
|
|
|
 View on GitHub View on GitHub
|
|
|
This tutorial demonstrates how to use a pretrained video classification model to classify an activity (such as dancing, swimming, biking etc) in the given video.
The model architecture used in this tutorial is called MoViNet (Mobile Video Networks). MoVieNets are a family of efficient video classification models trained on huge dataset (Kinetics 600).
In contrast to the i3d models available on TF Hub, MoViNets also support frame-by-frame inference on streaming video.
The pretrained models are available from TF Hub. The TF Hub collection also includes quantized models optimized for TFLite.
The source for these models is available in the TensorFlow Model Garden. This includes a longer version of this tutorial that also covers building and fine-tuning a MoViNet model.
This MoViNet tutorial is part of a series of TensorFlow video tutorials. Here are the other three tutorials:
- Load video data: This tutorial explains how to load and preprocess video data into a TensorFlow dataset pipeline from scratch.
- Build a 3D CNN model for video classification. Note that this tutorial uses a (2+1)D CNN that decomposes the spatial and temporal aspects of 3D data; if you are using volumetric data such as an MRI scan, consider using a 3D CNN instead of a (2+1)D CNN.
- Transfer learning for video classification with MoViNet: This tutorial explains how to use a pre-trained video classification model trained on a different dataset with the UCF-101 dataset.
Setup
For inference on smaller models (A0-A2), CPU is sufficient for this Colab.
sudo apt install -y ffmpegpip install -q mediapy
pip uninstall -q -y opencv-python-headlesspip install -q "opencv-python-headless<4.3"
# Import libraries
import pathlib
import matplotlib as mpl
import matplotlib.pyplot as plt
import mediapy as media
import numpy as np
import PIL
import tensorflow as tf
import tensorflow_hub as hub
import tqdm
mpl.rcParams.update({
'font.size': 10,
})
Get the kinetics 600 label list, and print the first few labels:
labels_path = tf.keras.utils.get_file(
fname='labels.txt',
origin='https://raw.githubusercontent.com/tensorflow/models/f8af2291cced43fc9f1d9b41ddbf772ae7b0d7d2/official/projects/movinet/files/kinetics_600_labels.txt'
)
labels_path = pathlib.Path(labels_path)
lines = labels_path.read_text().splitlines()
KINETICS_600_LABELS = np.array([line.strip() for line in lines])
KINETICS_600_LABELS[:20]
Downloading data from https://raw.githubusercontent.com/tensorflow/models/f8af2291cced43fc9f1d9b41ddbf772ae7b0d7d2/official/projects/movinet/files/kinetics_600_labels.txt
9209/9209 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step
array(['abseiling', 'acting in play', 'adjusting glasses', 'air drumming',
'alligator wrestling', 'answering questions', 'applauding',
'applying cream', 'archaeological excavation', 'archery',
'arguing', 'arm wrestling', 'arranging flowers',
'assembling bicycle', 'assembling computer',
'attending conference', 'auctioning', 'backflip (human)',
'baking cookies', 'bandaging'], dtype='<U49')
To provide a simple example video for classification, we can load a short gif of jumping jacks being performed.

Attribution: Footage shared by Coach Bobby Bluford on YouTube under the CC-BY license.
Download the gif.
jumpingjack_url = 'https://github.com/tensorflow/models/raw/f8af2291cced43fc9f1d9b41ddbf772ae7b0d7d2/official/projects/movinet/files/jumpingjack.gif'
jumpingjack_path = tf.keras.utils.get_file(
fname='jumpingjack.gif',
origin=jumpingjack_url,
cache_dir='.', cache_subdir='.',
)
Downloading data from https://github.com/tensorflow/models/raw/f8af2291cced43fc9f1d9b41ddbf772ae7b0d7d2/official/projects/movinet/files/jumpingjack.gif 783318/783318 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step
Define a function to read a gif file into a tf.Tensor:
# Read and process a video
def load_gif(file_path, image_size=(224, 224)):
"""Loads a gif file into a TF tensor.
Use images resized to match what's expected by your model.
The model pages say the "A2" models expect 224 x 224 images at 5 fps
Args:
file_path: path to the location of a gif file.
image_size: a tuple of target size.
Returns:
a video of the gif file
"""
# Load a gif file, convert it to a TF tensor
raw = tf.io.read_file(file_path)
video = tf.io.decode_gif(raw)
# Resize the video
video = tf.image.resize(video, image_size)
# change dtype to a float32
# Hub models always want images normalized to [0,1]
# ref: https://www.tensorflow.org/hub/common_signatures/images#input
video = tf.cast(video, tf.float32) / 255.
return video
The video's shape is (frames, height, width, colors)
jumpingjack=load_gif(jumpingjack_path)
jumpingjack.shape
2024-03-09 13:25:11.486732: E external/local_xla/xla/stream_executor/cuda/cuda_driver.cc:282] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected TensorShape([13, 224, 224, 3])
How to use the model
This section contains a walkthrough showing how to use the models from TensorFlow Hub. If you just want to see the models in action, skip to the next section.
