
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Este tutorial demuestra cómo preprocesar archivos de audio en formato WAV y crear y entrenar un modelo básico de reconocimiento automático de voz (ASR) para reconocer diez palabras diferentes. Utilizará una parte del conjunto de datos de Comandos de voz ( Warden, 2018 ), que contiene clips de audio breves (de un segundo o menos) de comandos, como "abajo", "ir", "izquierda", "no", " derecha", "stop", "arriba" y "sí".
Los sistemas de reconocimiento de voz y audio del mundo real son complejos. Pero, al igual que la clasificación de imágenes con el conjunto de datos MNIST , este tutorial debería brindarle una comprensión básica de las técnicas involucradas.
Configuración
Importe los módulos y dependencias necesarios. Tenga en cuenta que utilizará seaborn para la visualización en este tutorial.
import os
import pathlib
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
from IPython import display
# Set the seed value for experiment reproducibility.
seed = 42
tf.random.set_seed(seed)
np.random.seed(seed)
Importar el conjunto de datos de mini comandos de voz
Para ahorrar tiempo con la carga de datos, trabajará con una versión más pequeña del conjunto de datos de comandos de voz. El conjunto de datos original consta de más de 105 000 archivos de audio en formato de archivo de audio WAV (Waveform) de personas que dicen 35 palabras diferentes. Estos datos fueron recopilados por Google y publicados bajo una licencia CC BY.
Descargue y extraiga el archivo mini_speech_commands.zip que contiene los conjuntos de datos de comandos de voz más pequeños con tf.keras.utils.get_file :
DATASET_PATH = 'data/mini_speech_commands'
data_dir = pathlib.Path(DATASET_PATH)
if not data_dir.exists():
tf.keras.utils.get_file(
'mini_speech_commands.zip',
origin="http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip",
extract=True,
cache_dir='.', cache_subdir='data')
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip 182083584/182082353 [==============================] - 1s 0us/step 182091776/182082353 [==============================] - 1s 0us/step
Los clips de audio del conjunto de datos se almacenan en ocho carpetas correspondientes a cada comando de voz: no , yes , down , go , left , up , right y stop :
commands = np.array(tf.io.gfile.listdir(str(data_dir)))
commands = commands[commands != 'README.md']
print('Commands:', commands)
Commands: ['stop' 'left' 'no' 'go' 'yes' 'down' 'right' 'up']
Extraiga los clips de audio en una lista llamada filenames de archivo y mezcle:
filenames = tf.io.gfile.glob(str(data_dir) + '/*/*')
filenames = tf.random.shuffle(filenames)
num_samples = len(filenames)
print('Number of total examples:', num_samples)
print('Number of examples per label:',
len(tf.io.gfile.listdir(str(data_dir/commands[0]))))
print('Example file tensor:', filenames[0])
Number of total examples: 8000 Number of examples per label: 1000 Example file tensor: tf.Tensor(b'data/mini_speech_commands/yes/db72a474_nohash_0.wav', shape=(), dtype=string)
Divida los nombres de filenames en conjuntos de entrenamiento, validación y prueba utilizando una proporción de 80:10:10, respectivamente:
train_files = filenames[:6400]
val_files = filenames[6400: 6400 + 800]
test_files = filenames[-800:]
print('Training set size', len(train_files))
print('Validation set size', len(val_files))
print('Test set size', len(test_files))
Training set size 6400 Validation set size 800 Test set size 800
Leer los archivos de audio y sus etiquetas.
En esta sección, preprocesará el conjunto de datos, creando tensores decodificados para las formas de onda y las etiquetas correspondientes. Tenga en cuenta que:
- Cada archivo WAV contiene datos de series temporales con un número determinado de muestras por segundo.
- Cada muestra representa la amplitud de la señal de audio en ese momento específico.
- En un sistema de 16 bits , como los archivos WAV en el conjunto de datos mini Speech Commands, los valores de amplitud oscilan entre -32 768 y 32 767.
- La frecuencia de muestreo para este conjunto de datos es de 16 kHz.
