions below are to be implemented in subclasses.
@abc.abstractmethod
def _observe(self):
"""Returns an observation."""
@abc.abstractmethod
def _apply_action(self, action):
"""Applies `action` to the Environment and returns the corresponding reward.
"""
Les outils ci - dessus provisoires de classe abstraite PyEnvironment de _reset et _step fonctions et expose les fonctions abstraites _observe et _apply_action à mettre en œuvre par les sous - classes.
Un exemple simple de classe d'environnement
La classe suivante donne un environnement très simple pour lequel l'observation est un entier aléatoire compris entre -2 et 2, il y a 3 actions possibles (0, 1, 2), et la récompense est le produit de l'action et de l'observation.
class SimplePyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
super(SimplePyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return action * self._observation
Nous pouvons maintenant utiliser cet environnement pour obtenir des observations et recevoir des récompenses pour nos actions.
environment = SimplePyEnvironment()
observation = environment.reset().observation
print("observation: %d" % observation)
action = 2
print("action: %d" % action)
reward = environment.step(action).reward
print("reward: %f" % reward)
observation: -1 action: 2 reward: -2.000000
Environnements TF
On peut définir un environnement de bandit par le sous - classement BanditTFEnvironment , ou, de façon similaire aux environnements RL, on peut définir un BanditPyEnvironment et l' envelopper avec TFPyEnvironment . Par souci de simplicité, nous allons avec cette dernière option dans ce tutoriel.
tf_environment = tf_py_environment.TFPyEnvironment(environment)
Stratégies
Une politique dans un problème de bandit fonctionne de la même manière que dans un problème de RL: il fournit une action (ou une distribution d'actions), compte tenu d' une observation en entrée.
Pour plus de détails, voir le tutoriel TF-agents politiques .
Comme avec les environnements, il y a deux façons de construire une politique: On peut créer un PyPolicy et l' envelopper avec TFPyPolicy ou créer directement un TFPolicy . Ici, nous choisissons d'utiliser la méthode directe.
Cet exemple étant assez simple, nous pouvons définir manuellement la politique optimale. L'action ne dépend que du signe de l'observation, 0 quand est négatif et 2 quand est positif.
class SignPolicy(tf_policy.TFPolicy):
def __init__(self):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
super(SignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return ()
def _action(self, time_step, policy_state, seed):
observation_sign = tf.cast(tf.sign(time_step.observation[0]), dtype=tf.int32)
action = observation_sign + 1
return policy_step.PolicyStep(action, policy_state)
Maintenant, nous pouvons demander une observation à l'environnement, appeler la politique pour choisir une action, puis l'environnement affichera la récompense :
sign_policy = SignPolicy()
current_time_step = tf_environment.reset()
print('Observation:')
print (current_time_step.observation)
action = sign_policy.action(current_time_step).action
print('Action:')
print (action)
reward = tf_environment.step(action).reward
print('Reward:')
print(reward)
Observation: tf.Tensor([[2]], shape=(1, 1), dtype=int32) Action: tf.Tensor([2], shape=(1,), dtype=int32) Reward: tf.Tensor([[4.]], shape=(1, 1), dtype=float32)
La façon dont les environnements de bandits sont mis en œuvre garantit que chaque fois que nous faisons un pas, nous recevons non seulement la récompense pour l'action que nous avons entreprise, mais également la prochaine observation.
step = tf_environment.reset()
action = 1
next_step = tf_environment.step(action)
reward = next_step.reward
next_observation = next_step.observation
print("Reward: ")
print(reward)
print("Next observation:")
print(next_observation)
Reward: tf.Tensor([[-2.]], shape=(1, 1), dtype=float32) Next observation: tf.Tensor([[0]], shape=(1, 1), dtype=int32)
Agents
Maintenant que nous avons des environnements et des politiques de bandit, il est temps de définir également des agents de bandit, qui se chargent de modifier la politique en fonction des échantillons d'entraînement.
