
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
TensorFlow Вероятность (TFP) библиотека для вероятностных рассуждений и статистического анализа , который теперь работает на JAX ! Для тех, кто не знаком, JAX - это библиотека для ускоренных численных вычислений, основанная на преобразованиях составных функций.
TFP на JAX поддерживает множество наиболее полезных функций обычного TFP, сохраняя при этом абстракции и API, с которыми сейчас комфортно многие пользователи TFP.
Настраивать
СФП на JAX не зависит от TensorFlow; давайте полностью удалим TensorFlow из этого Colab.
pip uninstall tensorflow -y -q
Мы можем установить TFP на JAX с последними ночными сборками TFP.
pip install -Uq tfp-nightly[jax] > /dev/null
Давайте импортируем несколько полезных библиотек Python.
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from sklearn import datasets
sns.set(style='white')
/usr/local/lib/python3.6/dist-packages/statsmodels/tools/_testing.py:19: FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead. import pandas.util.testing as tm
Давайте также импортируем некоторые базовые функции JAX.
import jax.numpy as jnp
from jax import grad
from jax import jit
from jax import random
from jax import value_and_grad
from jax import vmap
Импорт TFP на JAX
Для того, чтобы использовать TFP на JAX, просто импортировать jax «субстрат» и использовать его как обычно будет tfp :
from tensorflow_probability.substrates import jax as tfp
tfd = tfp.distributions
tfb = tfp.bijectors
tfpk = tfp.math.psd_kernels
Демо: байесовская логистическая регрессия
Чтобы продемонстрировать, что мы можем делать с бэкэндом JAX, мы реализуем байесовскую логистическую регрессию, применяемую к классическому набору данных Iris.
Сначала давайте импортируем набор данных Iris и извлечем некоторые метаданные.
iris = datasets.load_iris()
features, labels = iris['data'], iris['target']
num_features = features.shape[-1]
num_classes = len(iris.target_names)
Мы можем определить модель с помощью tfd.JointDistributionCoroutine . Мы поместим стандартные нормальные априорные на обоих весах , а термин смещения затем написать target_log_prob функцию, штыри выборочные меток к данным.
Root = tfd.JointDistributionCoroutine.Root
def model():
w = yield Root(tfd.Sample(tfd.Normal(0., 1.),
sample_shape=(num_features, num_classes)))
b = yield Root(
tfd.Sample(tfd.Normal(0., 1.), sample_shape=(num_classes,)))
logits = jnp.dot(features, w) + b
yield tfd.Independent(tfd.Categorical(logits=logits),
reinterpreted_batch_ndims=1)
dist = tfd.JointDistributionCoroutine(model)
def target_log_prob(*params):
return dist.log_prob(params + (labels,))
Мы выборка из dist для получения начального состояния для MCMC. Затем мы можем определить функцию, которая принимает случайный ключ и начальное состояние и производит 500 выборок из сэмплера No-U-Turn-Sampler (NUTS). Обратите внимание , что мы можем использовать преобразования JAX как jit скомпилировать наш NUTS пробник с помощью XLA.
init_key, sample_key = random.split(random.PRNGKey(0))
init_params = tuple(dist.sample(seed=init_key)[:-1])
@jit
def run_chain(key, state):
kernel = tfp.mcmc.NoUTurnSampler(target_log_prob, 1e-3)
return tfp.mcmc.sample_chain(500,
current_state=state,
kernel=kernel,
trace_fn=lambda _, results: results.target_log_prob,
num_burnin_steps=500,
seed=key)
states, log_probs = run_chain(sample_key, init_params)
plt.figure()
plt.plot(log_probs)
plt.ylabel('Target Log Prob')
plt.xlabel('Iterations of NUTS')
plt.show()

Давайте использовать наши образцы для выполнения усреднения байесовской модели (BMA) путем усреднения предсказанных вероятностей каждого набора весов.
