
Los operadores de aprendizaje automático (ML) que utiliza en su modelo pueden afectar el proceso de conversión de un modelo de TensorFlow al formato TensorFlow Lite. El convertidor TensorFlow Lite admite una cantidad limitada de operaciones de TensorFlow utilizadas en modelos de inferencia comunes, lo que significa que no todos los modelos son directamente convertibles. La herramienta de conversión le permite incluir operadores adicionales, pero convertir un modelo de esta manera también requiere que modifique el entorno de ejecución de TensorFlow Lite que usa para ejecutar su modelo, lo que puede limitar su capacidad de usar opciones de implementación de tiempo de ejecución estándar, como los servicios de Google Play .
TensorFlow Lite Converter está diseñado para analizar la estructura del modelo y aplicar optimizaciones para hacerlo compatible con los operadores directamente admitidos. Por ejemplo, dependiendo de los operadores de ML en su modelo, el convertidor puede eludir o fusionar esos operadores para asignarlos a sus contrapartes de TensorFlow Lite.
Incluso para las operaciones admitidas, a veces se esperan patrones de uso específicos por motivos de rendimiento. La mejor manera de comprender cómo construir un modelo de TensorFlow que pueda usarse con TensorFlow Lite es considerar cuidadosamente cómo se convierten y optimizan las operaciones, junto con las limitaciones impuestas por este proceso.
Operadores soportados
Los operadores integrados de TensorFlow Lite son un subconjunto de los operadores que forman parte de la biblioteca principal de TensorFlow. Su modelo de TensorFlow también puede incluir operadores personalizados en forma de operadores compuestos o nuevos operadores definidos por usted. El siguiente diagrama muestra las relaciones entre estos operadores.
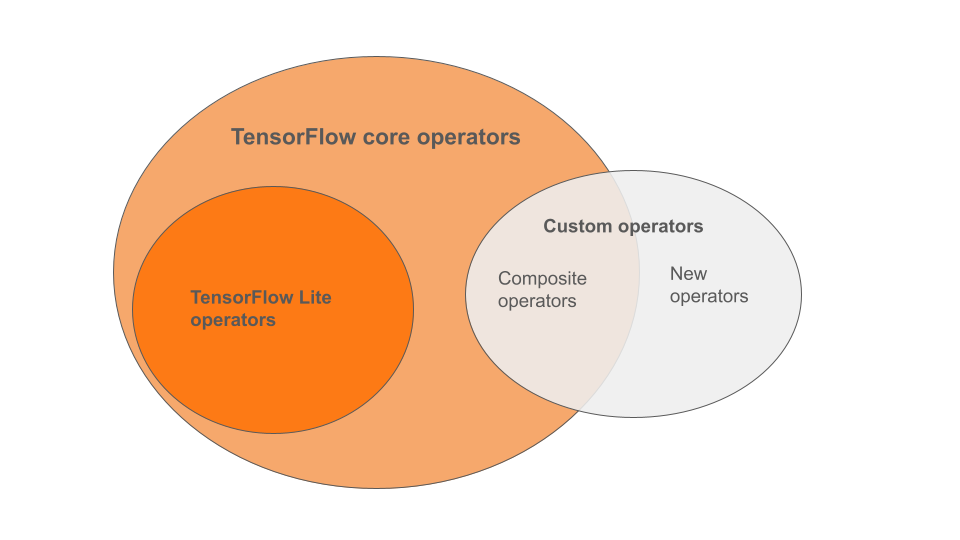
De esta gama de operadores de modelos ML, existen 3 tipos de modelos admitidos por el proceso de conversión:
- Modelos con operador integrado únicamente de TensorFlow Lite. ( Recomendado )
- Modelos con operadores integrados y operadores principales seleccionados de TensorFlow.
- Modelos con operadores integrados, operadores principales de TensorFlow y/u operadores personalizados.
