
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
במחברת זו, נחקור את TensorFlow Distributions (בקיצור TFD). המטרה של מחברת זו היא להביא אותך בעדינות במעלה עקומת הלמידה, כולל הבנת הטיפול של TFD בצורות טנזור. מחברת זו מנסה להציג דוגמאות לפני ולא מופשטות. נציג תחילה דרכים קלות קנוניות לעשות דברים, ונשמור את התצוגה המופשטת הכללית ביותר עד הסוף. אם אתה הטיפוס שמעדיף הדרכה מופשטת יותר ועיון בסגנון, לבדוק הבנת TensorFlow הפצות צורות . אם יש לך שאלות על החומר כאן, אל תהססו לפנות (או להצטרף) לרשימת דיוור הסתברות TensorFlow . אנחנו שמחים לעזור.
לפני שנתחיל, עלינו לייבא את הספריות המתאימות. הספרייה הכללית שלנו היא tensorflow_probability . ככלל, אנו בדרך כלל מתייחסים הספרייה הפצות כמו tfd .
Tensorflow הלהוט הוא סביבת ביצוע הכרחית עבור TensorFlow. ב- TensorFlow eager, כל פעולת TF מוערכת מיד ומביאה לתוצאה. זאת בניגוד למצב ה"גרף" הסטנדרטי של TensorFlow, שבו פעולות TF מוסיפות צמתים לגרף שמתבצע מאוחר יותר. כל המחברת הזו כתובה באמצעות TF Eager, למרות שאף אחד מהמושגים המוצגים כאן לא מסתמך על זה, וניתן להשתמש ב-TFP במצב גרף.
import collections
import tensorflow as tf
import tensorflow_probability as tfp
tfd = tfp.distributions
try:
tf.compat.v1.enable_eager_execution()
except ValueError:
pass
import matplotlib.pyplot as plt
התפלגויות חד-משתניות בסיסיות
בואו נצלול פנימה וניצור התפלגות נורמלית:
n = tfd.Normal(loc=0., scale=1.)
n
<tfp.distributions.Normal 'Normal' batch_shape=[] event_shape=[] dtype=float32>
נוכל לצייר ממנו דוגמה:
n.sample()
<tf.Tensor: shape=(), dtype=float32, numpy=0.25322816>
אנו יכולים לצייר מספר דוגמאות:
n.sample(3)
<tf.Tensor: shape=(3,), dtype=float32, numpy=array([-1.4658079, -0.5653636, 0.9314412], dtype=float32)>
אנו יכולים להעריך סבירות ביומן:
n.log_prob(0.)
<tf.Tensor: shape=(), dtype=float32, numpy=-0.9189385>
אנו יכולים להעריך הסתברויות יומן מרובות:
n.log_prob([0., 2., 4.])
<tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.9189385, -2.9189386, -8.918939 ], dtype=float32)>
יש לנו מגוון רחב של הפצות. בואו ננסה ברנולי:
b = tfd.Bernoulli(probs=0.7)
b
<tfp.distributions.Bernoulli 'Bernoulli' batch_shape=[] event_shape=[] dtype=int32>
b.sample()
<tf.Tensor: shape=(), dtype=int32, numpy=1>
b.sample(8)
<tf.Tensor: shape=(8,), dtype=int32, numpy=array([1, 0, 0, 0, 1, 0, 1, 0], dtype=int32)>
b.log_prob(1)
<tf.Tensor: shape=(), dtype=float32, numpy=-0.35667497>
b.log_prob([1, 0, 1, 0])
<tf.Tensor: shape=(4,), dtype=float32, numpy=array([-0.35667497, -1.2039728 , -0.35667497, -1.2039728 ], dtype=float32)>
התפלגויות רב משתנות
ניצור נורמלי רב משתנים עם שיתופיות אלכסונית:
nd = tfd.MultivariateNormalDiag(loc=[0., 10.], scale_diag=[1., 4.])
nd
<tfp.distributions.MultivariateNormalDiag 'MultivariateNormalDiag' batch_shape=[] event_shape=[2] dtype=float32>
אם משווים את זה לנורמלי החד-משתני שיצרנו קודם לכן, מה שונה?
tfd.Normal(loc=0., scale=1.)