Сначала давайте напишем функцию, которая для заданного набора параметров будет производить вероятности для каждого класса. Мы можем использовать dist.sample_distributions , чтобы получить окончательное распределение в модели.
def classifier_probs(params):
dists, _ = dist.sample_distributions(seed=random.PRNGKey(0),
value=params + (None,))
return dists[-1].distribution.probs_parameter()
Мы можем vmap(classifier_probs) на множестве образцов , чтобы получить оценки вероятности класса для каждого из наших образцов. Затем мы вычисляем среднюю точность для каждой выборки и точность усреднения байесовской модели.
all_probs = jit(vmap(classifier_probs))(states)
print('Average accuracy:', jnp.mean(all_probs.argmax(axis=-1) == labels))
print('BMA accuracy:', jnp.mean(all_probs.mean(axis=0).argmax(axis=-1) == labels))
Average accuracy: 0.96952 BMA accuracy: 0.97999996
Похоже, что BMA снижает количество ошибок почти на треть!
Основы
TFP на JAX имеет одинаковый API для ТФ , где вместо того , чтобы принимать объекты TF как tf.Tensor S он принимает JAX аналог. Например, везде , где tf.Tensor ранее был использован в качестве входных данных, то API , в настоящее время ожидает JAX DeviceArray . Вместо того , чтобы возвращать tf.Tensor , методы TFP вернутся DeviceArray s. TFP на JAX также работает с вложенными структурами объектов JAX, как список или словарь DeviceArray s.
Распределения
Большинство дистрибутивов TFP поддерживаются в JAX с семантикой, очень похожей на их аналоги TF. Кроме того, они зарегистрированы как JAX Pytrees , поэтому они могут быть входы и выходы JAX-трансформированных функций.
Базовые дистрибутивы
log_prob метод распределения работает так же.
dist = tfd.Normal(0., 1.)
print(dist.log_prob(0.))
-0.9189385
Выборка из распределения требует явной передачи в PRNGKey (или список целых чисел) в качестве seed аргумента ключевых слов. Отсутствие явной передачи семени вызовет ошибку.
tfd.Normal(0., 1.).sample(seed=random.PRNGKey(0))
DeviceArray(-0.20584226, dtype=float32)
Семантика формы для распределений остается тем же в JAX, где распределение будет иметь каждый event_shape и batch_shape и рисование много образцов будут добавлять дополнительные sample_shape размеров.
Например, tfd.MultivariateNormalDiag с векторными параметрами будет иметь форму вектора событий и пустую пакетную форму.
dist = tfd.MultivariateNormalDiag(
loc=jnp.zeros(5),
scale_diag=jnp.ones(5)
)
print('Event shape:', dist.event_shape)
print('Batch shape:', dist.batch_shape)
Event shape: (5,) Batch shape: ()
С другой стороны, tfd.Normal параметрироваться векторами будет иметь скалярную форму событий и вектор пакетную форму.
dist = tfd.Normal(
loc=jnp.ones(5),
scale=jnp.ones(5),
)
print('Event shape:', dist.event_shape)
print('Batch shape:', dist.batch_shape)
Event shape: () Batch shape: (5,)
Семантика взятия log_prob проб работает так же в JAX тоже.
dist = tfd.Normal(jnp.zeros(5), jnp.ones(5))
s = dist.sample(sample_shape=(10, 2), seed=random.PRNGKey(0))
print(dist.log_prob(s).shape)
dist = tfd.Independent(tfd.Normal(jnp.zeros(5), jnp.ones(5)), 1)
s = dist.sample(sample_shape=(10, 2), seed=random.PRNGKey(0))
print(dist.log_prob(s).shape)
(10, 2, 5) (10, 2)
Поскольку JAX DeviceArray s совместимы с библиотеками , как NumPy и Matplotlib, мы можем кормить образцы непосредственно в черчения функции.
sns.distplot(tfd.Normal(0., 1.).sample(1000, seed=random.PRNGKey(0)))
plt.show()
Distribution методы совместимы с JAX преобразований.
sns.distplot(jit(vmap(lambda key: tfd.Normal(0., 1.).sample(seed=key)))(
random.split(random.PRNGKey(0), 2000)))
plt.show()
x = jnp.linspace(-5., 5., 100)
plt.plot(x, jit(vmap(grad(tfd.Normal(0., 1.).prob)))(x))
plt.show()
Поскольку распределения TFP регистрируется как pytree узлы JAX, мы можем написать функции с распределениями в качестве входов и выходов и преобразование их с помощью jit , но они пока не поддерживаются в качестве аргументов vmap -ED функции.