Si su modelo solo contiene operaciones que son compatibles de forma nativa con TensorFlow Lite, no necesita ningún indicador adicional para convertirlo. Esta es la ruta recomendada porque este tipo de modelo se convertirá sin problemas y es más sencillo de optimizar y ejecutar utilizando el tiempo de ejecución predeterminado de TensorFlow Lite. También tienes más opciones de implementación para tu modelo, como los servicios de Google Play . Puede comenzar con la guía de conversión de TensorFlow Lite . Consulte la página TensorFlow Lite Ops para obtener una lista de operadores integrados.
Si necesita incluir operaciones seleccionadas de TensorFlow de la biblioteca principal, debe especificarlo en la conversión y asegurarse de que su tiempo de ejecución incluya esas operaciones. Consulte el tema Seleccionar operadores de TensorFlow para conocer los pasos detallados.
Siempre que sea posible, evite la última opción de incluir operadores personalizados en su modelo convertido. Los operadores personalizados son operadores creados combinando varios operadores principales primitivos de TensorFlow o definiendo uno completamente nuevo. Cuando se convierten los operadores personalizados, pueden aumentar el tamaño del modelo general al incurrir en dependencias fuera de la biblioteca integrada de TensorFlow Lite. Las operaciones personalizadas, si no se crean específicamente para la implementación de dispositivos o dispositivos móviles, pueden generar un peor rendimiento cuando se implementan en dispositivos con recursos limitados en comparación con un entorno de servidor. Finalmente, al igual que incluir operadores principales de TensorFlow seleccionados, los operadores personalizados requieren que usted modifique el entorno de ejecución del modelo , lo que le impide aprovechar los servicios de ejecución estándar, como los servicios de Google Play .
Tipos soportados
La mayoría de las operaciones de TensorFlow Lite tienen como objetivo la inferencia tanto de punto flotante ( float32 ) como cuantificada ( uint8 , int8 ), pero muchas operaciones aún no lo hacen para otros tipos como tf.float16 y strings.
Además de utilizar diferentes versiones de las operaciones, la otra diferencia entre los modelos de punto flotante y cuantificados es la forma en que se convierten. La conversión cuantificada requiere información de rango dinámico para los tensores. Esto requiere una "cuantificación falsa" durante el entrenamiento del modelo, obtener información de rango a través de un conjunto de datos de calibración o realizar una estimación de rango "sobre la marcha". Consulte cuantificación para obtener más detalles.
Conversiones sencillas, plegado y fusión constantes
TensorFlow Lite puede procesar varias operaciones de TensorFlow aunque no tengan un equivalente directo. Este es el caso de las operaciones que pueden eliminarse simplemente del gráfico ( tf.identity ), reemplazarse por tensores ( tf.placeholder ) o fusionarse en operaciones más complejas ( tf.nn.bias_add ). Incluso algunas operaciones admitidas a veces pueden eliminarse mediante uno de estos procesos.
Aquí hay una lista no exhaustiva de las operaciones de TensorFlow que generalmente se eliminan del gráfico:
-
tf.add -
tf.debugging.check_numerics -
tf.constant -
tf.div -
tf.divide -
tf.fake_quant_with_min_max_args -
tf.fake_quant_with_min_max_vars -
tf.identity -
tf.maximum -
tf.minimum -
tf.multiply -
tf.no_op -
tf.placeholder -
tf.placeholder_with_default -
tf.realdiv -
tf.reduce_max -
tf.reduce_min -
tf.reduce_sum -
tf.rsqrt -
tf.shape -
tf.sqrt -
tf.square -
tf.subtract -
tf.tile -
tf.nn.batch_norm_with_global_normalization -
tf.nn.bias_add -
tf.nn.fused_batch_norm -
tf.nn.relu -
tf.nn.relu6
Operaciones experimentales
Las siguientes operaciones de TensorFlow Lite están presentes, pero no están listas para modelos personalizados:
-
CALL -
CONCAT_EMBEDDINGS -
CUSTOM -
EMBEDDING_LOOKUP_SPARSE -
HASHTABLE_LOOKUP -
LSH_PROJECTION -
SKIP_GRAM -
SVDF