
Copyright 2021 Les auteurs TF-Agents.
Commencer
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Ce tutoriel est un guide étape par étape sur la façon d'utiliser la bibliothèque TF-Agents pour les problèmes de bandits contextuels où les actions (bras) ont leurs propres fonctionnalités, telles qu'une liste de films représentés par des fonctionnalités (genre, année de sortie, ...).
Prérequis
On suppose que le lecteur est un peu familier avec la bibliothèque Bandit de TF-agents, en particulier, a travaillé à travers le tutoriel pour Bandits à TF-agents avant de lire ce tutoriel.
Bandits multi-bras avec caractéristiques de bras
Dans le cadre « classique » des bandits multi-bras contextuels, un agent reçoit un vecteur de contexte (alias observation) à chaque pas de temps et doit choisir parmi un ensemble fini d'actions numérotées (bras) afin de maximiser sa récompense cumulative.
Considérons maintenant le scénario dans lequel un agent recommande à un utilisateur le prochain film à regarder. A chaque fois qu'une décision doit être prise, l'agent reçoit en contexte des informations sur l'utilisateur (historique de visionnage, préférence de genre, etc...), ainsi que la liste des films à choisir.
Nous pourrions essayer de formuler ce problème en ayant les informations utilisateur que le contexte et les armes serait movie_1, movie_2, ..., movie_K , mais cette approche a plusieurs défauts:
- Le nombre d'actions devrait correspondre à tous les films du système et il est fastidieux d'ajouter un nouveau film.
- L'agent doit apprendre un modèle pour chaque film.
- La similarité entre les films n'est pas prise en compte.
Au lieu de numéroter les films, nous pouvons faire quelque chose de plus intuitif : nous pouvons représenter les films avec un ensemble de caractéristiques comprenant le genre, la durée, la distribution, le classement, l'année, etc. Les avantages de cette approche sont multiples :
- Généralisation à travers les films.
- L'agent apprend une seule fonction de récompense qui modélise la récompense avec des fonctionnalités d'utilisateur et de film.
- Facile à retirer ou à introduire de nouveaux films dans le système.
Dans ce nouveau cadre, le nombre d'actions n'a même pas besoin d'être le même à chaque pas de temps.
Bandits par bras dans TF-Agents
La suite TF-Agents Bandit est développée pour que l'on puisse également l'utiliser pour le cas par bras. Il existe des environnements par bras, et la plupart des stratégies et des agents peuvent également fonctionner en mode par bras.
Avant de plonger dans le codage d'un exemple, nous avons besoin des importations nécessaires.
Installation
pip install tf-agents
Importations
import functools
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_per_arm_py_environment as p_a_env
from tf_agents.bandits.metrics import tf_metrics as tf_bandit_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.environments import tf_py_environment
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
nest = tf.nest
Paramètres - N'hésitez pas à jouer
# The dimension of the global features.
GLOBAL_DIM = 40
# The elements of the global feature will be integers in [-GLOBAL_BOUND, GLOBAL_BOUND).
GLOBAL_BOUND = 10
# The dimension of the per-arm features.
PER_ARM_DIM = 50
# The elements of the PER-ARM feature will be integers in [-PER_ARM_BOUND, PER_ARM_BOUND).
PER_ARM_BOUND = 6
# The variance of the Gaussian distribution that generates the rewards.
VARIANCE = 100.0
# The elements of the linear reward parameter will be integers in [-PARAM_BOUND, PARAM_BOUND).
PARAM_BOUND = 10
NUM_ACTIONS = 70
BATCH_SIZE = 20
# Parameter for linear reward function acting on the
# concatenation of global and per-arm features.
reward_param = list(np.random.randint(
-PARAM_BOUND, PARAM_BOUND, [GLOBAL_DIM + PER_ARM_DIM]))
Un environnement simple par bras
L'environnement stochastique stationnaire, a expliqué dans l'autre tutoriel , a une contre - per-bras.
Pour initialiser l'environnement par bras, il faut définir des fonctions qui génèrent
- mondiale et caractéristiques par le bras: Ces fonctions ont aucun paramètre d'entrée et génèrent un (global ou par bras) vecteur caractéristique lorsqu'il est appelé.
- récompense: Cette fonction prend en paramètre la concaténation d'un vecteur global et une fonction par le bras, et génère une récompense. Fondamentalement, c'est la fonction que l'agent devra "deviner". Il convient de noter ici que dans le cas par bras, la fonction de récompense est identique pour chaque bras. Il s'agit d'une différence fondamentale par rapport au cas classique du bandit, où l'agent doit estimer les fonctions de récompense pour chaque bras indépendamment.
def global_context_sampling_fn():
"""This function generates a single global observation vector."""
return np.random.randint(
-GLOBAL_BOUND, GLOBAL_BOUND, [GLOBAL_DIM]).astype(np.float32)
def per_arm_context_sampling_fn():
""""This function generates a single per-arm observation vector."""
return np.random.randint(
-PER_ARM_BOUND, PER_ARM_BOUND, [PER_ARM_DIM]).astype(np.float32)
def linear_normal_reward_fn(x):
"""This function generates a reward from the concatenated global and per-arm observations."""
mu = np.dot(x, reward_param)
return np.random.normal(mu, VARIANCE)
Nous sommes maintenant équipés pour initialiser notre environnement.
per_arm_py_env = p_a_env.StationaryStochasticPerArmPyEnvironment(
global_context_sampling_fn,
per_arm_context_sampling_fn,
NUM_ACTIONS,
linear_normal_reward_fn,
batch_size=BATCH_SIZE
)
per_arm_tf_env = tf_py_environment.TFPyEnvironment(per_arm_py_env)
Ci-dessous, nous pouvons vérifier ce que cet environnement produit.
print('observation spec: ', per_arm_tf_env.observation_spec())
print('\nAn observation: ', per_arm_tf_env.reset().observation)
action = tf.zeros(BATCH_SIZE, dtype=tf.int32)
time_step = per_arm_tf_env.step(action)
print('\nRewards after taking an action: ', time_step.reward)
observation spec: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None), 'per_arm': TensorSpec(shape=(70, 50), dtype=tf.float32, name=None)}
An observation: {'global': <tf.Tensor: shape=(20, 40), dtype=float32, numpy=
array([[ -9., -4., -3., 3., 5., -9., 6., -5., 4., -8., -6.,
-1., -7., -5., 7., 8., 2., 5., -8., 0., -4., 4.,
-1., -1., -4., 6., 8., 6., 9., -5., -1., -1., 2.,
5., -1., -8., 1., 0., 0., 5.],
[ 5., 7., 0., 3., -8., -7., -5., -2., -8., -7., -7.,
-8., 5., -3., 5., 4., -5., 2., -6., -10., -4., -2.,
2., -1., -1., 8., -7., 7., 2., -3., -10., -1., -4.,
-7., 3., 4., 8., -2., 9., 5.],
[ -6., -2., -1., -1., 6., -3., 4., 9., 2., -2., 3.,
1., 0., -7., 5., 5., -8., -4., 5., 7., -10., -4.,
5., 6., 8., -10., 7., -1., -8., -8., -6., -6., 4.,
-10., -8., 3., 8., -9., -5., 8.],
[ -1., 8., -8., -7., 9., 2., -6., 8., 4., -2., 1.,
8., -4., 3., 1., -6., -9., 3., -5., 7., -9., 6.,
6., -3., 1., 2., -1., 3., 7., 4., -8., 1., 1.,
3., -4., 1., -4., -5., -9., 4.],
[ -9., 8., 9., -8., 2., 9., -1., -9., -1., 9., -8.,
-4., 1., 1., 9., 6., -6., -10., -6., 2., 6., -4.,
-7., -2., -7., -8., -4., 5., -6., -1., 8., -3., -7.,
4., -9., -9., 6., -9., 6., -2.],
[ 0., -6., -5., -8., -10., 2., -4., 9., 9., -1., 5.,
-7., -1., -3., -10., -10., 3., -2., -7., -9., -4., -8.,
-4., -1., 7., -2., -4., -4., 9., 2., -2., -8., 6.,
5., -4., 7., 0., 6., -3., 2.],
[ 8., 5., 3., 5., 9., 4., -10., -5., -4., -4., -5.,
3., 5., -4., 9., -2., -7., -6., -2., -8., -7., -10.,
0., -2., 3., 1., -10., -8., 3., 9., -5., -6., 1.,
-7., -1., 3., -7., -2., 1., -1.],
[ 3., 9., 8., 6., -2., 9., 9., 7., 0., 5., -5.,
6., 9., 3., 2., 9., 4., -1., -3., 3., -1., -4.,
-9., -1., -3., 8., 0., 4., -1., 4., -3., 4., -5.,
-3., -6., -4., 7., -9., -7., -1.],
[ 5., -1., 9., -5., 8., 7., -7., -5., 0., -4., -5.,
6., -3., -1., 7., 3., -7., -9., 6., 4., 9., 6.,
-3., 3., -2., -6., -4., -7., -5., -6., -2., -1., -9.,
-4., -9., -2., -7., -6., -3., 6.],
[ -7., 1., -8., 1., -8., -9., 5., 1., -4., -2., -5.,
3., -1., -4., -4., 5., 0., -10., -4., -1., -5., 3.,
8., -5., -4., -10., -8., -6., -10., -1., -6., 1., 7.,
8., 6., -2., -4., -9., 7., -1.],
[ -2., 3., 8., -5., 0., 5., 8., -5., 6., -8., 5.,
8., -5., -5., -5., -10., 4., 8., -4., -7., 4., -6.,
-9., -8., -5., 4., -1., -2., -7., -10., -6., -8., -6.,
3., 1., 6., 9., 6., -8., -3.],
[ 9., -6., -2., -10., 2., -8., 8., -7., -5., 8., -10.,
4., -5., 9., 7., 9., -2., -9., -5., -2., 9., 0.,
-6., 2., 4., 6., -7., -4., -5., -7., -8., -8., 8.,
-7., -1., -5., 0., -7., 7., -6.],
[ -1., -3., 1., 8., 4., 7., -1., -8., -4., 6., 9.,
5., -10., 4., -4., 5., -2., 0., 3., 4., 3., -5.,
-2., 7., 4., -4., -9., 9., -6., -5., -8., 4., -10.,
-6., 3., 0., 6., -10., 4., 3.],
[ 8., 8., -5., 0., -7., 5., -6., -8., 2., -3., -5.,
5., 0., 6., -10., 3., -4., 1., -8., -9., 6., -5.,
5., -10., 1., 0., 3., 5., 2., -9., -6., 9., 7.,
9., -10., 4., -4., -10., -5., 1.],
[ 8., 3., -5., -2., -8., -6., 6., -7., 8., 1., -8.,
0., -2., 3., -6., 0., -10., 6., -8., -2., -5., 4.,
-1., -9., -7., 3., -1., -4., -1., -10., -3., -7., -3.,
4., -7., -6., -1., 9., -3., 2.],
[ 8., 7., 6., -5., -3., 0., 1., -2., 0., -3., 9.,
-8., 5., 1., 1., 1., -5., 4., -4., 0., -4., -3.,
7., -10., 3., 6., 4., 5., 2., -7., 0., -3., -5.,
2., -6., 4., 5., 8., -1., -3.],
[ 8., -9., -4., 8., -2., 9., 5., 5., -3., -4., 0.,
-5., 5., -2., -10., -4., -3., 5., 8., 6., -2., -2.,
-1., -8., -5., -9., 1., -1., 5., 6., 4., 9., -5.,
6., -2., 7., -7., -9., 4., 2.],
[ 2., 4., 6., 2., 6., -6., -2., 5., 8., 1., 3.,
8., 6., 9., -3., -1., 4., 7., -5., 7., 0., -10.,
9., -6., -4., -7., 1., -2., -2., 3., -1., 2., 5.,
8., 4., -9., 1., -4., 9., 6.],
[ -8., -5., 9., 3., 9., -10., -8., 3., -8., 0., -4.,
-8., -3., -4., -3., 0., 8., 3., -10., 7., 7., -3.,
8., 4., -3., 9., 3., 7., 2., 7., -8., -3., -4.,
-7., 3., -9., -10., 2., 5., 7.],
[ 5., -7., -8., 6., -8., 1., -8., 4., 2., 6., -6.,
-5., 4., -1., 3., -8., -3., 6., 5., -5., 1., -7.,
8., -10., 8., 1., 3., 7., 2., 2., -1., 1., -3.,
7., 1., 6., -6., 0., -9., 6.]], dtype=float32)>, 'per_arm': <tf.Tensor: shape=(20, 70, 50), dtype=float32, numpy=
array([[[ 5., -6., 4., ..., -3., 3., 4.],
[-5., -6., -4., ..., 3., 4., -4.],
[ 1., -1., 5., ..., -1., -3., 1.],
...,
[ 3., 3., -5., ..., 4., 4., 0.],
[ 5., 1., -3., ..., -2., -2., -3.],
[-6., 4., 2., ..., 4., 5., -5.]],
[[-5., -3., 1., ..., -2., -1., 1.],
[ 1., 4., -1., ..., -1., -4., -4.],
[ 4., -6., 5., ..., 2., -2., 4.],
...,
[ 0., 4., -4., ..., -1., -3., 1.],
[ 3., 4., 5., ..., -5., -2., -2.],
[ 0., 4., -3., ..., 5., 1., 3.]],
[[-2., -6., -6., ..., -6., 1., -5.],
[ 4., 5., 5., ..., 1., 4., -4.],
[ 0., 0., -3., ..., -5., 0., -2.],
...,
[-3., -1., 4., ..., 5., -2., 5.],
[-3., -6., -2., ..., 3., 1., -5.],
[ 5., -3., -5., ..., -4., 4., -5.]],
...,
[[ 4., 3., 0., ..., 1., -6., 4.],
[-5., -3., 5., ..., 0., -1., -5.],
[ 0., 4., 3., ..., -2., 1., -3.],
...,
[-5., -2., -5., ..., -5., -5., -2.],
[-2., 5., 4., ..., -2., -2., 2.],
[-1., -4., 4., ..., -5., 2., -3.]],
[[-1., -4., 4., ..., -3., -5., 4.],
[-4., -6., -2., ..., -1., -6., 0.],
[ 0., 0., 5., ..., 4., -4., 0.],
...,
[ 2., 3., 5., ..., -6., -5., 5.],
[-5., -5., 2., ..., 0., 4., -2.],
[ 4., -5., -4., ..., -5., -5., -1.]],
[[ 3., 0., 2., ..., 2., 1., -3.],
[-5., -4., 3., ..., -6., 0., -2.],
[-4., -5., 3., ..., -6., -3., 0.],
...,
[-6., -6., 4., ..., -1., -5., -2.],
[-4., 3., -1., ..., 1., 4., 4.],
[ 5., 2., 2., ..., -3., 1., -4.]]], dtype=float32)>}
Rewards after taking an action: tf.Tensor(
[-130.17787 344.98013 371.39893 75.433975 396.35742
-176.46881 56.62174 -158.03278 491.3239 -156.10696
-1.0527252 -264.42285 22.356699 -395.89832 125.951546
142.99467 -322.3012 -24.547596 -159.47539 -44.123775 ], shape=(20,), dtype=float32)
On voit que la spécification d'observation est un dictionnaire avec deux éléments :
- L' un avec la clé
'global': ceci est la partie de contexte global, avec une forme correspondant au paramètreGLOBAL_DIM. - Une avec la clé
'per_arm': c'est le contexte par le bras, et sa forme est[NUM_ACTIONS, PER_ARM_DIM]. Cette partie est l'espace réservé pour les fonctions de bras pour chaque bras dans un pas de temps.
L'agent LinUCB
L'agent LinUCB implémente l'algorithme Bandit du même nom, qui estime le paramètre de la fonction de récompense linéaire tout en maintenant un ellipsoïde de confiance autour de l'estimation. L'agent choisit le bras qui a la récompense attendue estimée la plus élevée, en supposant que le paramètre se trouve dans l'ellipsoïde de confiance.
La création d'un agent nécessite la connaissance de l'observation et la spécification de l'action. Lors de la définition de l'agent, nous avons mis le paramètre booléen accepts_per_arm_features réglé sur True .
observation_spec = per_arm_tf_env.observation_spec()
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=NUM_ACTIONS - 1)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec,
accepts_per_arm_features=True)
Le flux de données d'entraînement
Cette section donne un aperçu de la façon dont les fonctionnalités par bras passent de la politique à la formation. N'hésitez pas à passer à la section suivante (Définition de la métrique de regret) et à revenir ici plus tard si vous êtes intéressé.
Tout d'abord, examinons la spécification des données dans l'agent. L' training_data_spec attribut de l'agent spécifie quels éléments et la structure des données de formation devrait avoir.
print('training data spec: ', agent.training_data_spec)
training data spec: Trajectory(
{'action': BoundedTensorSpec(shape=(), dtype=tf.int32, name=None, minimum=array(0, dtype=int32), maximum=array(69, dtype=int32)),
'discount': BoundedTensorSpec(shape=(), dtype=tf.float32, name='discount', minimum=array(0., dtype=float32), maximum=array(1., dtype=float32)),
'next_step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type'),
'observation': {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)},
'policy_info': PerArmPolicyInfo(log_probability=(), predicted_rewards_mean=(), multiobjective_scalarized_predicted_rewards_mean=(), predicted_rewards_optimistic=(), predicted_rewards_sampled=(), bandit_policy_type=(), chosen_arm_features=TensorSpec(shape=(50,), dtype=tf.float32, name=None)),
'reward': TensorSpec(shape=(), dtype=tf.float32, name='reward'),
'step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type')})
Si nous regardons de plus près à l' observation une partie de la spécification, nous voyons qu'il ne contient pas de fonctionnalités par le bras!
print('observation spec in training: ', agent.training_data_spec.observation)
observation spec in training: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)}
Qu'est-il arrivé aux fonctionnalités par bras ? Pour répondre à cette question, d' abord , nous constatons que lorsque les trains d'agent de LinUCB, il n'a pas besoin des fonctionnalités par le bras de tous les bras, il faut que ceux du bras choisi. Par conséquent, il est logique de laisser tomber le tenseur de forme [BATCH_SIZE, NUM_ACTIONS, PER_ARM_DIM] , car il est très inutile, surtout si le nombre d'actions est grande.
Mais quand même, les caractéristiques par bras du bras choisi doivent être quelque part ! À cette fin, nous nous assurons que les magasins de politique LinUCB les caractéristiques du bras choisi dans le policy_info champ des données de formation:
print('chosen arm features: ', agent.training_data_spec.policy_info.chosen_arm_features)
chosen arm features: TensorSpec(shape=(50,), dtype=tf.float32, name=None)
On voit de la forme que le chosen_arm_features champ n'a que le vecteur caractéristique d'un bras, et ce sera le bras choisi. Notez que le policy_info , et avec elle les chosen_arm_features , fait partie des données de formation, comme nous l'avons vu d'inspecter les spécifications des données de formation, et il est donc disponible au moment de la formation.
Définition de la métrique de regret
Avant de commencer la boucle d'apprentissage, nous définissons quelques fonctions utilitaires qui aident à calculer le regret de notre agent. Ces fonctions aident à déterminer la récompense optimale attendue étant donné l'ensemble des actions (données par leurs caractéristiques de bras) et le paramètre linéaire qui est caché à l'agent.
def _all_rewards(observation, hidden_param):
"""Outputs rewards for all actions, given an observation."""
hidden_param = tf.cast(hidden_param, dtype=tf.float32)
global_obs = observation['global']
per_arm_obs = observation['per_arm']
num_actions = tf.shape(per_arm_obs)[1]
tiled_global = tf.tile(
tf.expand_dims(global_obs, axis=1), [1, num_actions, 1])
concatenated = tf.concat([tiled_global, per_arm_obs], axis=-1)
rewards = tf.linalg.matvec(concatenated, hidden_param)
return rewards
def optimal_reward(observation):
"""Outputs the maximum expected reward for every element in the batch."""
return tf.reduce_max(_all_rewards(observation, reward_param), axis=1)
regret_metric = tf_bandit_metrics.RegretMetric(optimal_reward)
Nous sommes maintenant prêts à commencer notre boucle d'entraînement de bandit. Le pilote ci-dessous s'occupe de choisir les actions à l'aide de la politique, de stocker les récompenses des actions choisies dans le tampon de relecture, de calculer la métrique de regret prédéfinie et d'exécuter l'étape de formation de l'agent.
num_iterations = 20 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=BATCH_SIZE,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=per_arm_tf_env,
policy=agent.collect_policy,
num_steps=steps_per_loop * BATCH_SIZE,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
WARNING:tensorflow:From /tmp/ipykernel_12052/1190294793.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead.
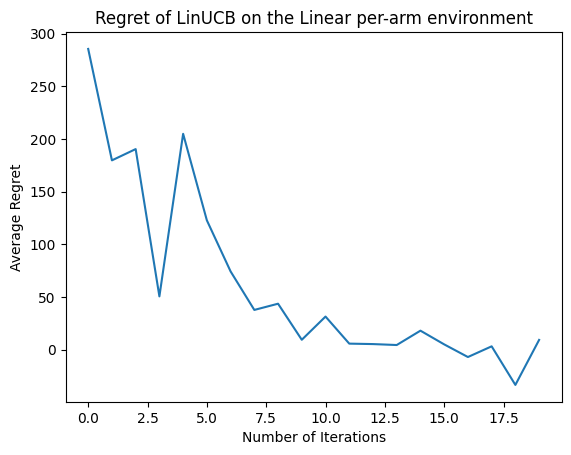
Voyons maintenant le résultat. Si nous avons tout fait correctement, l'agent est capable de bien estimer la fonction de récompense linéaire, et ainsi la politique peut choisir des actions dont la récompense attendue est proche de celle de l'optimum. Ceci est indiqué par notre métrique de regret définie ci-dessus, qui diminue et se rapproche de zéro.
plt.plot(regret_values)
plt.title('Regret of LinUCB on the Linear per-arm environment')
plt.xlabel('Number of Iterations')
_ = plt.ylabel('Average Regret')
Et après?
L'exemple ci - dessus est mis en œuvre dans notre base de code où vous pouvez choisir d'autres agents aussi bien, y compris l' agent epsilon-Greedy Neural .