<tfp.distributions.Normal 'Normal' batch_shape=[] event_shape=[] dtype=float32>
אנו רואים כי נורמלים משתנים אחד יש event_shape של () , סימן שהוא כבר חלוק סקלר. הרגיל של הרב משתנים יש event_shape של 2 , המציין את [שטח אירוע] הבסיסי (https://en.wikipedia.org/wiki/Event_ (probability_theory)) של הפצה זו היא דו-ממדי.
הדגימה עובדת בדיוק כמו קודם:
nd.sample()
<tf.Tensor: shape=(2,), dtype=float32, numpy=array([-1.2489667, 15.025171 ], dtype=float32)>
nd.sample(5)
<tf.Tensor: shape=(5, 2), dtype=float32, numpy=
array([[-1.5439653 , 8.9968405 ],
[-0.38730723, 12.448896 ],
[-0.8697963 , 9.330035 ],
[-1.2541095 , 10.268944 ],
[ 2.3475595 , 13.184147 ]], dtype=float32)>
nd.log_prob([0., 10])
<tf.Tensor: shape=(), dtype=float32, numpy=-3.2241714>
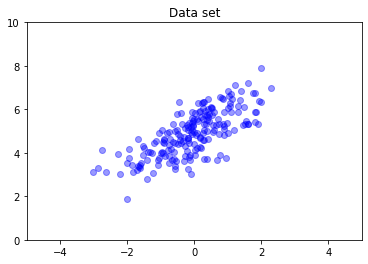
לנורמלים רב משתנים אין באופן כללי שיתוף פעולה אלכסוני. TFD מציע דרכים מרובות ליצור נורמלים מרובי משתנים, כולל מפרט שיתופיות מלאה, שבו אנו משתמשים כאן.
nd = tfd.MultivariateNormalFullCovariance(
loc = [0., 5], covariance_matrix = [[1., .7], [.7, 1.]])
data = nd.sample(200)
plt.scatter(data[:, 0], data[:, 1], color='blue', alpha=0.4)
plt.axis([-5, 5, 0, 10])
plt.title("Data set")
plt.show()
הפצות מרובות
הפצת ברנולי הראשונה שלנו ייצגה הטלה של מטבע הוגן יחיד. אנו יכולים גם ליצור קבוצה של התפלגות ברנולי עצמאית, כל אחד עם פרמטרים משלהם, בתוך אחת Distribution האובייקט:
b3 = tfd.Bernoulli(probs=[.3, .5, .7])
b3
<tfp.distributions.Bernoulli 'Bernoulli' batch_shape=[3] event_shape=[] dtype=int32>
חשוב שיהיה ברור מה זה אומר. השיחה הנ"ל מגדירה שלוש התפלגות ברנולי עצמאית, אשר תקרה להיכלל באותה Python Distribution האובייקט. לא ניתן לתפעל את שלוש ההפצות בנפרד. שים לב איך batch_shape הוא (3,) , מה שמעיד על אצווה של שלוש הפצות, ואת event_shape הוא () , המציין את הפצות הפרט יש מקום האירוע משתנה אחד.
אם נקרא sample , אנחנו מקבלים מדגם מכל שלושה:
b3.sample()
<tf.Tensor: shape=(3,), dtype=int32, numpy=array([0, 1, 1], dtype=int32)>
b3.sample(6)
<tf.Tensor: shape=(6, 3), dtype=int32, numpy=
array([[1, 0, 1],
[0, 1, 1],
[0, 0, 1],
[0, 0, 1],
[0, 0, 1],
[0, 1, 0]], dtype=int32)>
אם אנחנו קוראים prob , (זה יש את אותו סמנטיקה צורה כמו log_prob ; נשתמש prob עם דוגמאות ברנולי הקטנים האלה למען הבהירות, למרות log_prob עדיף בדרך כלל ביישומים) ואנו נוכל להעביר אותה וקטור ולהעריך את ההסתברות של כל מטבע מניב ערך :
b3.prob([1, 1, 0])
<tf.Tensor: shape=(3,), dtype=float32, numpy=array([0.29999998, 0.5 , 0.29999998], dtype=float32)>
מדוע ה-API כולל צורת אצווה? סמנטי, אפשר לבצע את אותו חישוב על ידי יצירת רשימה של הפצות ולביקורות מעליהם עם for לולאה (לפחות במצב להוט, במצב גרף TF היית צריך tf.while לולאה). עם זאת, קיום קבוצה (בפוטנציה גדולה) של הפצות עם פרמטרים זהים הוא נפוץ ביותר, והשימוש בחישובים מוקטורים במידת האפשר הוא מרכיב מרכזי ביכולת לבצע חישובים מהירים באמצעות מאיצי חומרה.
שימוש עצמאי כדי לצבור קבוצות לאירועים
בחלק הקודם, יצרנו b3 , סינגל Distribution אובייקט מיוצג מטבע שלוש הטלות. אם קראנו b3.prob על וקטור \(v\), את \(i\)"th הכניסה הייתה ההסתברות כי \(i\)ה המטבע לוקח ערך \(v[i]\).
נניח שבמקום זאת נרצה לציין התפלגות "משותף" על משתנים אקראיים בלתי תלויים מאותה משפחה בסיסית. זהו אובייקט שונה מבחינה מתמטית, כי עבור הפצה חדשה זה, prob על וקטור \(v\) יחזור ערך בודד המייצג את ההסתברות כי הסט השלם של מטבעות תואם את הווקטור \(v\).
איך אנחנו משיגים את זה? אנו משתמשים הפצה "מסדר גבוה" שנקראה Independent , אשר לוקחת הפצת מניב הפצה חדשה עם הצורה יצווה עברה את צורת אירוע:
b3_joint = tfd.Independent(b3, reinterpreted_batch_ndims=1)
b3_joint
<tfp.distributions.Independent 'IndependentBernoulli' batch_shape=[] event_shape=[3] dtype=int32>
השווה את הצורה לזה של המקורי b3 :
b3
<tfp.distributions.Bernoulli 'Bernoulli' batch_shape=[3] event_shape=[] dtype=int32>
כמובטח, אנו רואים כי זה Independent עבר את הצורה תצווה לתוך צורת אירוע: b3_joint היא הפצה יחידה ( batch_shape = () ) על פני שטח אירוע תלת ממדי ( event_shape = (3,) ).
בואו נבדוק את הסמנטיקה:
b3_joint.prob([1, 1, 0])
<tf.Tensor: shape=(), dtype=float32, numpy=0.044999998>
דרך חלופית להגיע לאותה התוצאה תהיה הסתברויות מחשוב באמצעות b3 ולעשות ההפחתה באופן ידני על ידי הכפלה (או, במקרה יותר מהרגיל שבו הסתברויות יומן משמשות, סיכום):
tf.reduce_prod(b3.prob([1, 1, 0]))
<tf.Tensor: shape=(), dtype=float32, numpy=0.044999994>
Indpendent מאפשרת למשתמש יותר במפורש לייצג את המושג הרצוי. אנו רואים בכך שימושי ביותר, למרות שזה לא הכרחי לחלוטין.
עובדות מהנות:
-
b3.sampleוb3_joint.sampleיש מימושים מושגית שונים, אבל פלטים נבדלו: ההבדל בין קבוצה של הפצות עצמאיות חלוקה בודדת נוצרה מן תצווה באמצעותIndependentמופיע בעת חישוב probabilites, לא כאשר דגימה. -
MultivariateNormalDiagיכול להיות מיושם טריוויאלית באמצעות סקלרNormalוIndependentהפצות (זה בעצם אינו מיושם בדרך זו, אבל זה יכול להיות).
קבוצות של הפרעות רב משתנות
בואו ניצור אצווה של שלושה נורמלים רב-משתנים דו-ממדיים בעלי שיתוף פעולה מלא:
nd_batch = tfd.MultivariateNormalFullCovariance(
loc = [[0., 0.], [1., 1.], [2., 2.]],
covariance_matrix = [[[1., .1], [.1, 1.]],
[[1., .3], [.3, 1.]],
[[1., .5], [.5, 1.]]])
nd_batch
<tfp.distributions.MultivariateNormalFullCovariance 'MultivariateNormalFullCovariance' batch_shape=[3] event_shape=[2] dtype=float32>
אנו רואים batch_shape = (3,) , כך ישנם שלושה הנורמלים מרובים משתנים בלתי תלוי, ואת event_shape = (2,) , כך שכול רב נורמלי הוא דו-ממדי. בדוגמה זו, להפצות הבודדות אין אלמנטים עצמאיים.