There are two versions of each model: base and streaming.
- The
baseversion takes a video as input, and returns the probabilities averaged over the frames. - The
streamingversion takes a video frame and an RNN state as input, and returns the predictions for that frame, and the new RNN state.
The base model
Download the pretrained model from TensorFlow Hub.
%%time
id = 'a2'
mode = 'base'
version = '3'
hub_url = f'https://tfhub.dev/tensorflow/movinet/{id}/{mode}/kinetics-600/classification/{version}'
model = hub.load(hub_url)
CPU times: user 16.9 s, sys: 672 ms, total: 17.6 s Wall time: 18.1 s
This version of the model has one signature. It takes an image argument which is a tf.float32 with shape (batch, frames, height, width, colors). It returns a dictionary containing one output: A tf.float32 tensor of logits with shape (batch, classes).
sig = model.signatures['serving_default']
print(sig.pretty_printed_signature())
Input Parameters: image (KEYWORD_ONLY): TensorSpec(shape=(None, None, None, None, 3), dtype=tf.float32, name='image') Output Type: Dict[['classifier_head', TensorSpec(shape=(None, 600), dtype=tf.float32, name='classifier_head')]] Captures: 139759956646544: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748771568: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748779360: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748778656: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748779008: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956645840: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748778304: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748777248: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748777600: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748777952: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956646192: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748776896: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748775840: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748776544: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748776192: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956645136: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956644784: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956644432: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956644080: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956645488: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748750512: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748750160: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748749808: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748775488: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749250048: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749250400: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956034480: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956034128: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956025184: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956033776: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749249696: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748748400: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748748752: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748749456: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748749104: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749249344: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748746992: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748748048: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748747696: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748747344: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749248640: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749248288: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749247936: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749247584: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749248992: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749446656: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749446304: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749445952: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749447008: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749247232: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749246880: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749445248: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749444896: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749445600: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749444544: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749246528: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749443488: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749443136: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749444192: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749443840: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749241680: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749241328: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749240976: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749240624: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749242032: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749524656: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749524304: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749523952: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749523600: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749240272: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749239920: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749523248: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749522896: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749522544: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749522192: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749239568: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749521136: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749504352: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749521840: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749521488: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749238864: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749238512: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749201248: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749200896: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749239216: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749503296: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749502944: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749504000: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749503648: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749200192: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749200544: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956024832: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956024480: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956024128: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956023776: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749198080: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749502240: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749501888: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749501536: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749502592: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749197728: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749500480: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749487792: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749501184: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749500832: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749199840: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749199488: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749199136: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749198784: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749197376: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749486384: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749487440: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749487088: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749486736: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749198432: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749188784: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749484976: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749486032: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749485680: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749485328: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749188432: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749484272: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749463392: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749463040: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749484624: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749187728: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749187376: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749187024: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749186672: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749188080: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749461984: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749461632: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749462688: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749462336: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749186320: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749185968: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749460576: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749460224: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749461280: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749460928: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749185616: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749459872: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749459520: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749356720: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749356368: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749168480: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749168128: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749167776: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749167424: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749185264: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749355664: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749355312: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749354960: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749356016: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749167072: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749166720: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749353904: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749353552: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749354608: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749354256: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749166368: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749401600: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749401248: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749353200: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749401952: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749165664: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749165312: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749164960: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749164608: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749166016: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749400896: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749400544: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749400192: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749399840: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749098672: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749098320: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749399136: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749398784: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749398432: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749399488: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749097968: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749368656: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749368304: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749398080: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749369008: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749097264: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749096912: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749096560: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749096208: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749097616: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749366896: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749367952: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749367600: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749367248: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749095504: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749095856: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956023424: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956022368: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956023072: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956022720: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749095152: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749366192: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749365840: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749365488: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749366544: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749090656: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749335712: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749335360: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749336416: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749336064: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749089952: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749089600: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749089248: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749088896: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749090304: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749335008: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749334656: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749334304: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749333952: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749088544: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749088192: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749333600: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749333248: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749332896: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749332544: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749087840: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749434192: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749433840: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749433488: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749434544: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749087136: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749086784: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749037232: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749036880: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749087488: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749432432: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749432080: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749433136: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749432784: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749036528: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749036176: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749431024: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749410144: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749431728: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749431376: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749035824: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749409792: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749409440: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749409088: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749408736: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749035120: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749034768: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749034416: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749034064: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749035472: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749408032: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749407680: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749407328: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749408384: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749033712: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749107040: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749406272: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749385392: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749406976: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749406624: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749106688: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749383984: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749385040: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749384688: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749384336: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749105984: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749105632: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749105280: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749104928: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749106336: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749383632: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749383280: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749382928: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749382576: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749104576: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749020496: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749381872: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749381472: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749381120: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749382224: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749020144: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749380064: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749379712: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749380768: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749380416: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749104224: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749103872: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749103520: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749103168: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749019792: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749379360: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749379008: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749378656: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749378304: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749020848: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749019440: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749377952: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749377600: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956164272: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956163920: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749019088: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956163216: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956162864: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956162512: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956163568: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749018384: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749018032: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749017680: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749017328: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764749018736: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956161456: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956161104: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956162160: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956161808: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748910432: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748910080: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956155904: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956155552: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956160752: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956156256: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748909728: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956155200: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956154848: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956154496: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956154144: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748908320: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748907968: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748909024: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748908672: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748909376: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956153440: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956153088: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956152736: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956153792: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748907616: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748907264: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956147536: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956147184: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956152384: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956147888: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748906912: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956145776: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956146832: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956146480: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956146128: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748897968: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748897616: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748897264: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748896912: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748906560: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956145424: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956145072: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956144720: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956144368: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748896560: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748896208: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956131328: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956130976: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956130624: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956131680: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748895856: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956129568: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956129216: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956130272: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956129920: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748895152: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748894800: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748894448: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748902240: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748895504: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956128864: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956128512: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956128160: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956127808: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748901888: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748901536: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956135600: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956135248: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956134896: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956134544: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748901184: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956133840: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956133488: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956133136: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956134192: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748900480: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748900128: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748899776: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748899424: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748900832: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956132080: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956127584: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956132784: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956132432: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748899072: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748898720: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956126528: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956126176: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956127232: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956126880: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748898368: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956125824: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956125472: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956125120: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956124768: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748868944: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748868592: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748868240: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748867888: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748869296: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956124064: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956123712: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956102832: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956124416: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748867184: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748867536: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956176736: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956175856: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956022016: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956021664: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748866832: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956101424: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956102480: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956102128: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956101776: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748866480: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956101072: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956100720: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956100368: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956100016: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748865776: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748865376: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748865024: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748864672: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748866128: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956099312: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956094816: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956094464: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956099664: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748864320: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748863968: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956093408: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956093056: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956094112: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956093760: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748863616: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956092704: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956092352: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956092000: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956091648: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748862912: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748862560: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748862208: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748861856: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748863264: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956091296: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956090944: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956082352: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956082000: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748861504: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748834416: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956081296: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956080944: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956080592: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956081648: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748834064: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956079536: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956079184: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956080240: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956079888: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748836176: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748835824: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748835472: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748835120: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748836528: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956078832: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956062048: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956061696: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956061344: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748834768: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748833712: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956060992: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956060640: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956060288: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956059936: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748833360: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956059232: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956058880: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956058528: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956059584: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748803936: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748803584: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748803232: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748802880: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748833008: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956069360: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956058176: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956070064: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956069712: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748802528: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748802176: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956067952: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956069008: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956068656: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956068304: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748801824: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956067600: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956067248: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956066896: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956066544: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748801120: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748800768: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748800416: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748800064: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748801472: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956049408: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956049056: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956048704: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956049760: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748775088: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748774736: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956047648: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956047296: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956048352: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956048000: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748774384: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956046944: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956046592: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956046240: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956045888: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748773680: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748773328: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748772976: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748772624: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748774032: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956037296: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956036944: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956036592: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956036240: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748772272: TensorSpec(shape=(), dtype=tf.resource, name=None) 139764748771920: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956035536: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956035184: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956034832: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956035888: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956693056: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956647600: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956647248: TensorSpec(shape=(), dtype=tf.resource, name=None) 139759956646896: TensorSpec(shape=(), dtype=tf.resource, name=None)
To run this signature on the video you need to add the outer batch dimension to the video first.
#warmup
sig(image = jumpingjack[tf.newaxis, :1]);
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR I0000 00:00:1709990730.779735 50954 service.cc:145] XLA service 0x7f1ca4006300 initialized for platform Host (this does not guarantee that XLA will be used). Devices: I0000 00:00:1709990730.779797 50954 service.cc:153] StreamExecutor device (0): Host, Default Version I0000 00:00:1709990730.795362 50954 device_compiler.h:188] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
%%time
logits = sig(image = jumpingjack[tf.newaxis, ...])
logits = logits['classifier_head'][0]
print(logits.shape)
print()
(600,) CPU times: user 24.1 s, sys: 771 ms, total: 24.8 s Wall time: 14.4 s
Define a get_top_k function that packages the above output processing for later.
# Get top_k labels and probabilities
def get_top_k(probs, k=5, label_map=KINETICS_600_LABELS):
"""Outputs the top k model labels and probabilities on the given video.
Args:
probs: probability tensor of shape (num_frames, num_classes) that represents
the probability of each class on each frame.
k: the number of top predictions to select.
label_map: a list of labels to map logit indices to label strings.
Returns:
a tuple of the top-k labels and probabilities.
