
Kwantyzacja po szkoleniu to technika konwersji, która może zmniejszyć rozmiar modelu, jednocześnie poprawiając opóźnienie procesora i akceleratora sprzętowego, przy niewielkim pogorszeniu dokładności modelu. Możesz skwantyzować już wyszkolony model float TensorFlow, konwertując go do formatu TensorFlow Lite za pomocą konwertera TensorFlow Lite .
Metody optymalizacji
Do wyboru jest kilka opcji kwantyzacji potreningowej. Oto tabela podsumowująca opcje i korzyści, jakie zapewniają:
| Technika | Korzyści | Sprzęt komputerowy |
|---|---|---|
| Kwantyzacja zakresu dynamicznego | 4x mniejszy, 2x-3x przyspieszenie | procesor |
| Pełna kwantyzacja całkowita | 4x mniejszy, 3x+ szybszy | Procesor, Edge TPU, Mikrokontrolery |
| Kwantyzacja Float16 | 2x mniejsze, przyspieszenie GPU | Procesor, karta graficzna |
Poniższe drzewo decyzyjne może pomóc w określeniu, która metoda kwantyzacji po treningu jest najlepsza dla Twojego przypadku użycia:
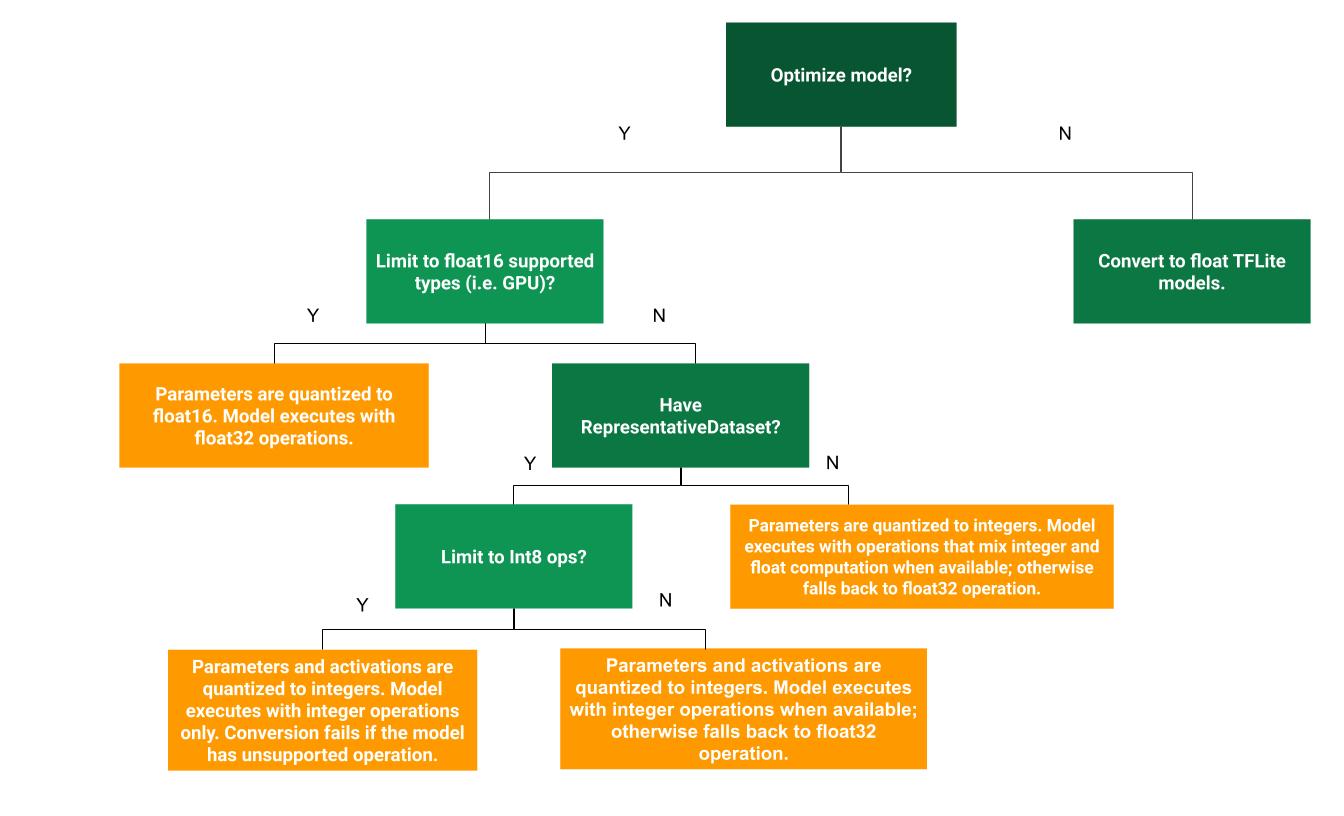
Kwantyzacja zakresu dynamicznego
Kwantyzacja zakresu dynamicznego jest zalecanym punktem wyjścia, ponieważ zapewnia mniejsze zużycie pamięci i szybsze obliczenia bez konieczności dostarczania reprezentatywnego zestawu danych do kalibracji. Ten typ kwantyzacji statycznie kwantyzuje tylko wagi od liczby zmiennoprzecinkowej do liczby całkowitej w czasie konwersji, co zapewnia 8-bitową precyzję:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
Aby jeszcze bardziej zmniejszyć opóźnienia podczas wnioskowania, operatorzy „zakresu dynamicznego” dynamicznie kwantyzują aktywacje w oparciu o ich zakres do 8 bitów i wykonują obliczenia z 8-bitowymi wagami i aktywacjami. Ta optymalizacja zapewnia opóźnienia zbliżone do wniosków o całkowicie ustalonym punkcie. Jednak dane wyjściowe są nadal przechowywane przy użyciu zmiennoprzecinkowego, więc zwiększona prędkość operacji w zakresie dynamicznym jest mniejsza niż pełne obliczenia stałoprzecinkowe.
Pełna kwantyzacja całkowita
Możesz uzyskać dalszą poprawę opóźnień, zmniejszenie szczytowego użycia pamięci i kompatybilność z urządzeniami sprzętowymi lub akceleratorami obsługującymi wyłącznie liczby całkowite, upewniając się, że wszystkie obliczenia matematyczne modelu są skwantowane na liczbach całkowitych.
