
L'utilizzo di unità di elaborazione grafica (GPU) per eseguire i modelli di machine learning (ML) può migliorare notevolmente le prestazioni del modello e l'esperienza utente delle applicazioni abilitate per ML. Sui dispositivi iOS, puoi abilitare l'uso dell'esecuzione accelerata dalla GPU dei tuoi modelli utilizzando un delegato . I delegati fungono da driver hardware per TensorFlow Lite, consentendoti di eseguire il codice del tuo modello su processori GPU.
Questa pagina descrive come abilitare l'accelerazione GPU per i modelli TensorFlow Lite nelle app iOS. Per ulteriori informazioni sull'utilizzo del delegato GPU per TensorFlow Lite, incluse best practice e tecniche avanzate, consulta la pagina dei delegati GPU .
Utilizza GPU con API Interpreter
L' API TensorFlow Lite Interpreter fornisce una serie di API generiche per la creazione di applicazioni di machine learning. Le seguenti istruzioni ti guidano attraverso l'aggiunta del supporto GPU a un'app iOS. Questa guida presuppone che tu abbia già un'app iOS in grado di eseguire correttamente un modello ML con TensorFlow Lite.
Modifica il Podfile per includere il supporto GPU
A partire dalla versione TensorFlow Lite 2.3.0, il delegato GPU viene escluso dal pod per ridurre la dimensione binaria. Puoi includerli specificando una specifica secondaria per il pod TensorFlowLiteSwift :
pod 'TensorFlowLiteSwift/Metal', '~> 0.0.1-nightly',
O
pod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['Metal']
Puoi anche utilizzare TensorFlowLiteObjC o TensorFlowLiteC se desideri utilizzare Objective-C, disponibile per le versioni 2.4.0 e successive, o l'API C.
Inizializza e utilizza il delegato GPU
Puoi utilizzare il delegato GPU con l' API TensorFlow Lite Interpreter con una serie di linguaggi di programmazione. Si consigliano Swift e Objective-C, ma è possibile utilizzare anche C++ e C. L'uso di C è obbligatorio se si utilizza una versione di TensorFlow Lite precedente alla 2.4. Negli esempi di codice seguenti viene illustrato come utilizzare il delegato con ciascuno di questi linguaggi.
Veloce
import TensorFlowLite
// Load model ...
// Initialize TensorFlow Lite interpreter with the GPU delegate.
let delegate = MetalDelegate()
if let interpreter = try Interpreter(modelPath: modelPath,
delegates: [delegate]) {
// Run inference ...
}
Obiettivo-C
// Import module when using CocoaPods with module support
@import TFLTensorFlowLite;
// Or import following headers manually
#import "tensorflow/lite/objc/apis/TFLMetalDelegate.h"
#import "tensorflow/lite/objc/apis/TFLTensorFlowLite.h"
// Initialize GPU delegate
TFLMetalDelegate* metalDelegate = [[TFLMetalDelegate alloc] init];
// Initialize interpreter with model path and GPU delegate
TFLInterpreterOptions* options = [[TFLInterpreterOptions alloc] init];
NSError* error = nil;
TFLInterpreter* interpreter = [[TFLInterpreter alloc]
initWithModelPath:modelPath
options:options
delegates:@[ metalDelegate ]
error:&error];
if (error != nil) { /* Error handling... */ }
if (![interpreter allocateTensorsWithError:&error]) { /* Error handling... */ }
if (error != nil) { /* Error handling... */ }
// Run inference ...
C++
// Set up interpreter.
auto model = FlatBufferModel::BuildFromFile(model_path);
if (!model) return false;
tflite::ops::builtin::BuiltinOpResolver op_resolver;
std::unique_ptr<Interpreter> interpreter;
InterpreterBuilder(*model, op_resolver)(&interpreter);
// Prepare GPU delegate.
auto* delegate = TFLGpuDelegateCreate(/*default options=*/nullptr);
if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false;
// Run inference.
WriteToInputTensor(interpreter->typed_input_tensor<float>(0));
if (interpreter->Invoke() != kTfLiteOk) return false;
ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0));
// Clean up.
