

La tarea de identificar lo que representa un audio se denomina clasificación de audio . Un modelo de clasificación de audio está entrenado para reconocer varios eventos de audio. Por ejemplo, puede entrenar a un modelo para que reconozca eventos que representan tres eventos diferentes: aplausos, chasquidos de dedos y escritura. TensorFlow Lite proporciona modelos optimizados previamente entrenados que puede implementar en sus aplicaciones móviles. Obtén más información sobre la clasificación de audio con TensorFlow aquí .
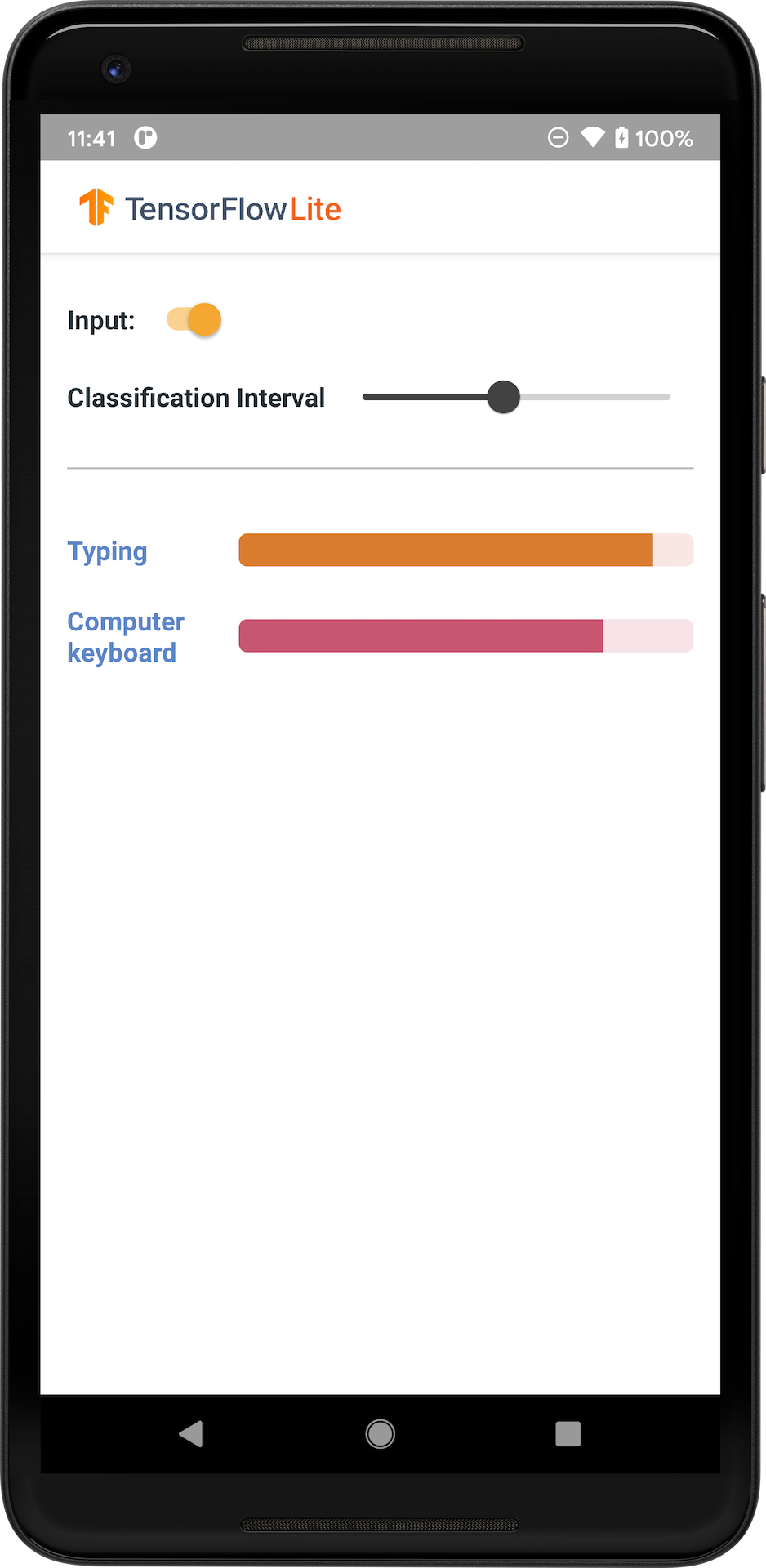
La siguiente imagen muestra la salida del modelo de clasificación de audio en Android.
Empezar
Si es nuevo en TensorFlow Lite y está trabajando con Android, le recomendamos explorar las siguientes aplicaciones de ejemplo que pueden ayudarlo a comenzar.