"""
# Sort predictions to find top_k
top_predictions = tf.argsort(probs, axis=-1, direction='DESCENDING')[:k]
# collect the labels of top_k predictions
top_labels = tf.gather(label_map, top_predictions, axis=-1)
# decode lablels
top_labels = [label.decode('utf8') for label in top_labels.numpy()]
# top_k probabilities of the predictions
top_probs = tf.gather(probs, top_predictions, axis=-1).numpy()
return tuple(zip(top_labels, top_probs))
Convert the logits to probabilities, and look up the top 5 classes for the video. The model confirms that the video is probably of jumping jacks.
probs = tf.nn.softmax(logits, axis=-1)
for label, p in get_top_k(probs):
print(f'{label:20s}: {p:.3f}')
jumping jacks : 0.834 zumba : 0.008 lunge : 0.003 doing aerobics : 0.003 polishing metal : 0.002
The streaming model
The previous section used a model that runs over a whole video. Often when processing a video you don't want a single prediction at the end, you want to update predictions frame by frame. The stream versions of the model allow you to do this.
Load the stream version of the model.
%%time
id = 'a2'
mode = 'stream'
version = '3'
hub_url = f'https://tfhub.dev/tensorflow/movinet/{id}/{mode}/kinetics-600/classification/{version}'
model = hub.load(hub_url)
WARNING:absl:`state/b1/l4/pool_frame_count` is not a valid tf.function parameter name. Sanitizing to `state_b1_l4_pool_frame_count`. WARNING:absl:`state/b3/l1/pool_buffer` is not a valid tf.function parameter name. Sanitizing to `state_b3_l1_pool_buffer`. WARNING:absl:`state/head/pool_buffer` is not a valid tf.function parameter name. Sanitizing to `state_head_pool_buffer`. WARNING:absl:`state/b1/l1/pool_buffer` is not a valid tf.function parameter name. Sanitizing to `state_b1_l1_pool_buffer`. WARNING:absl:`state/b4/l4/pool_buffer` is not a valid tf.function parameter name. Sanitizing to `state_b4_l4_pool_buffer`. CPU times: user 49.1 s, sys: 1.96 s, total: 51.1 s Wall time: 51.5 s
Using this model is slightly more complex than the base model. You have to keep track of the internal state of the model's RNNs.
list(model.signatures.keys())
['call', 'init_states']
The init_states signature takes the video's shape (batch, frames, height, width, colors) as input, and returns a large dictionary of tensors containing the initial RNN states:
lines = model.signatures['init_states'].pretty_printed_signature().splitlines()
lines = lines[:10]
lines.append(' ...')
print('.\n'.join(lines))
Input Parameters:.
input_shape (KEYWORD_ONLY): TensorSpec(shape=(5,), dtype=tf.int32, name='input_shape').
Output Type:.
Dict[['state/b3/l4/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b3/l4/pool_frame_count')], ['state/b4/l1/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 384), dtype=tf.float32, name='state/b4/l1/pool_buffer')], ['state/b4/l2/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 384), dtype=tf.float32, name='state/b4/l2/pool_buffer')], ['state/b4/l1/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b4/l1/pool_frame_count')], ['state/b2/l0/stream_buffer', TensorSpec(shape=(None, 4, None, None, 240), dtype=tf.float32, name='state/b2/l0/stream_buffer')], ['state/b0/l0/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 40), dtype=tf.float32, name='state/b0/l0/pool_buffer')], ['state/b2/l3/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 192), dtype=tf.float32, name='state/b2/l3/pool_buffer')], ['state/b3/l1/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b3/l1/pool_frame_count')], ['state/b1/l3/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b1/l3/pool_frame_count')], ['state/b0/l1/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 40), dtype=tf.float32, name='state/b0/l1/pool_buffer')], ['state/b3/l5/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b3/l5/pool_frame_count')], ['state/b2/l2/stream_buffer', TensorSpec(shape=(None, 2, None, None, 240), dtype=tf.float32, name='state/b2/l2/stream_buffer')], ['state/b4/l3/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 480), dtype=tf.float32, name='state/b4/l3/pool_buffer')], ['state/b4/l0/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 480), dtype=tf.float32, name='state/b4/l0/pool_buffer')], ['state/b0/l2/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 64), dtype=tf.float32, name='state/b0/l2/pool_buffer')], ['state/b1/l1/stream_buffer', TensorSpec(shape=(None, 2, None, None, 120), dtype=tf.float32, name='state/b1/l1/stream_buffer')], ['state/b3/l5/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 240), dtype=tf.float32, name='state/b3/l5/pool_buffer')], ['state/b4/l6/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 576), dtype=tf.float32, name='state/b4/l6/pool_buffer')], ['state/b4/l4/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b4/l4/pool_frame_count')], ['state/b3/l2/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b3/l2/pool_frame_count')], ['state/b3/l0/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 240), dtype=tf.float32, name='state/b3/l0/pool_buffer')], ['state/b1/l2/stream_buffer', TensorSpec(shape=(None, 2, None, None, 96), dtype=tf.float32, name='state/b1/l2/stream_buffer')], ['state/b2/l4/stream_buffer', TensorSpec(shape=(None, 2, None, None, 240), dtype=tf.float32, name='state/b2/l4/stream_buffer')], ['state/b2/l4/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 