
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন |
এই নির্দেশিকাটি একটি মেশিন লার্নিং মডেল তৈরি করে টেনসরফ্লো-এর জন্য সুইফটের পরিচয় দেয় যা প্রজাতি অনুসারে আইরিস ফুলকে শ্রেণীবদ্ধ করে। এটি TensorFlow এর জন্য সুইফট ব্যবহার করে:
- একটি মডেল তৈরি করুন,
- উদাহরণ তথ্যের উপর এই মডেল প্রশিক্ষণ, এবং
- অজানা তথ্য সম্পর্কে ভবিষ্যদ্বাণী করতে মডেল ব্যবহার করুন.
টেনসরফ্লো প্রোগ্রামিং
এই নির্দেশিকা টেনসরফ্লো ধারণার জন্য এই উচ্চ-স্তরের সুইফট ব্যবহার করে:
- Epochs API দিয়ে ডেটা আমদানি করুন।
- সুইফট অ্যাবস্ট্রাকশন ব্যবহার করে মডেল তৈরি করুন।
- বিশুদ্ধ সুইফ্ট লাইব্রেরি উপলব্ধ না হলে সুইফ্টের পাইথন ইন্টারঅপারেবিলিটি ব্যবহার করে পাইথন লাইব্রেরি ব্যবহার করুন।
এই টিউটোরিয়ালটি অনেক TensorFlow প্রোগ্রামের মত গঠন করা হয়েছে:
- ডেটা সেটগুলি আমদানি এবং পার্স করুন।
- মডেলের ধরন নির্বাচন করুন।
- মডেলকে প্রশিক্ষণ দিন।
- মডেলের কার্যকারিতা মূল্যায়ন করুন।
- ভবিষ্যদ্বাণী করতে প্রশিক্ষিত মডেল ব্যবহার করুন.
সেটআপ প্রোগ্রাম
আমদানি কনফিগার করুন
TensorFlow এবং কিছু দরকারী পাইথন মডিউল আমদানি করুন।
import TensorFlow
import PythonKit
// This cell is here to display the plots in a Jupyter Notebook.
// Do not copy it into another environment.
%include "EnableIPythonDisplay.swift"
print(IPythonDisplay.shell.enable_matplotlib("inline"))
('inline', 'module://ipykernel.pylab.backend_inline')
let plt = Python.import("matplotlib.pyplot")
import Foundation
import FoundationNetworking
func download(from sourceString: String, to destinationString: String) {
let source = URL(string: sourceString)!
let destination = URL(fileURLWithPath: destinationString)
let data = try! Data.init(contentsOf: source)
try! data.write(to: destination)
}
আইরিস শ্রেণীবিভাগ সমস্যা
কল্পনা করুন যে আপনি একজন উদ্ভিদবিদ যা আপনি খুঁজে পাওয়া প্রতিটি আইরিস ফুলকে শ্রেণিবদ্ধ করার জন্য একটি স্বয়ংক্রিয় উপায় খুঁজছেন। মেশিন লার্নিং ফুলকে পরিসংখ্যানগতভাবে শ্রেণীবদ্ধ করার জন্য অনেক অ্যালগরিদম প্রদান করে। উদাহরণস্বরূপ, একটি অত্যাধুনিক মেশিন লার্নিং প্রোগ্রাম ফটোগ্রাফের উপর ভিত্তি করে ফুলকে শ্রেণীবদ্ধ করতে পারে। আমাদের উচ্চাকাঙ্ক্ষা আরও বিনয়ী—আমরা তাদের সিপাল এবং পাপড়ির দৈর্ঘ্য এবং প্রস্থ পরিমাপের ভিত্তিতে আইরিস ফুলকে শ্রেণিবদ্ধ করতে যাচ্ছি।
আইরিস জেনাসে প্রায় 300টি প্রজাতি রয়েছে, তবে আমাদের প্রোগ্রামটি শুধুমাত্র নিম্নলিখিত তিনটিকে শ্রেণীবদ্ধ করবে:
- আইরিস সেটোসা
- আইরিস ভার্জিনিকা
- আইরিস ভার্সিকলার
 |
| চিত্র 1. আইরিস সেটোসা ( রাডোমিল , সিসি বাই-এসএ 3.0 দ্বারা), আইরিস ভার্সিকলার , ( ডলাংলোইস , সিসি বাই-এসএ 3.0 দ্বারা), এবং আইরিস ভার্জিনিকা ( ফ্রাঙ্ক মেফিল্ড দ্বারা, সিসি বাই-এসএ 2.0)। |
সৌভাগ্যবশত, কেউ ইতিমধ্যেই সেপাল এবং পাপড়ি পরিমাপের সাথে 120 টি আইরিস ফুলের একটি ডেটা সেট তৈরি করেছে। এটি একটি ক্লাসিক ডেটাসেট যা শিক্ষানবিস মেশিন লার্নিং ক্লাসিফিকেশন সমস্যার জন্য জনপ্রিয়।
প্রশিক্ষণ ডেটাসেট আমদানি এবং পার্স করুন
ডেটাসেট ফাইলটি ডাউনলোড করুন এবং এটিকে একটি কাঠামোতে রূপান্তর করুন যা এই সুইফট প্রোগ্রাম দ্বারা ব্যবহার করা যেতে পারে।
ডেটাসেট ডাউনলোড করুন
http://download.tensorflow.org/data/iris_training.csv থেকে প্রশিক্ষণ ডেটাসেট ফাইল ডাউনলোড করুন
let trainDataFilename = "iris_training.csv"
download(from: "http://download.tensorflow.org/data/iris_training.csv", to: trainDataFilename)
ডেটা পরিদর্শন করুন
এই ডেটাসেট, iris_training.csv , একটি প্লেইন টেক্সট ফাইল যা কমা-বিভাজিত মান (CSV) হিসাবে ফর্ম্যাট করা ট্যাবুলার ডেটা সঞ্চয় করে। আসুন প্রথম 5টি এন্ট্রি দেখি।
let f = Python.open(trainDataFilename)
for _ in 0..<5 {
print(Python.next(f).strip())
}
print(f.close())
