
 GitHub でソースを表示{ GitHub でソースを表示{ |
概要
このチュートリアルは、TensorFlow Lattice(TFL)ライブラリが提供する制約と正規化の概要です。ここでは、合成データセットに TFL 缶詰 Estimator を使用しますが、このチュートリアルの内容は TFL Keras レイヤーから構築されたモデルでも実行できます。
続行する前に、ランタイムに必要なすべてのパッケージがインストールされていることを確認してください(以下のコードセルでインポートされるとおりに行います)。
セットアップ
TF Lattice パッケージをインストールします。
pip install -q tensorflow-lattice必要なパッケージをインポートします。
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
このガイドで使用されるデフォルト値です。
NUM_EPOCHS = 500
BATCH_SIZE = 64
LEARNING_RATE=0.001
レストランのランク付けに使用するトレーニングデータセット
ユーザーがレストランの検索結果をクリックするかどうかを判定する、単純なシナリオを想定しましょう。このタスクでは、次の特定の入力特徴量でクリック率(CTR)を予測します。
- 平均評価(
avg_rating): [1,5] の範囲の値による数値特徴量。 - レビュー数(
num_reviews): 最大値 200 の数値特徴量。流行状況の測定値として使用します。 - ドル記号評価(
dollar_rating): {"D", "DD", "DDD", "DDDD"} セットの文字列値による分類特徴量。
ここでは、真の CTR を式 \( CTR = 1 / (1 + exp{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 }) \) で得る合成データセットを作成します。\(b(\cdot)\) は各 dollar_rating をベースラインの値 \( \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \) に変換します。
この式は、典型的なユーザーパターンを反映します。たとえば、ほかのすべてが固定された状態で、ユーザーは星評価の高いレストランを好み、"$$" のレストランは "$" のレストランよりも多いクリック率を得、"$$$"、"$$$$" となればさらに多いクリック率を得るというパターンです。
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
この CTR 関数の等高線図を見てみましょう。
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
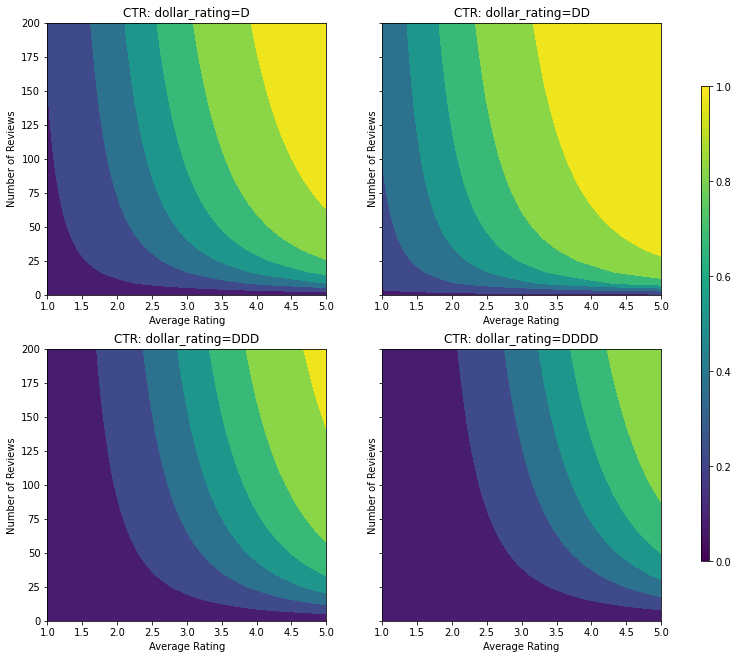
データを準備する
次に、合成データセットを作成する必要があります。シミュレーション済みのレストランのデータセットとその特徴量を生成するところから始めます。
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
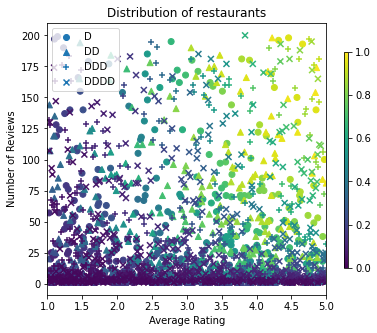
トレーニング、評価、およびテストデータセットを生成しましょう。検索結果でレストランが閲覧されるときに、ユーザーのエンゲージメント(クリック有りまたはクリック無し)をサンプルポイントとして記録できます。
実際には、ユーザーが全検索結果を見ることはほとんどありません。つまり、ユーザーは、使用されている現在のランキングモデルによってすでに「良い」とみなされているレストランのみを閲覧する傾向にあるでしょう。そのため、トレーニングデータセットでは「良い」レストランはより頻繁に表示されて、過剰表現されます。さらに多くの特徴量を使用する際に、トレーニングデータセットでは、特徴量空間の「悪い」部分に大きなギャップが生じてしまいます。
モデルがランキングに使用される場合、トレーニングデータセットで十分に表現されていないより均一な分布を持つ、すべての関連結果で評価されることがほとんどです。この場合、過剰に表現されたデータポイントの過適合によって一般化可能性に欠けることから、柔軟で複雑なモデルは失敗する可能性があります。この問題には、トレーニングデータセットから形状制約を拾えない場合に合理的な予測を立てられるようにモデルを誘導する形状制約を追加するドメインナレッジを適用して対処します。