Puede aprovechar la API lista para usar de la biblioteca de tareas de TensorFlow Lite para integrar modelos de clasificación de audio en solo unas pocas líneas de código. También puede crear su propia canalización de inferencia personalizada con la biblioteca de compatibilidad de TensorFlow Lite .
El siguiente ejemplo de Android demuestra la implementación utilizando la biblioteca de tareas TFLite
Si usa una plataforma que no sea Android/iOS, o si ya está familiarizado con las API de TensorFlow Lite , descargue el modelo de inicio y los archivos de soporte (si corresponde).
Descarga el modelo inicial de TensorFlow Hub
Descripcion del modelo
YAMNet es un clasificador de eventos de audio que toma la forma de onda de audio como entrada y realiza predicciones independientes para cada uno de los 521 eventos de audio de la ontología AudioSet . El modelo usa la arquitectura MobileNet v1 y fue entrenado usando el corpus AudioSet. Este modelo se lanzó originalmente en TensorFlow Model Garden, donde se encuentra el código fuente del modelo, el punto de control del modelo original y documentación más detallada.
Cómo funciona
Hay dos versiones del modelo YAMNet convertido a TFLite:
YAMNet es el modelo de clasificación de audio original, con tamaño de entrada dinámico, adecuado para transferencia de aprendizaje, implementación web y móvil. También tiene una salida más compleja.
YAMNet/clasificación es una versión cuantificada con una entrada de cuadro de longitud fija más simple (15600 muestras) y devuelve un único vector de puntuaciones para 521 clases de eventos de audio.
Entradas
El modelo acepta una matriz 1-D float32 Tensor o NumPy de longitud 15600 que contiene una forma de onda de 0,975 segundos representada como muestras mono de 16 kHz en el rango [-1.0, +1.0] .
Salidas
El modelo devuelve un tensor 2-D float32 de forma (1, 521) que contiene las puntuaciones predichas para cada una de las 521 clases en la ontología AudioSet que son compatibles con YAMNet. El índice de columna (0-520) del tensor de puntajes se asigna al nombre de clase de AudioSet correspondiente utilizando el mapa de clase de YAMNet, que está disponible como un archivo asociado yamnet_label_list.txt empaquetado en el archivo modelo. Vea a continuación para el uso.
Usos adecuados
Se puede utilizar YAMNet
- como un clasificador de eventos de audio independiente que proporciona una línea de base razonable en una amplia variedad de eventos de audio.
- como un extractor de funciones de alto nivel: la salida integrada 1024-D de YAMNet se puede usar como las funciones de entrada de otro modelo que luego se puede entrenar con una pequeña cantidad de datos para una tarea en particular. Esto permite crear rápidamente clasificadores de audio especializados sin requerir una gran cantidad de datos etiquetados y sin tener que entrenar un modelo grande de principio a fin.
- como un buen comienzo: los parámetros del modelo YAMNet se pueden usar para inicializar parte de un modelo más grande, lo que permite un ajuste más rápido y una exploración del modelo.
Limitaciones
- Las salidas del clasificador de YAMNet no se han calibrado entre clases, por lo que no puede tratar directamente las salidas como probabilidades. Para cualquier tarea determinada, es muy probable que necesite realizar una calibración con datos específicos de la tarea que le permitan asignar escalas y umbrales de puntuación adecuados por clase.
- YAMNet se ha capacitado en millones de videos de YouTube y, aunque estos son muy diversos, aún puede haber una discrepancia de dominio entre el video promedio de YouTube y las entradas de audio esperadas para una tarea determinada. Debería esperar realizar algunos ajustes y calibraciones para que YAMNet se pueda utilizar en cualquier sistema que construya.
Personalización del modelo
Los modelos preentrenados provistos están entrenados para detectar 521 clases de audio diferentes. Para obtener una lista completa de clases, consulte el archivo de etiquetas en el repositorio de modelos .
Puede usar una técnica conocida como transferencia de aprendizaje para volver a entrenar un modelo para que reconozca las clases que no están en el conjunto original. Por ejemplo, podría volver a entrenar el modelo para detectar varios cantos de pájaros. Para hacer esto, necesitará un conjunto de audios de entrenamiento para cada una de las nuevas etiquetas que desea entrenar. La forma recomendada es usar la biblioteca Model Maker de TensorFlow Lite , que simplifica el proceso de entrenamiento de un modelo de TensorFlow Lite con un conjunto de datos personalizado, en unas pocas líneas de códigos. Utiliza el aprendizaje por transferencia para reducir la cantidad de datos y tiempo de capacitación requeridos. También puede aprender de Transferencia de aprendizaje para el reconocimiento de audio como un ejemplo de transferencia de aprendizaje.
Más lecturas y recursos
Utilice los siguientes recursos para obtener más información sobre los conceptos relacionados con la clasificación de audio: