
| | |  Ver no GitHub Ver no GitHub | | |
Introdução
Bem-vindo à composição tutorial modelo para Florestas decisão TensorFlow (TF-DF). Este notebook mostra como compor várias florestas de decisão e modelos de redes neurais em conjunto, utilizando uma camada de pré-processamento comum ea API funcional Keras .
Você pode querer compor modelos juntos para melhorar o desempenho preditivo (agrupamento), para obter o melhor de diferentes tecnologias de modelagem (agrupamento de modelo heterogêneo), para treinar diferentes partes do modelo em conjuntos de dados diferentes (por exemplo, pré-treinamento) ou para criar um modelo empilhado (por exemplo, um modelo opera nas previsões de outro modelo).
Este tutorial cobre um caso de uso avançado de composição de modelo usando a API Funcional. Você pode encontrar exemplos para cenários mais simples de composição modelo na seção deste "recurso de pré-processamento" tutorial e no "usando um texto pré-treinado embutindo" deste tutorial .
Aqui está a estrutura do modelo que você construirá:
!pip install graphviz -U --quiet
from graphviz import Source
Source("""
digraph G {
raw_data [label="Input features"];
preprocess_data [label="Learnable NN pre-processing", shape=rect];
raw_data -> preprocess_data
subgraph cluster_0 {
color=grey;
a1[label="NN layer", shape=rect];
b1[label="NN layer", shape=rect];
a1 -> b1;
label = "Model #1";
}
subgraph cluster_1 {
color=grey;
a2[label="NN layer", shape=rect];
b2[label="NN layer", shape=rect];
a2 -> b2;
label = "Model #2";
}
subgraph cluster_2 {
color=grey;
a3[label="Decision Forest", shape=rect];
label = "Model #3";
}
subgraph cluster_3 {
color=grey;
a4[label="Decision Forest", shape=rect];
label = "Model #4";
}
preprocess_data -> a1;
preprocess_data -> a2;
preprocess_data -> a3;
preprocess_data -> a4;
b1 -> aggr;
b2 -> aggr;
a3 -> aggr;
a4 -> aggr;
aggr [label="Aggregation (mean)", shape=rect]
aggr -> predictions
}
""")

Seu modelo composto tem três estágios:
- O primeiro estágio é uma camada de pré-processamento composta por uma rede neural e comum a todos os modelos do próximo estágio. Na prática, essa camada de pré-processamento pode ser uma incorporação pré-treinada para ajuste fino ou uma rede neural inicializada aleatoriamente.
- O segundo estágio é um conjunto de dois modelos de floresta de decisão e dois modelos de rede neural.
- O último estágio calcula a média das previsões dos modelos do segundo estágio. Não contém pesos aprendíveis.
As redes neurais são treinados usando o algoritmo de backpropagation e gradiente descendente. Este algoritmo possui duas propriedades importantes: (1) A camada de rede neural pode ser treinada se receber um gradiente de perda (mais precisamente, o gradiente de perda de acordo com a saída da camada), e (2) o algoritmo "transmite" a gradiente de perda da saída da camada para a entrada da camada (esta é a "regra da cadeia"). Por esses dois motivos, o Backpropagation pode treinar várias camadas de redes neurais empilhadas umas sobre as outras.
Neste exemplo, as florestas de decisão são treinados com o aleatório Floresta algoritmo (RF). Ao contrário da retropropagação, o treinamento de RF não "transmite" o gradiente de perda de sua saída para sua entrada. Por essas razões, o algoritmo de RF clássico não pode ser usado para treinar ou ajustar uma rede neural por baixo. Em outras palavras, os estágios de "floresta de decisão" não podem ser usados para treinar o "bloco de pré-processamento NN aprendível".
- Treine o estágio de pré-processamento e redes neurais.
- Treine as etapas da floresta de decisão.
Instale o TensorFlow Decision Forests
Instale o TF-DF executando a célula a seguir.
pip install tensorflow_decision_forests -U --quiet
Instale Wurlitzer para mostrar os registros de treinamento detalhados. Isso só é necessário em notebooks.
pip install wurlitzer -U --quiet
Bibliotecas de importação
import tensorflow_decision_forests as tfdf
import os
import numpy as np
import pandas as pd
import tensorflow as tf
import math
import matplotlib.pyplot as plt
try:
from wurlitzer import sys_pipes
except:
from colabtools.googlelog import CaptureLog as sys_pipes
from IPython.core.magic import register_line_magic
from IPython.display import Javascript
WARNING:root:Failure to load the custom c++ tensorflow ops. This error is likely caused the version of TensorFlow and TensorFlow Decision Forests are not compatible. WARNING:root:TF Parameter Server distributed training not available.
Conjunto de dados
Você usará um conjunto de dados sintético simples neste tutorial para facilitar a interpretação do modelo final.
def make_dataset(num_examples, num_features, seed=1234):
np.random.seed(seed)
features = np.random.uniform(-1, 1, size=(num_examples, num_features))
noise = np.random.uniform(size=(num_examples))
left_side = np.sqrt(
np.sum(np.multiply(np.square(features[:, 0:2]), [1, 2]), axis=1))
right_side = features[:, 2] * 0.7 + np.sin(
features[:, 3] * 10) * 0.5 + noise * 0.0 + 0.5
labels = left_side <= right_side
return features, labels.astype(int)
Gere alguns exemplos:
make_dataset(num_examples=5, num_features=4)
(array([[-0.6169611 , 0.24421754, -0.12454452, 0.57071717],
[ 0.55995162, -0.45481479, -0.44707149, 0.60374436],
[ 0.91627871, 0.75186527, -0.28436546, 0.00199025],
[ 0.36692587, 0.42540405, -0.25949849, 0.12239237],
[ 0.00616633, -0.9724631 , 0.54565324, 0.76528238]]),
array([0, 0, 0, 1, 0]))
Você também pode representá-los para ter uma ideia do padrão sintético:
plot_features, plot_label = make_dataset(num_examples=50000, num_features=4)
plt.rcParams["figure.figsize"] = [8, 8]
common_args = dict(c=plot_label, s=1.0, alpha=0.5)
plt.subplot(2, 2, 1)
plt.scatter(plot_features[:, 0], plot_features[:, 1], **common_args)
plt.subplot(2, 2, 2)
plt.scatter(plot_features[:, 1], plot_features[:, 2], **common_args)
plt.subplot(2, 2, 3)
plt.scatter(plot_features[:, 0], plot_features[:, 2], **common_args)
plt.subplot(2, 2, 4)
plt.scatter(plot_features[:, 0], plot_features[:, 3], **common_args)
<matplotlib.collections.PathCollection at 0x7f6b78d20e90>
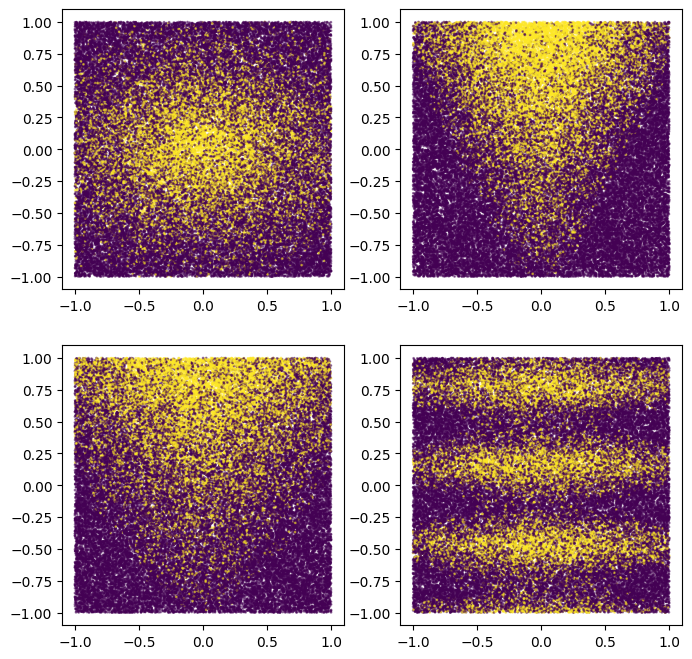
Observe que esse padrão é suave e não alinhado ao eixo. Isso irá beneficiar os modelos de rede neural. Isso ocorre porque é mais fácil para uma rede neural do que para uma árvore de decisão ter limites de decisão redondos e não alinhados.
Por outro lado, treinaremos o modelo em um pequeno conjunto de dados com 2.500 exemplos. Isso vai beneficiar os modelos de floresta de decisão. Isso ocorre porque as florestas de decisão são muito mais eficientes, usando todas as informações disponíveis nos exemplos (as florestas de decisão são "eficientes em termos de amostragem").
Nosso conjunto de redes neurais e florestas de decisão usará o melhor dos dois mundos.
Vamos criar um trem e teste tf.data.Dataset :
def make_tf_dataset(batch_size=64, **args):
features, labels = make_dataset(**args)
return tf.data.Dataset.from_tensor_slices(
(features, labels)).batch(batch_size)
num_features = 10
train_dataset = make_tf_dataset(
num_examples=2500, num_features=num_features, batch_size=64, seed=1234)
test_dataset = make_tf_dataset(
num_examples=10000, num_features=num_features, batch_size=64, seed=5678)
Estrutura do modelo
Defina a estrutura do modelo da seguinte forma:
# Input features.
raw_features = tf.keras.layers.Input(shape=(num_features,))
# Stage 1
# =======
# Common learnable pre-processing
preprocessor = tf.keras.layers.Dense(10, activation=tf.nn.relu6)
preprocess_features = preprocessor(raw_features)
# Stage 2
# =======
# Model #1: NN
m1_z1 = tf.keras.layers.Dense(5, activation=tf.nn.relu6)(preprocess_features)
m1_pred = tf.keras.layers.Dense(1, activation=tf.nn.sigmoid)(m1_z1)
# Model #2: NN
m2_z1 = tf.keras.layers.Dense(5, activation=tf.nn.relu6)(preprocess_features)
m2_pred = tf.keras.layers.Dense(1, activation=tf.nn.sigmoid)(m2_z1)
def seed_advanced_argument(seed):
"""Create a seed argument for a TF-DF model.
TODO(gbm): Surface the "seed" argument to the model constructor directly.
"""
return tfdf.keras.AdvancedArguments(
yggdrasil_training_config=tfdf.keras.core.YggdrasilTrainingConfig(
random_seed=seed))
# Model #3: DF
model_3 = tfdf.keras.RandomForestModel(
num_trees=1000, advanced_arguments=seed_advanced_argument(1234))
m3_pred = model_3(preprocess_features)
# Model #4: DF
model_4 = tfdf.keras.RandomForestModel(
num_trees=1000,
#split_axis="SPARSE_OBLIQUE", # Uncomment this line to increase the quality of this model
advanced_arguments=seed_advanced_argument(4567))
m4_pred = model_4(preprocess_features)
# Since TF-DF uses deterministic learning algorithms, you should set the model's
# training seed to different values otherwise both
# `tfdf.keras.RandomForestModel` will be exactly the same.
# Stage 3
# =======
mean_nn_only = tf.reduce_mean(tf.stack([m1_pred, m2_pred], axis=0), axis=0)
mean_nn_and_df = tf.reduce_mean(
tf.stack([m1_pred, m2_pred, m3_pred, m4_pred], axis=0), axis=0)
# Keras Models
# ============
ensemble_nn_only = tf.keras.models.Model(raw_features, mean_nn_only)
ensemble_nn_and_df = tf.keras.models.Model(raw_features, mean_nn_and_df)
WARNING:tensorflow:AutoGraph could not transform <bound method Socket.send of <zmq.Socket(zmq.PUSH) at 0x7f6ba21b62f0>> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: module, class, method, function, traceback, frame, or code object was expected, got cython_function_or_method
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING:absl:The model was called directly (i.e. using `model(data)` instead of using `model.predict(data)`) before being trained. The model will only return zeros until trained. The output shape might change after training Tensor("inputs:0", shape=(None, 10), dtype=float32)
WARNING:tensorflow:AutoGraph could not transform <bound method Socket.send of <zmq.Socket(zmq.PUSH) at 0x7f6ba21b62f0>> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: module, class, method, function, traceback, frame, or code object was expected, got cython_function_or_method
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING: AutoGraph could not transform <bound method Socket.send of <zmq.Socket(zmq.PUSH) at 0x7f6ba21b62f0>> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: module, class, method, function, traceback, frame, or code object was expected, got cython_function_or_method
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING:absl:The model was called directly (i.e. using `model(data)` instead of using `model.predict(data)`) before being trained. The model will only return zeros until trained. The output shape might change after training Tensor("inputs:0", shape=(None, 10), dtype=float32)
Antes de treinar o modelo, você pode plotá-lo para verificar se ele é semelhante ao diagrama inicial.
from keras.utils.vis_utils import plot_model
plot_model(ensemble_nn_and_df, to_file="/tmp/model.png", show_shapes=True)

Treinamento de modelo
Primeiro treine o pré-processamento e as duas camadas da rede neural usando o algoritmo de retropropagação.
%%time
ensemble_nn_only.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.BinaryCrossentropy(),
metrics=["accuracy"])
ensemble_nn_only.fit(train_dataset, epochs=20, validation_data=test_dataset)
Epoch 1/20 40/40 [==============================] - 1s 13ms/step - loss: 0.6115 - accuracy: 0.7308 - val_loss: 0.5857 - val_accuracy: 0.7407 Epoch 2/20 40/40 [==============================] - 0s 9ms/step - loss: 0.5645 - accuracy: 0.7484 - val_loss: 0.5487 - val_accuracy: 0.7391 Epoch 3/20 40/40 [==============================] - 0s 9ms/step - loss: 0.5310 - accuracy: 0.7496 - val_loss: 0.5237 - val_accuracy: 0.7392 Epoch 4/20 40/40 [==============================] - 0s 9ms/step - loss: 0.5074 - accuracy: 0.7500 - val_loss: 0.5055 - val_accuracy: 0.7391 Epoch 5/20 40/40 [==============================] - 0s 9ms/step - loss: 0.4887 - accuracy: 0.7496 - val_loss: 0.4901 - val_accuracy: 0.7397 Epoch 6/20 40/40 [==============================] - 0s 9ms/step - loss: 0.4725 - accuracy: 0.7520 - val_loss: 0.4763 - val_accuracy: 0.7440 Epoch 7/20 40/40 [==============================] - 0s 9ms/step - loss: 0.4585 - accuracy: 0.7584 - val_loss: 0.4644 - val_accuracy: 0.7542 Epoch 8/20 40/40 [==============================] - 0s 9ms/step - loss: 0.4470 - accuracy: 0.7700 - val_loss: 0.4544 - val_accuracy: 0.7682 Epoch 9/20 40/40 [==============================] - 0s 9ms/step - loss: 0.4374 - accuracy: 0.7804 - val_loss: 0.4462 - val_accuracy: 0.7789 Epoch 10/20 40/40 [==============================] - 0s 9ms/step - loss: 0.4297 - accuracy: 0.7848 - val_loss: 0.4395 - val_accuracy: 0.7865 Epoch 11/20 40/40 [==============================] - 0s 9ms/step - loss: 0.4232 - accuracy: 0.7904 - val_loss: 0.4339 - val_accuracy: 0.7933 Epoch 12/20 40/40 [==============================] - 0s 10ms/step - loss: 0.4176 - accuracy: 0.7952 - val_loss: 0.4289 - val_accuracy: 0.7963 Epoch 13/20 40/40 [==============================] - 0s 9ms/step - loss: 0.4126 - accuracy: 0.7992 - val_loss: 0.4243 - val_accuracy: 0.8010 Epoch 14/20 40/40 [==============================] - 0s 9ms/step - loss: 0.4078 - accuracy: 0.8052 - val_loss: 0.4199 - val_accuracy: 0.8033 Epoch 15/20 40/40 [==============================] - 0s 9ms/step - loss: 0.4029 - accuracy: 0.8096 - val_loss: 0.4155 - val_accuracy: 0.8067 Epoch 16/20 40/40 [==============================] - 0s 9ms/step - loss: 0.3981 - accuracy: 0.8132 - val_loss: 0.4109 - val_accuracy: 0.8099 Epoch 17/20 40/40 [==============================] - 0s 9ms/step - loss: 0.3932 - accuracy: 0.8152 - val_loss: 0.4061 - val_accuracy: 0.8129 Epoch 18/20 40/40 [==============================] - 0s 9ms/step - loss: 0.3883 - accuracy: 0.8208 - val_loss: 0.4012 - val_accuracy: 0.8149 Epoch 19/20 40/40 [==============================] - 0s 9ms/step - loss: 0.3832 - accuracy: 0.8232 - val_loss: 0.3963 - val_accuracy: 0.8168 Epoch 20/20 40/40 [==============================] - 0s 10ms/step - loss: 0.3783 - accuracy: 0.8276 - val_loss: 0.3912 - val_accuracy: 0.8203 CPU times: user 12.1 s, sys: 2.14 s, total: 14.2 s Wall time: 8.54 s <keras.callbacks.History at 0x7f6b181d7450>
Vamos avaliar o pré-processamento e a parte com as duas redes neurais apenas:
evaluation_nn_only = ensemble_nn_only.evaluate(test_dataset, return_dict=True)
print("Accuracy (NN #1 and #2 only): ", evaluation_nn_only["accuracy"])
print("Loss (NN #1 and #2 only): ", evaluation_nn_only["loss"])
157/157 [==============================] - 0s 2ms/step - loss: 0.3912 - accuracy: 0.8203 Accuracy (NN #1 and #2 only): 0.8202999830245972 Loss (NN #1 and #2 only): 0.39124569296836853
Vamos treinar os dois componentes da floresta de decisão (um após o outro).
%%time
train_dataset_with_preprocessing = train_dataset.map(lambda x,y: (preprocessor(x), y))
test_dataset_with_preprocessing = test_dataset.map(lambda x,y: (preprocessor(x), y))
model_3.fit(train_dataset_with_preprocessing)
model_4.fit(train_dataset_with_preprocessing)
WARNING:tensorflow:AutoGraph could not transform <function <lambda> at 0x7f6b86bc3dd0> and will run it as-is.
Cause: could not parse the source code of <function <lambda> at 0x7f6b86bc3dd0>: no matching AST found among candidates:
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING:tensorflow:AutoGraph could not transform <function <lambda> at 0x7f6b86bc3dd0> and will run it as-is.
Cause: could not parse the source code of <function <lambda> at 0x7f6b86bc3dd0>: no matching AST found among candidates:
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING: AutoGraph could not transform <function <lambda> at 0x7f6b86bc3dd0> and will run it as-is.
Cause: could not parse the source code of <function <lambda> at 0x7f6b86bc3dd0>: no matching AST found among candidates:
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING:tensorflow:AutoGraph could not transform <function <lambda> at 0x7f6b783a9320> and will run it as-is.
Cause: could not parse the source code of <function <lambda> at 0x7f6b783a9320>: no matching AST found among candidates:
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING:tensorflow:AutoGraph could not transform <function <lambda> at 0x7f6b783a9320> and will run it as-is.
Cause: could not parse the source code of <function <lambda> at 0x7f6b783a9320>: no matching AST found among candidates:
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING: AutoGraph could not transform <function <lambda> at 0x7f6b783a9320> and will run it as-is.
Cause: could not parse the source code of <function <lambda> at 0x7f6b783a9320>: no matching AST found among candidates:
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
23/40 [================>.............] - ETA: 0s
[INFO kernel.cc:736] Start Yggdrasil model training
[INFO kernel.cc:737] Collect training examples
[INFO kernel.cc:392] Number of batches: 40
[INFO kernel.cc:393] Number of examples: 2500
[INFO kernel.cc:759] Dataset:
Number of records: 2500
Number of columns: 11
Number of columns by type:
NUMERICAL: 10 (90.9091%)
CATEGORICAL: 1 (9.09091%)
Columns:
NUMERICAL: 10 (90.9091%)
0: "data:0.0" NUMERICAL mean:0.356465 min:0 max:2.37352 sd:0.451418
1: "data:0.1" NUMERICAL mean:0.392088 min:0 max:2.3411 sd:0.470499
2: "data:0.2" NUMERICAL mean:0.382386 min:0 max:2.11809 sd:0.483672
3: "data:0.3" NUMERICAL mean:0.290395 min:0 max:2.27481 sd:0.400102
4: "data:0.4" NUMERICAL mean:0.210684 min:0 max:1.35897 sd:0.281379
5: "data:0.5" NUMERICAL mean:0.4008 min:0 max:2.06561 sd:0.453018
6: "data:0.6" NUMERICAL mean:0.289166 min:0 max:2.0263 sd:0.407337
7: "data:0.7" NUMERICAL mean:0.277971 min:0 max:1.77561 sd:0.363215
8: "data:0.8" NUMERICAL mean:0.41254 min:0 max:2.79804 sd:0.553333
9: "data:0.9" NUMERICAL mean:0.197082 min:0 max:1.60773 sd:0.298194
CATEGORICAL: 1 (9.09091%)
10: "__LABEL" CATEGORICAL integerized vocab-size:3 no-ood-item
Terminology:
nas: Number of non-available (i.e. missing) values.
ood: Out of dictionary.
manually-defined: Attribute which type is manually defined by the user i.e. the type was not automatically inferred.
tokenized: The attribute value is obtained through tokenization.
has-dict: The attribute is attached to a string dictionary e.g. a categorical attribute stored as a string.
vocab-size: Number of unique values.
[INFO kernel.cc:762] Configure learner
[INFO kernel.cc:787] Training config:
learner: "RANDOM_FOREST"
features: "data:0\\.0"
features: "data:0\\.1"
features: "data:0\\.2"
features: "data:0\\.3"
features: "data:0\\.4"
features: "data:0\\.5"
features: "data:0\\.6"
features: "data:0\\.7"
features: "data:0\\.8"
features: "data:0\\.9"
label: "__LABEL"
task: CLASSIFICATION
random_seed: 1234
[yggdrasil_decision_forests.model.random_forest.proto.random_forest_config] {
num_trees: 1000
decision_tree {
max_depth: 16
min_examples: 5
in_split_min_examples_check: true
missing_value_policy: GLOBAL_IMPUTATION
allow_na_conditions: false
categorical_set_greedy_forward {
sampling: 0.1
max_num_items: -1
min_item_frequency: 1
}
growing_strategy_local {
}
categorical {
cart {
}
}
num_candidate_attributes_ratio: -1
axis_aligned_split {
}
internal {
sorting_strategy: PRESORTED
}
}
winner_take_all_inference: true
compute_oob_performances: true
compute_oob_variable_importances: false
adapt_bootstrap_size_ratio_for_maximum_training_duration: false
}
[INFO kernel.cc:790] Deployment config:
num_threads: 6
[INFO kernel.cc:817] Train model
[INFO random_forest.cc:315] Training random forest on 2500 example(s) and 10 feature(s).
[INFO random_forest.cc:628] Training of tree 1/1000 (tree index:1) done accuracy:0.781996 logloss:7.85767
[INFO random_forest.cc:628] Training of tree 11/1000 (tree index:8) done accuracy:0.79895 logloss:2.7263
[INFO random_forest.cc:628] Training of tree 21/1000 (tree index:20) done accuracy:0.8012 logloss:1.26831
[INFO random_forest.cc:628] Training of tree 31/1000 (tree index:30) done accuracy:0.8076 logloss:0.898323
[INFO random_forest.cc:628] Training of tree 41/1000 (tree index:37) done accuracy:0.8084 logloss:0.736323
[INFO random_forest.cc:628] Training of tree 51/1000 (tree index:51) done accuracy:0.8072 logloss:0.612984
[INFO random_forest.cc:628] Training of tree 61/1000 (tree index:63) done accuracy:0.8104 logloss:0.55782
[INFO random_forest.cc:628] Training of tree 71/1000 (tree index:69) done accuracy:0.81 logloss:0.544938
[INFO random_forest.cc:628] Training of tree 81/1000 (tree index:80) done accuracy:0.814 logloss:0.532167
[INFO random_forest.cc:628] Training of tree 91/1000 (tree index:89) done accuracy:0.8144 logloss:0.530892
[INFO random_forest.cc:628] Training of tree 101/1000 (tree index:100) done accuracy:0.814 logloss:0.516588
[INFO random_forest.cc:628] Training of tree 111/1000 (tree index:108) done accuracy:0.8128 logloss:0.490739
[INFO random_forest.cc:628] Training of tree 121/1000 (tree index:118) done accuracy:0.8124 logloss:0.490544
[INFO random_forest.cc:628] Training of tree 131/1000 (tree index:134) done accuracy:0.8112 logloss:0.451653
[INFO random_forest.cc:628] Training of tree 141/1000 (tree index:140) done accuracy:0.8136 logloss:0.437757
[INFO random_forest.cc:628] Training of tree 151/1000 (tree index:150) done accuracy:0.8144 logloss:0.424328
[INFO random_forest.cc:628] Training of tree 161/1000 (tree index:159) done accuracy:0.8132 logloss:0.42426
[INFO random_forest.cc:628] Training of tree 171/1000 (tree index:168) done accuracy:0.814 logloss:0.411061
[INFO random_forest.cc:628] Training of tree 181/1000 (tree index:184) done accuracy:0.8136 logloss:0.411324
[INFO random_forest.cc:628] Training of tree 191/1000 (tree index:190) done accuracy:0.8148 logloss:0.410002
[INFO random_forest.cc:628] Training of tree 201/1000 (tree index:200) done accuracy:0.8144 logloss:0.409526
[INFO random_forest.cc:628] Training of tree 211/1000 (tree index:208) done accuracy:0.814 logloss:0.40944
[INFO random_forest.cc:628] Training of tree 221/1000 (tree index:218) done accuracy:0.8152 logloss:0.409039
[INFO random_forest.cc:628] Training of tree 231/1000 (tree index:234) done accuracy:0.8144 logloss:0.409254
[INFO random_forest.cc:628] Training of tree 241/1000 (tree index:242) done accuracy:0.8144 logloss:0.40879
[INFO random_forest.cc:628] Training of tree 251/1000 (tree index:251) done accuracy:0.8152 logloss:0.395703
[INFO random_forest.cc:628] Training of tree 261/1000 (tree index:259) done accuracy:0.8168 logloss:0.395747
[INFO random_forest.cc:628] Training of tree 271/1000 (tree index:268) done accuracy:0.814 logloss:0.394959
[INFO random_forest.cc:628] Training of tree 281/1000 (tree index:283) done accuracy:0.8148 logloss:0.395202
[INFO random_forest.cc:628] Training of tree 291/1000 (tree index:292) done accuracy:0.8136 logloss:0.395536
[INFO random_forest.cc:628] Training of tree 301/1000 (tree index:300) done accuracy:0.8128 logloss:0.39472
[INFO random_forest.cc:628] Training of tree 311/1000 (tree index:308) done accuracy:0.8124 logloss:0.394763
[INFO random_forest.cc:628] Training of tree 321/1000 (tree index:318) done accuracy:0.8132 logloss:0.394732
[INFO random_forest.cc:628] Training of tree 331/1000 (tree index:334) done accuracy:0.8136 logloss:0.394822
[INFO random_forest.cc:628] Training of tree 341/1000 (tree index:343) done accuracy:0.812 logloss:0.395051
[INFO random_forest.cc:628] Training of tree 351/1000 (tree index:350) done accuracy:0.8132 logloss:0.39492
[INFO random_forest.cc:628] Training of tree 361/1000 (tree index:358) done accuracy:0.8132 logloss:0.395054
[INFO random_forest.cc:628] Training of tree 371/1000 (tree index:368) done accuracy:0.812 logloss:0.395588
[INFO random_forest.cc:628] Training of tree 381/1000 (tree index:384) done accuracy:0.8104 logloss:0.395576
[INFO random_forest.cc:628] Training of tree 391/1000 (tree index:390) done accuracy:0.8132 logloss:0.395713
[INFO random_forest.cc:628] Training of tree 401/1000 (tree index:400) done accuracy:0.8088 logloss:0.383693
[INFO random_forest.cc:628] Training of tree 411/1000 (tree index:408) done accuracy:0.8088 logloss:0.383575
[INFO random_forest.cc:628] Training of tree 421/1000 (tree index:417) done accuracy:0.8096 logloss:0.383934
[INFO random_forest.cc:628] Training of tree 431/1000 (tree index:434) done accuracy:0.81 logloss:0.384001
[INFO random_forest.cc:628] Training of tree 441/1000 (tree index:442) done accuracy:0.808 logloss:0.384118
[INFO random_forest.cc:628] Training of tree 451/1000 (tree index:450) done accuracy:0.8096 logloss:0.384076
[INFO random_forest.cc:628] Training of tree 461/1000 (tree index:458) done accuracy:0.8104 logloss:0.383208
[INFO random_forest.cc:628] Training of tree 471/1000 (tree index:468) done accuracy:0.812 logloss:0.383298
[INFO random_forest.cc:628] Training of tree 481/1000 (tree index:482) done accuracy:0.81 logloss:0.38358
[INFO random_forest.cc:628] Training of tree 491/1000 (tree index:492) done accuracy:0.812 logloss:0.383453
[INFO random_forest.cc:628] Training of tree 501/1000 (tree index:500) done accuracy:0.8128 logloss:0.38317
[INFO random_forest.cc:628] Training of tree 511/1000 (tree index:508) done accuracy:0.812 logloss:0.383369
[INFO random_forest.cc:628] Training of tree 521/1000 (tree index:518) done accuracy:0.8132 logloss:0.383461
[INFO random_forest.cc:628] Training of tree 531/1000 (tree index:532) done accuracy:0.8124 logloss:0.38342
[INFO random_forest.cc:628] Training of tree 541/1000 (tree index:542) done accuracy:0.8128 logloss:0.383376
[INFO random_forest.cc:628] Training of tree 551/1000 (tree index:550) done accuracy:0.8128 logloss:0.383663
[INFO random_forest.cc:628] Training of tree 561/1000 (tree index:558) done accuracy:0.812 logloss:0.383574
[INFO random_forest.cc:628] Training of tree 571/1000 (tree index:568) done accuracy:0.8116 logloss:0.383529
[INFO random_forest.cc:628] Training of tree 581/1000 (tree index:580) done accuracy:0.8128 logloss:0.383624
[INFO random_forest.cc:628] Training of tree 591/1000 (tree index:592) done accuracy:0.814 logloss:0.383599
[INFO random_forest.cc:628] Training of tree 601/1000 (tree index:601) done accuracy:0.8148 logloss:0.383524
[INFO random_forest.cc:628] Training of tree 611/1000 (tree index:608) done accuracy:0.8156 logloss:0.383555
[INFO random_forest.cc:628] Training of tree 621/1000 (tree index:619) done accuracy:0.8132 logloss:0.382847
[INFO random_forest.cc:628] Training of tree 631/1000 (tree index:632) done accuracy:0.8124 logloss:0.382872
[INFO random_forest.cc:628] Training of tree 641/1000 (tree index:641) done accuracy:0.8144 logloss:0.382728
[INFO random_forest.cc:628] Training of tree 651/1000 (tree index:648) done accuracy:0.8132 logloss:0.382554
[INFO random_forest.cc:628] Training of tree 661/1000 (tree index:658) done accuracy:0.8128 logloss:0.382705
[INFO random_forest.cc:628] Training of tree 671/1000 (tree index:670) done accuracy:0.8136 logloss:0.38288
[INFO random_forest.cc:628] Training of tree 681/1000 (tree index:682) done accuracy:0.8152 logloss:0.383007
[INFO random_forest.cc:628] Training of tree 691/1000 (tree index:690) done accuracy:0.8144 logloss:0.382971
[INFO random_forest.cc:628] Training of tree 701/1000 (tree index:698) done accuracy:0.8152 logloss:0.382869
[INFO random_forest.cc:628] Training of tree 711/1000 (tree index:708) done accuracy:0.8152 logloss:0.382792
[INFO random_forest.cc:628] Training of tree 721/1000 (tree index:722) done accuracy:0.8136 logloss:0.38274
[INFO random_forest.cc:628] Training of tree 731/1000 (tree index:732) done accuracy:0.8144 logloss:0.38268
[INFO random_forest.cc:628] Training of tree 741/1000 (tree index:740) done accuracy:0.814 logloss:0.382835
[INFO random_forest.cc:628] Training of tree 751/1000 (tree index:751) done accuracy:0.8152 logloss:0.38297
[INFO random_forest.cc:628] Training of tree 761/1000 (tree index:758) done accuracy:0.8152 logloss:0.382917
[INFO random_forest.cc:628] Training of tree 771/1000 (tree index:770) done accuracy:0.8156 logloss:0.370596
[INFO random_forest.cc:628] Training of tree 781/1000 (tree index:782) done accuracy:0.816 logloss:0.370687
[INFO random_forest.cc:628] Training of tree 791/1000 (tree index:789) done accuracy:0.8164 logloss:0.37068
[INFO random_forest.cc:628] Training of tree 801/1000 (tree index:798) done accuracy:0.8172 logloss:0.370535
[INFO random_forest.cc:628] Training of tree 811/1000 (tree index:809) done accuracy:0.816 logloss:0.370674
[INFO random_forest.cc:628] Training of tree 821/1000 (tree index:821) done accuracy:0.816 logloss:0.370929
[INFO random_forest.cc:628] Training of tree 831/1000 (tree index:829) done accuracy:0.8148 logloss:0.370904
[INFO random_forest.cc:628] Training of tree 841/1000 (tree index:841) done accuracy:0.8164 logloss:0.371016
[INFO random_forest.cc:628] Training of tree 851/1000 (tree index:849) done accuracy:0.8168 logloss:0.370914
[INFO random_forest.cc:628] Training of tree 861/1000 (tree index:860) done accuracy:0.8164 logloss:0.371043
[INFO random_forest.cc:628] Training of tree 871/1000 (tree index:871) done accuracy:0.8168 logloss:0.371094
[INFO random_forest.cc:628] Training of tree 881/1000 (tree index:878) done accuracy:0.8152 logloss:0.371054
[INFO random_forest.cc:628] Training of tree 891/1000 (tree index:888) done accuracy:0.8156 logloss:0.370908
[INFO random_forest.cc:628] Training of tree 901/1000 (tree index:900) done accuracy:0.8156 logloss:0.370831
[INFO random_forest.cc:628] Training of tree 911/1000 (tree index:910) done accuracy:0.8152 logloss:0.370775
[INFO random_forest.cc:628] Training of tree 921/1000 (tree index:922) done accuracy:0.814 logloss:0.370804
[INFO random_forest.cc:628] Training of tree 931/1000 (tree index:929) done accuracy:0.8148 logloss:0.370495
[INFO random_forest.cc:628] Training of tree 941/1000 (tree index:941) done accuracy:0.816 logloss:0.370443
[INFO random_forest.cc:628] Training of tree 951/1000 (tree index:948) done accuracy:0.8156 logloss:0.370486
[INFO random_forest.cc:628] Training of tree 961/1000 (tree index:960) done accuracy:0.8152 logloss:0.370519
[INFO random_forest.cc:628] Training of tree 971/1000 (tree index:971) done accuracy:0.8144 logloss:0.370543
[INFO random_forest.cc:628] Training of tree 981/1000 (tree index:983) done accuracy:0.8144 logloss:0.370629
[INFO random_forest.cc:628] Training of tree 991/1000 (tree index:991) done accuracy:0.814 logloss:0.370625
[INFO random_forest.cc:628] Training of tree 1000/1000 (tree index:998) done accuracy:0.8144 logloss:0.370667
[INFO random_forest.cc:696] Final OOB metrics: accuracy:0.8144 logloss:0.370667
[INFO kernel.cc:828] Export model in log directory: /tmp/tmp9izglk4r
[INFO kernel.cc:836] Save model in resources
[INFO kernel.cc:988] Loading model from path
40/40 [==============================] - 6s 66ms/step
[INFO decision_forest.cc:590] Model loaded with 1000 root(s), 324508 node(s), and 10 input feature(s).
[INFO abstract_model.cc:993] Engine "RandomForestOptPred" built
[INFO kernel.cc:848] Use fast generic engine
24/40 [=================>............] - ETA: 0s
[INFO kernel.cc:736] Start Yggdrasil model training
[INFO kernel.cc:737] Collect training examples
[INFO kernel.cc:392] Number of batches: 40
[INFO kernel.cc:393] Number of examples: 2500
[INFO kernel.cc:759] Dataset:
Number of records: 2500
Number of columns: 11
Number of columns by type:
NUMERICAL: 10 (90.9091%)
CATEGORICAL: 1 (9.09091%)
Columns:
NUMERICAL: 10 (90.9091%)
0: "data:0.0" NUMERICAL mean:0.356465 min:0 max:2.37352 sd:0.451418
1: "data:0.1" NUMERICAL mean:0.392088 min:0 max:2.3411 sd:0.470499
2: "data:0.2" NUMERICAL mean:0.382386 min:0 max:2.11809 sd:0.483672
3: "data:0.3" NUMERICAL mean:0.290395 min:0 max:2.27481 sd:0.400102
4: "data:0.4" NUMERICAL mean:0.210684 min:0 max:1.35897 sd:0.281379
5: "data:0.5" NUMERICAL mean:0.4008 min:0 max:2.06561 sd:0.453018
6: "data:0.6" NUMERICAL mean:0.289166 min:0 max:2.0263 sd:0.407337
7: "data:0.7" NUMERICAL mean:0.277971 min:0 max:1.77561 sd:0.363215
8: "data:0.8" NUMERICAL mean:0.41254 min:0 max:2.79804 sd:0.553333
9: "data:0.9" NUMERICAL mean:0.197082 min:0 max:1.60773 sd:0.298194
CATEGORICAL: 1 (9.09091%)
10: "__LABEL" CATEGORICAL integerized vocab-size:3 no-ood-item
Terminology:
nas: Number of non-available (i.e. missing) values.
ood: Out of dictionary.
manually-defined: Attribute which type is manually defined by the user i.e. the type was not automatically inferred.
tokenized: The attribute value is obtained through tokenization.
has-dict: The attribute is attached to a string dictionary e.g. a categorical attribute stored as a string.
vocab-size: Number of unique values.
[INFO kernel.cc:762] Configure learner
[INFO kernel.cc:787] Training config:
learner: "RANDOM_FOREST"
features: "data:0\\.0"
features: "data:0\\.1"
features: "data:0\\.2"
features: "data:0\\.3"
features: "data:0\\.4"
features: "data:0\\.5"
features: "data:0\\.6"
features: "data:0\\.7"
features: "data:0\\.8"
features: "data:0\\.9"
label: "__LABEL"
task: CLASSIFICATION
random_seed: 4567
[yggdrasil_decision_forests.model.random_forest.proto.random_forest_config] {
num_trees: 1000
decision_tree {
max_depth: 16
min_examples: 5
in_split_min_examples_check: true
missing_value_policy: GLOBAL_IMPUTATION
allow_na_conditions: false
categorical_set_greedy_forward {
sampling: 0.1
max_num_items: -1
min_item_frequency: 1
}
growing_strategy_local {
}
categorical {
cart {
}
}
num_candidate_attributes_ratio: -1
axis_aligned_split {
}
internal {
sorting_strategy: PRESORTED
}
}
winner_take_all_inference: true
compute_oob_performances: true
compute_oob_variable_importances: false
adapt_bootstrap_size_ratio_for_maximum_training_duration: false
}
[INFO kernel.cc:790] Deployment config:
num_threads: 6
[INFO kernel.cc:817] Train model
[INFO random_forest.cc:315] Training random forest on 2500 example(s) and 10 feature(s).
[INFO random_forest.cc:628] Training of tree 1/1000 (tree index:1) done accuracy:0.783262 logloss:7.81204
[INFO random_forest.cc:628] Training of tree 11/1000 (tree index:9) done accuracy:0.801127 logloss:2.73187
[INFO random_forest.cc:628] Training of tree 21/1000 (tree index:19) done accuracy:0.811449 logloss:1.1286
[INFO random_forest.cc:628] Training of tree 31/1000 (tree index:32) done accuracy:0.8132 logloss:0.910787
[INFO random_forest.cc:628] Training of tree 41/1000 (tree index:42) done accuracy:0.812 logloss:0.745694
[INFO random_forest.cc:628] Training of tree 51/1000 (tree index:48) done accuracy:0.8144 logloss:0.690226
[INFO random_forest.cc:628] Training of tree 61/1000 (tree index:59) done accuracy:0.8136 logloss:0.659137
[INFO random_forest.cc:628] Training of tree 71/1000 (tree index:72) done accuracy:0.8176 logloss:0.577357
[INFO random_forest.cc:628] Training of tree 81/1000 (tree index:79) done accuracy:0.814 logloss:0.565115
[INFO random_forest.cc:628] Training of tree 91/1000 (tree index:91) done accuracy:0.8156 logloss:0.56459
[INFO random_forest.cc:628] Training of tree 101/1000 (tree index:99) done accuracy:0.8148 logloss:0.564104
[INFO random_forest.cc:628] Training of tree 111/1000 (tree index:109) done accuracy:0.8172 logloss:0.537417
[INFO random_forest.cc:628] Training of tree 121/1000 (tree index:120) done accuracy:0.8156 logloss:0.524543
[INFO random_forest.cc:628] Training of tree 131/1000 (tree index:132) done accuracy:0.8152 logloss:0.511111
[INFO random_forest.cc:628] Training of tree 141/1000 (tree index:141) done accuracy:0.816 logloss:0.498209
[INFO random_forest.cc:628] Training of tree 151/1000 (tree index:150) done accuracy:0.8192 logloss:0.485477
[INFO random_forest.cc:628] Training of tree 161/1000 (tree index:160) done accuracy:0.8196 logloss:0.472341
[INFO random_forest.cc:628] Training of tree 171/1000 (tree index:171) done accuracy:0.818 logloss:0.459903
[INFO random_forest.cc:628] Training of tree 181/1000 (tree index:182) done accuracy:0.8172 logloss:0.459812
[INFO random_forest.cc:628] Training of tree 191/1000 (tree index:190) done accuracy:0.8192 logloss:0.459588
[INFO random_forest.cc:628] Training of tree 201/1000 (tree index:199) done accuracy:0.818 logloss:0.459855
[INFO random_forest.cc:628] Training of tree 211/1000 (tree index:209) done accuracy:0.8176 logloss:0.459088
[INFO random_forest.cc:628] Training of tree 221/1000 (tree index:221) done accuracy:0.8168 logloss:0.43377
[INFO random_forest.cc:628] Training of tree 231/1000 (tree index:233) done accuracy:0.8196 logloss:0.433567
[INFO random_forest.cc:628] Training of tree 241/1000 (tree index:241) done accuracy:0.8208 logloss:0.434371
[INFO random_forest.cc:628] Training of tree 251/1000 (tree index:250) done accuracy:0.8192 logloss:0.434301
[INFO random_forest.cc:628] Training of tree 261/1000 (tree index:260) done accuracy:0.8172 logloss:0.43402
[INFO random_forest.cc:628] Training of tree 271/1000 (tree index:271) done accuracy:0.818 logloss:0.433583
[INFO random_forest.cc:628] Training of tree 281/1000 (tree index:283) done accuracy:0.8184 logloss:0.420657
[INFO random_forest.cc:628] Training of tree 291/1000 (tree index:291) done accuracy:0.8168 logloss:0.420481
[INFO random_forest.cc:628] Training of tree 301/1000 (tree index:299) done accuracy:0.82 logloss:0.419901
[INFO random_forest.cc:628] Training of tree 311/1000 (tree index:312) done accuracy:0.8188 logloss:0.419881
[INFO random_forest.cc:628] Training of tree 321/1000 (tree index:319) done accuracy:0.8172 logloss:0.419582
[INFO random_forest.cc:628] Training of tree 331/1000 (tree index:332) done accuracy:0.8176 logloss:0.419608
[INFO random_forest.cc:628] Training of tree 341/1000 (tree index:341) done accuracy:0.816 logloss:0.419608
[INFO random_forest.cc:628] Training of tree 351/1000 (tree index:352) done accuracy:0.8152 logloss:0.419729
[INFO random_forest.cc:628] Training of tree 361/1000 (tree index:361) done accuracy:0.8152 logloss:0.419264
[INFO random_forest.cc:628] Training of tree 371/1000 (tree index:369) done accuracy:0.8148 logloss:0.418932
[INFO random_forest.cc:628] Training of tree 381/1000 (tree index:379) done accuracy:0.8156 logloss:0.419148
[INFO random_forest.cc:628] Training of tree 391/1000 (tree index:391) done accuracy:0.8164 logloss:0.419344
[INFO random_forest.cc:628] Training of tree 401/1000 (tree index:398) done accuracy:0.8156 logloss:0.419051
[INFO random_forest.cc:628] Training of tree 411/1000 (tree index:408) done accuracy:0.8168 logloss:0.406486
[INFO random_forest.cc:628] Training of tree 421/1000 (tree index:420) done accuracy:0.8168 logloss:0.406477
[INFO random_forest.cc:628] Training of tree 431/1000 (tree index:430) done accuracy:0.816 logloss:0.406362
[INFO random_forest.cc:628] Training of tree 441/1000 (tree index:440) done accuracy:0.8172 logloss:0.406377
[INFO random_forest.cc:628] Training of tree 451/1000 (tree index:448) done accuracy:0.8176 logloss:0.406083
[INFO random_forest.cc:628] Training of tree 461/1000 (tree index:458) done accuracy:0.8172 logloss:0.406205
[INFO random_forest.cc:628] Training of tree 471/1000 (tree index:474) done accuracy:0.8168 logloss:0.406437
[INFO random_forest.cc:628] Training of tree 481/1000 (tree index:482) done accuracy:0.8184 logloss:0.406287
[INFO random_forest.cc:628] Training of tree 491/1000 (tree index:490) done accuracy:0.8172 logloss:0.40588
[INFO random_forest.cc:628] Training of tree 501/1000 (tree index:498) done accuracy:0.816 logloss:0.406036
[INFO random_forest.cc:628] Training of tree 511/1000 (tree index:508) done accuracy:0.8164 logloss:0.406053
[INFO random_forest.cc:628] Training of tree 521/1000 (tree index:524) done accuracy:0.8168 logloss:0.405945
[INFO random_forest.cc:628] Training of tree 531/1000 (tree index:530) done accuracy:0.816 logloss:0.405778
[INFO random_forest.cc:628] Training of tree 541/1000 (tree index:540) done accuracy:0.8156 logloss:0.405737
[INFO random_forest.cc:628] Training of tree 551/1000 (tree index:552) done accuracy:0.8156 logloss:0.406028
[INFO random_forest.cc:628] Training of tree 561/1000 (tree index:559) done accuracy:0.8164 logloss:0.406081
[INFO random_forest.cc:628] Training of tree 571/1000 (tree index:569) done accuracy:0.8152 logloss:0.405734
[INFO random_forest.cc:628] Training of tree 581/1000 (tree index:579) done accuracy:0.8172 logloss:0.393451
[INFO random_forest.cc:628] Training of tree 591/1000 (tree index:591) done accuracy:0.816 logloss:0.393428
[INFO random_forest.cc:628] Training of tree 601/1000 (tree index:603) done accuracy:0.8156 logloss:0.393545
[INFO random_forest.cc:628] Training of tree 611/1000 (tree index:609) done accuracy:0.8156 logloss:0.3934
[INFO random_forest.cc:628] Training of tree 621/1000 (tree index:620) done accuracy:0.8148 logloss:0.393539
[INFO random_forest.cc:628] Training of tree 631/1000 (tree index:629) done accuracy:0.8156 logloss:0.393731
[INFO random_forest.cc:628] Training of tree 641/1000 (tree index:641) done accuracy:0.8164 logloss:0.39383
[INFO random_forest.cc:628] Training of tree 651/1000 (tree index:649) done accuracy:0.8152 logloss:0.393724
[INFO random_forest.cc:628] Training of tree 661/1000 (tree index:659) done accuracy:0.8152 logloss:0.393764
[INFO random_forest.cc:628] Training of tree 671/1000 (tree index:670) done accuracy:0.816 logloss:0.393834
[INFO random_forest.cc:628] Training of tree 681/1000 (tree index:680) done accuracy:0.8156 logloss:0.393894
[INFO random_forest.cc:628] Training of tree 691/1000 (tree index:689) done accuracy:0.8152 logloss:0.393746
[INFO random_forest.cc:628] Training of tree 701/1000 (tree index:698) done accuracy:0.814 logloss:0.393743
[INFO random_forest.cc:628] Training of tree 711/1000 (tree index:708) done accuracy:0.8152 logloss:0.393294
[INFO random_forest.cc:628] Training of tree 721/1000 (tree index:721) done accuracy:0.816 logloss:0.393451
[INFO random_forest.cc:628] Training of tree 731/1000 (tree index:733) done accuracy:0.8164 logloss:0.393486
[INFO random_forest.cc:628] Training of tree 741/1000 (tree index:739) done accuracy:0.8156 logloss:0.393553
[INFO random_forest.cc:628] Training of tree 751/1000 (tree index:751) done accuracy:0.816 logloss:0.393731
[INFO random_forest.cc:628] Training of tree 761/1000 (tree index:758) done accuracy:0.8172 logloss:0.393635
[INFO random_forest.cc:628] Training of tree 771/1000 (tree index:769) done accuracy:0.8164 logloss:0.393584
[INFO random_forest.cc:628] Training of tree 781/1000 (tree index:779) done accuracy:0.8184 logloss:0.393728
[INFO random_forest.cc:628] Training of tree 791/1000 (tree index:789) done accuracy:0.8192 logloss:0.393858
[INFO random_forest.cc:628] Training of tree 801/1000 (tree index:800) done accuracy:0.8184 logloss:0.381756
[INFO random_forest.cc:628] Training of tree 811/1000 (tree index:813) done accuracy:0.82 logloss:0.38174
[INFO random_forest.cc:628] Training of tree 821/1000 (tree index:819) done accuracy:0.8196 logloss:0.381865