240), dtype=tf.float32, name='state/b2/l4/pool_buffer')], ['state/b4/l5/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b4/l5/pool_frame_count')], ['state/head/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/head/pool_frame_count')], ['state/b0/l2/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b0/l2/pool_frame_count')], ['state/b4/l6/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b4/l6/pool_frame_count')], ['state/b4/l5/stream_buffer', TensorSpec(shape=(None, 2, None, None, 480), dtype=tf.float32, name='state/b4/l5/stream_buffer')], ['state/b1/l3/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 96), dtype=tf.float32, name='state/b1/l3/pool_buffer')], ['state/b3/l0/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b3/l0/pool_frame_count')], ['state/b3/l3/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b3/l3/pool_frame_count')], ['state/b1/l4/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b1/l4/pool_frame_count')], ['state/b1/l2/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 96), dtype=tf.float32, name='state/b1/l2/pool_buffer')], ['state/b3/l1/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 240), dtype=tf.float32, name='state/b3/l1/pool_buffer')], ['state/b2/l1/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 160), dtype=tf.float32, name='state/b2/l1/pool_buffer')], ['state/b2/l3/stream_buffer', TensorSpec(shape=(None, 2, None, None, 192), dtype=tf.float32, name='state/b2/l3/stream_buffer')], ['state/b3/l1/stream_buffer', TensorSpec(shape=(None, 2, None, None, 240), dtype=tf.float32, name='state/b3/l1/stream_buffer')], ['state/b1/l1/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b1/l1/pool_frame_count')], ['state/b0/l1/stream_buffer', TensorSpec(shape=(None, 2, None, None, 40), dtype=tf.float32, name='state/b0/l1/stream_buffer')], ['state/b3/l3/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 240), dtype=tf.float32, name='state/b3/l3/pool_buffer')], ['state/b1/l4/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 120), dtype=tf.float32, name='state/b1/l4/pool_buffer')], ['state/b4/l4/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 480), dtype=tf.float32, name='state/b4/l4/pool_buffer')], ['state/b4/l2/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b4/l2/pool_frame_count')], ['state/b3/l5/stream_buffer', TensorSpec(shape=(None, 2, None, None, 240), dtype=tf.float32, name='state/b3/l5/stream_buffer')], ['state/b1/l0/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 96), dtype=tf.float32, name='state/b1/l0/pool_buffer')], ['state/b4/l0/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b4/l0/pool_frame_count')], ['state/b3/l2/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 240), dtype=tf.float32, name='state/b3/l2/pool_buffer')], ['state/b3/l0/stream_buffer', TensorSpec(shape=(None, 4, None, None, 240), dtype=tf.float32, name='state/b3/l0/stream_buffer')], ['state/b2/l2/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b2/l2/pool_frame_count')], ['state/b3/l2/stream_buffer', TensorSpec(shape=(None, 2, None, None, 240), dtype=tf.float32, name='state/b3/l2/stream_buffer')], ['state/b4/l0/stream_buffer', TensorSpec(shape=(None, 4, None, None, 480), dtype=tf.float32, name='state/b4/l0/stream_buffer')], ['state/b0/l1/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b0/l1/pool_frame_count')], ['state/b1/l3/stream_buffer', TensorSpec(shape=(None, 2, None, None, 96), dtype=tf.float32, name='state/b1/l3/stream_buffer')], ['state/b2/l1/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b2/l1/pool_frame_count')], ['state/b0/l2/stream_buffer', TensorSpec(shape=(None, 2, None, None, 64), dtype=tf.float32, name='state/b0/l2/stream_buffer')], ['state/b2/l0/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 240), dtype=tf.float32, name='state/b2/l0/pool_buffer')], ['state/b3/l3/stream_buffer', TensorSpec(shape=(None, 2, None, None, 240), dtype=tf.float32, name='state/b3/l3/stream_buffer')], ['state/b1/l4/stream_buffer', TensorSpec(shape=(None, 2, None, None, 120), dtype=tf.float32, name='state/b1/l4/stream_buffer')], ['state/b3/l4/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 144), dtype=tf.float32, name='state/b3/l4/pool_buffer')], ['state/b2/l3/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b2/l3/pool_frame_count')], ['state/b4/l5/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 480), dtype=tf.float32, name='state/b4/l5/pool_buffer')], ['state/b1/l0/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b1/l0/pool_frame_count')], ['state/b0/l0/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b0/l0/pool_frame_count')], ['state/b2/l2/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 240), dtype=tf.float32, name='state/b2/l2/pool_buffer')], ['state/b1/l2/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b1/l2/pool_frame_count')], ['state/b4/l3/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b4/l3/pool_frame_count')], ['state/b1/l0/stream_buffer', TensorSpec(shape=(None, 2, None, None, 96), dtype=tf.float32, name='state/b1/l0/stream_buffer')], ['state/head/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 640), dtype=tf.float32, name='state/head/pool_buffer')], ['state/b2/l0/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b2/l0/pool_frame_count')], ['state/b1/l1/pool_buffer', TensorSpec(shape=(None, 1, 1, 1, 120), dtype=tf.float32, name='state/b1/l1/pool_buffer')], ['state/b2/l4/pool_frame_count', TensorSpec(shape=(1,), dtype=tf.int32, name='state/b2/l4/pool_frame_count')], ['state/b2/l1/stream_buffer', TensorSpec(shape=(None, 2, None, None, 160), dtype=tf.float32, name='state/b2/l1/stream_buffer')]].