La forma del tensor devuelto por tf.audio.decode_wav es [samples, channels] , donde channels son 1 para mono o 2 para estéreo. El conjunto de datos de mini comandos de voz solo contiene grabaciones mono.
test_file = tf.io.read_file(DATASET_PATH+'/down/0a9f9af7_nohash_0.wav')
test_audio, _ = tf.audio.decode_wav(contents=test_file)
test_audio.shape
TensorShape([13654, 1])
Ahora, definamos una función que preprocesa los archivos de audio WAV sin procesar del conjunto de datos en tensores de audio:
def decode_audio(audio_binary):
# Decode WAV-encoded audio files to `float32` tensors, normalized
# to the [-1.0, 1.0] range. Return `float32` audio and a sample rate.
audio, _ = tf.audio.decode_wav(contents=audio_binary)
# Since all the data is single channel (mono), drop the `channels`
# axis from the array.
return tf.squeeze(audio, axis=-1)
Defina una función que cree etiquetas usando los directorios principales para cada archivo:
- Divida las rutas de archivo en
tf.RaggedTensors (tensores con dimensiones irregulares, con sectores que pueden tener diferentes longitudes).
def get_label(file_path):
parts = tf.strings.split(
input=file_path,
sep=os.path.sep)
# Note: You'll use indexing here instead of tuple unpacking to enable this
# to work in a TensorFlow graph.
return parts[-2]
Defina otra función auxiliar, get_waveform_and_label , que lo integre todo:
- La entrada es el nombre del archivo de audio WAV.
- La salida es una tupla que contiene el audio y los tensores de etiquetas listos para el aprendizaje supervisado.
def get_waveform_and_label(file_path):
label = get_label(file_path)
audio_binary = tf.io.read_file(file_path)
waveform = decode_audio(audio_binary)
return waveform, label
Cree el conjunto de entrenamiento para extraer los pares de etiquetas de audio:
- Cree un
tf.data.DatasetconDataset.from_tensor_slicesyDataset.map, usandoget_waveform_and_labeldefinido anteriormente.
Construirá los conjuntos de validación y prueba usando un procedimiento similar más adelante.
AUTOTUNE = tf.data.AUTOTUNE
files_ds = tf.data.Dataset.from_tensor_slices(train_files)
waveform_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
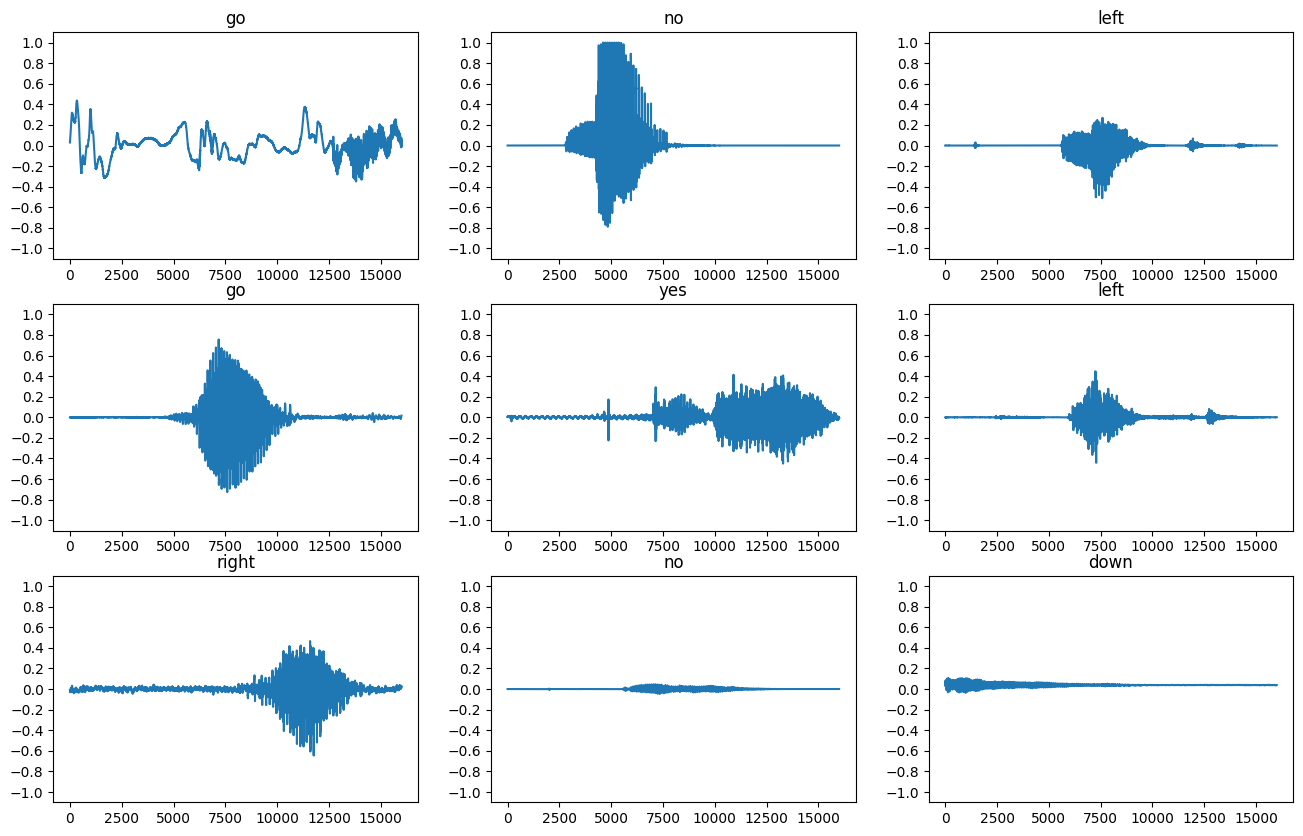