[INFO random_forest.cc:628] Training of tree 831/1000 (tree index:829) done accuracy:0.8172 logloss:0.381929
[INFO random_forest.cc:628] Training of tree 841/1000 (tree index:838) done accuracy:0.8164 logloss:0.382007
[INFO random_forest.cc:628] Training of tree 851/1000 (tree index:850) done accuracy:0.8172 logloss:0.382099
[INFO random_forest.cc:628] Training of tree 861/1000 (tree index:863) done accuracy:0.8172 logloss:0.381937
[INFO random_forest.cc:628] Training of tree 871/1000 (tree index:869) done accuracy:0.8168 logloss:0.382131
[INFO random_forest.cc:628] Training of tree 881/1000 (tree index:879) done accuracy:0.8188 logloss:0.381963
[INFO random_forest.cc:628] Training of tree 891/1000 (tree index:889) done accuracy:0.8192 logloss:0.382052
[INFO random_forest.cc:628] Training of tree 901/1000 (tree index:901) done accuracy:0.8184 logloss:0.382174
[INFO random_forest.cc:628] Training of tree 911/1000 (tree index:913) done accuracy:0.8192 logloss:0.382273
[INFO random_forest.cc:628] Training of tree 921/1000 (tree index:919) done accuracy:0.82 logloss:0.382407
[INFO random_forest.cc:628] Training of tree 931/1000 (tree index:929) done accuracy:0.8216 logloss:0.382277
[INFO random_forest.cc:628] Training of tree 941/1000 (tree index:939) done accuracy:0.8204 logloss:0.382434
[INFO random_forest.cc:628] Training of tree 951/1000 (tree index:951) done accuracy:0.8192 logloss:0.382444
[INFO random_forest.cc:628] Training of tree 961/1000 (tree index:959) done accuracy:0.8192 logloss:0.382497
[INFO random_forest.cc:628] Training of tree 971/1000 (tree index:969) done accuracy:0.8188 logloss:0.382592
[INFO random_forest.cc:628] Training of tree 981/1000 (tree index:979) done accuracy:0.8192 logloss:0.382657
[INFO random_forest.cc:628] Training of tree 991/1000 (tree index:989) done accuracy:0.8188 logloss:0.382671
[INFO random_forest.cc:628] Training of tree 1000/1000 (tree index:997) done accuracy:0.8192 logloss:0.38269
[INFO random_forest.cc:696] Final OOB metrics: accuracy:0.8192 logloss:0.38269
[INFO kernel.cc:828] Export model in log directory: /tmp/tmp0r9hhl7d
[INFO kernel.cc:836] Save model in resources
[INFO kernel.cc:988] Loading model from path
40/40 [==============================] - 3s 64ms/step
[INFO decision_forest.cc:590] Model loaded with 1000 root(s), 324942 node(s), and 10 input feature(s).
[INFO kernel.cc:848] Use fast generic engine
CPU times: user 21.5 s, sys: 755 ms, total: 22.2 s
Wall time: 10.5 s
<keras.callbacks.History at 0x7f6b7874c4d0>
E vamos avaliar as Florestas de Decisão individualmente.
model_3.compile(["accuracy"])
model_4.compile(["accuracy"])
evaluation_df3_only = model_3.evaluate(
test_dataset_with_preprocessing, return_dict=True)
evaluation_df4_only = model_4.evaluate(
test_dataset_with_preprocessing, return_dict=True)
print("Accuracy (DF #3 only): ", evaluation_df3_only["accuracy"])
print("Accuracy (DF #4 only): ", evaluation_df4_only["accuracy"])
157/157 [==============================] - 2s 8ms/step - loss: 0.0000e+00 - accuracy: 0.8218 157/157 [==============================] - 1s 8ms/step - loss: 0.0000e+00 - accuracy: 0.8223 Accuracy (DF #3 only): 0.8217999935150146 Accuracy (DF #4 only): 0.8223000168800354
Vamos avaliar toda a composição do modelo:
ensemble_nn_and_df.compile(
loss=tf.keras.losses.BinaryCrossentropy(), metrics=["accuracy"])
evaluation_nn_and_df = ensemble_nn_and_df.evaluate(
test_dataset, return_dict=True)
print("Accuracy (2xNN and 2xDF): ", evaluation_nn_and_df["accuracy"])
print("Loss (2xNN and 2xDF): ", evaluation_nn_and_df["loss"])
157/157 [==============================] - 2s 8ms/step - loss: 0.3707 - accuracy: 0.8236 Accuracy (2xNN and 2xDF): 0.8235999941825867 Loss (2xNN and 2xDF): 0.3706760108470917
Para terminar, vamos ajustar a camada de rede neural um pouco mais. Observe que não ajustamos a incorporação pré-treinada, pois os modelos DF dependem dela (a menos que também os retreinemos depois).
Em resumo, você tem:
print(f"Accuracy (NN #1 and #2 only):\t{evaluation_nn_only['accuracy']:.6f}")
print(f"Accuracy (DF #3 only):\t\t{evaluation_df3_only['accuracy']:.6f}")
print(f"Accuracy (DF #4 only):\t\t{evaluation_df4_only['accuracy']:.6f}")
print("----------------------------------------")
print(f"Accuracy (2xNN and 2xDF):\t{evaluation_nn_and_df['accuracy']:.6f}")
def delta_percent(src_eval, key):
src_acc = src_eval["accuracy"]
final_acc = evaluation_nn_and_df["accuracy"]
increase = final_acc - src_acc
print(f"\t\t\t\t {increase:+.6f} over {key}")
delta_percent(evaluation_nn_only, "NN #1 and #2 only")
delta_percent(evaluation_df3_only, "DF #3 only")
delta_percent(evaluation_df4_only, "DF #4 only")
Accuracy (NN #1 and #2 only): 0.820300
Accuracy (DF #3 only): 0.821800
Accuracy (DF #4 only): 0.822300
----------------------------------------
Accuracy (2xNN and 2xDF): 0.823600
+0.003300 over NN #1 and #2 only
+0.001800 over DF #3 only
+0.001300 over DF #4 only
Aqui, você pode ver que o modelo composto tem um desempenho melhor do que suas partes individuais. É por isso que os conjuntos funcionam tão bem.
Qual é o próximo?
Neste exemplo, você viu como combinar florestas de decisão com redes neurais. Uma etapa extra seria treinar ainda mais a rede neural e as florestas de decisão juntas.
Além disso, para fins de clareza, as florestas de decisão receberam apenas os insumos pré-processados. No entanto, as florestas de decisão geralmente são grandes e estão consumindo dados brutos. O modelo seria melhorado também alimentando os recursos brutos para os modelos de floresta de decisão.
Neste exemplo, o modelo final é a média das previsões dos modelos individuais. Essa solução funciona bem se todo o modelo tiver mais desempenho ou menos com o mesmo. No entanto, se um dos submodelos for muito bom, agregá-lo a outros modelos pode ser prejudicial (ou vice-versa; por exemplo, tente reduzir o número de exemplos de 1k e veja como isso prejudica muito as redes neurais; ou permitir a SPARSE_OBLIQUE separação no segundo modelo aleatório Floresta).