| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Descripción general
Uno de los mayores desafíos en el reconocimiento automático de voz es la preparación y el aumento de datos de audio. El análisis de datos de audio puede realizarse en el dominio del tiempo o de la frecuencia, lo que agrega complejidad adicional en comparación con otras fuentes de datos, como las imágenes.
Como parte del ecosistema TensorFlow, tensorflow-io paquete proporciona unos APIs relacionados con el audio bastante útil que ayuda a aliviar la preparación y la ampliación de datos de audio.
Configuración
Instale los paquetes necesarios y reinicie el tiempo de ejecución
pip install tensorflow-io
Uso
Leer un archivo de audio
En TensorFlow IO, clase tfio.audio.AudioIOTensor le permite leer un archivo de audio en un perezoso-cargado IOTensor :
import tensorflow as tf
import tensorflow_io as tfio
audio = tfio.audio.AudioIOTensor('gs://cloud-samples-tests/speech/brooklyn.flac')
print(audio)
<AudioIOTensor: shape=[28979 1], dtype=<dtype: 'int16'>, rate=16000>
En el ejemplo anterior, el archivo FLAC brooklyn.flac es de un clip de audio de acceso público en la nube de Google .
La dirección de GCS gs://cloud-samples-tests/speech/brooklyn.flac se utilizan directamente porque GCS es un sistema de archivos compatible en TensorFlow. Además de Flac formato, WAV , Ogg , MP3 , y MP4A reciban ayuda de AudioIOTensor con detección automática de formato de archivo.
AudioIOTensor es-lazy cargado de modo que sólo la forma, dtype y frecuencia de muestreo se muestra inicialmente. La forma de la AudioIOTensor se representa como [samples, channels] , lo que significa el clip de audio que ha cargado es mono canal con 28979 muestras en int16 .
El contenido del clip de audio sólo se puede leer como sea necesario, ya sea mediante la conversión de AudioIOTensor a Tensor través to_tensor() , o aunque el corte en lonchas. El corte es especialmente útil cuando solo se necesita una pequeña parte de un clip de audio grande:
audio_slice = audio[100:]
# remove last dimension
audio_tensor = tf.squeeze(audio_slice, axis=[-1])
print(audio_tensor)
tf.Tensor([16 39 66 ... 56 81 83], shape=(28879,), dtype=int16)
El audio se puede reproducir a través de:
from IPython.display import Audio
Audio(audio_tensor.numpy(), rate=audio.rate.numpy())
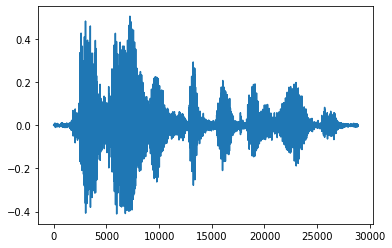
Es más conveniente convertir el tensor en números flotantes y mostrar el clip de audio en un gráfico:
import matplotlib.pyplot as plt
tensor = tf.cast(audio_tensor, tf.float32) / 32768.0
plt.figure()
plt.plot(tensor.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd3eb72d0>]
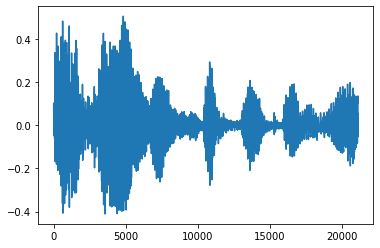
Recortar el ruido
A veces tiene sentido para recortar el ruido del audio, lo que podría hacerse a través de la API tfio.audio.trim . En la API es un par de [start, stop] posición de la segement de:
position = tfio.audio.trim(tensor, axis=0, epsilon=0.1)
print(position)
start = position[0]
stop = position[1]
print(start, stop)
processed = tensor[start:stop]
plt.figure()
plt.plot(processed.numpy())
tf.Tensor([ 2398 23546], shape=(2,), dtype=int64) tf.Tensor(2398, shape=(), dtype=int64) tf.Tensor(23546, shape=(), dtype=int64) [<matplotlib.lines.Line2D at 0x7fbdd3dce9d0>]
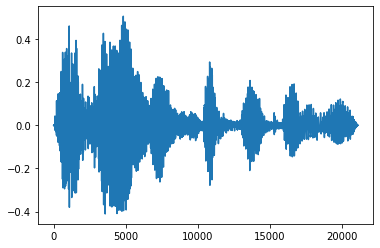
Fundido de entrada y salida
Una técnica de ingeniería de audio útil es el desvanecimiento, que aumenta o disminuye gradualmente las señales de audio. Esto se puede hacer a través tfio.audio.fade . tfio.audio.fade admite diferentes formas de fundidos tales como linear , logarithmic , o exponential :
fade = tfio.audio.fade(
processed, fade_in=1000, fade_out=2000, mode="logarithmic")
plt.figure()
plt.plot(fade.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd00d9b10>]
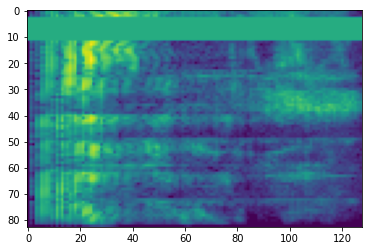
Espectrograma
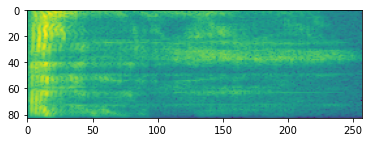
El procesamiento de audio avanzado a menudo funciona con cambios de frecuencia a lo largo del tiempo. En tensorflow-io una forma de onda puede ser convertido en espectrograma través tfio.audio.spectrogram :
# Convert to spectrogram
spectrogram = tfio.audio.spectrogram(
fade, nfft=512, window=512, stride=256)
plt.figure()
plt.imshow(tf.math.log(spectrogram).numpy())
<matplotlib.image.AxesImage at 0x7fbdd005add0>
También es posible una transformación adicional a diferentes escalas:
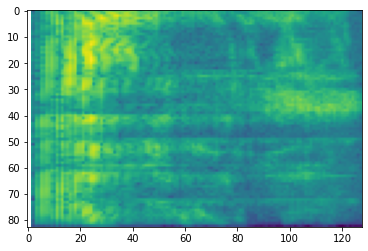
# Convert to mel-spectrogram
mel_spectrogram = tfio.audio.melscale(
spectrogram, rate=16000, mels=128, fmin=0, fmax=8000)
plt.figure()
plt.imshow(tf.math.log(mel_spectrogram).numpy())
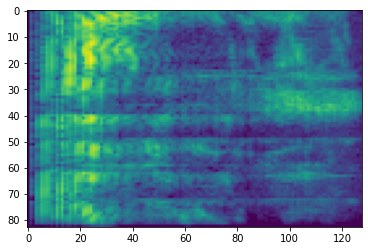
# Convert to db scale mel-spectrogram
dbscale_mel_spectrogram = tfio.audio.dbscale(
mel_spectrogram, top_db=80)
plt.figure()
plt.imshow(dbscale_mel_spectrogram.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb20bd10>
Aumento de especificaciones
Además de lo anterior APIs de preparación de datos y de aumento mencionados, tensorflow-io paquete también proporciona aumentos espectrograma avanzados, lo más notablemente frecuencia y el tiempo de enmascaramiento discute en SpecAugment: (. Park et al, 2019) un método de datos de aumento simple para reconocimiento de voz automático .
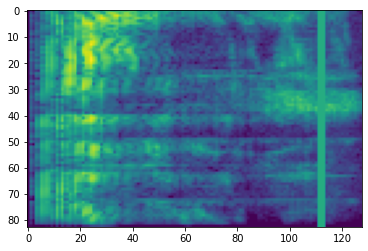
Enmascaramiento de frecuencia
En enmascaramiento de frecuencia, canales de frecuencia [f0, f0 + f) están enmascaradas, donde f se elige de una distribución uniforme de 0 a la máscara de frecuencia parámetro F , y f0 se selecciona de entre (0, ν − f) donde ν es el número de canales de frecuencia.
# Freq masking
freq_mask = tfio.audio.freq_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(freq_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb155cd0>
Enmascaramiento de tiempo
En enmascaramiento tiempo, t pasos de tiempo consecutivos [t0, t0 + t) están enmascaradas, donde t se elige de una distribución uniforme de 0 a la máscara de parámetro de tiempo T , y t0 se selecciona de entre [0, τ − t) donde τ es el pasos de tiempo.
# Time masking
time_mask = tfio.audio.time_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(time_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb0d9bd0>