Captures:.
None.
...
initial_state = model.init_states(jumpingjack[tf.newaxis, ...].shape)
type(initial_state)
dict
list(sorted(initial_state.keys()))[:5]
['state/b0/l0/pool_buffer', 'state/b0/l0/pool_frame_count', 'state/b0/l1/pool_buffer', 'state/b0/l1/pool_frame_count', 'state/b0/l1/stream_buffer']
Once you have the initial state for the RNNs, you can pass the state and a video frame as input (keeping the (batch, frames, height, width, colors) shape for the video frame). The model returns a (logits, state) pair.
After just seeing the first frame, the model is not convinced that the video is of "jumping jacks":
inputs = initial_state.copy()
# Add the batch axis, take the first frme, but keep the frame-axis.
inputs['image'] = jumpingjack[tf.newaxis, 0:1, ...]
# warmup
model(inputs);
logits, new_state = model(inputs)
logits = logits[0]
probs = tf.nn.softmax(logits, axis=-1)
for label, p in get_top_k(probs):
print(f'{label:20s}: {p:.3f}')
print()
golf chipping : 0.427 tackling : 0.134 lunge : 0.056 stretching arm : 0.053 passing american football (not in game): 0.039
If you run the model in a loop, passing the updated state with each frame, the model quickly converges to the correct result:
%%time
state = initial_state.copy()
all_logits = []
for n in range(len(jumpingjack)):
inputs = state
inputs['image'] = jumpingjack[tf.newaxis, n:n+1, ...]
result, state = model(inputs)
all_logits.append(logits)
probabilities = tf.nn.softmax(all_logits, axis=-1)
CPU times: user 1.5 s, sys: 374 ms, total: 1.87 s Wall time: 696 ms
for label, p in get_top_k(probabilities[-1]):
print(f'{label:20s}: {p:.3f}')
golf chipping : 0.427 tackling : 0.134 lunge : 0.056 stretching arm : 0.053 passing american football (not in game): 0.039
id = tf.argmax(probabilities[-1])
plt.plot(probabilities[:, id])
plt.xlabel('Frame #')
plt.ylabel(f"p('{KINETICS_600_LABELS[id]}')");
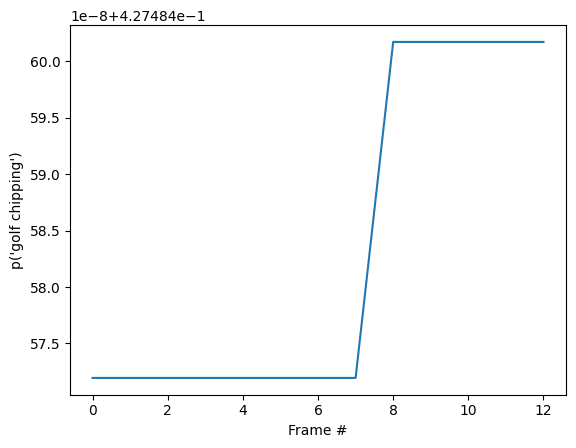
You may notice that the final probability is much more certain than in the previous section where you ran the base model. The base model returns an average of the predictions over the frames.
for label, p in get_top_k(tf.reduce_mean(probabilities, axis=0)):
print(f'{label:20s}: {p:.3f}')
golf chipping : 0.427 tackling : 0.134 lunge : 0.056 stretching arm : 0.053 passing american football (not in game): 0.039
Animate the predictions over time
The previous section went into some details about how to use these models. This section builds on top of that to produce some nice inference animations.
The hidden cell below to defines helper functions used in this section.
# Get top_k labels and probabilities predicted using MoViNets streaming model
def get_top_k_streaming_labels(probs, k=5, label_map=KINETICS_600_LABELS):
"""Returns the top-k labels over an entire video sequence.
Args:
probs: probability tensor of shape (num_frames, num_classes) that represents
the probability of each class on each frame.
k: the number of top predictions to select.
label_map: a list of labels to map logit indices to label strings.