Tracemos algunas formas de onda de audio:
rows = 3
cols = 3
n = rows * cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 12))
for i, (audio, label) in enumerate(waveform_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
ax.plot(audio.numpy())
ax.set_yticks(np.arange(-1.2, 1.2, 0.2))
label = label.numpy().decode('utf-8')
ax.set_title(label)
plt.show()
Convertir formas de onda en espectrogramas
Las formas de onda en el conjunto de datos se representan en el dominio del tiempo. A continuación, transformará las formas de onda de las señales de dominio de tiempo en señales de dominio de frecuencia de tiempo mediante el cálculo de la transformada de Fourier de tiempo corto (STFT) para convertir las formas de onda en espectrogramas , que muestran los cambios de frecuencia a lo largo del tiempo y pueden ser representados como imágenes 2D. Introducirá las imágenes del espectrograma en su red neuronal para entrenar el modelo.
Una transformada de Fourier ( tf.signal.fft ) convierte una señal a las frecuencias de sus componentes, pero pierde toda la información de tiempo. En comparación, STFT ( tf.signal.stft ) divide la señal en ventanas de tiempo y ejecuta una transformada de Fourier en cada ventana, preservando parte de la información de tiempo y devolviendo un tensor 2D en el que puede ejecutar convoluciones estándar.
Cree una función de utilidad para convertir formas de onda en espectrogramas:
- Las formas de onda deben tener la misma longitud, de modo que cuando las convierta en espectrogramas, los resultados tengan dimensiones similares. Esto se puede hacer simplemente rellenando con ceros los clips de audio que son más cortos que un segundo (usando
tf.zeros). - Al llamar a
tf.signal.stft, elija los parámetrosframe_lengthyframe_stepmodo que la "imagen" del espectrograma generado sea casi cuadrada. Para obtener más información sobre la elección de los parámetros STFT, consulte este video de Coursera sobre el procesamiento de señales de audio y STFT. - La STFT produce una serie de números complejos que representan la magnitud y la fase. Sin embargo, en este tutorial solo usará la magnitud, que puede derivar aplicando
tf.absen la salida detf.signal.stft.