L'API pour les agents de bandit ne diffère pas de celle des agents RL: l'agent a juste besoin de mettre en œuvre la _initialize et _train méthodes et définir une policy et un collect_policy .
Un environnement plus compliqué
Avant d'écrire notre agent bandit, nous devons avoir un environnement un peu plus difficile à comprendre. Pour pimenter les choses un peu, l'environnement prochain soit toujours donner la reward = observation * action ou reward = -observation * action . Cela sera décidé lors de l'initialisation de l'environnement.
class TwoWayPyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
# Flipping the sign with probability 1/2.
self._reward_sign = 2 * np.random.randint(2) - 1
print("reward sign:")
print(self._reward_sign)
super(TwoWayPyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return self._reward_sign * action * self._observation[0]
two_way_tf_environment = tf_py_environment.TFPyEnvironment(TwoWayPyEnvironment())
reward sign: -1
Une politique plus compliquée
Un environnement plus compliqué appelle une politique plus compliquée. Nous avons besoin d'une politique qui détecte le comportement de l'environnement sous-jacent. La stratégie doit gérer trois situations :
- L'agent n'a pas encore détecté la version de l'environnement en cours d'exécution.
- L'agent a détecté que la version d'origine de l'environnement est en cours d'exécution.
- L'agent a détecté que la version inversée de l'environnement est en cours d'exécution.
Nous définissons un tf_variable nommé _situation pour stocker ces informations codées sous forme de valeurs dans [0, 2] , puis fait fonctionner la politique en conséquence.
class TwoWaySignPolicy(tf_policy.TFPolicy):
def __init__(self, situation):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
self._situation = situation
super(TwoWaySignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return [self._situation]
def _action(self, time_step, policy_state, seed):
sign = tf.cast(tf.sign(time_step.observation[0, 0]), dtype=tf.int32)
def case_unknown_fn():
# Choose 1 so that we get information on the sign.
return tf.constant(1, shape=(1,))
# Choose 0 or 2, depending on the situation and the sign of the observation.
def case_normal_fn():
return tf.constant(sign + 1, shape=(1,))
def case_flipped_fn():
return tf.constant(1 - sign, shape=(1,))
cases = [(tf.equal(self._situation, 0), case_unknown_fn),
(tf.equal(self._situation, 1), case_normal_fn),
(tf.equal(self._situation, 2), case_flipped_fn)]
action = tf.case(cases, exclusive=True)
return policy_step.PolicyStep(action, policy_state)
L'agent
Il est maintenant temps de définir l'agent qui détecte le signe de l'environnement et définit la politique de manière appropriée.
class SignAgent(tf_agent.TFAgent):
def __init__(self):
self._situation = tf.Variable(0, dtype=tf.int32)
policy = TwoWaySignPolicy(self._situation)
time_step_spec = policy.time_step_spec
action_spec = policy.action_spec
super(SignAgent, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec,
policy=policy,
collect_policy=policy,
train_sequence_length=None)
def _initialize(self):
return tf.compat.v1.variables_initializer(self.variables)
def _train(self, experience, weights=None):
observation = experience.observation
action = experience.action
reward = experience.reward
# We only need to change the value of the situation variable if it is
# unknown (0) right now, and we can infer the situation only if the
# observation is not 0.
needs_action = tf.logical_and(tf.equal(self._situation, 0),
tf.not_equal(reward, 0))
def new_situation_fn():
"""This returns either 1 or 2, depending on the signs."""
return (3 - tf.sign(tf.cast(observation[0, 0, 0], dtype=tf.int32) *
tf.cast(action[0, 0], dtype=tf.int32) *
tf.cast(reward[0, 0], dtype=tf.int32))) / 2
new_situation = tf.cond(needs_action,
new_situation_fn,
lambda: self._situation)
new_situation = tf.cast(new_situation, tf.int32)
tf.compat.v1.assign(self._situation, new_situation)
return tf_agent.LossInfo((), ())
sign_agent = SignAgent()
Dans le code ci - dessus, l'agent définit la politique, et la variable la situation est partagée par l'agent et la politique.