TFLGpuDelegateDelete(delegate);
C (prima della 2.4.0)
#include "tensorflow/lite/c/c_api.h"
#include "tensorflow/lite/delegates/gpu/metal_delegate.h"
// Initialize model
TfLiteModel* model = TfLiteModelCreateFromFile(model_path);
// Initialize interpreter with GPU delegate
TfLiteInterpreterOptions* options = TfLiteInterpreterOptionsCreate();
TfLiteDelegate* delegate = TFLGPUDelegateCreate(nil); // default config
TfLiteInterpreterOptionsAddDelegate(options, metal_delegate);
TfLiteInterpreter* interpreter = TfLiteInterpreterCreate(model, options);
TfLiteInterpreterOptionsDelete(options);
TfLiteInterpreterAllocateTensors(interpreter);
NSMutableData *input_data = [NSMutableData dataWithLength:input_size * sizeof(float)];
NSMutableData *output_data = [NSMutableData dataWithLength:output_size * sizeof(float)];
TfLiteTensor* input = TfLiteInterpreterGetInputTensor(interpreter, 0);
const TfLiteTensor* output = TfLiteInterpreterGetOutputTensor(interpreter, 0);
// Run inference
TfLiteTensorCopyFromBuffer(input, inputData.bytes, inputData.length);
TfLiteInterpreterInvoke(interpreter);
TfLiteTensorCopyToBuffer(output, outputData.mutableBytes, outputData.length);
// Clean up
TfLiteInterpreterDelete(interpreter);
TFLGpuDelegateDelete(metal_delegate);
TfLiteModelDelete(model);
Note sull'utilizzo del linguaggio dell'API GPU
- Le versioni di TensorFlow Lite precedenti alla 2.4.0 possono utilizzare solo l'API C per Objective-C.
- L'API C++ è disponibile solo quando utilizzi Bazel o crei TensorFlow Lite da solo. L'API C++ non può essere utilizzata con CocoaPods.
- Quando utilizzi TensorFlow Lite con il delegato GPU con C++, ottieni il delegato GPU tramite la funzione
TFLGpuDelegateCreate()e quindi passalo aInterpreter::ModifyGraphWithDelegate(), invece di chiamareInterpreter::AllocateTensors().
Costruisci e testa con la modalità di rilascio
Passa a una build di rilascio con le impostazioni appropriate dell'acceleratore API Metal per ottenere prestazioni migliori e per il test finale. Questa sezione spiega come abilitare una build di rilascio e configurare le impostazioni per l'accelerazione Metal.
Per passare a una build di rilascio:
- Modifica le impostazioni di creazione selezionando Prodotto > Schema > Modifica schema... e quindi selezionando Esegui .
- Nella scheda Informazioni , modifica Configurazione build in Rilascio e deseleziona Debug eseguibile .
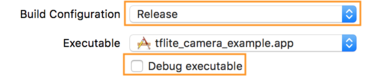
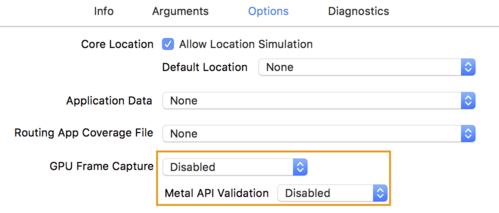
- Fai clic sulla scheda Opzioni e modifica Acquisizione frame GPU su Disabilitato e Convalida API Metal su Disabilitato .
- Assicurati di selezionare build di sola versione su architettura a 64 bit. In Navigatore progetto > tflite_camera_example > PROGETTO > nome_progetto > Impostazioni di creazione imposta Crea solo architettura attiva > Rilascia su Sì .

Supporto GPU avanzato
Questa sezione illustra gli usi avanzati del delegato GPU per iOS, incluse le opzioni del delegato, i buffer di input e output e l'uso di modelli quantizzati.
Opzioni delegato per iOS
Il costruttore per il delegato GPU accetta una struct di opzioni nell'API Swift , nell'API Objective-C e nell'API C. Il passaggio nullptr (API C) o nulla (API Objective-C e Swift) all'inizializzatore imposta le opzioni predefinite (che sono spiegate nell'esempio di utilizzo di base sopra).