この例では、トレーニングデータセットは、人気のある良いレストランとのユーザーインタラクションで構成されており、テストデータセットには、上記で説明した評価設定をシミュレーションする一様分布があります。このようなテストデータセットは、実際の問題設定では利用できないことに注意してください。
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(2000, testing_set=False)
data_val = sample_dataset(1000, testing_set=False)
data_test = sample_dataset(1000, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)

トレーニングと評価に使用する input_fn を定義します。
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
勾配ブースティング木を適合させる
まずは、avg_rating と num_reviews の 2 つの特徴量から始めましょう。
検証とテストのメトリックを描画および計算する補助関数をいくつか作成します。
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
データセットに TensorFlow 勾配ブースティング決定木を適合できます。
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=3,
n_trees=20,
min_node_weight=0.1,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.7248634099960327 Testing AUC: 0.6980500817298889
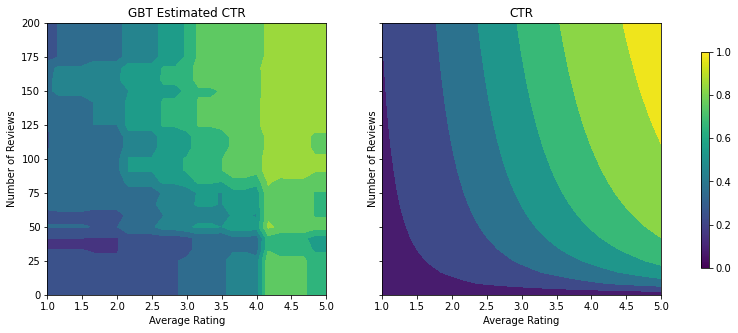
モデルは本来の CTR の一般的な形状をキャプチャし、まともな検証メトリックを使用していますが、入力空間のいくつかの部分に直感に反する振る舞いがあります。推定される CTR は平均評価またはレビュー数が増加するにつれ降下しているところです。これは、トレーニングデータセットがうまくカバーしていない領域のサンプルポイントが不足しているためです。単に、モデルにはデータのみから正しい振る舞いを推測する術がないのです。
この問題を解決するには、モデルが平均評価とレビュー数の両方に対して単調的に増加する値を出力しなければならないように、形状制約を強制します。TFL にこれを実装する方法は、後で説明します。
DNN を適合させる
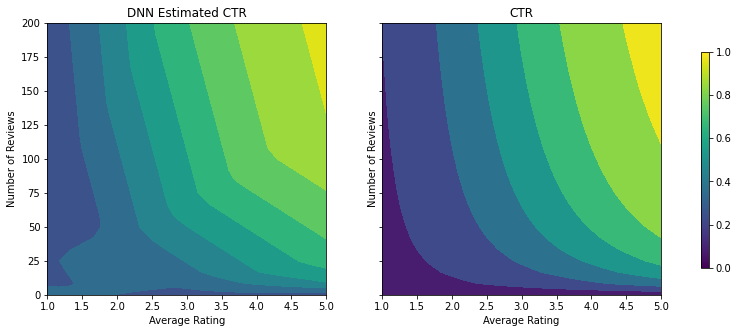
DNN 分類器で、同じ手順を繰り返すことができます。レビュー数が少なく、十分なサンプルポイントがないため、同様の、意味をなさない外挿パターンとなります。検証メトリックが木のソリューションより優れていても、テストメトリックが悪化するところに注意してください。
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.7519322633743286 Testing AUC: 0.7452506422996521
形状制約
TensorFlow Lattice(TFL)の焦点は、トレーニングデータを超えてモデルの振る舞いを守るために形状制約を強制することに当てられます。形状制約は TFL Keras レイヤーに適用されます。その詳細は、TensorFlow の JMLR 論文をご覧ください。
このチュートリアルでは、TF 缶詰 Estimator を使用してさまざまな形状制約を説明しますが、手順はすべて、TFL Keras レイヤーから作成されたモデルで実行することができます。
ほかの TensorFlow Estimator と同様に、TFL 缶詰 Estimator では、特徴量カラムを使用して入力形式を定義し、トレーニングの input_fn を使用してデータを渡します。TFL 缶詰 Estimator を使用するには、次の項目も必要です。
- モデルの構成: モデルのアーキテクチャと特徴量ごとの形状制約とレギュラライザを定義します。
- 特徴量分析 input_fn: TFL 初期化を行うために TF input_fn でデータを渡します。
より詳しい説明については、缶詰 Estimator のチュートリアルまたは API ドキュメントをご覧ください。
単調性
最初に、単調性形状制約を両方の特徴量に追加して、単調性に関する問題を解決します。
TFL に形状制約を強制するように指示するには、特徴量の構成に制約を指定します。次のコードは、monotonicity="increasing" を設定することによって、num_reviews と avg_rating の両方に対して単調的に出力を増加するようにする方法を示します。
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
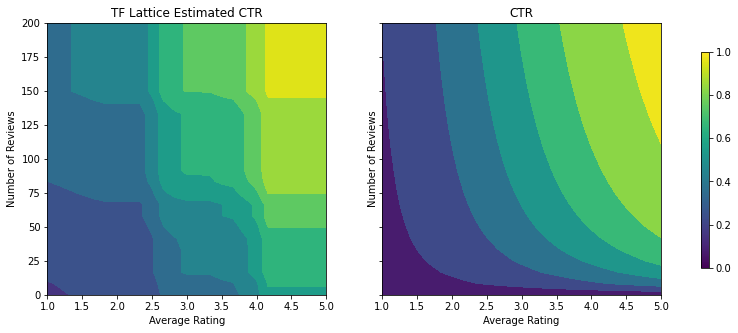
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.7401219606399536 Testing AUC: 0.7358466982841492
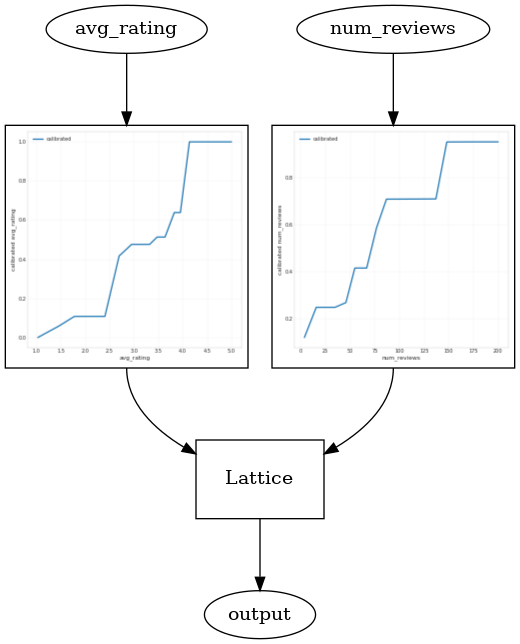
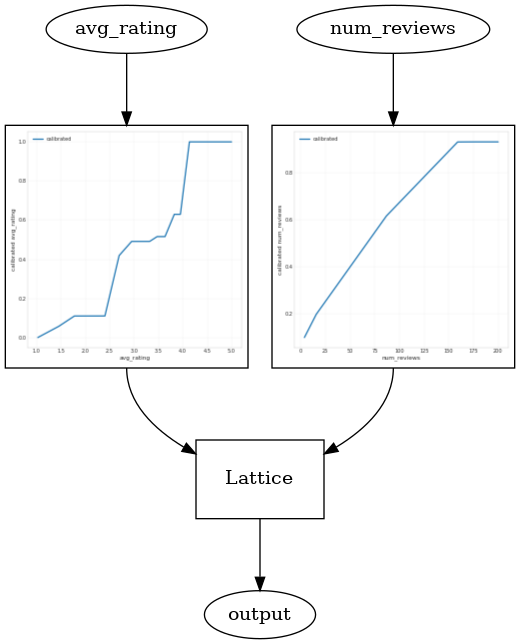
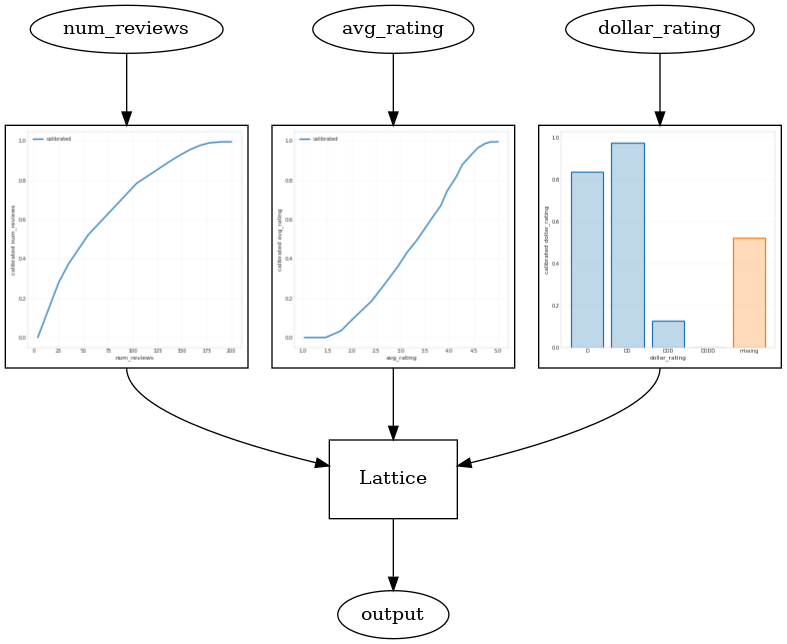
CalibratedLatticeConfig を使用して、各入力にキャリブレータを適用(数値特徴量のピース単位の線形関数)してから格子レイヤーを適用して非線形的に較正済みの特徴量を融合する缶詰分類器を作成します。モデルの視覚化には、tfl.visualization を使用できます。特に、次のプロットは、缶詰分類器に含まれるトレーニング済みのキャリブレータを示します。
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)
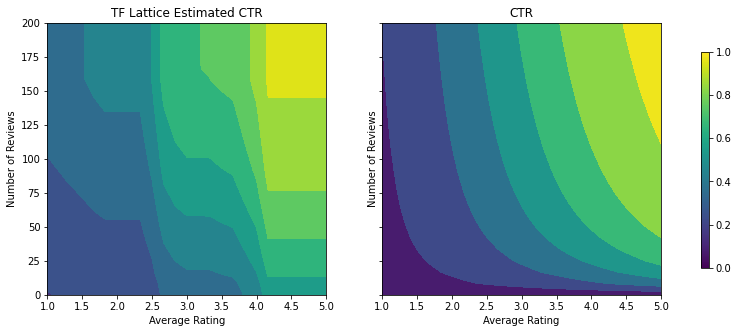
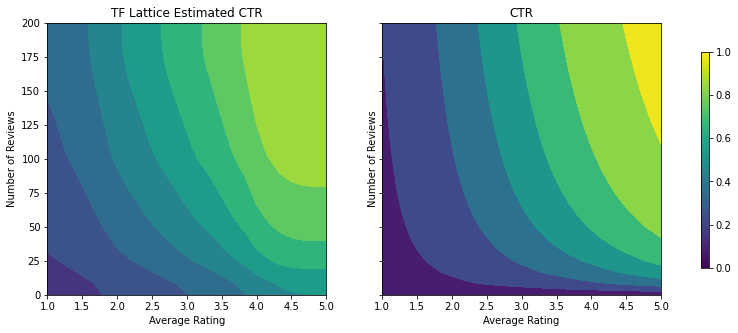
制約が追加されると、推定される CTR は平均評価またはレビュー数が増加するにつれて、必ず増加するようになります。これは、キャリブレータと格子を確実に単調にすることで行われます。
収穫逓減
収穫逓減とは、特定の特徴量値を増加すると、それを高める上で得る限界利益は減少することを意味します。このケースでは、num_reviews 特徴慮はこのパターンに従うと予測されるため、それに合わせてキャリブレータを構成することができます。収穫逓減を次の 2 つの十分な条件に分けることができます。
- キャリブレータが単調的に増加している
- キャリブレータが凹状である
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7388392686843872 Testing AUC: 0.7402855753898621
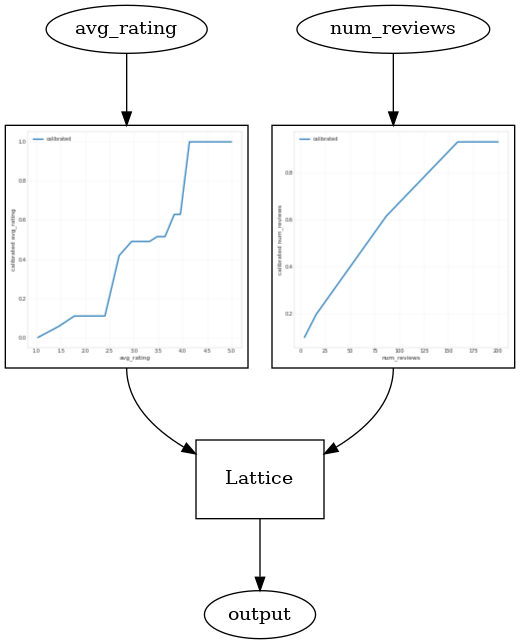
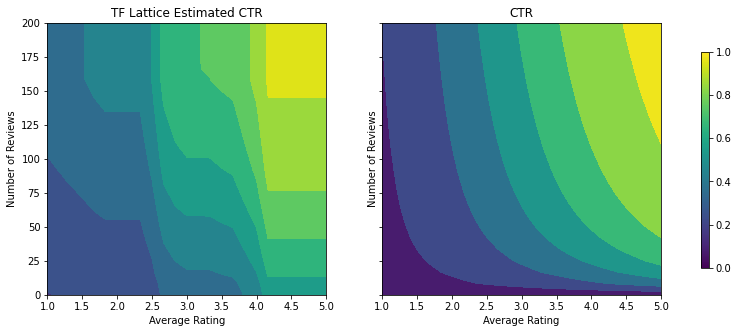
テストメトリックが、凹状の制約を追加することで改善しているのがわかります。予測図もグラウンドトゥルースにより似通っています。
2D 形状制約: 信頼
1 つか 2 つのレビューのみを持つレストランの 5 つ星評価は、信頼できない評価である可能性があります(レストランは実際には良くない可能性があります)が、数百件のレビューのあるレストランの 4 つ星評価にははるかに高い信頼性があります(この場合、レストランは良い可能性があります)。レストランのレビュー数によって平均評価にどれほどの信頼を寄せるかが変化することを見ることができます。
ある特徴量のより大きな(または小さな)値が別の特徴量の高い信頼性を示すことをモデルに指示する TFL 信頼制約を訓練することができます。これは、特徴量の構成で、reflects_trust_in 構成を設定することで実行できます。
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7388392686843872 Testing AUC: 0.7402815222740173
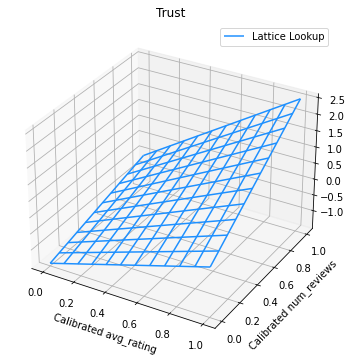
次の図は、トレーニング済みの格子関数を示します。信頼制約により、較正済みの num_reviews のより大きな値によって、較正済みの avg_rating に対してより高い勾配が強制され、格子出力により大きな変化が生じることが期待されます。