En outre, le paramètre experience de la _train fonction est une trajectoire:
Trajectoires
Dans TF-agents, les trajectories sont nommées tuples qui contiennent des échantillons provenant des étapes précédentes prises. Ces exemples sont ensuite utilisés par l'agent pour former et mettre à jour la stratégie. Dans RL, les trajectoires doivent contenir des informations sur l'état actuel, l'état suivant et si l'épisode actuel est terminé. Puisque dans le monde Bandit nous n'avons pas besoin de ces choses, nous avons mis en place une fonction d'assistance pour créer une trajectoire :
# We need to add another dimension here because the agent expects the
# trajectory of shape [batch_size, time, ...], but in this tutorial we assume
# that both batch size and time are 1. Hence all the expand_dims.
def trajectory_for_bandit(initial_step, action_step, final_step):
return trajectory.Trajectory(observation=tf.expand_dims(initial_step.observation, 0),
action=tf.expand_dims(action_step.action, 0),
policy_info=action_step.info,
reward=tf.expand_dims(final_step.reward, 0),
discount=tf.expand_dims(final_step.discount, 0),
step_type=tf.expand_dims(initial_step.step_type, 0),
next_step_type=tf.expand_dims(final_step.step_type, 0))
Formation d'un agent
Maintenant, toutes les pièces sont prêtes pour la formation de notre agent bandit.
step = two_way_tf_environment.reset()
for _ in range(10):
action_step = sign_agent.collect_policy.action(step)
next_step = two_way_tf_environment.step(action_step.action)
experience = trajectory_for_bandit(step, action_step, next_step)
print(experience)
sign_agent.train(experience)
step = next_step
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[0]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[1.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[2.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[4.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
D'après la sortie, on peut voir qu'après la deuxième étape (sauf si l'observation était 0 à la première étape), la politique choisit l'action de la bonne manière et donc la récompense collectée est toujours non négative.
Un vrai exemple de bandit contextuel
Dans le reste de ce tutoriel, nous utilisons les pré-mis en œuvre des environnements et des agents de la TF-agents Bandits bibliothèque.
# Imports for example.
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_py_environment as sspe
from tf_agents.bandits.metrics import tf_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.replay_buffers import tf_uniform_replay_buffer
import matplotlib.pyplot as plt
Environnement stochastique stationnaire avec fonctions de gain linéaire
L'environnement utilisé dans cet exemple est le StationaryStochasticPyEnvironment . Cet environnement prend comme paramètre une fonction (généralement bruyante) pour donner des observations (contexte), et pour chaque bras prend une fonction (également bruyante) qui calcule la récompense en fonction de l'observation donnée. Dans notre exemple, nous échantillonnons le contexte uniformément à partir d'un cube de dimension d, et les fonctions de récompense sont des fonctions linéaires du contexte, plus un peu de bruit gaussien.
batch_size = 2 # @param
arm0_param = [-3, 0, 1, -2] # @param
arm1_param = [1, -2, 3, 0] # @param
arm2_param = [0, 0, 1, 1] # @param
def context_sampling_fn(batch_size):
"""Contexts from [-10, 10]^4."""
def _context_sampling_fn():
return np.random.randint(-10, 10, [batch_size, 4]).astype(np.float32)
return _context_sampling_fn
class LinearNormalReward(object):
"""A class that acts as linear reward function when called."""
def __init__(self, theta, sigma):
self.theta = theta
self.sigma = sigma
def __call__(self, x):
mu = np.dot(x, self.theta)
return np.random.normal(mu, self.sigma)
arm0_reward_fn = LinearNormalReward(arm0_param, 1)
arm1_reward_fn = LinearNormalReward(arm1_param, 1)
arm2_reward_fn = LinearNormalReward(arm2_param, 1)
environment = tf_py_environment.TFPyEnvironment(
sspe.StationaryStochasticPyEnvironment(
context_sampling_fn(batch_size),
[arm0_reward_fn, arm1_reward_fn, arm2_reward_fn],
batch_size=batch_size))
L'agent LinUCB
L'agent ci - dessous met en œuvre le LinUCB algorithme.
observation_spec = tensor_spec.TensorSpec([4], tf.float32)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=2)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec)
Métrique de regret
Mesure la plus importante de Bandits est regret, calculé comme la différence entre la récompense recueillie par l'agent et la récompense attendue d'une politique d'oracle qui a accès aux fonctions de récompense de l'environnement. Le RegretMetric a donc besoin d' une fonction baseline_reward_fn qui calcule la meilleure récompense attendue réalisable compte tenu d' une observation. Pour notre exemple, nous devons prendre le maximum des équivalents sans bruit des fonctions de récompense que nous avons déjà définies pour l'environnement.
def compute_optimal_reward(observation):
expected_reward_for_arms = [
tf.linalg.matvec(observation, tf.cast(arm0_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm1_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm2_param, dtype=tf.float32))]
optimal_action_reward = tf.reduce_max(expected_reward_for_arms, axis=0)
return optimal_action_reward
regret_metric = tf_metrics.RegretMetric(compute_optimal_reward)
Entraînement
Maintenant, nous rassemblons tous les composants que nous avons présentés ci-dessus : l'environnement, la politique et l'agent. Nous courons la politique sur l'environnement et les données de formation de sortie avec l'aide d'un conducteur, et former l'agent sur les données.
Notez qu'il existe deux paramètres qui spécifient ensemble le nombre de pas effectués. num_iterations précise , nous courons combien de fois la boucle d'entraînement, tandis que le conducteur prendra steps_per_loop étapes par itération. La principale raison pour laquelle ces deux paramètres sont conservés est que certaines opérations sont effectuées par itération, tandis que d'autres sont effectuées par le pilote à chaque étape. Par exemple, l'agent train fonction est appelée une seule fois par itération. Le compromis ici est que si nous nous entraînons plus souvent, notre politique est « plus fraîche », d'un autre côté, la formation en lots plus importants pourrait être plus efficace en termes de temps.
num_iterations = 90 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=batch_size,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=environment,
policy=agent.collect_policy,
num_steps=steps_per_loop * batch_size,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
plt.plot(regret_values)
plt.ylabel('Average Regret')
plt.xlabel('Number of Iterations')
WARNING:tensorflow:From /tmp/ipykernel_11392/3138849230.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead. Text(0.5, 0, 'Number of Iterations')
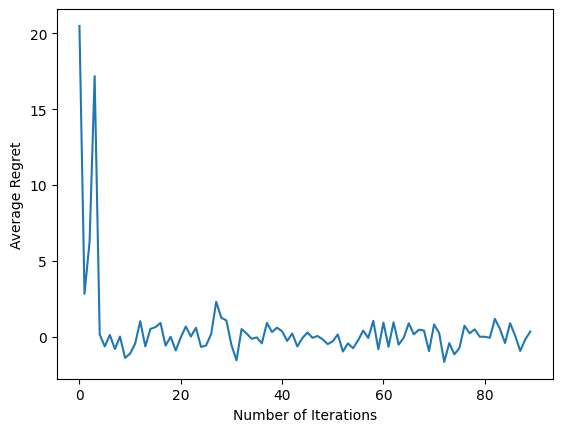
Après avoir exécuté le dernier extrait de code, le graphique résultant (espérons-le) montre que le regret moyen diminue à mesure que l'agent est formé et que la politique s'améliore pour déterminer quelle est la bonne action, compte tenu de l'observation.
Et après?
Pour voir des exemples plus de travail, s'il vous plaît voir les bandits / agents / exemples répertoire qui a des exemples prêts à fonctionner pour différents agents et environnements.
La bibliothèque TF-Agents est également capable de gérer les bandits multi-bras avec des fonctionnalités par bras. À cette fin, nous renvoyons le lecteur au bandit par le bras tutoriel .