@jit
def random_distribution(key):
loc_key, scale_key = random.split(key)
loc, log_scale = random.normal(loc_key), random.normal(scale_key)
return tfd.Normal(loc, jnp.exp(log_scale))
random_dist = random_distribution(random.PRNGKey(0))
print(random_dist.mean(), random_dist.variance())
0.14389051 0.081832744
Преобразованные распределения
Преобразованные распределения , т.е. распределения которых образцы пропускают через Bijector также работать из коробки (bijectors работать тоже! Смотри ниже).
dist = tfd.TransformedDistribution(
tfd.Normal(0., 1.),
tfb.Sigmoid()
)
sns.distplot(dist.sample(1000, seed=random.PRNGKey(0)))
plt.show()
Совместные раздачи
СФП предлагает JointDistribution с , чтобы позволить объединение распределений компонентов в единое распределение по нескольким случайным величинам. В настоящее время TFP предлагает три основных варианта ( JointDistributionSequential , JointDistributionNamed и JointDistributionCoroutine ) , все из которых поддерживаются в JAX. В AutoBatched варианты также все поддерживается.
dist = tfd.JointDistributionSequential([
tfd.Normal(0., 1.),
lambda x: tfd.Normal(x, 1e-1)
])
plt.scatter(*dist.sample(1000, seed=random.PRNGKey(0)), alpha=0.5)
plt.show()

joint = tfd.JointDistributionNamed(dict(
e= tfd.Exponential(rate=1.),
n= tfd.Normal(loc=0., scale=2.),
m=lambda n, e: tfd.Normal(loc=n, scale=e),
x=lambda m: tfd.Sample(tfd.Bernoulli(logits=m), 12),
))
joint.sample(seed=random.PRNGKey(0))
{'e': DeviceArray(3.376818, dtype=float32),
'm': DeviceArray(2.5449684, dtype=float32),
'n': DeviceArray(-0.6027825, dtype=float32),
'x': DeviceArray([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], dtype=int32)}
Root = tfd.JointDistributionCoroutine.Root
def model():
e = yield Root(tfd.Exponential(rate=1.))
n = yield Root(tfd.Normal(loc=0, scale=2.))
m = yield tfd.Normal(loc=n, scale=e)
x = yield tfd.Sample(tfd.Bernoulli(logits=m), 12)
joint = tfd.JointDistributionCoroutine(model)
joint.sample(seed=random.PRNGKey(0))
StructTuple(var0=DeviceArray(0.17315261, dtype=float32), var1=DeviceArray(-3.290489, dtype=float32), var2=DeviceArray(-3.1949058, dtype=float32), var3=DeviceArray([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], dtype=int32))
Другие дистрибутивы
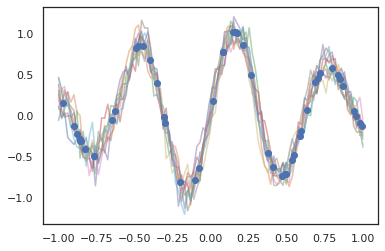
Гауссовские процессы также работают в режиме JAX!