Aby uzyskać pełną kwantyzację liczb całkowitych, należy skalibrować lub oszacować zakres, tj. (min., maks.) wszystkich tensorów zmiennoprzecinkowych w modelu. W przeciwieństwie do stałych tensorów, takich jak wagi i odchylenia, tensory zmienne, takie jak dane wejściowe modelu, aktywacje (wyjścia warstw pośrednich) i dane wyjściowe modelu, nie mogą zostać skalibrowane, chyba że wykonamy kilka cykli wnioskowania. W rezultacie konwerter wymaga reprezentatywnego zestawu danych do ich kalibracji. Ten zbiór danych może stanowić niewielki podzbiór (około ~100–500 próbek) danych szkoleniowych lub walidacyjnych. Zapoznaj się z funkcją representative_dataset() poniżej.
Od wersji TensorFlow 2.7 możesz określić reprezentatywny zestaw danych za pomocą podpisu , jak w poniższym przykładzie:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
Jeśli w danym modelu TensorFlow znajduje się więcej niż jeden podpis, możesz określić wielokrotny zbiór danych, określając klucze podpisu:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
Możesz wygenerować reprezentatywny zbiór danych, dostarczając listę tensorów wejściowych:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
Od wersji TensorFlow 2.7 zalecamy stosowanie podejścia opartego na sygnaturach zamiast podejścia opartego na liście tensorów wejściowych, ponieważ kolejność tensorów wejściowych można łatwo odwrócić.
Do celów testowych możesz użyć fikcyjnego zbioru danych w następujący sposób:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
Liczba całkowita z rezerwą typu float (przy użyciu domyślnego wejścia/wyjścia typu float)
Aby w pełni skwantyzować model na liczbach całkowitych, ale użyć operatorów zmiennoprzecinkowych, jeśli nie mają one implementacji liczb całkowitych (aby zapewnić płynność konwersji), wykonaj następujące kroki:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
Tylko liczba całkowita
Tworzenie modeli zawierających wyłącznie liczby całkowite jest częstym przypadkiem użycia TensorFlow Lite dla mikrokontrolerów i procesorów TPU Coral Edge .
Dodatkowo, aby zapewnić zgodność z urządzeniami obsługującymi wyłącznie liczby całkowite (takimi jak 8-bitowe mikrokontrolery) i akceleratorami (takimi jak Coral Edge TPU), można wymusić pełną kwantyzację liczb całkowitych dla wszystkich operacji, w tym wejścia i wyjścia, wykonując następujące kroki:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Kwantyzacja Float16
Można zmniejszyć rozmiar modelu zmiennoprzecinkowego, kwantyzując wagi do float16, standardu IEEE dla 16-bitowych liczb zmiennoprzecinkowych. Aby włączyć kwantyzację wag metodą float16, wykonaj następujące kroki:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
Zalety kwantyzacji float16 są następujące:
- Zmniejsza rozmiar modelu nawet o połowę (ponieważ wszystkie ciężarki stają się o połowę mniejsze od pierwotnego rozmiaru).
- Powoduje minimalną utratę dokładności.
- Obsługuje niektóre delegaty (np. delegata GPU), które mogą działać bezpośrednio na danych typu float16, co skutkuje szybszym wykonaniem niż obliczenia typu float32.
Wady kwantyzacji float16 są następujące:
- Nie zmniejsza to opóźnień tak bardzo, jak kwantyzacja do matematyki o punkcie stałym.
- Domyślnie skwantowany model typu float16 po uruchomieniu na procesorze „dekwantyzuje” wartości wag do wartości float32. (Zauważ, że delegat GPU nie wykona tej dekwantyzacji, ponieważ może operować na danych typu float16.)
Tylko liczby całkowite: 16-bitowe aktywacje z 8-bitowymi wagami (eksperymentalne)
Jest to eksperymentalny schemat kwantyzacji. Jest podobny do schematu „tylko liczby całkowite”, ale aktywacje są kwantowane w oparciu o ich zakres do 16 bitów, wagi są kwantowane w 8-bitowej liczbie całkowitej, a odchylenie jest kwantowane w 64-bitowej liczbie całkowitej. Nazywa się to dalej kwantyzacją 16x8.
Główną zaletą tej kwantyzacji jest to, że może znacznie poprawić dokładność, ale tylko nieznacznie zwiększyć rozmiar modelu.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
Jeśli kwantyzacja 16x8 nie jest obsługiwana dla niektórych operatorów w modelu, wówczas model nadal może być skwantowany, ale nieobsługiwane operatory pozostają w trybie zmiennoprzecinkowym. Aby to umożliwić, należy dodać następującą opcję do target_spec.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
Przykłady przypadków użycia, w których ulepszenia dokładności zapewniane przez ten schemat kwantyzacji obejmują:
- superrozdzielczość,
- przetwarzanie sygnału audio, takie jak redukcja szumów i kształtowanie wiązki,
- odszumianie obrazu,
- Rekonstrukcja HDR z pojedynczego obrazu.
Wadą tej kwantyzacji jest:
- Obecnie wnioskowanie jest zauważalnie wolniejsze niż 8-bitowa pełna liczba całkowita ze względu na brak zoptymalizowanej implementacji jądra.
- Obecnie jest niekompatybilny z istniejącymi delegatami TFLite z akceleracją sprzętową.
Samouczek dotyczący tego trybu kwantyzacji można znaleźć tutaj .
Dokładność modelu
Ponieważ wagi są kwantyzowane po szkoleniu, może wystąpić utrata dokładności, szczególnie w przypadku mniejszych sieci. Wstępnie wyszkolone, w pełni skwantowane modele są dostępne dla określonych sieci w TensorFlow Hub . Ważne jest sprawdzenie dokładności skwantowanego modelu, aby sprawdzić, czy jakiekolwiek pogorszenie dokładności mieści się w dopuszczalnych granicach. Istnieją narzędzia do oceny dokładności modelu TensorFlow Lite .
Alternatywnie, jeśli spadek dokładności jest zbyt duży, rozważ skorzystanie z szkolenia uwzględniającego kwantyzację . Wymaga to jednak modyfikacji podczas uczenia modelu w celu dodania fałszywych węzłów kwantyzacji, podczas gdy techniki kwantyzacji po szkoleniu na tej stronie wykorzystują istniejący, wstępnie wyszkolony model.
Reprezentacja skwantowanych tensorów
Kwantyzacja 8-bitowa przybliża wartości zmiennoprzecinkowe za pomocą następującego wzoru.
\[real\_value = (int8\_value - zero\_point) \times scale\]
Reprezentacja składa się z dwóch głównych części:
Wagi na oś (inaczej na kanał) lub na tensor reprezentowane przez wartości uzupełnienia do dwóch int8 w zakresie [-127, 127] z punktem zerowym równym 0.
Aktywacje/wejścia na tensor reprezentowane przez wartości uzupełnienia do dwóch int8 w zakresie [-128, 127], z punktem zerowym w zakresie [-128, 127].
Aby uzyskać szczegółowy widok naszego schematu kwantyzacji, zobacz naszą specyfikację kwantyzacji . Zachęcamy dostawców sprzętu, którzy chcą podłączyć się do interfejsu delegatów TensorFlow Lite, do wdrożenia opisanego tam schematu kwantyzacji.