
|
|
|
 View on GitHub View on GitHub
|
|
|
Introduction
Welcome to the model composition tutorial for TensorFlow Decision Forests (TF-DF). This notebook shows you how to compose multiple decision forest and neural network models together using a common preprocessing layer and the Keras functional API.
You might want to compose models together to improve predictive performance (ensembling), to get the best of different modeling technologies (heterogeneous model ensembling), to train different part of the model on different datasets (e.g. pre-training), or to create a stacked model (e.g. a model operates on the predictions of another model).
This tutorial covers an advanced use case of model composition using the Functional API. You can find examples for simpler scenarios of model composition in the "feature preprocessing" section of this tutorial and in the "using a pretrained text embedding" section of this tutorial.
Here is the structure of the model you'll build:
!pip install graphviz -U --quiet
from graphviz import Source
Source("""
digraph G {
raw_data [label="Input features"];
preprocess_data [label="Learnable NN pre-processing", shape=rect];
raw_data -> preprocess_data
subgraph cluster_0 {
color=grey;
a1[label="NN layer", shape=rect];
b1[label="NN layer", shape=rect];
a1 -> b1;
label = "Model #1";
}
subgraph cluster_1 {
color=grey;
a2[label="NN layer", shape=rect];
b2[label="NN layer", shape=rect];
a2 -> b2;
label = "Model #2";
}
subgraph cluster_2 {
color=grey;
a3[label="Decision Forest", shape=rect];
label = "Model #3";
}
subgraph cluster_3 {
color=grey;
a4[label="Decision Forest", shape=rect];
label = "Model #4";
}
preprocess_data -> a1;
preprocess_data -> a2;
preprocess_data -> a3;
preprocess_data -> a4;
b1 -> aggr;
b2 -> aggr;
a3 -> aggr;
a4 -> aggr;
aggr [label="Aggregation (mean)", shape=rect]
aggr -> predictions
}
""")

Your composed model has three stages:
- The first stage is a preprocessing layer composed of a neural network and common to all the models in the next stage. In practice, such a preprocessing layer could either be a pre-trained embedding to fine-tune, or a randomly initialized neural network.
- The second stage is an ensemble of two decision forest and two neural network models.
- The last stage averages the predictions of the models in the second stage. It does not contain any learnable weights.
The neural networks are trained using the backpropagation algorithm and gradient descent. This algorithm has two important properties: (1) The layer of neural network can be trained if its receives a loss gradient (more precisely, the gradient of the loss according to the layer's output), and (2) the algorithm "transmits" the loss gradient from the layer's output to the layer's input (this is the "chain rule"). For these two reasons, Backpropagation can train together multiple layers of neural networks stacked on top of each other.
In this example, the decision forests are trained with the Random Forest (RF) algorithm. Unlike Backpropagation, the training of RF does not "transmit" the loss gradient to from its output to its input. For this reasons, the classical RF algorithm cannot be used to train or fine-tune a neural network underneath. In other words, the "decision forest" stages cannot be used to train the "Learnable NN pre-processing block".
- Train the preprocessing and neural networks stage.
- Train the decision forest stages.
Install TensorFlow Decision Forests
Install TF-DF by running the following cell.
pip install tensorflow_decision_forests -U --quietWurlitzer is needed to display
the detailed training logs in Colabs (when using verbose=2 in the model constructor).
pip install wurlitzer -U --quietImport libraries
import os
# Keep using Keras 2
os.environ['TF_USE_LEGACY_KERAS'] = '1'
import tensorflow_decision_forests as tfdf
import numpy as np
import pandas as pd
import tensorflow as tf
import tf_keras
import math
import matplotlib.pyplot as plt
2026-01-12 15:04:37.279648: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:467] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered WARNING: All log messages before absl::InitializeLog() is called are written to STDERR E0000 00:00:1768230277.301853 180025 cuda_dnn.cc:8579] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered E0000 00:00:1768230277.309311 180025 cuda_blas.cc:1407] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered W0000 00:00:1768230277.327629 180025 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once. W0000 00:00:1768230277.327647 180025 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once. W0000 00:00:1768230277.327650 180025 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once. W0000 00:00:1768230277.327652 180025 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
Dataset
You will use a simple synthetic dataset in this tutorial to make it easier to interpret the final model.
def make_dataset(num_examples, num_features, seed=1234):
np.random.seed(seed)
features = np.random.uniform(-1, 1, size=(num_examples, num_features))
noise = np.random.uniform(size=(num_examples))
left_side = np.sqrt(
np.sum(np.multiply(np.square(features[:, 0:2]), [1, 2]), axis=1))
right_side = features[:, 2] * 0.7 + np.sin(
features[:, 3] * 10) * 0.5 + noise * 0.0 + 0.5
labels = left_side <= right_side
return features, labels.astype(int)
Generate some examples:
make_dataset(num_examples=5, num_features=4)
(array([[-0.6169611 , 0.24421754, -0.12454452, 0.57071717],
[ 0.55995162, -0.45481479, -0.44707149, 0.60374436],
[ 0.91627871, 0.75186527, -0.28436546, 0.00199025],
[ 0.36692587, 0.42540405, -0.25949849, 0.12239237],
[ 0.00616633, -0.9724631 , 0.54565324, 0.76528238]]),
array([0, 0, 0, 1, 0]))
You can also plot them to get an idea of the synthetic pattern:
plot_features, plot_label = make_dataset(num_examples=50000, num_features=4)
plt.rcParams["figure.figsize"] = [8, 8]
common_args = dict(c=plot_label, s=1.0, alpha=0.5)
plt.subplot(2, 2, 1)
plt.scatter(plot_features[:, 0], plot_features[:, 1], **common_args)
plt.subplot(2, 2, 2)
plt.scatter(plot_features[:, 1], plot_features[:, 2], **common_args)
plt.subplot(2, 2, 3)
plt.scatter(plot_features[:, 0], plot_features[:, 2], **common_args)
plt.subplot(2, 2, 4)
plt.scatter(plot_features[:, 0], plot_features[:, 3], **common_args)
<matplotlib.collections.PathCollection at 0x7f8e19d74580>
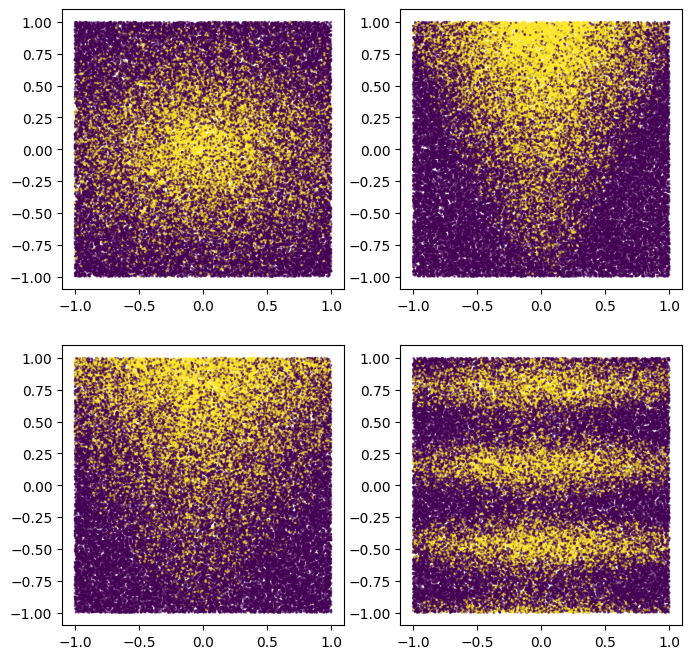
Note that this pattern is smooth and not axis aligned. This will advantage the neural network models. This is because it is easier for a neural network than for a decision tree to have round and non aligned decision boundaries.
On the other hand, we will train the model on a small datasets with 2500 examples. This will advantage the decision forest models. This is because decision forests are much more efficient, using all the available information from the examples (decision forests are "sample efficient").
Our ensemble of neural networks and decision forests will use the best of both worlds.