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
キャリブレータを平滑化する
では、avg_rating のキャリブレータを見てみましょう。単調的に上昇してはいますが、勾配の変化は突然起こっており、解釈が困難です。そのため、regularizer_configs にレギュラライザーをセットアップして、このキャリブレータを平滑化したいと思います。
ここでは、反りの変化を縮減するために wrinkle レギュラライザを適用します。また、laplacian レギュラライザを使用してキャリブレータを平らにし、hessian レギュラライザを使用してより線形にします。
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7513659596443176 Testing AUC: 0.7543530464172363
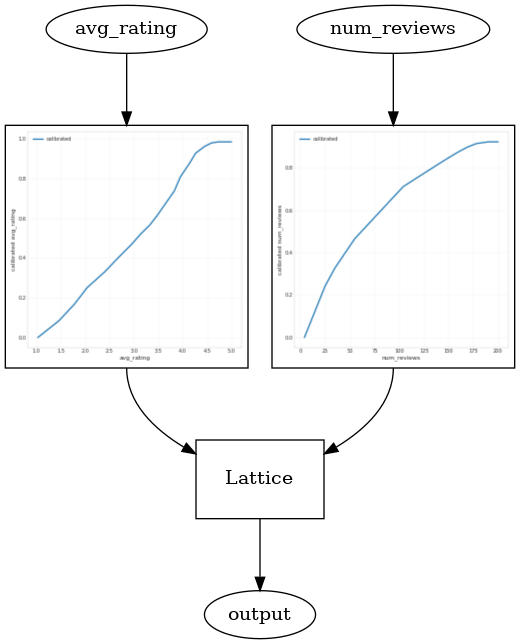
キャリブレータがスムーズになり、全体的な推定 CTR がグラウンドトゥルースにより一致するように改善されました。これは、テストメトリックと等高線図の両方に反映されます。
分類較正の部分単調性
これまで、モデルには 2 つの数値特徴量のみを使用してきました。ここでは、分類較正レイヤーを使用した 3 つ目の特徴量を追加します。もう一度、描画とメトリック計算用のヘルパー関数のセットアップから始めます。
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
3 つ目の特徴量である dollar_rating を追加するには、TFL での分類特徴量の取り扱いは、特徴量カラムと特徴量構成の両方においてわずかに異なることを思い出してください。ここでは、ほかのすべての特徴量が固定されている場合に、"DD" レストランの出力が "D" よりも大きくなるように、部分単調性を強制します。これは、特徴量構成の monotonicity 設定を使用して行います。
