
スタートガイド
TensorFlow Hub は、すぐに微調整してどこにでもデプロイ可能な事前トレーニング済みモデルの包括的リポジトリです。tensorflow_hub ライブラリを使用して、最小限のコードで最新のトレーニング済みモデルをダウンロードします。
以下のチュートリアルは、TF Hub のモデルを個別のニーズに適用する際のスタートガイドとして役立ちます。インタラクティブなチュートリアルでは、内容を変更しながら実施できます。変更を加えるには、インタラクティブなチュートリアルの上部にある [Google Colab で実行] ボタンをクリックします。
入門者向け
機械学習や TensorFlow になじみがない場合は、画像やテキストを分類する方法の概要を理解したり、画像内のオブジェクトを検出したり、所有する有名アーティストなどの写真を画風変換したりすることから始めるとよいでしょう。

画像分類
事前トレーニング済みの画像分類ツール上に Keras モデルを構築して花を識別します。
BERT を使用したテキスト分類
BERT を使用して Keras モデルを構築し、テキスト分類による感情分析タスクを解決します。画風変換
ニューラル ネットワークに、ピカソやゴッホ、あるいは自分自身の画風で画像を再描画させることができます。
オブジェクト検出
FasterRCNN や SSD などのモデルを使用して画像内のオブジェクトを検出します。経験豊かなデベロッパー向け
TensorFlow Hub の NLP、画像、音声、動画の各モデルの使い方に関するさらに高度なチュートリアルをご覧ください。
NLP チュートリアル
TensorFlow Hub のモデルを使用して、一般的な NLP タスクを解決します。左側のナビゲーションに、利用可能なすべての NLP チュートリアルが表示されます。
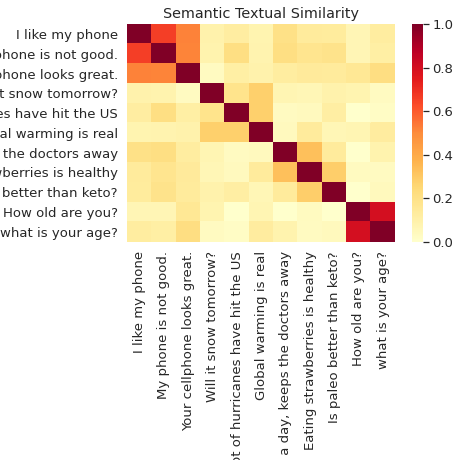
意味的類似性
Universal Sentence Encoder を使用して、文の分類と意味的な比較を行います。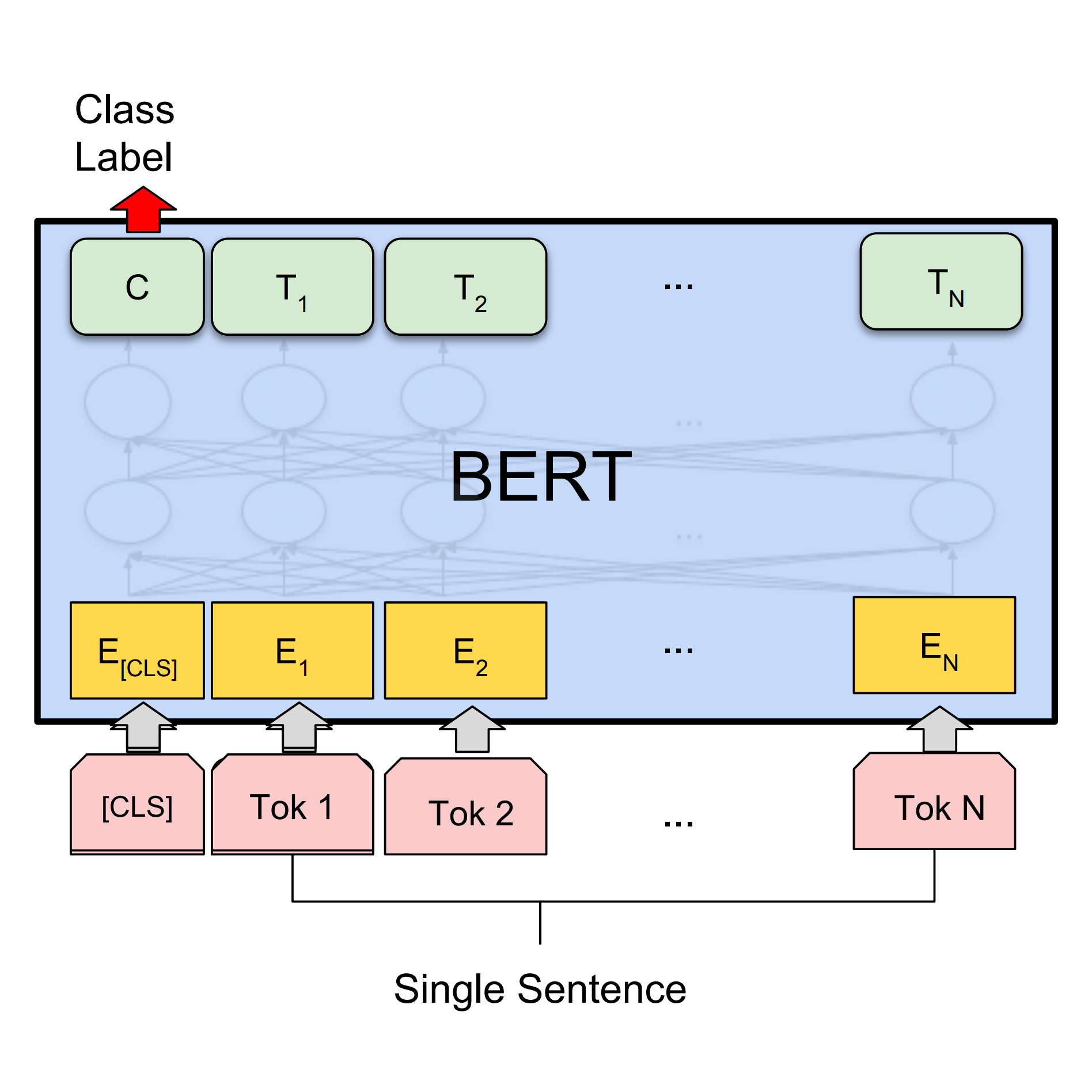
TPU 上での BERT
BERT を使用して、TPU 上で実行されている GLUE ベンチマーク タスクを解決します。Multilingual Universal Sentence Encoder の Q&A
Multilingual Universal Sentence Encoder の Q&A モデルを使用して、SQuAD データセットからのさまざまな言語による質問に回答します。画像チュートリアル
GAN、超解像モデルなどの使い方について説明します。左側のナビゲーションに、利用可能なすべての画像チュートリアルが表示されます。



音声チュートリアル
音程認識と音声分類を含む音声データ用にトレーニングされたモデルを使用したチュートリアルです。

動画チュートリアル
動作認識、動画の補完などの動画データ用にトレーニングされた ML モデルをお試しください。

動作認識
Inflated 3D ConvNet モデルを使用して、動画から 400 種類の動作のいずれかを検出します。
動画の補完
インビトウィーンを 3D 畳み込みとともに使用して、動画フレームの間を補完します。