עבודות דגימה:
nd_batch.sample(4)
<tf.Tensor: shape=(4, 3, 2), dtype=float32, numpy=
array([[[ 0.7367498 , 2.730996 ],
[-0.74080074, -0.36466932],
[ 0.6516018 , 0.9391426 ]],
[[ 1.038303 , 0.12231752],
[-0.94788766, -1.204232 ],
[ 4.059758 , 3.035752 ]],
[[ 0.56903946, -0.06875849],
[-0.35127294, 0.5311631 ],
[ 3.4635801 , 4.565582 ]],
[[-0.15989424, -0.25715637],
[ 0.87479895, 0.97391707],
[ 0.5211419 , 2.32108 ]]], dtype=float32)>
מאז batch_shape = (3,) ו event_shape = (2,) , אנו חולפים על פני מותח של הצורה (3, 2) כדי log_prob :
nd_batch.log_prob([[0., 0.], [1., 1.], [2., 2.]])
<tf.Tensor: shape=(3,), dtype=float32, numpy=array([-1.8328519, -1.7907217, -1.694036 ], dtype=float32)>
שידור, הלא הוא למה זה כל כך מבלבל?
לפשט את מה שעשינו עד כה, כל חלוקה בעל צורה אצווה B ו- צורה אירוע E . לאפשר BE להיות שרשור של צורות האירוע:
- עבור הפצות סקלר משתנה אחד
nו-b,BE = ().. - עבור הנורמלים המרובים משתנים דו ממדי
nd.BE = (2). - עבור שניהם
b3ו-b3_joint,BE = (3). - עבור האצווה של הנורמלים מרובים משתנים
ndb,BE = (3, 2).
"כללי ההערכה" שבהם השתמשנו עד כה הם:
- לדוגמא עם טענה לא מחזירה מותחת עם צורת
BE; דגימה עם סקלר n מחזיר "n ידיBEמותח". -
probוlog_probלקחת מותח של הצורהBEולהחזיר תוצאה של צורתB.
"שלטון ההערכה" בפועל עבור prob ו log_prob מסתבך יותר, באופן הצעות כוח פוטנציאלי ומהיר אלא גם מורכבות ואתגרים. הכלל בפועל הוא (בעיקרו) שהטיעון כדי log_prob חייב להיות broadcastable נגד BE ; כל ממדים "נוספים" נשמרים בפלט.
בואו נחקור את ההשלכות. עבור נורמלית משתנה אחד n , BE = () , כך log_prob מצפה סקלר. אם עברנו log_prob טנזור עם צורה הלא-ריקה, אלה מופיעים כעליה ממדים יצוו בפלט:
n = tfd.Normal(loc=0., scale=1.)
n
<tfp.distributions.Normal 'Normal' batch_shape=[] event_shape=[] dtype=float32>
n.log_prob(0.)
<tf.Tensor: shape=(), dtype=float32, numpy=-0.9189385>
n.log_prob([0.])
<tf.Tensor: shape=(1,), dtype=float32, numpy=array([-0.9189385], dtype=float32)>
n.log_prob([[0., 1.], [-1., 2.]])
<tf.Tensor: shape=(2, 2), dtype=float32, numpy=
array([[-0.9189385, -1.4189385],
[-1.4189385, -2.9189386]], dtype=float32)>
בתורו באים אל נורמלי הרב משתנה דו ממדי nd (פרמטרים השתנו להמחשה):
nd = tfd.MultivariateNormalDiag(loc=[0., 1.], scale_diag=[1., 1.])
nd
<tfp.distributions.MultivariateNormalDiag 'MultivariateNormalDiag' batch_shape=[] event_shape=[2] dtype=float32>
log_prob "מצפה" ויכוח עם צורה (2,) , אבל זה יהיה לקבל כל טיעון כי שידורי נגד הצורה הזו:
nd.log_prob([0., 0.])
<tf.Tensor: shape=(), dtype=float32, numpy=-2.337877>
אבל אנחנו יכולים לעבור "יותר" דוגמאות, ולהעריך את כל שלהם log_prob "s בבת אחת:
nd.log_prob([[0., 0.],
[1., 1.],
[2., 2.]])
<tf.Tensor: shape=(3,), dtype=float32, numpy=array([-2.337877 , -2.337877 , -4.3378773], dtype=float32)>
אולי פחות מושך, אנחנו יכולים לשדר על ממדי האירוע:
nd.log_prob([0.])
<tf.Tensor: shape=(), dtype=float32, numpy=-2.337877>
nd.log_prob([[0.], [1.], [2.]])
<tf.Tensor: shape=(3,), dtype=float32, numpy=array([-2.337877 , -2.337877 , -4.3378773], dtype=float32)>
שידור בדרך זו הוא תוצאה של העיצוב שלנו "אפשר שידור בכל הזדמנות אפשרית"; השימוש הזה שנוי במחלוקת במידה מסוימת ועשוי להיות מוסר בגרסה עתידית של TFP.
כעת נסתכל שוב על דוגמה של שלושת המטבעות:
b3 = tfd.Bernoulli(probs=[.3, .5, .7])
כאן, באמצעות שידור לייצג את ההסתברות שכל המטבע עולה ראשים די אינטואיטיבי:
b3.prob([1])
<tf.Tensor: shape=(3,), dtype=float32, numpy=array([0.29999998, 0.5 , 0.7 ], dtype=float32)>
(השווה זאת b3.prob([1., 1., 1.]) , שבו נצטרך בחזרה משמשים בו b3 הוצג.)
כעת, נניח שאנו רוצים לדעת, לכל מטבע, ההסתברות המטבע עולה ראשים ואת ההסתברות שזה עולה זנבות. יכולנו לדמיין לנסות:
b3.log_prob([0, 1])
למרבה הצער, זה מייצר שגיאה עם עקבות מחסנית ארוכה ולא מאוד קריא. b3 יש BE = (3) , ולכן עלינו לעבור b3.prob משהו broadcastable נגד (3,) . [0, 1] יש צורה (2) , כך שזה לא לשדר ויוצר שגיאה. במקום זאת, עלינו לומר:
b3.prob([[0], [1]])
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[0.7, 0.5, 0.3],
[0.3, 0.5, 0.7]], dtype=float32)>
למה? [[0], [1]] יש צורה (2, 1) , כך שהוא משדר נגד צורה (3) כדי ליצור צורת שידור (2, 3) .
השידור הוא די חזק: ישנם מקרים שבהם הוא מאפשר הפחתה בסדר גודל של כמות הזיכרון בשימוש, ולעתים קרובות הוא מקצר את קוד המשתמש. עם זאת, זה יכול להיות מאתגר לתכנת איתו. אם אתה קורא log_prob ולקבל שגיאה, כשל השידור הוא כמעט תמיד הבעיה.
הולך רחוק יותר
במדריך זה, סיפקנו (בתקווה) הקדמה פשוטה. כמה עצות להמשך הדרך:
-
event_shape,batch_shapeוsample_shapeיכולים להיות בדרגה שרירותית (במדריך זה הם תמיד גם סקלר או דרגת 1). זה מגביר את הכוח אבל שוב יכול להוביל לאתגרי תכנות, במיוחד כאשר מדובר בשידור. לקבלת צלילה עמוקה נוספת לתוך מניפולציה צורה, לראות את צורות TensorFlow הפצות הבנה . - פריון הכולל כולל הפשטת עצמה המכונית
Bijectors, אשר בשילוב עםTransformedDistribution, מניב בדרך גמישה, הלחנה ליצור הפצות חדשות בקלות כי הם טרנספורמציות להיפוך של הפצות קיימות. ננסה לכתוב הדרכה על בקרוב זה, אבל בינתיים, לבדוק את התיעוד