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.8138159513473511 Testing AUC: 0.8294155597686768
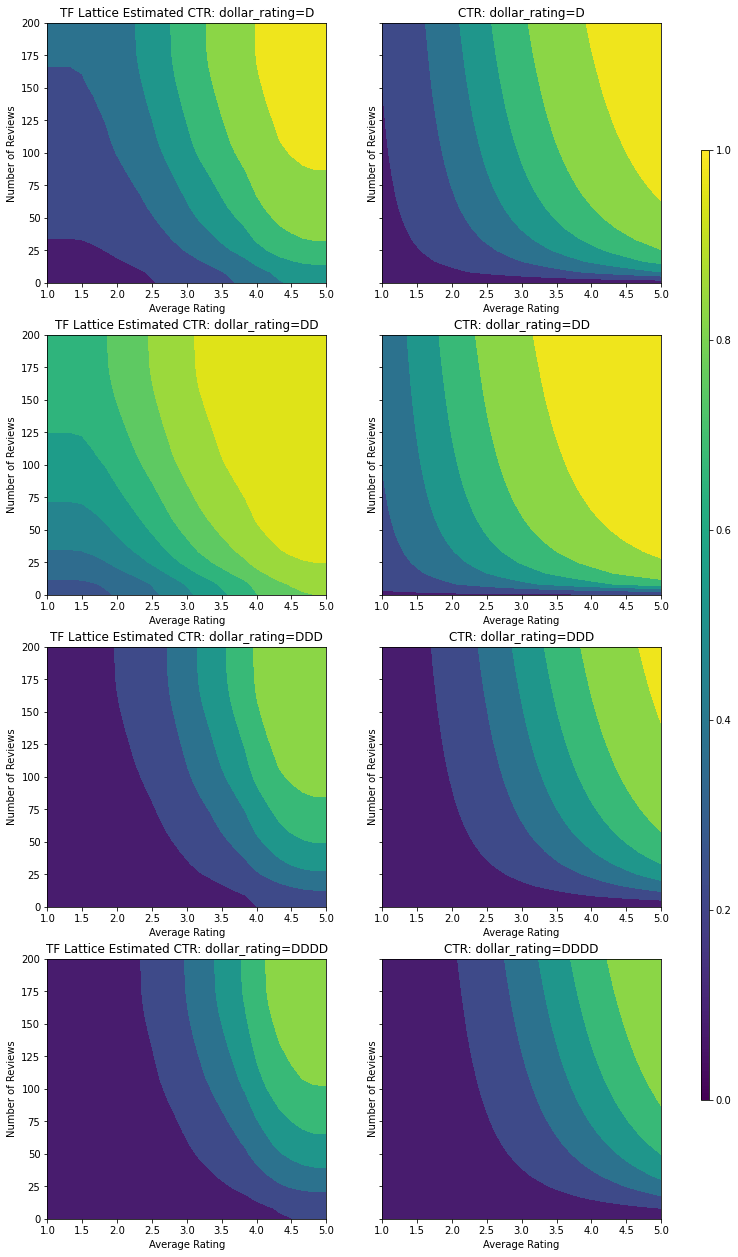
この分類キャリブレータは、DD > D > DDD > DDDD というモデル出力の優先を示します。このセットアップではこれらは定数です。欠落する値のカラムもあることに注意してください。このチュートリアルのトレーニングデータとテストデータには欠落した特徴量はありませんが、ダウンストリームでモデルが使用される場合に値の欠落が生じたときには、モデルは欠損値の帰属を提供します。
ここでは、dollar_rating で条件付けされたモデルの予測 CTR も描画します。必要なすべての制約が各スライスで満たされているところに注意してください。
出力較正
ここまでトレーニングしてきたすべての TFL モデルでは、格子レイヤー(モデルグラフで "Lattice" と示される部分)はモデル予測を直接出力しますが、格子出力をスケーリングし直してモデル出力を送信すべきかわからないことがたまにあります。
- 特徴量が \(log\) カウントでラベルがカウントである。
- 格子は頂点をほとんど使用しないように構成されているが、ラベル分布は比較的複雑である。
こういった場合には、格子出力とモデル出力の間に別のキャリブレータを追加して、モデルの柔軟性を高めることができます。ここでは、今作成したモデルにキーポイントを 5 つ使用したキャリブレータレイヤーを追加することにしましょう。また、出力キャリブレータのレギュラライザも追加して、関数の平滑性を維持します。
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.813232958316803 Testing AUC: 0.8300531506538391
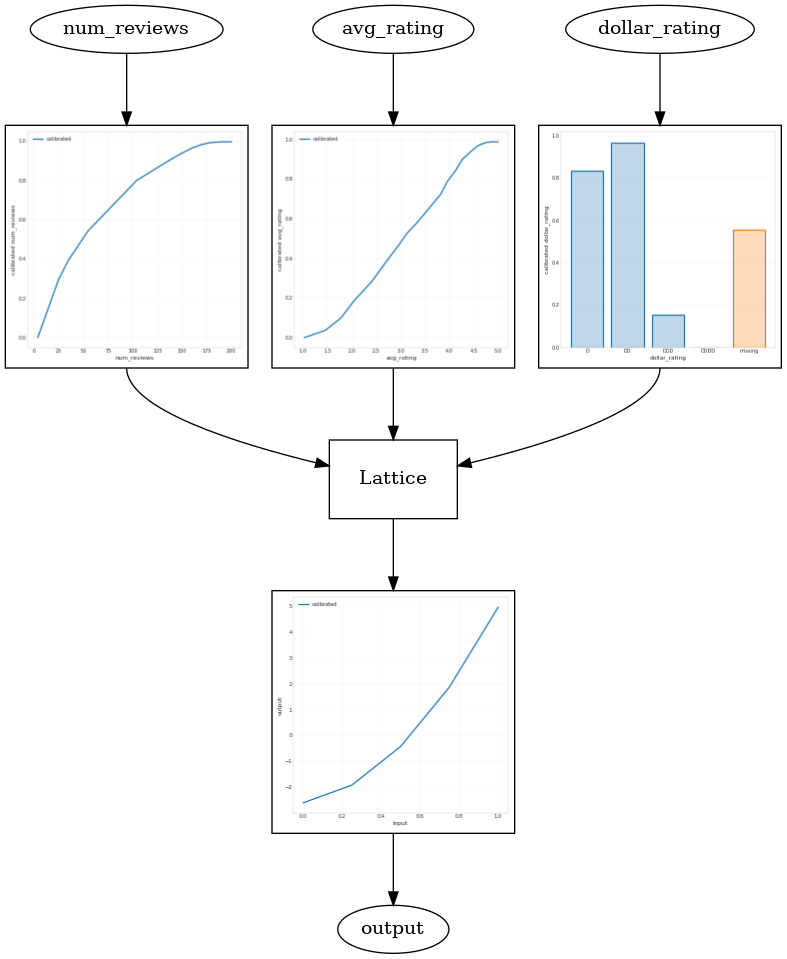
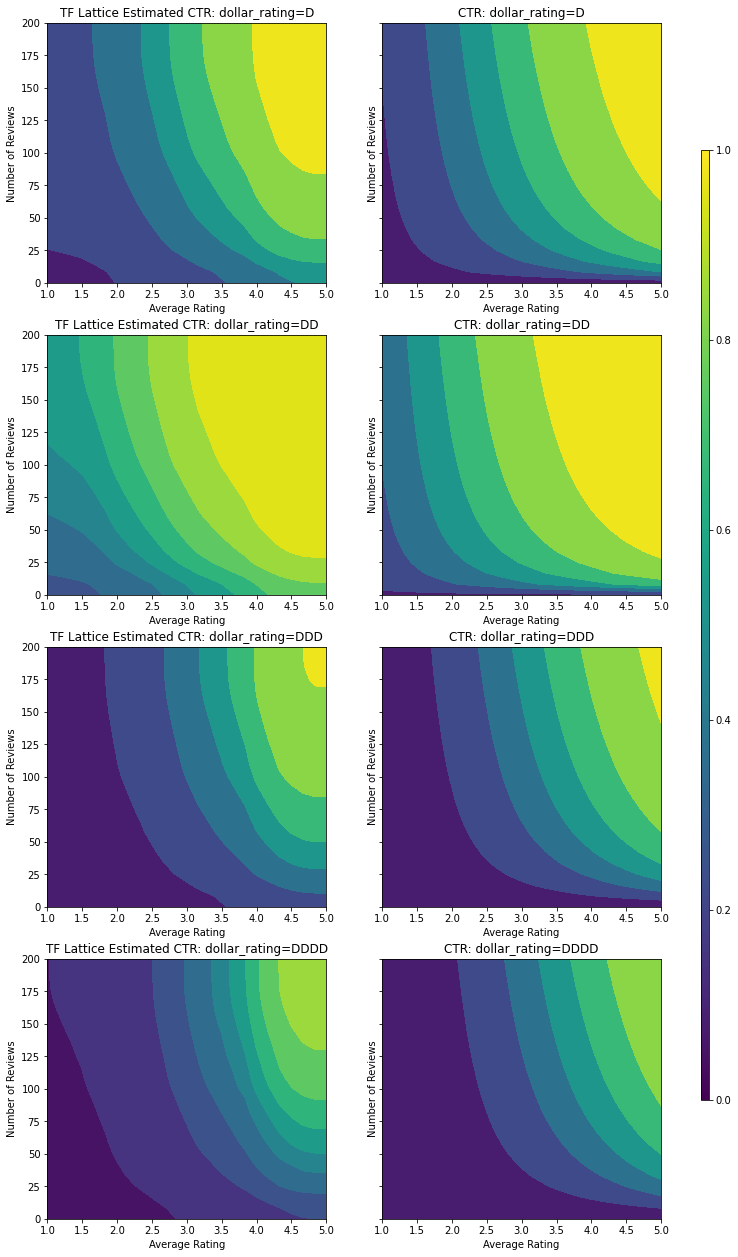
最後のテストメトリックとプロットは、常識的な制約を使用することで、モデルが予期しない振る舞いを回避して全体的な入力空間の外挿をいかに改善できるかを示します。