Let's create a train and test tf.data.Dataset:
def make_tf_dataset(batch_size=64, **args):
features, labels = make_dataset(**args)
return tf.data.Dataset.from_tensor_slices(
(features, labels)).batch(batch_size)
num_features = 10
train_dataset = make_tf_dataset(
num_examples=2500, num_features=num_features, batch_size=100, seed=1234)
test_dataset = make_tf_dataset(
num_examples=10000, num_features=num_features, batch_size=100, seed=5678)
I0000 00:00:1768230286.031846 180025 gpu_device.cc:2019] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 13638 MB memory: -> device: 0, name: Tesla T4, pci bus id: 0000:00:05.0, compute capability: 7.5 I0000 00:00:1768230286.034103 180025 gpu_device.cc:2019] Created device /job:localhost/replica:0/task:0/device:GPU:1 with 13756 MB memory: -> device: 1, name: Tesla T4, pci bus id: 0000:00:06.0, compute capability: 7.5 I0000 00:00:1768230286.036284 180025 gpu_device.cc:2019] Created device /job:localhost/replica:0/task:0/device:GPU:2 with 13756 MB memory: -> device: 2, name: Tesla T4, pci bus id: 0000:00:07.0, compute capability: 7.5 I0000 00:00:1768230286.038455 180025 gpu_device.cc:2019] Created device /job:localhost/replica:0/task:0/device:GPU:3 with 13756 MB memory: -> device: 3, name: Tesla T4, pci bus id: 0000:00:08.0, compute capability: 7.5
Model structure
Define the model structure as follows:
# Input features.
raw_features = tf_keras.layers.Input(shape=(num_features,))
# Stage 1
# =======
# Common learnable pre-processing
preprocessor = tf_keras.layers.Dense(10, activation=tf.nn.relu6)
preprocess_features = preprocessor(raw_features)
# Stage 2
# =======
# Model #1: NN
m1_z1 = tf_keras.layers.Dense(5, activation=tf.nn.relu6)(preprocess_features)
m1_pred = tf_keras.layers.Dense(1, activation=tf.nn.sigmoid)(m1_z1)
# Model #2: NN
m2_z1 = tf_keras.layers.Dense(5, activation=tf.nn.relu6)(preprocess_features)
m2_pred = tf_keras.layers.Dense(1, activation=tf.nn.sigmoid)(m2_z1)
# Model #3: DF
model_3 = tfdf.keras.RandomForestModel(num_trees=1000, random_seed=1234)
m3_pred = model_3(preprocess_features)
# Model #4: DF
model_4 = tfdf.keras.RandomForestModel(
num_trees=1000,
#split_axis="SPARSE_OBLIQUE", # Uncomment this line to increase the quality of this model
random_seed=4567)
m4_pred = model_4(preprocess_features)
# Since TF-DF uses deterministic learning algorithms, you should set the model's
# training seed to different values otherwise both
# `tfdf.keras.RandomForestModel` will be exactly the same.
# Stage 3
# =======
mean_nn_only = tf.reduce_mean(tf.stack([m1_pred, m2_pred], axis=0), axis=0)
mean_nn_and_df = tf.reduce_mean(
tf.stack([m1_pred, m2_pred, m3_pred, m4_pred], axis=0), axis=0)
# Keras Models
# ============
ensemble_nn_only = tf_keras.models.Model(raw_features, mean_nn_only)
ensemble_nn_and_df = tf_keras.models.Model(raw_features, mean_nn_and_df)
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
Use /tmpfs/tmp/tmpmn7x3uo4 as temporary training directory
Warning: The model was called directly (i.e. using `model(data)` instead of using `model.predict(data)`) before being trained. The model will only return zeros until trained. The output shape might change after training Tensor("inputs:0", shape=(None, 10), dtype=float32)
WARNING:absl:The model was called directly (i.e. using `model(data)` instead of using `model.predict(data)`) before being trained. The model will only return zeros until trained. The output shape might change after training Tensor("inputs:0", shape=(None, 10), dtype=float32)
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
Use /tmpfs/tmp/tmpm730xbef as temporary training directory
Warning: The model was called directly (i.e. using `model(data)` instead of using `model.predict(data)`) before being trained. The model will only return zeros until trained. The output shape might change after training Tensor("inputs:0", shape=(None, 10), dtype=float32)
WARNING:absl:The model was called directly (i.e. using `model(data)` instead of using `model.predict(data)`) before being trained. The model will only return zeros until trained. The output shape might change after training Tensor("inputs:0", shape=(None, 10), dtype=float32)
Before you train the model, you can plot it to check if it is similar to the initial diagram.
from keras.utils import plot_model
plot_model(ensemble_nn_and_df, to_file="/tmp/model.png", show_shapes=True)
Model training
First train the preprocessing and two neural network layers using the backpropagation algorithm.
%%time
ensemble_nn_only.compile(
optimizer=tf_keras.optimizers.Adam(),
loss=tf_keras.losses.BinaryCrossentropy(),
metrics=["accuracy"])
ensemble_nn_only.fit(train_dataset, epochs=20, validation_data=test_dataset)
Epoch 1/20 WARNING: All log messages before absl::InitializeLog() is called are written to STDERR I0000 00:00:1768230290.067700 180217 service.cc:152] XLA service 0x7f8c08ef9b10 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices: I0000 00:00:1768230290.067730 180217 service.cc:160] StreamExecutor device (0): Tesla T4, Compute Capability 7.5 I0000 00:00:1768230290.067734 180217 service.cc:160] StreamExecutor device (1): Tesla T4, Compute Capability 7.5 I0000 00:00:1768230290.067737 180217 service.cc:160] StreamExecutor device (2): Tesla T4, Compute Capability 7.5 I0000 00:00:1768230290.067740 180217 service.cc:160] StreamExecutor device (3): Tesla T4, Compute Capability 7.5 I0000 00:00:1768230290.103621 180217 cuda_dnn.cc:529] Loaded cuDNN version 91701 I0000 00:00:1768230290.210677 180217 device_compiler.h:188] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process. 25/25 [==============================] - 4s 25ms/step - loss: 0.6257 - accuracy: 0.7504 - val_loss: 0.6152 - val_accuracy: 0.7393 Epoch 2/20 25/25 [==============================] - 0s 11ms/step - loss: 0.6013 - accuracy: 0.7500 - val_loss: 0.5948 - val_accuracy: 0.7392 Epoch 3/20 25/25 [==============================] - 0s 11ms/step - loss: 0.5814 - accuracy: 0.7500 - val_loss: 0.5782 - val_accuracy: 0.7392 Epoch 4/20 25/25 [==============================] - 0s 11ms/step - loss: 0.5649 - accuracy: 0.7500 - val_loss: 0.5643 - val_accuracy: 0.7392 Epoch 5/20 25/25 [==============================] - 0s 10ms/step - loss: 0.5508 - accuracy: 0.7500 - val_loss: 0.5520 - val_accuracy: 0.7392 Epoch 6/20 25/25 [==============================] - 0s 10ms/step - loss: 0.5377 - accuracy: 0.7500 - val_loss: 0.5399 - val_accuracy: 0.7392 Epoch 7/20 25/25 [==============================] - 0s 10ms/step - loss: 0.5242 - accuracy: 0.7500 - val_loss: 0.5266 - val_accuracy: 0.7392 Epoch 8/20 25/25 [==============================] - 0s 10ms/step - loss: 0.5091 - accuracy: 0.7500 - val_loss: 0.5115 - val_accuracy: 0.7397 Epoch 9/20 25/25 [==============================] - 0s 11ms/step - loss: 0.4929 - accuracy: 0.7536 - val_loss: 0.4957 - val_accuracy: 0.7472 Epoch 10/20 25/25 [==============================] - 0s 10ms/step - loss: 0.4770 - accuracy: 0.7604 - val_loss: 0.4807 - val_accuracy: 0.7577 Epoch 11/20 25/25 [==============================] - 0s 10ms/step - loss: 0.4624 - accuracy: 0.7740 - val_loss: 0.4674 - val_accuracy: 0.7687 Epoch 12/20 25/25 [==============================] - 0s 10ms/step - loss: 0.4499 - accuracy: 0.7868 - val_loss: 0.4566 - val_accuracy: 0.7775 Epoch 13/20 25/25 [==============================] - 0s 10ms/step - loss: 0.4401 - accuracy: 0.7956 - val_loss: 0.4483 - val_accuracy: 0.7827 Epoch 14/20 25/25 [==============================] - 0s 10ms/step - loss: 0.4325 - accuracy: 0.7996 - val_loss: 0.4420 - val_accuracy: 0.7861 Epoch 15/20 25/25 [==============================] - 0s 10ms/step - loss: 0.4266 - accuracy: 0.8024 - val_loss: 0.4371 - val_accuracy: 0.7893 Epoch 16/20 25/25 [==============================] - 0s 10ms/step - loss: 0.4218 - accuracy: 0.8060 - val_loss: 0.4329 - val_accuracy: 0.7933 Epoch 17/20 25/25 [==============================] - 0s 10ms/step - loss: 0.4176 - accuracy: 0.8056 - val_loss: 0.4291 - val_accuracy: 0.7962 Epoch 18/20 25/25 [==============================] - 0s 10ms/step - loss: 0.4137 - accuracy: 0.8052 - val_loss: 0.4254 - val_accuracy: 0.7985 Epoch 19/20 25/25 [==============================] - 0s 11ms/step - loss: 0.4098 - accuracy: 0.8060 - val_loss: 0.4217 - val_accuracy: 0.8004 Epoch 20/20 25/25 [==============================] - 0s 10ms/step - loss: 0.4060 - accuracy: 0.8080 - val_loss: 0.4180 - val_accuracy: 0.8033 CPU times: user 11 s, sys: 1.4 s, total: 12.4 s Wall time: 9.27 s <tf_keras.src.callbacks.History at 0x7f8cd03ae490>
Let's evaluate the preprocessing and the part with the two neural networks only:
evaluation_nn_only = ensemble_nn_only.evaluate(test_dataset, return_dict=True)
print("Accuracy (NN #1 and #2 only): ", evaluation_nn_only["accuracy"])
print("Loss (NN #1 and #2 only): ", evaluation_nn_only["loss"])
100/100 [==============================] - 0s 2ms/step - loss: 0.4180 - accuracy: 0.8033 Accuracy (NN #1 and #2 only): 0.8033000230789185 Loss (NN #1 and #2 only): 0.41803866624832153
Let's train the two Decision Forest components (one after another).