Veloce
// THIS:
var options = MetalDelegate.Options()
options.isPrecisionLossAllowed = false
options.waitType = .passive
options.isQuantizationEnabled = true
let delegate = MetalDelegate(options: options)
// IS THE SAME AS THIS:
let delegate = MetalDelegate()
Obiettivo-C
// THIS:
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init];
options.precisionLossAllowed = false;
options.waitType = TFLMetalDelegateThreadWaitTypePassive;
options.quantizationEnabled = true;
TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] initWithOptions:options];
// IS THE SAME AS THIS:
TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] init];
C
// THIS:
const TFLGpuDelegateOptions options = {
.allow_precision_loss = false,
.wait_type = TFLGpuDelegateWaitType::TFLGpuDelegateWaitTypePassive,
.enable_quantization = true,
};
TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
// IS THE SAME AS THIS:
TfLiteDelegate* delegate = TFLGpuDelegateCreate(nullptr);
Buffer di input/output che utilizzano l'API C++
Il calcolo sulla GPU richiede che i dati siano disponibili sulla GPU. Questo requisito spesso significa che è necessario eseguire una copia della memoria. Se possibile, dovresti evitare che i tuoi dati oltrepassino il limite di memoria della CPU/GPU, poiché ciò può richiedere una notevole quantità di tempo. Di solito tale incrocio è inevitabile, ma in alcuni casi particolari l'uno o l'altro può essere omesso.
Se l'input della rete è un'immagine già caricata nella memoria della GPU (ad esempio, una texture GPU contenente il feed della fotocamera), può rimanere nella memoria della GPU senza mai entrare nella memoria della CPU. Allo stesso modo, se l'output della rete è sotto forma di un'immagine renderizzabile, come un'operazione di trasferimento di uno stile immagine , è possibile visualizzare direttamente il risultato sullo schermo.
Per ottenere le migliori prestazioni, TensorFlow Lite consente agli utenti di leggere e scrivere direttamente nel buffer hardware di TensorFlow e di ignorare le copie di memoria evitabili.
Supponendo che l'input dell'immagine sia nella memoria della GPU, devi prima convertirlo in un oggetto MTLBuffer per Metal. È possibile associare un TfLiteTensor a un MTLBuffer preparato dall'utente con la funzione TFLGpuDelegateBindMetalBufferToTensor() . Tieni presente che questa funzione deve essere chiamata dopo Interpreter::ModifyGraphWithDelegate() . Inoltre, l'output dell'inferenza viene, per impostazione predefinita, copiato dalla memoria della GPU alla memoria della CPU. È possibile disattivare questo comportamento chiamando Interpreter::SetAllowBufferHandleOutput(true) durante l'inizializzazione.
C++
#include "tensorflow/lite/delegates/gpu/metal_delegate.h"
#include "tensorflow/lite/delegates/gpu/metal_delegate_internal.h"
// ...
// Prepare GPU delegate.
auto* delegate = TFLGpuDelegateCreate(nullptr);
if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false;
interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy
if (!TFLGpuDelegateBindMetalBufferToTensor(
delegate, interpreter->inputs()[0], user_provided_input_buffer)) {
return false;
}
if (!TFLGpuDelegateBindMetalBufferToTensor(
delegate, interpreter->outputs()[0], user_provided_output_buffer)) {
return false;
}
// Run inference.
if (interpreter->Invoke() != kTfLiteOk) return false;
Una volta disattivato il comportamento predefinito, la copia dell'output dell'inferenza dalla memoria della GPU alla memoria della CPU richiede una chiamata esplicita a Interpreter::EnsureTensorDataIsReadable() per ogni tensore di output. Questo approccio funziona anche per i modelli quantizzati, ma è comunque necessario utilizzare un buffer di dimensioni float32 con dati float32 , poiché il buffer è associato al buffer dequantizzato interno.
Modelli quantizzati
Le librerie dei delegati GPU iOS supportano i modelli quantizzati per impostazione predefinita . Non è necessario apportare modifiche al codice per utilizzare modelli quantizzati con il delegato GPU. La sezione seguente spiega come disabilitare il supporto quantizzato per scopi di test o sperimentali.
Disabilita il supporto del modello quantizzato
Il codice seguente mostra come disabilitare il supporto per i modelli quantizzati.
Veloce
var options = MetalDelegate.Options()
options.isQuantizationEnabled = false
let delegate = MetalDelegate(options: options)
Obiettivo-C
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init];
options.quantizationEnabled = false;
C
TFLGpuDelegateOptions options = TFLGpuDelegateOptionsDefault();
options.enable_quantization = false;
TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
Per ulteriori informazioni sull'esecuzione di modelli quantizzati con accelerazione GPU, vedere Panoramica del delegato GPU .