k1, k2, k3 = random.split(random.PRNGKey(0), 3)
observation_noise_variance = 0.01
f = lambda x: jnp.sin(10*x[..., 0]) * jnp.exp(-x[..., 0]**2)
observation_index_points = random.uniform(
k1, [50], minval=-1.,maxval= 1.)[..., jnp.newaxis]
observations = f(observation_index_points) + tfd.Normal(
loc=0., scale=jnp.sqrt(observation_noise_variance)).sample(seed=k2)
index_points = jnp.linspace(-1., 1., 100)[..., jnp.newaxis]
kernel = tfpk.ExponentiatedQuadratic(length_scale=0.1)
gprm = tfd.GaussianProcessRegressionModel(
kernel=kernel,
index_points=index_points,
observation_index_points=observation_index_points,
observations=observations,
observation_noise_variance=observation_noise_variance)
samples = gprm.sample(10, seed=k3)
for i in range(10):
plt.plot(index_points, samples[i], alpha=0.5)
plt.plot(observation_index_points, observations, marker='o', linestyle='')
plt.show()
Также поддерживаются скрытые марковские модели.
initial_distribution = tfd.Categorical(probs=[0.8, 0.2])
transition_distribution = tfd.Categorical(probs=[[0.7, 0.3],
[0.2, 0.8]])
observation_distribution = tfd.Normal(loc=[0., 15.], scale=[5., 10.])
model = tfd.HiddenMarkovModel(
initial_distribution=initial_distribution,
transition_distribution=transition_distribution,
observation_distribution=observation_distribution,
num_steps=7)
print(model.mean())
print(model.log_prob(jnp.zeros(7)))
print(model.sample(seed=random.PRNGKey(0)))
[3. 6. 7.5 8.249999 8.625001 8.812501 8.90625 ] /usr/local/lib/python3.6/dist-packages/tensorflow_probability/substrates/jax/distributions/hidden_markov_model.py:483: UserWarning: HiddenMarkovModel.log_prob in TFP versions < 0.12.0 had a bug in which the transition model was applied prior to the initial step. This bug has been fixed. You may observe a slight change in behavior. 'HiddenMarkovModel.log_prob in TFP versions < 0.12.0 had a bug ' -19.855635 [ 1.3641367 0.505798 1.3626463 3.6541772 2.272286 15.10309 22.794212 ]
Несколько распределений как PixelCNN пока не поддерживаются из - за строгие зависимости от TensorFlow или XLA несовместимости.
Бижекторы
Большинство бижекторов TFP сегодня поддерживаются в JAX!
tfb.Exp().inverse(1.)
DeviceArray(0., dtype=float32)
bij = tfb.Shift(1.)(tfb.Scale(3.))
print(bij.forward(jnp.ones(5)))
print(bij.inverse(jnp.ones(5)))
[4. 4. 4. 4. 4.] [0. 0. 0. 0. 0.]
b = tfb.FillScaleTriL(diag_bijector=tfb.Exp(), diag_shift=None)
print(b.forward(x=[0., 0., 0.]))
print(b.inverse(y=[[1., 0], [.5, 2]]))
[[1. 0.] [0. 1.]] [0.6931472 0.5 0. ]
b = tfb.Chain([tfb.Exp(), tfb.Softplus()])
# or:
# b = tfb.Exp()(tfb.Softplus())
print(b.forward(-jnp.ones(5)))
[1.3678794 1.3678794 1.3678794 1.3678794 1.3678794]
Bijectors совместимы с JAX преобразований , как jit , grad и vmap .
jit(vmap(tfb.Exp().inverse))(jnp.arange(4.))
DeviceArray([ -inf, 0. , 0.6931472, 1.0986123], dtype=float32)
x = jnp.linspace(0., 1., 100)
plt.plot(x, jit(grad(lambda x: vmap(tfb.Sigmoid().inverse)(x).sum()))(x))
plt.show()
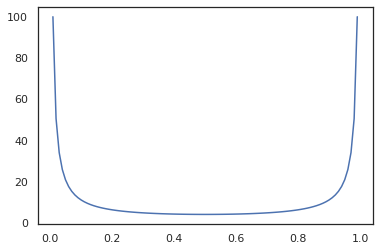
Некоторый bijectors, как RealNVP и FFJORD пока не поддерживается.
MCMC
Мы портирования tfp.mcmc к JAX, так что мы можем запустить алгоритмы как гамильтонова Монте - Карло (HMC) и No-U-Turn-Sampler (NUTS) в JAX.
target_log_prob = tfd.MultivariateNormalDiag(jnp.zeros(2), jnp.ones(2)).log_prob
В отличие от TFP на TF, мы должны пройти PRNGKey в sample_chain с использованием seed аргумента ключевых слов.
def run_chain(key, state):
kernel = tfp.mcmc.NoUTurnSampler(target_log_prob, 1e-1)
return tfp.mcmc.sample_chain(1000,
current_state=state,
kernel=kernel,
trace_fn=lambda _, results: results.target_log_prob,
seed=key)
states, log_probs = jit(run_chain)(random.PRNGKey(0), jnp.zeros(2))
plt.figure()
plt.scatter(*states.T, alpha=0.5)
plt.figure()
plt.plot(log_probs)
plt.show()
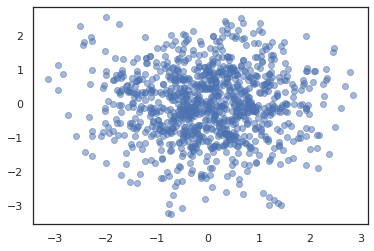
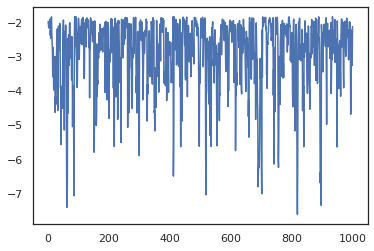
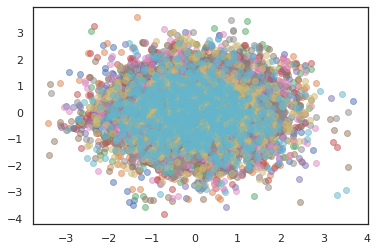
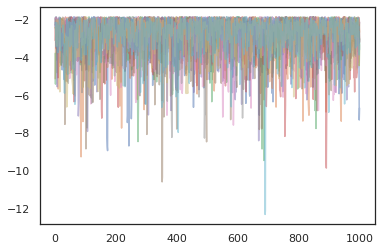
Для запуска нескольких цепочек, мы можем либо передать пакет состояний в sample_chain или использование vmap (хотя мы еще не исследовали различия в производительности между этими двумя подходами).
states, log_probs = jit(run_chain)(random.PRNGKey(0), jnp.zeros([10, 2]))
plt.figure()
for i in range(10):
plt.scatter(*states[:, i].T, alpha=0.5)
plt.figure()
for i in range(10):
plt.plot(log_probs[:, i], alpha=0.5)
plt.show()
Оптимизаторы
TFP на JAX поддерживает некоторые важные оптимизаторы, такие как BFGS и L-BFGS. Давайте настроим простую масштабированную квадратичную функцию потерь.
minimum = jnp.array([1.0, 1.0]) # The center of the quadratic bowl.
scales = jnp.array([2.0, 3.0]) # The scales along the two axes.
# The objective function and the gradient.
def quadratic_loss(x):
return jnp.sum(scales * jnp.square(x - minimum))
start = jnp.array([0.6, 0.8]) # Starting point for the search.
BFGS может найти минимум этой потери.
optim_results = tfp.optimizer.bfgs_minimize(
value_and_grad(quadratic_loss), initial_position=start, tolerance=1e-8)
# Check that the search converged
assert(optim_results.converged)
# Check that the argmin is close to the actual value.
np.testing.assert_allclose(optim_results.position, minimum)
# Print out the total number of function evaluations it took. Should be 5.
print("Function evaluations: %d" % optim_results.num_objective_evaluations)
Function evaluations: 5
Так может L-BFGS.
optim_results = tfp.optimizer.lbfgs_minimize(
value_and_grad(quadratic_loss), initial_position=start, tolerance=1e-8)
# Check that the search converged
assert(optim_results.converged)
# Check that the argmin is close to the actual value.
np.testing.assert_allclose(optim_results.position, minimum)
# Print out the total number of function evaluations it took. Should be 5.
print("Function evaluations: %d" % optim_results.num_objective_evaluations)
Function evaluations: 5
Для vmap L-BFGS, давайте создадим функцию , которая оптимизирует потери для одной отправной точки.
def optimize_single(start):
return tfp.optimizer.lbfgs_minimize(
value_and_grad(quadratic_loss), initial_position=start, tolerance=1e-8)
all_results = jit(vmap(optimize_single))(
random.normal(random.PRNGKey(0), (10, 2)))
assert all(all_results.converged)
for i in range(10):
np.testing.assert_allclose(optim_results.position[i], minimum)
print("Function evaluations: %s" % all_results.num_objective_evaluations)
Function evaluations: [6 6 9 6 6 8 6 8 5 9]
Предостережения
Между TF и JAX есть некоторые фундаментальные различия, некоторые режимы TFP будут отличаться между двумя подложками, и не все функции поддерживаются. Например,
- TFP на JAX ничего подобного не поддерживает
tf.Variable, так как ничего подобного она существует в JAX. Это также означает , что утилиты , какtfp.util.TransformedVariableне поддерживаются либо. -
tfp.layersне поддерживается во внутреннем интерфейсе все же, из - за своей зависимости от Keras иtf.Variables. -
tfp.math.minimizeне работает в СФП на JAX из - за своей зависимости отtf.Variable. - С TFP на JAX тензорные формы всегда являются конкретными целочисленными значениями и никогда не являются неизвестными / динамическими, как в TFP на TF.
- Псевдослучайность обрабатывается по-разному в TF и JAX (см. Приложение).
- Библиотеки в
tfp.experimentalне гарантируется существование в JAX подложке. - Правила продвижения Dtype различны для TF и JAX. TFP на JAX пытается внутренне уважать семантику dtype TF для обеспечения согласованности.
- Бижекторы еще не зарегистрированы как pytrees JAX.
Чтобы увидеть полный список того , что поддерживается в СФП на JAX, пожалуйста , обратитесь к документации по API .
Вывод
Мы портировали множество функций TFP на JAX и очень рады видеть, что все построят. Некоторые функции пока не поддерживаются; если мы пропустили что - то важное для вас (или если вы нашли ошибку!) , обратитесь к нам - вы можете по электронной почте tfprobability@tensorflow.org или подать вопрос на нашем Github репо .
Приложение: псевдослучайность в JAX
Генерации псевдослучайных чисел модель (ПСЧ) JAX является лицом без. В отличие от модели с отслеживанием состояния, здесь нет изменяемого глобального состояния, которое развивается после каждого случайного розыгрыша. В модели Jax, мы начинаем с ключом ПСЧ, который действует как пара 32-битных целых чисел. Мы можем построить эти ключи с помощью jax.random.PRNGKey .
key = random.PRNGKey(0) # Creates a key with value [0, 0]
print(key)
[0 0]
Случайные функции JAX потребляют ключ к детерминированным произвести случайный мерный, то есть они не должны использоваться снова. Например, мы можем использовать key к образцу нормально распределенное значения, но мы не должны использовать key еще раз в другом месте. Кроме того, передавая то же самое значение в random.normal будет производить такое же значение.
print(random.normal(key))
-0.20584226
Так как же нам нарисовать несколько образцов из одного ключа? Ответ является ключом расщепления. Основная идея заключается в том, что мы можем разделить PRNGKey на несколько, и каждый из новых ключей может рассматриваться как независимый источник случайности.
key1, key2 = random.split(key, num=2)
print(key1, key2)
[4146024105 967050713] [2718843009 1272950319]
Разделение ключей детерминировано, но хаотично, поэтому теперь каждый новый ключ можно использовать для построения отдельной случайной выборки.
print(random.normal(key1), random.normal(key2))
0.14389051 -1.2515389
Для получения более подробной информации о детерминированной модели ключ разделения Jax, см это руководство .