def get_spectrogram(waveform):
# Zero-padding for an audio waveform with less than 16,000 samples.
input_len = 16000
waveform = waveform[:input_len]
zero_padding = tf.zeros(
[16000] - tf.shape(waveform),
dtype=tf.float32)
# Cast the waveform tensors' dtype to float32.
waveform = tf.cast(waveform, dtype=tf.float32)
# Concatenate the waveform with `zero_padding`, which ensures all audio
# clips are of the same length.
equal_length = tf.concat([waveform, zero_padding], 0)
# Convert the waveform to a spectrogram via a STFT.
spectrogram = tf.signal.stft(
equal_length, frame_length=255, frame_step=128)
# Obtain the magnitude of the STFT.
spectrogram = tf.abs(spectrogram)
# Add a `channels` dimension, so that the spectrogram can be used
# as image-like input data with convolution layers (which expect
# shape (`batch_size`, `height`, `width`, `channels`).
spectrogram = spectrogram[..., tf.newaxis]
return spectrogram
A continuación, comience a explorar los datos. Imprima las formas de la forma de onda tensionada de un ejemplo y el espectrograma correspondiente, y reproduzca el audio original:
for waveform, label in waveform_ds.take(1):
label = label.numpy().decode('utf-8')
spectrogram = get_spectrogram(waveform)
print('Label:', label)
print('Waveform shape:', waveform.shape)
print('Spectrogram shape:', spectrogram.shape)
print('Audio playback')
display.display(display.Audio(waveform, rate=16000))
Label: yes Waveform shape: (16000,) Spectrogram shape: (124, 129, 1) Audio playback
Ahora, defina una función para mostrar un espectrograma:
def plot_spectrogram(spectrogram, ax):
if len(spectrogram.shape) > 2:
assert len(spectrogram.shape) == 3
spectrogram = np.squeeze(spectrogram, axis=-1)
# Convert the frequencies to log scale and transpose, so that the time is
# represented on the x-axis (columns).
# Add an epsilon to avoid taking a log of zero.
log_spec = np.log(spectrogram.T + np.finfo(float).eps)
height = log_spec.shape[0]
width = log_spec.shape[1]
X = np.linspace(0, np.size(spectrogram), num=width, dtype=int)
Y = range(height)
ax.pcolormesh(X, Y, log_spec)
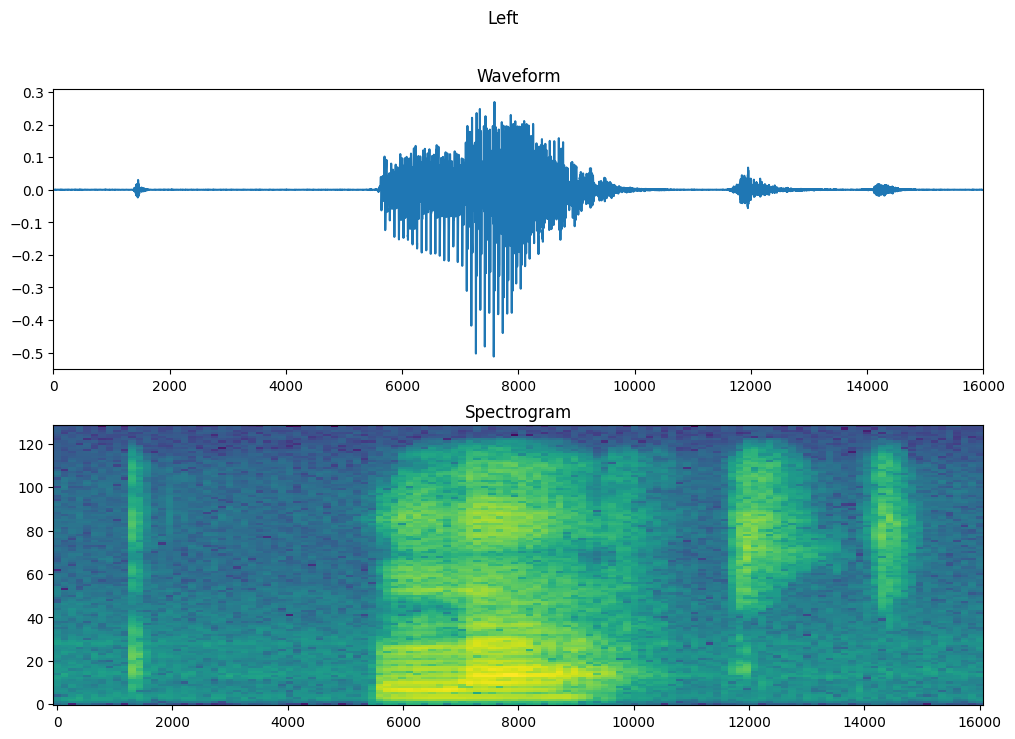
Trace la forma de onda del ejemplo a lo largo del tiempo y el espectrograma correspondiente (frecuencias a lo largo del tiempo):
fig, axes = plt.subplots(2, figsize=(12, 8))
timescale = np.arange(waveform.shape[0])
axes[0].plot(timescale, waveform.numpy())
axes[0].set_title('Waveform')
axes[0].set_xlim([0, 16000])
plot_spectrogram(spectrogram.numpy(), axes[1])
axes[1].set_title('Spectrogram')
plt.show()
Ahora, defina una función que transforme el conjunto de datos de forma de onda en espectrogramas y sus etiquetas correspondientes como ID de números enteros:
def get_spectrogram_and_label_id(audio, label):
spectrogram = get_spectrogram(audio)
label_id = tf.argmax(label == commands)
return spectrogram, label_id
Asigne get_spectrogram_and_label_id a través de los elementos del conjunto de datos con Dataset.map :
spectrogram_ds = waveform_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
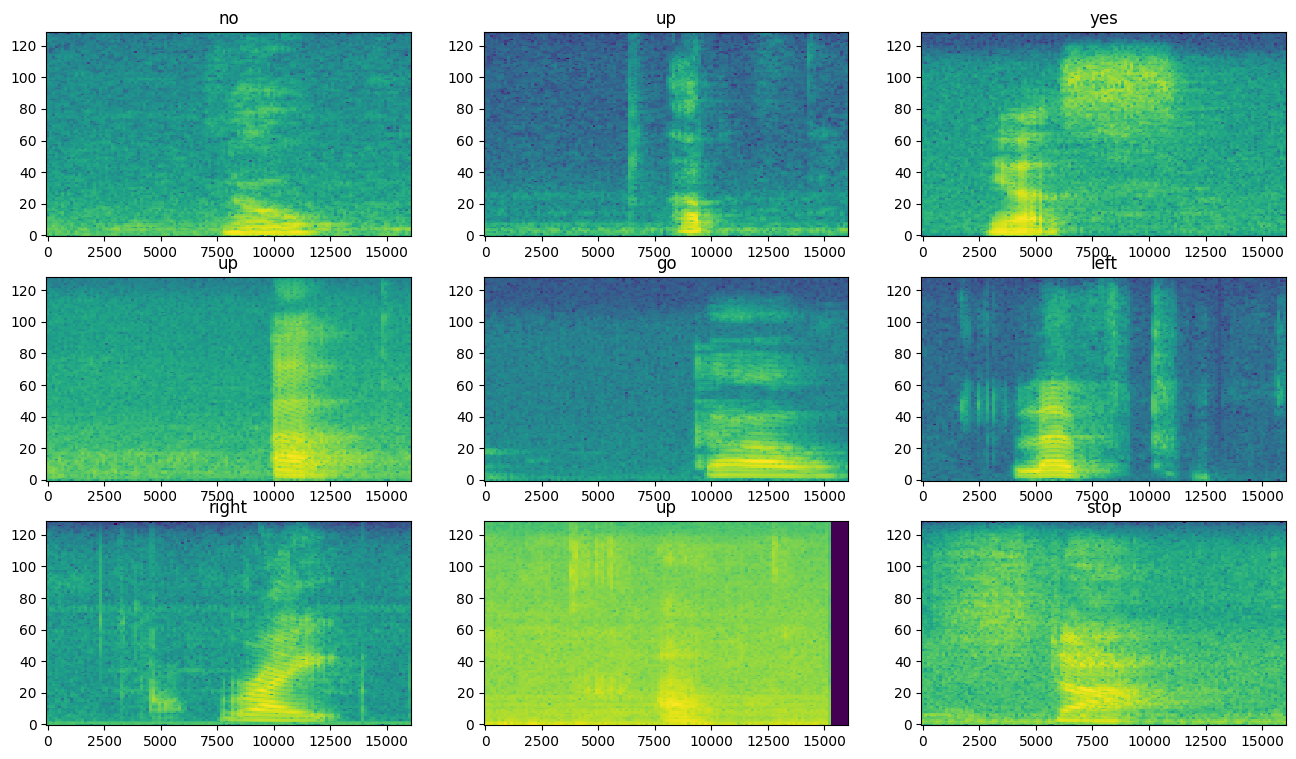
Examine los espectrogramas para ver diferentes ejemplos del conjunto de datos:
rows = 3
cols = 3
n = rows*cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 10))
for i, (spectrogram, label_id) in enumerate(spectrogram_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
plot_spectrogram(spectrogram.numpy(), ax)
ax.set_title(commands[label_id.numpy()])
ax.axis('off')
plt.show()
Construir y entrenar el modelo.
Repita el preprocesamiento del conjunto de entrenamiento en los conjuntos de validación y prueba:
def preprocess_dataset(files):
files_ds = tf.data.Dataset.from_tensor_slices(files)
output_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
output_ds = output_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
return output_ds
train_ds = spectrogram_ds
val_ds = preprocess_dataset(val_files)
test_ds = preprocess_dataset(test_files)
Agrupe los conjuntos de entrenamiento y validación para el entrenamiento del modelo:
batch_size = 64
train_ds = train_ds.batch(batch_size)
val_ds = val_ds.batch(batch_size)
Agregue las operaciones Dataset.cache y Dataset.prefetch para reducir la latencia de lectura mientras entrena el modelo:
train_ds = train_ds.cache().prefetch(AUTOTUNE)
val_ds = val_ds.cache().prefetch(AUTOTUNE)
Para el modelo, utilizará una red neuronal convolucional (CNN) simple, ya que ha transformado los archivos de audio en imágenes de espectrograma.
Su modelo tf.keras.Sequential utilizará las siguientes capas de preprocesamiento de Keras:
-
tf.keras.layers.Resizing: para reducir la muestra de la entrada y permitir que el modelo se entrene más rápido. -
tf.keras.layers.Normalization: para normalizar cada píxel de la imagen en función de su media y desviación estándar.
Para la capa de Normalization , primero se necesitaría llamar a su método de adapt en los datos de entrenamiento para calcular las estadísticas agregadas (es decir, la media y la desviación estándar).
for spectrogram, _ in spectrogram_ds.take(1):
input_shape = spectrogram.shape
print('Input shape:', input_shape)
num_labels = len(commands)
# Instantiate the `tf.keras.layers.Normalization` layer.
norm_layer = layers.Normalization()
# Fit the state of the layer to the spectrograms
# with `Normalization.adapt`.
norm_layer.adapt(data=spectrogram_ds.map(map_func=lambda spec, label: spec))
model = models.Sequential([
layers.Input(shape=input_shape),
# Downsample the input.
layers.Resizing(32, 32),
# Normalize.
norm_layer,
layers.Conv2D(32, 3, activation='relu'),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.5),
layers.Dense(num_labels),
])
model.summary()
Input shape: (124, 129, 1)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
resizing (Resizing) (None, 32, 32, 1) 0
normalization (Normalizatio (None, 32, 32, 1) 3
n)
conv2d (Conv2D) (None, 30, 30, 32) 320
conv2d_1 (Conv2D) (None, 28, 28, 64) 18496
max_pooling2d (MaxPooling2D (None, 14, 14, 64) 0
)
dropout (Dropout) (None, 14, 14, 64) 0
flatten (Flatten) (None, 12544) 0
dense (Dense) (None, 128) 1605760
dropout_1 (Dropout) (None, 128) 0
dense_1 (Dense) (None, 8) 1032
=================================================================
Total params: 1,625,611
Trainable params: 1,625,608
Non-trainable params: 3
_________________________________________________________________
Configure el modelo de Keras con el optimizador de Adam y la pérdida de entropía cruzada:
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'],
)
Entrene el modelo durante 10 épocas con fines de demostración:
EPOCHS = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=EPOCHS,
callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=2),
)
Epoch 1/10 100/100 [==============================] - 6s 41ms/step - loss: 1.7503 - accuracy: 0.3630 - val_loss: 1.2850 - val_accuracy: 0.5763 Epoch 2/10 100/100 [==============================] - 0s 5ms/step - loss: 1.2101 - accuracy: 0.5698 - val_loss: 0.9314 - val_accuracy: 0.6913 Epoch 3/10 100/100 [==============================] - 0s 5ms/step - loss: 0.9336 - accuracy: 0.6703 - val_loss: 0.7529 - val_accuracy: 0.7325 Epoch 4/10 100/100 [==============================] - 0s 5ms/step - loss: 0.7503 - accuracy: 0.7397 - val_loss: 0.6721 - val_accuracy: 0.7713 Epoch 5/10 100/100 [==============================] - 0s 5ms/step - loss: 0.6367 - accuracy: 0.7741 - val_loss: 0.6061 - val_accuracy: 0.7975 Epoch 6/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5650 - accuracy: 0.7987 - val_loss: 0.5489 - val_accuracy: 0.8125 Epoch 7/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5099 - accuracy: 0.8183 - val_loss: 0.5344 - val_accuracy: 0.8238 Epoch 8/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4560 - accuracy: 0.8392 - val_loss: 0.5194 - val_accuracy: 0.8288 Epoch 9/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4101 - accuracy: 0.8547 - val_loss: 0.4809 - val_accuracy: 0.8388 Epoch 10/10 100/100 [==============================] - 0s 5ms/step - loss: 0.3905 - accuracy: 0.8589 - val_loss: 0.4973 - val_accuracy: 0.8363
Tracemos las curvas de pérdida de entrenamiento y validación para verificar cómo ha mejorado su modelo durante el entrenamiento:
metrics = history.history
plt.plot(history.epoch, metrics['loss'], metrics['val_loss'])
plt.legend(['loss', 'val_loss'])
plt.show()

Evaluar el rendimiento del modelo.
Ejecute el modelo en el conjunto de prueba y verifique el rendimiento del modelo:
test_audio = []
test_labels = []
for audio, label in test_ds:
test_audio.append(audio.numpy())
test_labels.append(label.numpy())
test_audio = np.array(test_audio)
test_labels = np.array(test_labels)
y_pred = np.argmax(model.predict(test_audio), axis=1)
y_true = test_labels
test_acc = sum(y_pred == y_true) / len(y_true)
print(f'Test set accuracy: {test_acc:.0%}')
Test set accuracy: 85%
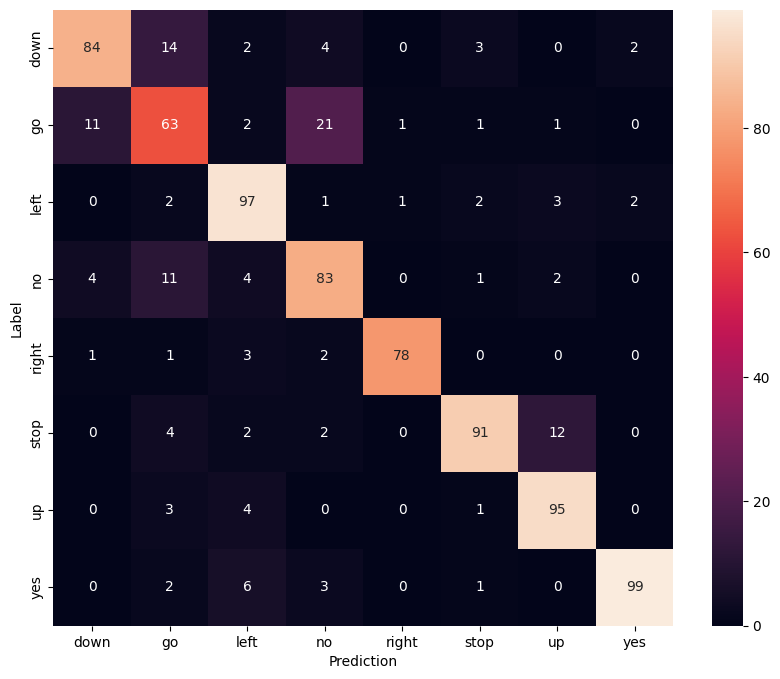
Mostrar una matriz de confusión
Use una matriz de confusión para verificar qué tan bien el modelo clasificó cada uno de los comandos en el conjunto de prueba:
confusion_mtx = tf.math.confusion_matrix(y_true, y_pred)
plt.figure(figsize=(10, 8))
sns.heatmap(confusion_mtx,
xticklabels=commands,
yticklabels=commands,
annot=True, fmt='g')
plt.xlabel('Prediction')
plt.ylabel('Label')
plt.show()
Ejecutar inferencia en un archivo de audio
Finalmente, verifique la salida de predicción del modelo utilizando un archivo de audio de entrada de alguien que dice "no". ¿Qué tan bien funciona tu modelo?
sample_file = data_dir/'no/01bb6a2a_nohash_0.wav'
sample_ds = preprocess_dataset([str(sample_file)])
for spectrogram, label in sample_ds.batch(1):
prediction = model(spectrogram)
plt.bar(commands, tf.nn.softmax(prediction[0]))
plt.title(f'Predictions for "{commands[label[0]]}"')
plt.show()
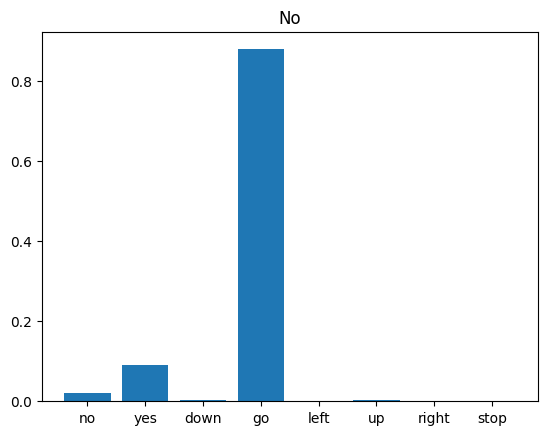
Como sugiere el resultado, su modelo debería haber reconocido el comando de audio como "no".
Próximos pasos
Este tutorial demostró cómo llevar a cabo una clasificación de audio simple/reconocimiento automático de voz usando una red neuronal convolucional con TensorFlow y Python. Para obtener más información, considere los siguientes recursos:
- El tutorial Clasificación de sonido con YAMNet muestra cómo utilizar el aprendizaje por transferencia para la clasificación de audio.
- Los cuadernos del desafío de reconocimiento de voz TensorFlow de Kaggle .
- El TensorFlow.js: reconocimiento de audio mediante el laboratorio de código de aprendizaje por transferencia enseña cómo crear su propia aplicación web interactiva para la clasificación de audio.
- Un tutorial sobre aprendizaje profundo para la recuperación de información musical (Choi et al., 2017) en arXiv.
- TensorFlow también tiene soporte adicional para la preparación y el aumento de datos de audio para ayudarlo con sus propios proyectos basados en audio.
- Considere usar la biblioteca librosa , un paquete de Python para el análisis de música y audio.