Returns:
a tuple of the top-k probabilities, labels, and logit indices
"""
top_categories_last = tf.argsort(probs, -1, 'DESCENDING')[-1, :1]
# Sort predictions to find top_k
categories = tf.argsort(probs, -1, 'DESCENDING')[:, :k]
categories = tf.reshape(categories, [-1])
counts = sorted([
(i.numpy(), tf.reduce_sum(tf.cast(categories == i, tf.int32)).numpy())
for i in tf.unique(categories)[0]
], key=lambda x: x[1], reverse=True)
top_probs_idx = tf.constant([i for i, _ in counts[:k]])
top_probs_idx = tf.concat([top_categories_last, top_probs_idx], 0)
# find unique indices of categories
top_probs_idx = tf.unique(top_probs_idx)[0][:k+1]
# top_k probabilities of the predictions
top_probs = tf.gather(probs, top_probs_idx, axis=-1)
top_probs = tf.transpose(top_probs, perm=(1, 0))
# collect the labels of top_k predictions
top_labels = tf.gather(label_map, top_probs_idx, axis=0)
# decode the top_k labels
top_labels = [label.decode('utf8') for label in top_labels.numpy()]
return top_probs, top_labels, top_probs_idx
# Plot top_k predictions at a given time step
def plot_streaming_top_preds_at_step(
top_probs,
top_labels,
step=None,
image=None,
legend_loc='lower left',
duration_seconds=10,
figure_height=500,
playhead_scale=0.8,
grid_alpha=0.3):
"""Generates a plot of the top video model predictions at a given time step.
Args:
top_probs: a tensor of shape (k, num_frames) representing the top-k
probabilities over all frames.
top_labels: a list of length k that represents the top-k label strings.
step: the current time step in the range [0, num_frames].
image: the image frame to display at the current time step.
legend_loc: the placement location of the legend.
duration_seconds: the total duration of the video.
figure_height: the output figure height.
playhead_scale: scale value for the playhead.
grid_alpha: alpha value for the gridlines.
Returns:
A tuple of the output numpy image, figure, and axes.
"""
# find number of top_k labels and frames in the video
num_labels, num_frames = top_probs.shape
if step is None:
step = num_frames
# Visualize frames and top_k probabilities of streaming video
fig = plt.figure(figsize=(6.5, 7), dpi=300)
gs = mpl.gridspec.GridSpec(8, 1)
ax2 = plt.subplot(gs[:-3, :])
ax = plt.subplot(gs[-3:, :])
# display the frame
if image is not None:
ax2.imshow(image, interpolation='nearest')
ax2.axis('off')
# x-axis (frame number)
preview_line_x = tf.linspace(0., duration_seconds, num_frames)
# y-axis (top_k probabilities)
preview_line_y = top_probs
line_x = preview_line_x[:step+1]
line_y = preview_line_y[:, :step+1]
for i in range(num_labels):
ax.plot(preview_line_x, preview_line_y[i], label=None, linewidth='1.5',
linestyle=':', color='gray')
ax.plot(line_x, line_y[i], label=top_labels[i], linewidth='2.0')
ax.grid(which='major', linestyle=':', linewidth='1.0', alpha=grid_alpha)
ax.grid(which='minor', linestyle=':', linewidth='0.5', alpha=grid_alpha)
min_height = tf.reduce_min(top_probs) * playhead_scale
max_height = tf.reduce_max(top_probs)
ax.vlines(preview_line_x[step], min_height, max_height, colors='red')
ax.scatter(preview_line_x[step], max_height, color='red')
ax.legend(loc=legend_loc)
plt.xlim(0, duration_seconds)
plt.ylabel('Probability')
plt.xlabel('Time (s)')
plt.yscale('log')
fig.tight_layout()
fig.canvas.draw()
data = np.frombuffer(fig.canvas.tostring_rgb(), dtype=np.uint8)
data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
plt.close()
figure_width = int(figure_height * data.shape[1] / data.shape[0])
image = PIL.Image.fromarray(data).resize([figure_width, figure_height])
image = np.array(image)
return image
# Plotting top_k predictions from MoViNets streaming model
def plot_streaming_top_preds(
probs,
video,
top_k=5,
video_fps=25.,
figure_height=500,
use_progbar=True):
"""Generates a video plot of the top video model predictions.
Args:
probs: probability tensor of shape (num_frames, num_classes) that represents
the probability of each class on each frame.
video: the video to display in the plot.
top_k: the number of top predictions to select.
video_fps: the input video fps.
figure_fps: the output video fps.
figure_height: the height of the output video.
use_progbar: display a progress bar.
Returns:
A numpy array representing the output video.
"""
# select number of frames per second
video_fps = 8.
# select height of the image
figure_height = 500
# number of time steps of the given video
steps = video.shape[0]
# estimate duration of the video (in seconds)
duration = steps / video_fps
# estimate top_k probabilities and corresponding labels
top_probs, top_labels, _ = get_top_k_streaming_labels(probs, k=top_k)
images = []
step_generator = tqdm.trange(steps) if use_progbar else range(steps)
for i in step_generator:
image = plot_streaming_top_preds_at_step(
top_probs=top_probs,
top_labels=top_labels,
step=i,
image=video[i],
duration_seconds=duration,
figure_height=figure_height,
)
images.append(image)
return np.array(images)
Start by running the streaming model across the frames of the video, and collecting the logits:
init_states = model.init_states(jumpingjack[tf.newaxis].shape)
# Insert your video clip here
video = jumpingjack
images = tf.split(video[tf.newaxis], video.shape[0], axis=1)
all_logits = []
# To run on a video, pass in one frame at a time
states = init_states
for image in tqdm.tqdm(images):
# predictions for each frame
logits, states = model({**states, 'image': image})
all_logits.append(logits)
# concatenating all the logits
logits = tf.concat(all_logits, 0)
# estimating probabilities
probs = tf.nn.softmax(logits, axis=-1)
100%|██████████| 13/13 [00:00<00:00, 18.92it/s]
final_probs = probs[-1]
print('Top_k predictions and their probablities\n')
for label, p in get_top_k(final_probs):
print(f'{label:20s}: {p:.3f}')
Top_k predictions and their probablities jumping jacks : 0.999 zumba : 0.000 doing aerobics : 0.000 dancing charleston : 0.000 slacklining : 0.000
Convert the sequence of probabilities into a video:
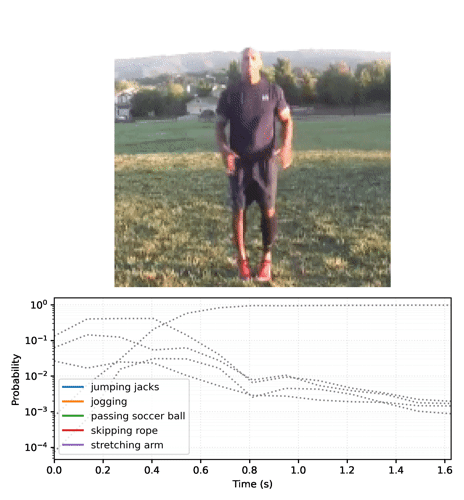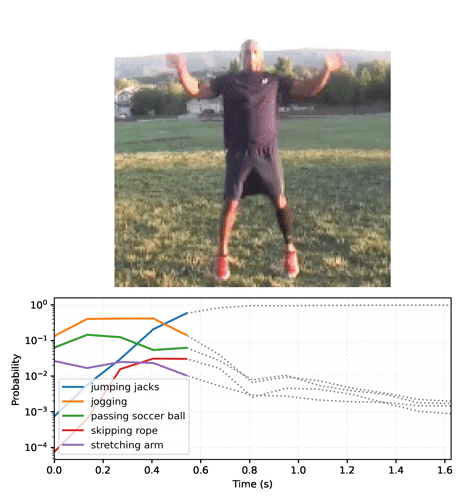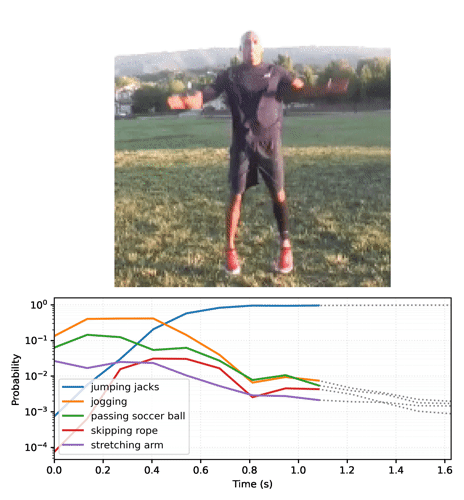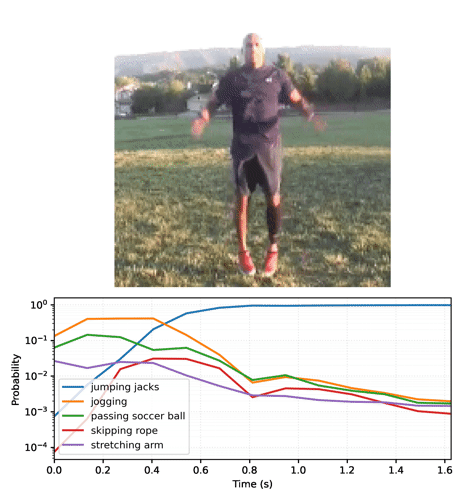
# Generate a plot and output to a video tensor
plot_video = plot_streaming_top_preds(probs, video, video_fps=8.)
0%| | 0/13 [00:00<?, ?it/s]/tmpfs/tmp/ipykernel_50732/567636217.py:112: MatplotlibDeprecationWarning: The tostring_rgb function was deprecated in Matplotlib 3.8 and will be removed two minor releases later. Use buffer_rgba instead. data = np.frombuffer(fig.canvas.tostring_rgb(), dtype=np.uint8) 100%|██████████| 13/13 [00:06<00:00, 1.88it/s]
# For gif format, set codec='gif'
media.show_video(plot_video, fps=3)
Resources
The pretrained models are available from TF Hub. The TF Hub collection also includes quantized models optimized for TFLite.
The source for these models is available in the TensorFlow Model Garden. This includes a longer version of this tutorial that also covers building and fine-tuning a MoViNet model.
Next Steps
To learn more about working with video data in TensorFlow, check out the following tutorials: