
Copyright 2020 Autores do TF-Agents.
Iniciar
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Configurar
Se você não instalou as seguintes dependências, execute:
pip install tf-agents
Importações
import abc
import numpy as np
import tensorflow as tf
from tf_agents.agents import tf_agent
from tf_agents.drivers import driver
from tf_agents.environments import py_environment
from tf_agents.environments import tf_environment
from tf_agents.environments import tf_py_environment
from tf_agents.policies import tf_policy
from tf_agents.specs import array_spec
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
from tf_agents.trajectories import trajectory
from tf_agents.trajectories import policy_step
nest = tf.nest
Introdução
O problema do Bandido Multi-Armado (MAB) é um caso especial de Aprendizagem por Reforço: um agente coleta recompensas em um ambiente ao realizar algumas ações após observar algum estado do ambiente. A principal diferença entre RL geral e MAB é que no MAB, presumimos que a ação realizada pelo agente não influencia o próximo estado do ambiente. Portanto, os agentes não modelam transições de estado, recompensas de crédito para ações passadas ou "planejam com antecedência" para chegar a estados ricos em recompensas.
Como em outros domínios RL, o objetivo de um agente MAB é encontrar uma política que recolhe tanto recompensa possível. Seria um erro, no entanto, sempre tentar explorar a ação que promete a maior recompensa, porque então existe uma chance de perdermos ações melhores se não explorarmos o suficiente. Este é o principal problema a ser resolvido em (MAB), chamado frequentemente o dilema exploração-exploração.
Ambientes bandido, políticas e agentes para MAB podem ser encontrados em subdiretórios do tf_agents / bandidos .
Ambientes
Em TF-agentes, a classe ambiente serve a função de dar informação sobre o estado actual (isto é chamado de observação ou contexto), que recebe uma acção como entrada, realizando uma transição de estado, e a saída de uma recompensa. Esta classe também se encarrega de reiniciar quando um episódio termina, para que um novo episódio possa começar. Isto é realizado chamando uma reset função quando um estado é rotulado como "último" do episódio.
Para mais detalhes, consulte o TF-agentes ambientes tutorial .
Conforme mencionado acima, o MAB difere do RL geral porque as ações não influenciam a próxima observação. Outra diferença é que em Bandidos não há "episódios": cada passo de tempo começa com uma nova observação, independentemente dos passos de tempo anteriores.
Para fazer observações certeza são independentes e para longe abstrair o conceito de episódios RL, vamos introduzir subclasses de PyEnvironment e TFEnvironment : BanditPyEnvironment e BanditTFEnvironment . Essas classes expõem duas funções-membro privadas que ainda precisam ser implementadas pelo usuário:
@abc.abstractmethod
def _observe(self):
e
@abc.abstractmethod
def _apply_action(self, action):
O _observe função devolve uma observação. Em seguida, a política escolhe uma ação com base nessa observação. O _apply_action recebe essa acção como uma entrada, e retorna a recompensa correspondente. Estas funções de membro privadas são chamados pelo funções reset e step , respectivamente.
class BanditPyEnvironment(py_environment.PyEnvironment):
def __init__(self, observation_spec, action_spec):
self._observation_spec = observation_spec
self._action_spec = action_spec
super(BanditPyEnvironment, self).__init__()
# Helper functions.
def action_spec(self):
return self._action_spec
def observation_spec(self):
return self._observation_spec
def _empty_observation(self):
return tf.nest.map_structure(lambda x: np.zeros(x.shape, x.dtype),
self.observation_spec())
# These two functions below should not be overridden by subclasses.
def _reset(self):
"""Returns a time step containing an observation."""
return ts.restart(self._observe(), batch_size=self.batch_size)
def _step(self, action):
"""Returns a time step containing the reward for the action taken."""
reward = self._apply_action(action)
return ts.termination(self._observe(), reward)
# These two functions below are to be implemented in subclasses.
@abc.abstractmethod
def _observe(self):
"""Returns an observation."""
@abc.abstractmethod
def _apply_action(self, action):
"""Applies `action` to the Environment and returns the corresponding reward.
"""
O acima de implementos classe abstrata intercalares PyEnvironment 's _reset e _step funções e expõe as funções abstratas _observe e _apply_action a ser implementado por subclasses.
Um exemplo simples de classe de ambiente
A classe a seguir fornece um ambiente muito simples para o qual a observação é um número inteiro aleatório entre -2 e 2, existem 3 ações possíveis (0, 1, 2) e a recompensa é o produto da ação e da observação.
class SimplePyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
super(SimplePyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return action * self._observation
Agora podemos usar este ambiente para obter observações e receber recompensas por nossas ações.
environment = SimplePyEnvironment()
observation = environment.reset().observation
print("observation: %d" % observation)
action = 2
print("action: %d" % action)
reward = environment.step(action).reward
print("reward: %f" % reward)
observation: -1 action: 2 reward: -2.000000
Ambientes TF
Pode-se definir um ambiente de bandido por subclasse BanditTFEnvironment , ou, de forma semelhante a ambientes RL, pode-se definir um BanditPyEnvironment e envolvê-la com TFPyEnvironment . Para simplificar, escolhemos a última opção neste tutorial.
tf_environment = tf_py_environment.TFPyEnvironment(environment)
Políticas
Uma política em um problema bandido funciona da mesma maneira como em um problema RL: ele fornece uma ação (ou uma distribuição de ações), tendo em conta uma observação como entrada.
Para mais detalhes, veja o tutorial TF-agentes Política .
Tal como acontece com os ambientes, há duas maneiras de construir uma política: pode-se criar um PyPolicy e envolvê-la com TFPyPolicy , ou criar diretamente um TFPolicy . Aqui, optamos pelo método direto.
Como este exemplo é bastante simples, podemos definir a política ideal manualmente. A ação depende apenas do sinal da observação, 0 quando é negativo e 2 quando é positivo.
class SignPolicy(tf_policy.TFPolicy):
def __init__(self):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
super(SignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return ()
def _action(self, time_step, policy_state, seed):
observation_sign = tf.cast(tf.sign(time_step.observation[0]), dtype=tf.int32)
action = observation_sign + 1
return policy_step.PolicyStep(action, policy_state)
Agora podemos solicitar uma observação do ambiente, chamar a política para escolher uma ação, então o ambiente produzirá a recompensa:
sign_policy = SignPolicy()
current_time_step = tf_environment.reset()
print('Observation:')
print (current_time_step.observation)
action = sign_policy.action(current_time_step).action
print('Action:')
print (action)
reward = tf_environment.step(action).reward
print('Reward:')
print(reward)
Observation: tf.Tensor([[2]], shape=(1, 1), dtype=int32) Action: tf.Tensor([2], shape=(1,), dtype=int32) Reward: tf.Tensor([[4.]], shape=(1, 1), dtype=float32)
A forma como os ambientes de bandidos são implementados garante que cada vez que damos um passo, não recebamos apenas a recompensa pela ação que realizamos, mas também a próxima observação.
step = tf_environment.reset()
action = 1
next_step = tf_environment.step(action)
reward = next_step.reward
next_observation = next_step.observation
print("Reward: ")
print(reward)
print("Next observation:")
print(next_observation)
Reward: tf.Tensor([[-2.]], shape=(1, 1), dtype=float32) Next observation: tf.Tensor([[0]], shape=(1, 1), dtype=int32)
Agentes
Agora que temos ambientes e políticas de bandidos, é hora de definir também os agentes de bandidos, que cuidam de mudar a política com base em amostras de treinamento.
A API para agentes de bandidos não difere da de agentes RL: o agente só precisa de implementar o _initialize e _train métodos e definir uma policy e uma collect_policy .
Um ambiente mais complicado
Antes de escrevermos nosso agente bandido, precisamos ter um ambiente um pouco mais difícil de descobrir. Para apimentar as coisas um pouco, o próximo ambiente vão quer sempre dar reward = observation * action ou reward = -observation * action . Isso será decidido quando o ambiente for inicializado.
class TwoWayPyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
# Flipping the sign with probability 1/2.
self._reward_sign = 2 * np.random.randint(2) - 1
print("reward sign:")
print(self._reward_sign)
super(TwoWayPyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return self._reward_sign * action * self._observation[0]
two_way_tf_environment = tf_py_environment.TFPyEnvironment(TwoWayPyEnvironment())
reward sign: -1
Uma política mais complicada
Um ambiente mais complicado exige uma política mais complicada. Precisamos de uma política que detecte o comportamento do ambiente subjacente. Existem três situações que a política precisa lidar:
- O agente ainda não detectou saber qual versão do ambiente está em execução.
- O agente detectou que a versão original do ambiente está em execução.
- O agente detectou que a versão invertida do ambiente está em execução.
Nós definimos um tf_variable chamado _situation para armazenar essas informações codificadas como valores em [0, 2] , em seguida, fazer a comportar política de conformidade.
class TwoWaySignPolicy(tf_policy.TFPolicy):
def __init__(self, situation):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
self._situation = situation
super(TwoWaySignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return [self._situation]
def _action(self, time_step, policy_state, seed):
sign = tf.cast(tf.sign(time_step.observation[0, 0]), dtype=tf.int32)
def case_unknown_fn():
# Choose 1 so that we get information on the sign.
return tf.constant(1, shape=(1,))
# Choose 0 or 2, depending on the situation and the sign of the observation.
def case_normal_fn():
return tf.constant(sign + 1, shape=(1,))
def case_flipped_fn():
return tf.constant(1 - sign, shape=(1,))
cases = [(tf.equal(self._situation, 0), case_unknown_fn),
(tf.equal(self._situation, 1), case_normal_fn),
(tf.equal(self._situation, 2), case_flipped_fn)]
action = tf.case(cases, exclusive=True)
return policy_step.PolicyStep(action, policy_state)
O agente
Agora é hora de definir o agente que detecta o sinal do ambiente e define a política de forma adequada.
class SignAgent(tf_agent.TFAgent):
def __init__(self):
self._situation = tf.Variable(0, dtype=tf.int32)
policy = TwoWaySignPolicy(self._situation)
time_step_spec = policy.time_step_spec
action_spec = policy.action_spec
super(SignAgent, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec,
policy=policy,
collect_policy=policy,
train_sequence_length=None)
def _initialize(self):
return tf.compat.v1.variables_initializer(self.variables)
def _train(self, experience, weights=None):
observation = experience.observation
action = experience.action
reward = experience.reward
# We only need to change the value of the situation variable if it is
# unknown (0) right now, and we can infer the situation only if the
# observation is not 0.
needs_action = tf.logical_and(tf.equal(self._situation, 0),
tf.not_equal(reward, 0))
def new_situation_fn():
"""This returns either 1 or 2, depending on the signs."""
return (3 - tf.sign(tf.cast(observation[0, 0, 0], dtype=tf.int32) *
tf.cast(action[0, 0], dtype=tf.int32) *
tf.cast(reward[0, 0], dtype=tf.int32))) / 2
new_situation = tf.cond(needs_action,
new_situation_fn,
lambda: self._situation)
new_situation = tf.cast(new_situation, tf.int32)
tf.compat.v1.assign(self._situation, new_situation)
return tf_agent.LossInfo((), ())
sign_agent = SignAgent()
No código acima, o agente define a política, ea variável situation é compartilhada pelo agente e da política.
Além disso, o parâmetro experience do _train função é uma trajetória:
Trajetórias
Em TF-agentes, trajectories são nomeadas tuplas que contêm amostras de etapas anteriores tomadas. Essas amostras são então usadas pelo agente para treinar e atualizar a política. Em RL, as trajetórias devem conter informações sobre o estado atual, o próximo estado e se o episódio atual terminou. Já que no mundo Bandit não precisamos dessas coisas, configuramos uma função auxiliar para criar uma trajetória:
# We need to add another dimension here because the agent expects the
# trajectory of shape [batch_size, time, ...], but in this tutorial we assume
# that both batch size and time are 1. Hence all the expand_dims.
def trajectory_for_bandit(initial_step, action_step, final_step):
return trajectory.Trajectory(observation=tf.expand_dims(initial_step.observation, 0),
action=tf.expand_dims(action_step.action, 0),
policy_info=action_step.info,
reward=tf.expand_dims(final_step.reward, 0),
discount=tf.expand_dims(final_step.discount, 0),
step_type=tf.expand_dims(initial_step.step_type, 0),
next_step_type=tf.expand_dims(final_step.step_type, 0))
Treinando um Agente
Agora todas as peças estão prontas para treinar nosso agente bandido.
step = two_way_tf_environment.reset()
for _ in range(10):
action_step = sign_agent.collect_policy.action(step)
next_step = two_way_tf_environment.step(action_step.action)
experience = trajectory_for_bandit(step, action_step, next_step)
print(experience)
sign_agent.train(experience)
step = next_step
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[0]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[1.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[2.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[4.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
A partir do resultado, pode-se ver que após a segunda etapa (a menos que a observação fosse 0 na primeira etapa), a política escolhe a ação da maneira certa e, portanto, a recompensa coletada é sempre não negativa.
Um exemplo real de bandido contextual
No restante deste tutorial, utilizamos os pré-implementado ambientes e agentes da biblioteca TF-agentes Bandits.
# Imports for example.
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_py_environment as sspe
from tf_agents.bandits.metrics import tf_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.replay_buffers import tf_uniform_replay_buffer
import matplotlib.pyplot as plt
Ambiente Estocástico Estocástico com Funções Lineares de Payoff
O ambiente utilizado neste exemplo é o StationaryStochasticPyEnvironment . Este ambiente assume como parâmetro uma função (geralmente ruidosa) para dar observações (contexto), e para cada braço toma uma função (também ruidosa) que calcula a recompensa com base na observação dada. Em nosso exemplo, amostramos o contexto uniformemente de um cubo d-dimensional e as funções de recompensa são funções lineares do contexto, além de algum ruído gaussiano.
batch_size = 2 # @param
arm0_param = [-3, 0, 1, -2] # @param
arm1_param = [1, -2, 3, 0] # @param
arm2_param = [0, 0, 1, 1] # @param
def context_sampling_fn(batch_size):
"""Contexts from [-10, 10]^4."""
def _context_sampling_fn():
return np.random.randint(-10, 10, [batch_size, 4]).astype(np.float32)
return _context_sampling_fn
class LinearNormalReward(object):
"""A class that acts as linear reward function when called."""
def __init__(self, theta, sigma):
self.theta = theta
self.sigma = sigma
def __call__(self, x):
mu = np.dot(x, self.theta)
return np.random.normal(mu, self.sigma)
arm0_reward_fn = LinearNormalReward(arm0_param, 1)
arm1_reward_fn = LinearNormalReward(arm1_param, 1)
arm2_reward_fn = LinearNormalReward(arm2_param, 1)
environment = tf_py_environment.TFPyEnvironment(
sspe.StationaryStochasticPyEnvironment(
context_sampling_fn(batch_size),
[arm0_reward_fn, arm1_reward_fn, arm2_reward_fn],
batch_size=batch_size))
O Agente LinUCB
O agente abaixo implementa o LinUCB algoritmo.
observation_spec = tensor_spec.TensorSpec([4], tf.float32)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=2)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec)
Métrica de arrependimento
Métrica mais importante bandidos é arrependimento, calculado como a diferença entre a recompensa coletadas pelo agente ea recompensa esperada de uma política oráculo que tem acesso às funções de recompensa do meio ambiente. O RegretMetric precisa, assim, uma função baseline_reward_fn que calcula a melhor recompensa esperada viável dada uma observação. Para nosso exemplo, precisamos pegar o máximo dos equivalentes sem ruído das funções de recompensa que já definimos para o ambiente.
def compute_optimal_reward(observation):
expected_reward_for_arms = [
tf.linalg.matvec(observation, tf.cast(arm0_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm1_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm2_param, dtype=tf.float32))]
optimal_action_reward = tf.reduce_max(expected_reward_for_arms, axis=0)
return optimal_action_reward
regret_metric = tf_metrics.RegretMetric(compute_optimal_reward)
Treinamento
Agora reunimos todos os componentes que apresentamos acima: o ambiente, a política e o agente. Corremos a política sobre os dados do ambiente e formação de saída com a ajuda de um motorista, e treinar o agente sobre os dados.
Observe que existem dois parâmetros que, juntos, especificam o número de etapas executadas. num_iterations especifica quantas vezes corremos o ciclo treinador, enquanto o motorista terá steps_per_loop passos por iteração. A principal razão para manter esses dois parâmetros é que algumas operações são feitas por iteração, enquanto outras são feitas pelo driver em cada etapa. Por exemplo, o agente train função só é chamado uma vez por iteração. A compensação aqui é que, se treinarmos com mais frequência, nossa política será "mais fresca"; por outro lado, o treinamento em lotes maiores pode ser mais eficiente em termos de tempo.
num_iterations = 90 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=batch_size,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=environment,
policy=agent.collect_policy,
num_steps=steps_per_loop * batch_size,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
plt.plot(regret_values)
plt.ylabel('Average Regret')
plt.xlabel('Number of Iterations')
WARNING:tensorflow:From /tmp/ipykernel_11392/3138849230.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead. Text(0.5, 0, 'Number of Iterations')
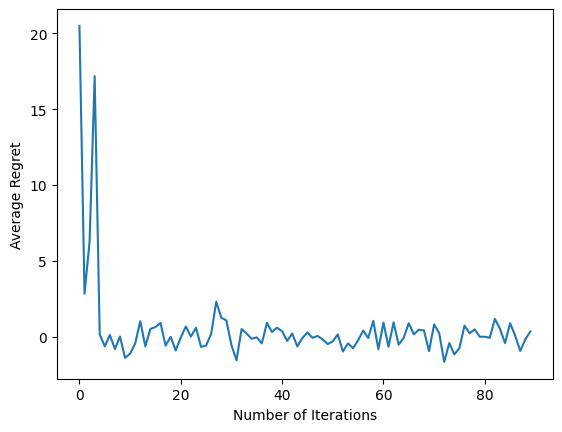
Depois de executar o último fragmento de código, o gráfico resultante (com sorte) mostra que o arrependimento médio está diminuindo conforme o agente é treinado e a política fica melhor em descobrir qual é a ação certa, dada a observação.
Qual é o próximo?
Para ver mais exemplos de trabalho, consulte o bandidos / agentes / exemplos diretório que tem exemplos prontos para correr para os diferentes agentes e ambientes.
A biblioteca TF-Agents também é capaz de lidar com Multi-Armed Bandits com recursos por braço. Para esse fim, remeter o leitor para o bandido per-braço tutorial .