%%time
train_dataset_with_preprocessing = train_dataset.map(lambda x,y: (preprocessor(x), y))
test_dataset_with_preprocessing = test_dataset.map(lambda x,y: (preprocessor(x), y))
model_3.fit(train_dataset_with_preprocessing)
model_4.fit(train_dataset_with_preprocessing)
WARNING:tensorflow:AutoGraph could not transform <function <lambda> at 0x7f8cd03a2af0> and will run it as-is.
Cause: could not parse the source code of <function <lambda> at 0x7f8cd03a2af0>: no matching AST found among candidates:
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING:tensorflow:AutoGraph could not transform <function <lambda> at 0x7f8cd03a2af0> and will run it as-is.
Cause: could not parse the source code of <function <lambda> at 0x7f8cd03a2af0>: no matching AST found among candidates:
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING: AutoGraph could not transform <function <lambda> at 0x7f8cd03a2af0> and will run it as-is.
Cause: could not parse the source code of <function <lambda> at 0x7f8cd03a2af0>: no matching AST found among candidates:
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING:tensorflow:AutoGraph could not transform <function <lambda> at 0x7f8eaa4e2310> and will run it as-is.
Cause: could not parse the source code of <function <lambda> at 0x7f8eaa4e2310>: no matching AST found among candidates:
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING:tensorflow:AutoGraph could not transform <function <lambda> at 0x7f8eaa4e2310> and will run it as-is.
Cause: could not parse the source code of <function <lambda> at 0x7f8eaa4e2310>: no matching AST found among candidates:
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING: AutoGraph could not transform <function <lambda> at 0x7f8eaa4e2310> and will run it as-is.
Cause: could not parse the source code of <function <lambda> at 0x7f8eaa4e2310>: no matching AST found among candidates:
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
Reading training dataset...
Training dataset read in 0:00:03.601530. Found 2500 examples.
Training model...
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1768230300.681540 180025 kernel.cc:782] Start Yggdrasil model training
I0000 00:00:1768230300.681587 180025 kernel.cc:783] Collect training examples
I0000 00:00:1768230300.681595 180025 kernel.cc:795] Dataspec guide:
column_guides {
column_name_pattern: "^__LABEL$"
type: CATEGORICAL
categorial {
min_vocab_frequency: 0
max_vocab_count: -1
}
}
default_column_guide {
categorial {
max_vocab_count: 2000
}
discretized_numerical {
maximum_num_bins: 255
}
}
ignore_columns_without_guides: false
detect_numerical_as_discretized_numerical: false
I0000 00:00:1768230300.682117 180025 kernel.cc:401] Number of batches: 25
I0000 00:00:1768230300.682135 180025 kernel.cc:402] Number of examples: 2500
I0000 00:00:1768230300.682342 180025 kernel.cc:802] Training dataset:
Number of records: 2500
Number of columns: 11
Number of columns by type:
NUMERICAL: 10 (90.9091%)
CATEGORICAL: 1 (9.09091%)
Columns:
NUMERICAL: 10 (90.9091%)
1: "data:0.0" NUMERICAL mean:0.451604 min:0 max:2.43006 sd:0.528824
2: "data:0.1" NUMERICAL mean:0.467226 min:0 max:2.83875 sd:0.563156
3: "data:0.2" NUMERICAL mean:0.360429 min:0 max:2.23123 sd:0.438675
4: "data:0.3" NUMERICAL mean:0.560341 min:0 max:2.83355 sd:0.605117
5: "data:0.4" NUMERICAL mean:0.385571 min:0 max:1.66618 sd:0.395101
6: "data:0.5" NUMERICAL mean:0.302864 min:0 max:2.01404 sd:0.4148
7: "data:0.6" NUMERICAL mean:0.449712 min:0 max:2.8338 sd:0.518206
8: "data:0.7" NUMERICAL mean:0.352096 min:0 max:2.24348 sd:0.46333
9: "data:0.8" NUMERICAL mean:0.503446 min:0 max:2.21647 sd:0.510352
10: "data:0.9" NUMERICAL mean:0.183463 min:0 max:1.12886 sd:0.270109
CATEGORICAL: 1 (9.09091%)
0: "__LABEL" CATEGORICAL integerized vocab-size:3 no-ood-item
Terminology:
nas: Number of non-available (i.e. missing) values.
ood: Out of dictionary.
manually-defined: Attribute whose type is manually defined by the user, i.e., the type was not automatically inferred.
tokenized: The attribute value is obtained through tokenization.
has-dict: The attribute is attached to a string dictionary e.g. a categorical attribute stored as a string.
vocab-size: Number of unique values.
I0000 00:00:1768230300.682365 180025 kernel.cc:818] Configure learner
I0000 00:00:1768230300.682550 180025 kernel.cc:831] Training config:
learner: "RANDOM_FOREST"
features: "^data:0\\.0$"
features: "^data:0\\.1$"
features: "^data:0\\.2$"
features: "^data:0\\.3$"
features: "^data:0\\.4$"
features: "^data:0\\.5$"
features: "^data:0\\.6$"
features: "^data:0\\.7$"
features: "^data:0\\.8$"
features: "^data:0\\.9$"
label: "^__LABEL$"
task: CLASSIFICATION
random_seed: 1234
metadata {
framework: "TF Keras"
}
pure_serving_model: false
[yggdrasil_decision_forests.model.random_forest.proto.random_forest_config] {
num_trees: 1000
decision_tree {
max_depth: 16
min_examples: 5
in_split_min_examples_check: true
keep_non_leaf_label_distribution: true
num_candidate_attributes: 0
missing_value_policy: GLOBAL_IMPUTATION
allow_na_conditions: false
categorical_set_greedy_forward {
sampling: 0.1
max_num_items: -1
min_item_frequency: 1
}
growing_strategy_local {
}
categorical {
cart {
}
}
axis_aligned_split {
}
internal {
sorting_strategy: PRESORTED
}
uplift {
min_examples_in_treatment: 5
split_score: KULLBACK_LEIBLER
}
numerical_vector_sequence {
max_num_test_examples: 1000
num_random_selected_anchors: 100
}
}
winner_take_all_inference: true
compute_oob_performances: true
compute_oob_variable_importances: false
num_oob_variable_importances_permutations: 1
bootstrap_training_dataset: true
bootstrap_size_ratio: 1
adapt_bootstrap_size_ratio_for_maximum_training_duration: false
sampling_with_replacement: true
}
I0000 00:00:1768230300.682929 180025 kernel.cc:834] Deployment config:
cache_path: "/tmpfs/tmp/tmpmn7x3uo4/working_cache"
num_threads: 32
try_resume_training: true
I0000 00:00:1768230300.683145 182833 kernel.cc:895] Train model
I0000 00:00:1768230300.683265 182833 random_forest.cc:438] Training random forest on 2500 example(s) and 10 feature(s).
I0000 00:00:1768230300.687565 182833 gpu.cc:93] Cannot initialize GPU: Not compiled with GPU support
I0000 00:00:1768230300.697110 182850 random_forest.cc:865] Train tree 1/1000 accuracy:0.770789 logloss:8.2616 [index:7 total:0.01s tree:0.01s]
I0000 00:00:1768230300.698860 182868 random_forest.cc:865] Train tree 15/1000 accuracy:0.775701 logloss:4.78036 [index:24 total:0.01s tree:0.01s]
I0000 00:00:1768230300.699490 182871 random_forest.cc:865] Train tree 32/1000 accuracy:0.783153 logloss:4.20293 [index:27 total:0.01s tree:0.01s]
I0000 00:00:1768230300.709562 182851 random_forest.cc:865] Train tree 47/1000 accuracy:0.8024 logloss:0.825284 [index:44 total:0.02s tree:0.01s]
I0000 00:00:1768230300.713373 182853 random_forest.cc:865] Train tree 57/1000 accuracy:0.8112 logloss:0.729202 [index:52 total:0.03s tree:0.01s]
I0000 00:00:1768230300.718985 182846 random_forest.cc:865] Train tree 67/1000 accuracy:0.8132 logloss:0.60408 [index:66 total:0.03s tree:0.01s]
I0000 00:00:1768230300.720667 182845 random_forest.cc:865] Train tree 81/1000 accuracy:0.8156 logloss:0.577192 [index:78 total:0.03s tree:0.01s]
I0000 00:00:1768230300.725785 182866 random_forest.cc:865] Train tree 97/1000 accuracy:0.8196 logloss:0.523222 [index:92 total:0.04s tree:0.01s]
I0000 00:00:1768230300.731309 182870 random_forest.cc:865] Train tree 113/1000 accuracy:0.8212 logloss:0.472075 [index:113 total:0.04s tree:0.01s]
I0000 00:00:1768230300.735347 182850 random_forest.cc:865] Train tree 123/1000 accuracy:0.8188 logloss:0.47073 [index:126 total:0.05s tree:0.01s]
I0000 00:00:1768230300.738329 182860 random_forest.cc:865] Train tree 133/1000 accuracy:0.82 logloss:0.469323 [index:136 total:0.05s tree:0.01s]
I0000 00:00:1768230300.744164 182852 random_forest.cc:865] Train tree 143/1000 accuracy:0.818 logloss:0.470759 [index:140 total:0.06s tree:0.01s]
I0000 00:00:1768230300.744947 182863 random_forest.cc:865] Train tree 153/1000 accuracy:0.818 logloss:0.470603 [index:152 total:0.06s tree:0.01s]
I0000 00:00:1768230300.750457 182871 random_forest.cc:865] Train tree 163/1000 accuracy:0.8212 logloss:0.456126 [index:162 total:0.06s tree:0.01s]
I0000 00:00:1768230300.753221 182845 random_forest.cc:865] Train tree 178/1000 accuracy:0.822 logloss:0.443247 [index:177 total:0.07s tree:0.01s]
I0000 00:00:1768230300.757045 182869 random_forest.cc:865] Train tree 192/1000 accuracy:0.8228 logloss:0.444042 [index:186 total:0.07s tree:0.01s]
I0000 00:00:1768230300.763734 182875 random_forest.cc:865] Train tree 202/1000 accuracy:0.8228 logloss:0.431619 [index:204 total:0.08s tree:0.01s]
I0000 00:00:1768230300.765069 182856 random_forest.cc:865] Train tree 215/1000 accuracy:0.8232 logloss:0.431544 [index:213 total:0.08s tree:0.01s]
I0000 00:00:1768230300.770414 182873 random_forest.cc:865] Train tree 228/1000 accuracy:0.8216 logloss:0.431848 [index:231 total:0.08s tree:0.01s]
I0000 00:00:1768230300.776181 182862 random_forest.cc:865] Train tree 238/1000 accuracy:0.8212 logloss:0.419546 [index:234 total:0.09s tree:0.01s]
I0000 00:00:1768230300.779418 182844 random_forest.cc:865] Train tree 248/1000 accuracy:0.822 logloss:0.419099 [index:245 total:0.09s tree:0.01s]
I0000 00:00:1768230300.783070 182858 random_forest.cc:865] Train tree 258/1000 accuracy:0.8216 logloss:0.419296 [index:256 total:0.10s tree:0.01s]
I0000 00:00:1768230300.786090 182865 random_forest.cc:865] Train tree 269/1000 accuracy:0.8212 logloss:0.419362 [index:268 total:0.10s tree:0.01s]
I0000 00:00:1768230300.788865 182851 random_forest.cc:865] Train tree 282/1000 accuracy:0.822 logloss:0.419034 [index:282 total:0.10s tree:0.01s]
I0000 00:00:1768230300.794095 182845 random_forest.cc:865] Train tree 292/1000 accuracy:0.8232 logloss:0.419222 [index:291 total:0.11s tree:0.01s]
I0000 00:00:1768230300.797647 182851 random_forest.cc:865] Train tree 308/1000 accuracy:0.8244 logloss:0.419122 [index:306 total:0.11s tree:0.01s]
I0000 00:00:1768230300.801025 182874 random_forest.cc:865] Train tree 320/1000 accuracy:0.8252 logloss:0.418835 [index:317 total:0.11s tree:0.01s]
I0000 00:00:1768230300.804996 182853 random_forest.cc:865] Train tree 332/1000 accuracy:0.8252 logloss:0.418317 [index:335 total:0.12s tree:0.01s]
I0000 00:00:1768230300.810623 182855 random_forest.cc:865] Train tree 342/1000 accuracy:0.8244 logloss:0.417741 [index:340 total:0.12s tree:0.01s]
I0000 00:00:1768230300.813964 182861 random_forest.cc:865] Train tree 352/1000 accuracy:0.8256 logloss:0.417784 [index:353 total:0.13s tree:0.01s]
I0000 00:00:1768230300.816244 182872 random_forest.cc:865] Train tree 365/1000 accuracy:0.8248 logloss:0.417986 [index:363 total:0.13s tree:0.01s]
I0000 00:00:1768230300.821441 182866 random_forest.cc:865] Train tree 375/1000 accuracy:0.826 logloss:0.405443 [index:375 total:0.13s tree:0.01s]
I0000 00:00:1768230300.823053 182856 random_forest.cc:865] Train tree 385/1000 accuracy:0.8236 logloss:0.393259 [index:385 total:0.14s tree:0.01s]
I0000 00:00:1768230300.827707 182858 random_forest.cc:865] Train tree 395/1000 accuracy:0.8236 logloss:0.393505 [index:397 total:0.14s tree:0.01s]
I0000 00:00:1768230300.831280 182871 random_forest.cc:865] Train tree 405/1000 accuracy:0.8232 logloss:0.393504 [index:399 total:0.14s tree:0.01s]
I0000 00:00:1768230300.834163 182853 random_forest.cc:865] Train tree 419/1000 accuracy:0.8228 logloss:0.393749 [index:418 total:0.15s tree:0.01s]
I0000 00:00:1768230300.837645 182871 random_forest.cc:865] Train tree 431/1000 accuracy:0.822 logloss:0.393661 [index:436 total:0.15s tree:0.01s]
I0000 00:00:1768230300.843014 182854 random_forest.cc:865] Train tree 441/1000 accuracy:0.822 logloss:0.393984 [index:439 total:0.16s tree:0.01s]
I0000 00:00:1768230300.846461 182867 random_forest.cc:865] Train tree 456/1000 accuracy:0.8212 logloss:0.39435 [index:453 total:0.16s tree:0.01s]
I0000 00:00:1768230300.850271 182861 random_forest.cc:865] Train tree 466/1000 accuracy:0.8224 logloss:0.394349 [index:462 total:0.16s tree:0.01s]
I0000 00:00:1768230300.854976 182869 random_forest.cc:865] Train tree 476/1000 accuracy:0.8208 logloss:0.393756 [index:476 total:0.17s tree:0.01s]
I0000 00:00:1768230300.859272 182875 random_forest.cc:865] Train tree 488/1000 accuracy:0.8216 logloss:0.393632 [index:486 total:0.17s tree:0.01s]
I0000 00:00:1768230300.863550 182857 random_forest.cc:865] Train tree 500/1000 accuracy:0.8212 logloss:0.393843 [index:500 total:0.18s tree:0.01s]
I0000 00:00:1768230300.865379 182856 random_forest.cc:865] Train tree 510/1000 accuracy:0.8216 logloss:0.393812 [index:506 total:0.18s tree:0.01s]
I0000 00:00:1768230300.870049 182861 random_forest.cc:865] Train tree 526/1000 accuracy:0.822 logloss:0.393784 [index:523 total:0.18s tree:0.01s]
I0000 00:00:1768230300.874994 182869 random_forest.cc:865] Train tree 538/1000 accuracy:0.824 logloss:0.393228 [index:540 total:0.19s tree:0.01s]
I0000 00:00:1768230300.878303 182864 random_forest.cc:865] Train tree 548/1000 accuracy:0.8232 logloss:0.392874 [index:550 total:0.19s tree:0.01s]
I0000 00:00:1768230300.883737 182872 random_forest.cc:865] Train tree 558/1000 accuracy:0.8228 logloss:0.393247 [index:559 total:0.20s tree:0.01s]
I0000 00:00:1768230300.887206 182862 random_forest.cc:865] Train tree 571/1000 accuracy:0.822 logloss:0.393299 [index:570 total:0.20s tree:0.01s]
I0000 00:00:1768230300.891563 182861 random_forest.cc:865] Train tree 581/1000 accuracy:0.822 logloss:0.393191 [index:581 total:0.20s tree:0.01s]
I0000 00:00:1768230300.895058 182857 random_forest.cc:865] Train tree 591/1000 accuracy:0.824 logloss:0.393257 [index:592 total:0.21s tree:0.01s]
I0000 00:00:1768230300.898263 182851 random_forest.cc:865] Train tree 601/1000 accuracy:0.8228 logloss:0.393378 [index:600 total:0.21s tree:0.01s]
I0000 00:00:1768230300.901623 182861 random_forest.cc:865] Train tree 613/1000 accuracy:0.8232 logloss:0.393491 [index:612 total:0.21s tree:0.01s]
I0000 00:00:1768230300.905510 182856 random_forest.cc:865] Train tree 623/1000 accuracy:0.822 logloss:0.39339 [index:619 total:0.22s tree:0.01s]
I0000 00:00:1768230300.908617 182864 random_forest.cc:865] Train tree 636/1000 accuracy:0.8212 logloss:0.393297 [index:633 total:0.22s tree:0.01s]
I0000 00:00:1768230300.913122 182871 random_forest.cc:865] Train tree 646/1000 accuracy:0.8204 logloss:0.393106 [index:644 total:0.23s tree:0.01s]
I0000 00:00:1768230300.914962 182845 random_forest.cc:865] Train tree 660/1000 accuracy:0.8196 logloss:0.392913 [index:655 total:0.23s tree:0.01s]
I0000 00:00:1768230300.920870 182871 random_forest.cc:865] Train tree 676/1000 accuracy:0.82 logloss:0.392853 [index:677 total:0.23s tree:0.01s]
I0000 00:00:1768230300.926782 182856 random_forest.cc:865] Train tree 686/1000 accuracy:0.8216 logloss:0.393013 [index:686 total:0.24s tree:0.01s]
I0000 00:00:1768230300.928917 182865 random_forest.cc:865] Train tree 699/1000 accuracy:0.822 logloss:0.393061 [index:698 total:0.24s tree:0.01s]
I0000 00:00:1768230300.934079 182872 random_forest.cc:865] Train tree 715/1000 accuracy:0.8216 logloss:0.39323 [index:713 total:0.25s tree:0.01s]
I0000 00:00:1768230300.938052 182859 random_forest.cc:865] Train tree 728/1000 accuracy:0.8224 logloss:0.393316 [index:727 total:0.25s tree:0.01s]
I0000 00:00:1768230300.941879 182868 random_forest.cc:865] Train tree 740/1000 accuracy:0.8224 logloss:0.393537 [index:735 total:0.25s tree:0.01s]
I0000 00:00:1768230300.946028 182847 random_forest.cc:865] Train tree 751/1000 accuracy:0.8224 logloss:0.39351 [index:751 total:0.26s tree:0.01s]
I0000 00:00:1768230300.949119 182871 random_forest.cc:865] Train tree 762/1000 accuracy:0.8216 logloss:0.393328 [index:758 total:0.26s tree:0.01s]
I0000 00:00:1768230300.954740 182848 random_forest.cc:865] Train tree 772/1000 accuracy:0.8224 logloss:0.393358 [index:775 total:0.27s tree:0.01s]
I0000 00:00:1768230300.957457 182866 random_forest.cc:865] Train tree 788/1000 accuracy:0.8228 logloss:0.393359 [index:788 total:0.27s tree:0.01s]
I0000 00:00:1768230300.963092 182844 random_forest.cc:865] Train tree 798/1000 accuracy:0.8224 logloss:0.39314 [index:794 total:0.28s tree:0.01s]
I0000 00:00:1768230300.966451 182870 random_forest.cc:865] Train tree 813/1000 accuracy:0.8228 logloss:0.393187 [index:812 total:0.28s tree:0.01s]
I0000 00:00:1768230300.970050 182871 random_forest.cc:865] Train tree 824/1000 accuracy:0.8228 logloss:0.39304 [index:822 total:0.28s tree:0.01s]
I0000 00:00:1768230300.974925 182866 random_forest.cc:865] Train tree 841/1000 accuracy:0.8224 logloss:0.393349 [index:840 total:0.29s tree:0.01s]
I0000 00:00:1768230300.980700 182858 random_forest.cc:865] Train tree 851/1000 accuracy:0.8208 logloss:0.393379 [index:852 total:0.29s tree:0.01s]
I0000 00:00:1768230300.983809 182844 random_forest.cc:865] Train tree 861/1000 accuracy:0.8208 logloss:0.393269 [index:859 total:0.30s tree:0.01s]
I0000 00:00:1768230300.985477 182867 random_forest.cc:865] Train tree 874/1000 accuracy:0.8216 logloss:0.392942 [index:873 total:0.30s tree:0.01s]
I0000 00:00:1768230300.991092 182858 random_forest.cc:865] Train tree 884/1000 accuracy:0.8216 logloss:0.392877 [index:882 total:0.30s tree:0.01s]
I0000 00:00:1768230300.994395 182872 random_forest.cc:865] Train tree 894/1000 accuracy:0.822 logloss:0.392757 [index:895 total:0.31s tree:0.01s]
I0000 00:00:1768230300.996388 182847 random_forest.cc:865] Train tree 908/1000 accuracy:0.8228 logloss:0.39268 [index:907 total:0.31s tree:0.01s]
I0000 00:00:1768230301.001299 182856 random_forest.cc:865] Train tree 921/1000 accuracy:0.8224 logloss:0.39268 [index:920 total:0.31s tree:0.01s]
I0000 00:00:1768230301.004969 182847 random_forest.cc:865] Train tree 933/1000 accuracy:0.8224 logloss:0.392732 [index:930 total:0.32s tree:0.01s]
I0000 00:00:1768230301.008330 182865 random_forest.cc:865] Train tree 943/1000 accuracy:0.822 logloss:0.392641 [index:944 total:0.32s tree:0.01s]
I0000 00:00:1768230301.013507 182849 random_forest.cc:865] Train tree 953/1000 accuracy:0.822 logloss:0.392901 [index:954 total:0.33s tree:0.01s]
I0000 00:00:1768230301.014777 182873 random_forest.cc:865] Train tree 964/1000 accuracy:0.8216 logloss:0.392839 [index:962 total:0.33s tree:0.01s]
I0000 00:00:1768230301.018683 182860 random_forest.cc:865] Train tree 975/1000 accuracy:0.8212 logloss:0.392662 [index:973 total:0.33s tree:0.01s]
I0000 00:00:1768230301.022530 182863 random_forest.cc:865] Train tree 989/1000 accuracy:0.8208 logloss:0.392667 [index:988 total:0.33s tree:0.01s]
I0000 00:00:1768230301.027536 182844 random_forest.cc:865] Train tree 999/1000 accuracy:0.8208 logloss:0.392441 [index:995 total:0.34s tree:0.01s]
I0000 00:00:1768230301.028046 182848 random_forest.cc:865] Train tree 1000/1000 accuracy:0.8208 logloss:0.392439 [index:998 total:0.34s tree:0.01s]
I0000 00:00:1768230301.028583 182833 random_forest.cc:949] Final OOB metrics: accuracy:0.8208 logloss:0.392439
I0000 00:00:1768230301.178241 182833 kernel.cc:926] Export model in log directory: /tmpfs/tmp/tmpmn7x3uo4 with prefix 4140d529447043ee
I0000 00:00:1768230301.409876 182833 kernel.cc:944] Save model in resources
I0000 00:00:1768230301.413540 180025 abstract_model.cc:921] Model self evaluation:
Number of predictions (without weights): 2500
Number of predictions (with weights): 2500
Task: CLASSIFICATION
Label: __LABEL
Accuracy: 0.8208 CI95[W][0.807707 0.833334]
LogLoss: : 0.392439
ErrorRate: : 0.1792
Default Accuracy: : 0.75
Default LogLoss: : 0.562335
Default ErrorRate: : 0.25
Confusion Table:
truth\prediction
1 2
1 1729 146
2 302 323
Total: 2500
Model trained in 0:00:02.033220
Compiling model...
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1768230302.604784 180025 decision_forest.cc:808] Model loaded with 1000 root(s), 343712 node(s), and 10 input feature(s).
I0000 00:00:1768230302.608020 180025 abstract_model.cc:1439] Engine "RandomForestOptPred" built
Model compiled.
Reading training dataset...
Training dataset read in 0:00:00.205199. Found 2500 examples.
Training model...
I0000 00:00:1768230303.453842 180025 kernel.cc:782] Start Yggdrasil model training
I0000 00:00:1768230303.453877 180025 kernel.cc:783] Collect training examples
I0000 00:00:1768230303.453885 180025 kernel.cc:795] Dataspec guide:
column_guides {
column_name_pattern: "^__LABEL$"
type: CATEGORICAL
categorial {
min_vocab_frequency: 0
max_vocab_count: -1
}
}
default_column_guide {
categorial {
max_vocab_count: 2000
}
discretized_numerical {
maximum_num_bins: 255
}
}
ignore_columns_without_guides: false
detect_numerical_as_discretized_numerical: false
I0000 00:00:1768230303.453958 180025 kernel.cc:401] Number of batches: 25
I0000 00:00:1768230303.453964 180025 kernel.cc:402] Number of examples: 2500
I0000 00:00:1768230303.454178 180025 kernel.cc:802] Training dataset:
Number of records: 2500
Number of columns: 11
Number of columns by type:
NUMERICAL: 10 (90.9091%)
CATEGORICAL: 1 (9.09091%)
Columns:
NUMERICAL: 10 (90.9091%)
1: "data:0.0" NUMERICAL mean:0.451604 min:0 max:2.43006 sd:0.528824
2: "data:0.1" NUMERICAL mean:0.467226 min:0 max:2.83875 sd:0.563156
3: "data:0.2" NUMERICAL mean:0.360429 min:0 max:2.23123 sd:0.438675
4: "data:0.3" NUMERICAL mean:0.560341 min:0 max:2.83355 sd:0.605117
5: "data:0.4" NUMERICAL mean:0.385571 min:0 max:1.66618 sd:0.395101
6: "data:0.5" NUMERICAL mean:0.302864 min:0 max:2.01404 sd:0.4148
7: "data:0.6" NUMERICAL mean:0.449712 min:0 max:2.8338 sd:0.518206
8: "data:0.7" NUMERICAL mean:0.352096 min:0 max:2.24348 sd:0.46333
9: "data:0.8" NUMERICAL mean:0.503446 min:0 max:2.21647 sd:0.510352
10: "data:0.9" NUMERICAL mean:0.183463 min:0 max:1.12886 sd:0.270109
CATEGORICAL: 1 (9.09091%)
0: "__LABEL" CATEGORICAL integerized vocab-size:3 no-ood-item
Terminology:
nas: Number of non-available (i.e. missing) values.
ood: Out of dictionary.
manually-defined: Attribute whose type is manually defined by the user, i.e., the type was not automatically inferred.
tokenized: The attribute value is obtained through tokenization.
has-dict: The attribute is attached to a string dictionary e.g. a categorical attribute stored as a string.
vocab-size: Number of unique values.
I0000 00:00:1768230303.454202 180025 kernel.cc:818] Configure learner
I0000 00:00:1768230303.454385 180025 kernel.cc:831] Training config:
learner: "RANDOM_FOREST"
features: "^data:0\\.0$"
features: "^data:0\\.1$"
features: "^data:0\\.2$"
features: "^data:0\\.3$"
features: "^data:0\\.4$"
features: "^data:0\\.5$"
features: "^data:0\\.6$"
features: "^data:0\\.7$"
features: "^data:0\\.8$"
features: "^data:0\\.9$"
label: "^__LABEL$"
task: CLASSIFICATION
random_seed: 4567
metadata {
framework: "TF Keras"
}
pure_serving_model: false
[yggdrasil_decision_forests.model.random_forest.proto.random_forest_config] {
num_trees: 1000
decision_tree {
max_depth: 16
min_examples: 5
in_split_min_examples_check: true
keep_non_leaf_label_distribution: true
num_candidate_attributes: 0
missing_value_policy: GLOBAL_IMPUTATION
allow_na_conditions: false
categorical_set_greedy_forward {
sampling: 0.1
max_num_items: -1
min_item_frequency: 1
}
growing_strategy_local {
}
categorical {
cart {
}
}
axis_aligned_split {
}
internal {
sorting_strategy: PRESORTED
}
uplift {
min_examples_in_treatment: 5
split_score: KULLBACK_LEIBLER
}
numerical_vector_sequence {
max_num_test_examples: 1000
num_random_selected_anchors: 100
}
}
winner_take_all_inference: true
compute_oob_performances: true
compute_oob_variable_importances: false
num_oob_variable_importances_permutations: 1
bootstrap_training_dataset: true
bootstrap_size_ratio: 1
adapt_bootstrap_size_ratio_for_maximum_training_duration: false
sampling_with_replacement: true
}
I0000 00:00:1768230303.454451 180025 kernel.cc:834] Deployment config:
cache_path: "/tmpfs/tmp/tmpm730xbef/working_cache"
num_threads: 32
try_resume_training: true
I0000 00:00:1768230303.454658 182983 kernel.cc:895] Train model
I0000 00:00:1768230303.454785 182983 random_forest.cc:438] Training random forest on 2500 example(s) and 10 feature(s).
I0000 00:00:1768230303.455814 182983 gpu.cc:93] Cannot initialize GPU: Not compiled with GPU support
I0000 00:00:1768230303.465401 183004 random_forest.cc:865] Train tree 1/1000 accuracy:0.762987 logloss:8.54281 [index:11 total:0.01s tree:0.01s]
I0000 00:00:1768230303.466493 183006 random_forest.cc:865] Train tree 14/1000 accuracy:0.781926 logloss:6.56401 [index:13 total:0.01s tree:0.01s]
I0000 00:00:1768230303.467462 183020 random_forest.cc:865] Train tree 30/1000 accuracy:0.783652 logloss:5.53403 [index:27 total:0.01s tree:0.01s]
I0000 00:00:1768230303.477709 183008 random_forest.cc:865] Train tree 46/1000 accuracy:0.8128 logloss:0.807687 [index:43 total:0.02s tree:0.01s]
I0000 00:00:1768230303.483488 182995 random_forest.cc:865] Train tree 56/1000 accuracy:0.8144 logloss:0.659373 [index:53 total:0.03s tree:0.01s]
I0000 00:00:1768230303.486892 183017 random_forest.cc:865] Train tree 66/1000 accuracy:0.8128 logloss:0.605998 [index:65 total:0.03s tree:0.01s]
I0000 00:00:1768230303.491315 183012 random_forest.cc:865] Train tree 76/1000 accuracy:0.8172 logloss:0.551689 [index:77 total:0.04s tree:0.01s]
I0000 00:00:1768230303.494712 183015 random_forest.cc:865] Train tree 86/1000 accuracy:0.8172 logloss:0.53852 [index:83 total:0.04s tree:0.01s]
I0000 00:00:1768230303.496502 183017 random_forest.cc:865] Train tree 100/1000 accuracy:0.8188 logloss:0.526545 [index:97 total:0.04s tree:0.01s]
I0000 00:00:1768230303.502669 183011 random_forest.cc:865] Train tree 110/1000 accuracy:0.82 logloss:0.498517 [index:110 total:0.05s tree:0.01s]
I0000 00:00:1768230303.506105 183016 random_forest.cc:865] Train tree 120/1000 accuracy:0.8204 logloss:0.48502 [index:120 total:0.05s tree:0.01s]
I0000 00:00:1768230303.507049 183001 random_forest.cc:865] Train tree 131/1000 accuracy:0.8204 logloss:0.484673 [index:130 total:0.05s tree:0.01s]
I0000 00:00:1768230303.510393 183023 random_forest.cc:865] Train tree 141/1000 accuracy:0.82 logloss:0.485591 [index:137 total:0.05s tree:0.01s]
I0000 00:00:1768230303.514416 183009 random_forest.cc:865] Train tree 153/1000 accuracy:0.8208 logloss:0.471322 [index:154 total:0.06s tree:0.01s]
I0000 00:00:1768230303.517841 183005 random_forest.cc:865] Train tree 165/1000 accuracy:0.8212 logloss:0.470914 [index:166 total:0.06s tree:0.01s]
I0000 00:00:1768230303.524441 183011 random_forest.cc:865] Train tree 175/1000 accuracy:0.8216 logloss:0.469738 [index:171 total:0.07s tree:0.01s]
I0000 00:00:1768230303.527888 183002 random_forest.cc:865] Train tree 185/1000 accuracy:0.82 logloss:0.456836 [index:180 total:0.07s tree:0.01s]
I0000 00:00:1768230303.529685 183008 random_forest.cc:865] Train tree 195/1000 accuracy:0.8204 logloss:0.456703 [index:195 total:0.07s tree:0.01s]
I0000 00:00:1768230303.534141 183003 random_forest.cc:865] Train tree 205/1000 accuracy:0.82 logloss:0.430207 [index:202 total:0.08s tree:0.01s]
I0000 00:00:1768230303.537951 183010 random_forest.cc:865] Train tree 215/1000 accuracy:0.8208 logloss:0.429771 [index:215 total:0.08s tree:0.01s]
I0000 00:00:1768230303.539775 183017 random_forest.cc:865] Train tree 227/1000 accuracy:0.8216 logloss:0.429196 [index:225 total:0.08s tree:0.01s]
I0000 00:00:1768230303.545094 183010 random_forest.cc:865] Train tree 245/1000 accuracy:0.82 logloss:0.415412 [index:246 total:0.09s tree:0.01s]
I0000 00:00:1768230303.550977 182994 random_forest.cc:865] Train tree 255/1000 accuracy:0.8192 logloss:0.403028 [index:254 total:0.10s tree:0.01s]
I0000 00:00:1768230303.554383 183024 random_forest.cc:865] Train tree 265/1000 accuracy:0.8168 logloss:0.403629 [index:263 total:0.10s tree:0.01s]
I0000 00:00:1768230303.555967 183019 random_forest.cc:865] Train tree 275/1000 accuracy:0.8188 logloss:0.403607 [index:277 total:0.10s tree:0.01s]
I0000 00:00:1768230303.558121 183020 random_forest.cc:865] Train tree 285/1000 accuracy:0.8188 logloss:0.40407 [index:282 total:0.10s tree:0.01s]
I0000 00:00:1768230303.564233 183019 random_forest.cc:865] Train tree 303/1000 accuracy:0.8176 logloss:0.403832 [index:298 total:0.11s tree:0.01s]
I0000 00:00:1768230303.570841 183017 random_forest.cc:865] Train tree 313/1000 accuracy:0.8168 logloss:0.404546 [index:313 total:0.11s tree:0.01s]
I0000 00:00:1768230303.572298 183024 random_forest.cc:865] Train tree 325/1000 accuracy:0.8164 logloss:0.404478 [index:327 total:0.12s tree:0.01s]
I0000 00:00:1768230303.575662 183001 random_forest.cc:865] Train tree 337/1000 accuracy:0.8184 logloss:0.403586 [index:341 total:0.12s tree:0.01s]
I0000 00:00:1768230303.581660 183006 random_forest.cc:865] Train tree 347/1000 accuracy:0.818 logloss:0.390508 [index:342 total:0.13s tree:0.01s]
I0000 00:00:1768230303.585200 183003 random_forest.cc:865] Train tree 357/1000 accuracy:0.82 logloss:0.39007 [index:358 total:0.13s tree:0.01s]
I0000 00:00:1768230303.586682 183012 random_forest.cc:865] Train tree 368/1000 accuracy:0.82 logloss:0.389862 [index:365 total:0.13s tree:0.01s]
I0000 00:00:1768230303.591873 182994 random_forest.cc:865] Train tree 378/1000 accuracy:0.8188 logloss:0.389753 [index:374 total:0.14s tree:0.01s]
I0000 00:00:1768230303.595428 182999 random_forest.cc:865] Train tree 388/1000 accuracy:0.8196 logloss:0.389617 [index:386 total:0.14s tree:0.01s]
I0000 00:00:1768230303.596894 183023 random_forest.cc:865] Train tree 399/1000 accuracy:0.8204 logloss:0.389636 [index:397 total:0.14s tree:0.01s]
I0000 00:00:1768230303.601908 183008 random_forest.cc:865] Train tree 417/1000 accuracy:0.8192 logloss:0.390487 [index:418 total:0.15s tree:0.01s]
I0000 00:00:1768230303.608197 183015 random_forest.cc:865] Train tree 427/1000 accuracy:0.8196 logloss:0.390638 [index:427 total:0.15s tree:0.01s]
I0000 00:00:1768230303.610284 182995 random_forest.cc:865] Train tree 439/1000 accuracy:0.8192 logloss:0.390578 [index:437 total:0.15s tree:0.01s]
I0000 00:00:1768230303.614520 183003 random_forest.cc:865] Train tree 452/1000 accuracy:0.8196 logloss:0.390347 [index:452 total:0.16s tree:0.01s]
I0000 00:00:1768230303.620181 183001 random_forest.cc:865] Train tree 462/1000 accuracy:0.8204 logloss:0.389768 [index:460 total:0.16s tree:0.01s]
I0000 00:00:1768230303.621931 183021 random_forest.cc:865] Train tree 475/1000 accuracy:0.8196 logloss:0.389892 [index:472 total:0.17s tree:0.01s]
I0000 00:00:1768230303.625538 183007 random_forest.cc:865] Train tree 485/1000 accuracy:0.8196 logloss:0.390221 [index:485 total:0.17s tree:0.01s]
I0000 00:00:1768230303.629469 183010 random_forest.cc:865] Train tree 497/1000 accuracy:0.82 logloss:0.390335 [index:502 total:0.17s tree:0.01s]
I0000 00:00:1768230303.633987 183003 random_forest.cc:865] Train tree 512/1000 accuracy:0.8192 logloss:0.390262 [index:511 total:0.18s tree:0.01s]
I0000 00:00:1768230303.638718 182995 random_forest.cc:865] Train tree 527/1000 accuracy:0.8212 logloss:0.390504 [index:527 total:0.18s tree:0.01s]
I0000 00:00:1768230303.644347 182998 random_forest.cc:865] Train tree 537/1000 accuracy:0.8196 logloss:0.390457 [index:537 total:0.19s tree:0.01s]
I0000 00:00:1768230303.647942 183002 random_forest.cc:865] Train tree 547/1000 accuracy:0.82 logloss:0.390243 [index:549 total:0.19s tree:0.01s]
I0000 00:00:1768230303.650266 183000 random_forest.cc:865] Train tree 560/1000 accuracy:0.8196 logloss:0.390609 [index:560 total:0.19s tree:0.01s]
I0000 00:00:1768230303.654073 183007 random_forest.cc:865] Train tree 574/1000 accuracy:0.82 logloss:0.390777 [index:573 total:0.20s tree:0.01s]
I0000 00:00:1768230303.658821 183015 random_forest.cc:865] Train tree 587/1000 accuracy:0.8212 logloss:0.3908 [index:587 total:0.20s tree:0.01s]
I0000 00:00:1768230303.664089 182996 random_forest.cc:865] Train tree 597/1000 accuracy:0.82 logloss:0.390817 [index:596 total:0.21s tree:0.01s]
I0000 00:00:1768230303.665652 182994 random_forest.cc:865] Train tree 607/1000 accuracy:0.82 logloss:0.390852 [index:607 total:0.21s tree:0.01s]
I0000 00:00:1768230303.671099 183010 random_forest.cc:865] Train tree 627/1000 accuracy:0.8216 logloss:0.390909 [index:623 total:0.22s tree:0.01s]
I0000 00:00:1768230303.676283 182995 random_forest.cc:865] Train tree 640/1000 accuracy:0.8212 logloss:0.390891 [index:639 total:0.22s tree:0.01s]
I0000 00:00:1768230303.681430 183019 random_forest.cc:865] Train tree 650/1000 accuracy:0.822 logloss:0.390983 [index:649 total:0.23s tree:0.01s]
I0000 00:00:1768230303.683583 183003 random_forest.cc:865] Train tree 663/1000 accuracy:0.8216 logloss:0.39087 [index:661 total:0.23s tree:0.01s]
I0000 00:00:1768230303.689211 183011 random_forest.cc:865] Train tree 673/1000 accuracy:0.8216 logloss:0.390566 [index:674 total:0.23s tree:0.01s]
I0000 00:00:1768230303.692439 183016 random_forest.cc:865] Train tree 683/1000 accuracy:0.8216 logloss:0.390462 [index:686 total:0.24s tree:0.01s]
I0000 00:00:1768230303.694875 183006 random_forest.cc:865] Train tree 699/1000 accuracy:0.8212 logloss:0.39041 [index:696 total:0.24s tree:0.01s]
I0000 00:00:1768230303.700278 183004 random_forest.cc:865] Train tree 716/1000 accuracy:0.8216 logloss:0.390474 [index:713 total:0.24s tree:0.01s]
I0000 00:00:1768230303.706257 183008 random_forest.cc:865] Train tree 726/1000 accuracy:0.8212 logloss:0.390097 [index:726 total:0.25s tree:0.01s]
I0000 00:00:1768230303.708027 182994 random_forest.cc:865] Train tree 738/1000 accuracy:0.8216 logloss:0.390157 [index:736 total:0.25s tree:0.01s]
I0000 00:00:1768230303.713020 183023 random_forest.cc:865] Train tree 754/1000 accuracy:0.8212 logloss:0.389946 [index:753 total:0.26s tree:0.01s]
I0000 00:00:1768230303.717847 183013 random_forest.cc:865] Train tree 767/1000 accuracy:0.82 logloss:0.389843 [index:769 total:0.26s tree:0.01s]
I0000 00:00:1768230303.723641 183014 random_forest.cc:865] Train tree 777/1000 accuracy:0.8204 logloss:0.389768 [index:774 total:0.27s tree:0.01s]
I0000 00:00:1768230303.724315 183012 random_forest.cc:865] Train tree 787/1000 accuracy:0.8208 logloss:0.389771 [index:788 total:0.27s tree:0.01s]
I0000 00:00:1768230303.727058 183019 random_forest.cc:865] Train tree 798/1000 accuracy:0.8208 logloss:0.38986 [index:798 total:0.27s tree:0.01s]
I0000 00:00:1768230303.732122 183005 random_forest.cc:865] Train tree 811/1000 accuracy:0.8196 logloss:0.389831 [index:812 total:0.28s tree:0.01s]
I0000 00:00:1768230303.734916 183019 random_forest.cc:865] Train tree 821/1000 accuracy:0.82 logloss:0.389688 [index:817 total:0.28s tree:0.01s]
I0000 00:00:1768230303.741373 183006 random_forest.cc:865] Train tree 831/1000 accuracy:0.8204 logloss:0.389872 [index:829 total:0.29s tree:0.01s]
I0000 00:00:1768230303.744810 183019 random_forest.cc:865] Train tree 843/1000 accuracy:0.8204 logloss:0.390055 [index:842 total:0.29s tree:0.01s]
I0000 00:00:1768230303.747393 183024 random_forest.cc:865] Train tree 855/1000 accuracy:0.8208 logloss:0.390179 [index:852 total:0.29s tree:0.01s]
I0000 00:00:1768230303.752320 183012 random_forest.cc:865] Train tree 870/1000 accuracy:0.82 logloss:0.390277 [index:868 total:0.30s tree:0.01s]
I0000 00:00:1768230303.756196 183023 random_forest.cc:865] Train tree 881/1000 accuracy:0.8216 logloss:0.390109 [index:876 total:0.30s tree:0.01s]
I0000 00:00:1768230303.760200 183006 random_forest.cc:865] Train tree 894/1000 accuracy:0.8212 logloss:0.390015 [index:893 total:0.30s tree:0.01s]
I0000 00:00:1768230303.763619 183008 random_forest.cc:865] Train tree 904/1000 accuracy:0.8212 logloss:0.389881 [index:905 total:0.31s tree:0.01s]
I0000 00:00:1768230303.767822 183022 random_forest.cc:865] Train tree 918/1000 accuracy:0.8212 logloss:0.389576 [index:921 total:0.31s tree:0.01s]
I0000 00:00:1768230303.773291 183001 random_forest.cc:865] Train tree 934/1000 accuracy:0.8212 logloss:0.389619 [index:938 total:0.32s tree:0.01s]
I0000 00:00:1768230303.777380 182999 random_forest.cc:865] Train tree 945/1000 accuracy:0.822 logloss:0.38962 [index:943 total:0.32s tree:0.01s]
I0000 00:00:1768230303.781865 183021 random_forest.cc:865] Train tree 961/1000 accuracy:0.8212 logloss:0.389526 [index:965 total:0.33s tree:0.01s]
I0000 00:00:1768230303.787267 182999 random_forest.cc:865] Train tree 971/1000 accuracy:0.8208 logloss:0.389411 [index:971 total:0.33s tree:0.01s]
I0000 00:00:1768230303.790665 183010 random_forest.cc:865] Train tree 981/1000 accuracy:0.82 logloss:0.389526 [index:976 total:0.33s tree:0.01s]
I0000 00:00:1768230303.793262 183019 random_forest.cc:865] Train tree 992/1000 accuracy:0.8216 logloss:0.389514 [index:990 total:0.34s tree:0.01s]
I0000 00:00:1768230303.796235 183015 random_forest.cc:865] Train tree 1000/1000 accuracy:0.8208 logloss:0.389381 [index:992 total:0.34s tree:0.01s]
I0000 00:00:1768230303.796440 182983 random_forest.cc:949] Final OOB metrics: accuracy:0.8208 logloss:0.389381
I0000 00:00:1768230303.937319 182983 kernel.cc:926] Export model in log directory: /tmpfs/tmp/tmpm730xbef with prefix bc9b6e8a9a974d3f
I0000 00:00:1768230304.162959 182983 kernel.cc:944] Save model in resources
I0000 00:00:1768230304.165439 180025 abstract_model.cc:921] Model self evaluation:
Number of predictions (without weights): 2500
Number of predictions (with weights): 2500
Task: CLASSIFICATION
Label: __LABEL
Accuracy: 0.8208 CI95[W][0.807707 0.833334]
LogLoss: : 0.389381
ErrorRate: : 0.1792
Default Accuracy: : 0.75
Default LogLoss: : 0.562335
Default ErrorRate: : 0.25
Confusion Table:
truth\prediction
1 2
1 1729 146
2 302 323
Total: 2500
Model trained in 0:00:01.882787
Compiling model...
I0000 00:00:1768230305.275836 180025 decision_forest.cc:808] Model loaded with 1000 root(s), 343324 node(s), and 10 input feature(s).
Model compiled.
CPU times: user 22.1 s, sys: 1.72 s, total: 23.8 s
Wall time: 8.5 s
<tf_keras.src.callbacks.History at 0x7f8e0c076730>
And let's evaluate the Decision Forests individually.
model_3.compile(["accuracy"])
model_4.compile(["accuracy"])
evaluation_df3_only = model_3.evaluate(
test_dataset_with_preprocessing, return_dict=True)
evaluation_df4_only = model_4.evaluate(
test_dataset_with_preprocessing, return_dict=True)
print("Accuracy (DF #3 only): ", evaluation_df3_only["accuracy"])
print("Accuracy (DF #4 only): ", evaluation_df4_only["accuracy"])
100/100 [==============================] - 1s 10ms/step - loss: 0.0000e+00 - accuracy: 0.8185 100/100 [==============================] - 1s 10ms/step - loss: 0.0000e+00 - accuracy: 0.8200 Accuracy (DF #3 only): 0.8184999823570251 Accuracy (DF #4 only): 0.8199999928474426
Let's evaluate the entire model composition:
ensemble_nn_and_df.compile(
loss=tf_keras.losses.BinaryCrossentropy(), metrics=["accuracy"])
evaluation_nn_and_df = ensemble_nn_and_df.evaluate(
test_dataset, return_dict=True)
print("Accuracy (2xNN and 2xDF): ", evaluation_nn_and_df["accuracy"])
print("Loss (2xNN and 2xDF): ", evaluation_nn_and_df["loss"])
100/100 [==============================] - 1s 10ms/step - loss: 0.3902 - accuracy: 0.8171 Accuracy (2xNN and 2xDF): 0.8170999884605408 Loss (2xNN and 2xDF): 0.39022520184516907
To finish, let's finetune the neural network layer a bit more. Note that we do not finetune the pre-trained embedding as the DF models depends on it (unless we would also retrain them after).
In summary, you have:
print(f"Accuracy (NN #1 and #2 only):\t{evaluation_nn_only['accuracy']:.6f}")
print(f"Accuracy (DF #3 only):\t\t{evaluation_df3_only['accuracy']:.6f}")
print(f"Accuracy (DF #4 only):\t\t{evaluation_df4_only['accuracy']:.6f}")
print("----------------------------------------")
print(f"Accuracy (2xNN and 2xDF):\t{evaluation_nn_and_df['accuracy']:.6f}")
def delta_percent(src_eval, key):
src_acc = src_eval["accuracy"]
final_acc = evaluation_nn_and_df["accuracy"]
increase = final_acc - src_acc
print(f"\t\t\t\t {increase:+.6f} over {key}")
delta_percent(evaluation_nn_only, "NN #1 and #2 only")
delta_percent(evaluation_df3_only, "DF #3 only")
delta_percent(evaluation_df4_only, "DF #4 only")
Accuracy (NN #1 and #2 only): 0.803300
Accuracy (DF #3 only): 0.818500
Accuracy (DF #4 only): 0.820000
----------------------------------------
Accuracy (2xNN and 2xDF): 0.817100
+0.013800 over NN #1 and #2 only
-0.001400 over DF #3 only
-0.002900 over DF #4 only
Here, you can see that the composed model performs better than its individual parts. This is why ensembles work so well.
What's next?
In this example, you saw how to combine decision forests with neural networks. An extra step would be to further train the neural network and the decision forests together.
In addition, for the sake of clarity, the decision forests received only the preprocessed input. However, decision forests are generally great are consuming raw data. The model would be improved by also feeding the raw features to the decision forest models.
In this example, the final model is the average of the predictions of the
individual models. This solution works well if all of the model perform more of
less with the same. However, if one of the sub-models is very good, aggregating
it with other models might actually be detrimental (or vice-versa; for example
try to reduce the number of examples from 1k and see how it hurts the neural
networks a lot; or enable the SPARSE_OBLIQUE split in the second Random Forest
model).