
This page lists a set of known guides and tools solving problems in the text domain with TensorFlow Hub. It is a starting place for anybody who wants to solve typical ML problems using pre-trained ML components rather than starting from scratch.
Classification
When we want to predict a class for a given example, for example sentiment, toxicity, article category, or any other characteristic.

The tutorials below are solving the same task from different perspectives and using different tools.
Keras
Text classification with Keras - example for building an IMDB sentiment classifier with Keras and TensorFlow Datasets.
Estimator
Text classification - example for building an IMDB sentiment classifier with Estimator. Contains multiple tips for improvement and a module comparison section.
BERT
Predicting Movie Review Sentiment with BERT on TF Hub -
shows how to use a BERT module for classification. Includes use of bert
library for tokenization and preprocessing.
Kaggle
IMDB classification on Kaggle - shows how to easily interact with a Kaggle competition from a Colab, including downloading the data and submitting the results.
| Estimator | Keras | TF2 | TF Datasets | BERT | Kaggle APIs | |
|---|---|---|---|---|---|---|
| Text classification | ||||||
| Text classification with Keras | ||||||
| Predicting Movie Review Sentiment with BERT on TF Hub | ||||||
| IMDB classification on Kaggle |
Bangla task with FastText embeddings
TensorFlow Hub does not currently offer a module in every language. The following tutorial shows how to leverage TensorFlow Hub for fast experimentation and modular ML development.
Bangla Article Classifier - demonstrates how to create a reusable TensorFlow Hub text embedding, and use it to train a Keras classifier for BARD Bangla Article dataset.
Semantic similarity
When we want to find out which sentences correlate with each other in zero-shot setup (no training examples).
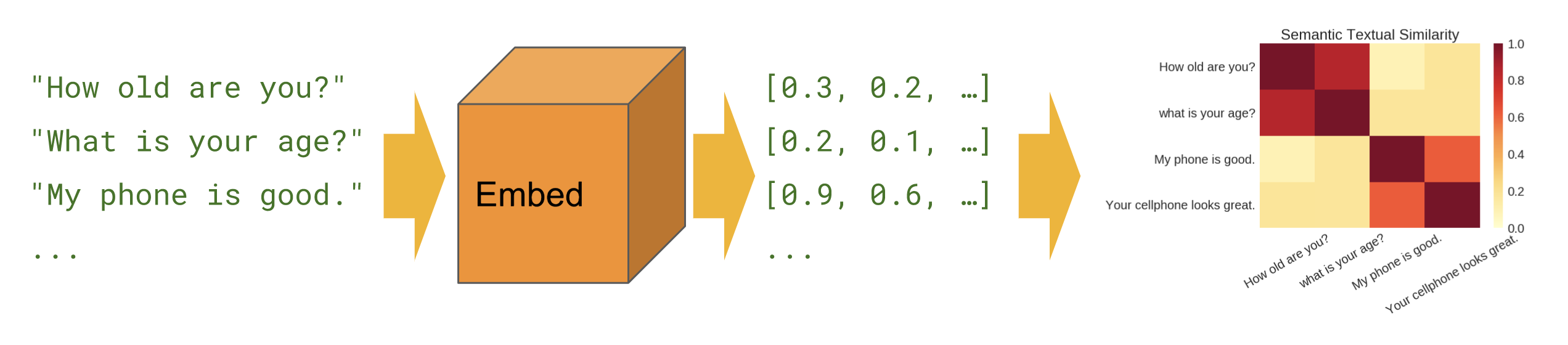
Basic
Semantic similarity - shows how to use the sentence encoder module to compute sentence similarity.
Cross-lingual
Cross-lingual semantic similarity - shows how to use one of the cross-lingual sentence encoders to compute sentence similarity across languages.
Semantic retrieval
Semantic retrieval - shows how to use Q/A sentence encoder to index a collection of documents for retrieval based on semantic similarity.
SentencePiece input
Semantic similarity with universal encoder lite - shows how to use sentence encoder modules that accept SentencePiece ids on input instead of text.
Module creation
Instead of using only modules on tfhub.dev, there are ways to create own modules. This can be a useful tool for better ML codebase modularity and for further sharing.
Wrapping existing pre-trained embeddings
Text embedding module exporter - a tool to wrap an existing pre-trained embedding into a module. Shows how to include text pre-processing ops into the module. This allows to create a sentence embedding module from token embeddings.
Text embedding module exporter v2 - same as above, but compatible with TensorFlow 2 and eager execution.