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0 None
ডেটাসেটের এই দৃশ্য থেকে, নিম্নলিখিতগুলি লক্ষ্য করুন:
- প্রথম লাইনটি ডেটাসেট সম্পর্কে তথ্য ধারণকারী একটি শিরোনাম:
- মোট 120টি উদাহরণ রয়েছে। প্রতিটি উদাহরণে চারটি বৈশিষ্ট্য এবং তিনটি সম্ভাব্য লেবেল নামের একটি রয়েছে৷
- পরবর্তী সারিগুলি ডেটা রেকর্ড, প্রতি লাইনে একটি উদাহরণ , যেখানে:
আসুন কোডে এটি লিখি:
let featureNames = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
let labelName = "species"
let columnNames = featureNames + [labelName]
print("Features: \(featureNames)")
print("Label: \(labelName)")
Features: ["sepal_length", "sepal_width", "petal_length", "petal_width"] Label: species
প্রতিটি লেবেল স্ট্রিং নামের সাথে যুক্ত থাকে (উদাহরণস্বরূপ, "সেটোসা"), কিন্তু মেশিন লার্নিং সাধারণত সংখ্যাসূচক মানের উপর নির্ভর করে। লেবেল নম্বরগুলি একটি নামযুক্ত উপস্থাপনায় ম্যাপ করা হয়, যেমন:
-
0: আইরিস সেটোসা -
1: আইরিস ভার্সিকলার -
2: আইরিস ভার্জিনিকা
বৈশিষ্ট্য এবং লেবেল সম্পর্কে আরও তথ্যের জন্য, মেশিন লার্নিং ক্র্যাশ কোর্সের ML পরিভাষা বিভাগটি দেখুন।
let classNames = ["Iris setosa", "Iris versicolor", "Iris virginica"]
Epochs API ব্যবহার করে একটি ডেটাসেট তৈরি করুন
TensorFlow-এর Epochs API-এর জন্য Swift হল একটি উচ্চ-স্তরের API যা ডেটা পড়ার জন্য এবং প্রশিক্ষণের জন্য ব্যবহৃত ফর্মে রূপান্তরিত করে।
let batchSize = 32
/// A batch of examples from the iris dataset.
struct IrisBatch {
/// [batchSize, featureCount] tensor of features.
let features: Tensor<Float>
/// [batchSize] tensor of labels.
let labels: Tensor<Int32>
}
/// Conform `IrisBatch` to `Collatable` so that we can load it into a `TrainingEpoch`.
extension IrisBatch: Collatable {
public init<BatchSamples: Collection>(collating samples: BatchSamples)
where BatchSamples.Element == Self {
/// `IrisBatch`es are collated by stacking their feature and label tensors
/// along the batch axis to produce a single feature and label tensor
features = Tensor<Float>(stacking: samples.map{$0.features})
labels = Tensor<Int32>(stacking: samples.map{$0.labels})
}
}
যেহেতু আমরা যে ডেটাসেটগুলি ডাউনলোড করেছি সেগুলি CSV ফর্ম্যাটে রয়েছে, আসুন আইরিসব্যাচ অবজেক্টের তালিকা হিসাবে ডেটাতে লোড করার জন্য একটি ফাংশন লিখি
/// Initialize an `IrisBatch` dataset from a CSV file.
func loadIrisDatasetFromCSV(
contentsOf: String, hasHeader: Bool, featureColumns: [Int], labelColumns: [Int]) -> [IrisBatch] {
let np = Python.import("numpy")
let featuresNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: featureColumns,
dtype: Float.numpyScalarTypes.first!)
guard let featuresTensor = Tensor<Float>(numpy: featuresNp) else {
// This should never happen, because we construct featuresNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
let labelsNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: labelColumns,
dtype: Int32.numpyScalarTypes.first!)
guard let labelsTensor = Tensor<Int32>(numpy: labelsNp) else {
// This should never happen, because we construct labelsNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
return zip(featuresTensor.unstacked(), labelsTensor.unstacked()).map{IrisBatch(features: $0.0, labels: $0.1)}
}
আমরা এখন প্রশিক্ষণ ডেটাসেট লোড করতে এবং একটি TrainingEpochs অবজেক্ট তৈরি করতে CSV লোডিং ফাংশন ব্যবহার করতে পারি
let trainingDataset: [IrisBatch] = loadIrisDatasetFromCSV(contentsOf: trainDataFilename,
hasHeader: true,
featureColumns: [0, 1, 2, 3],
labelColumns: [4])
let trainingEpochs: TrainingEpochs = TrainingEpochs(samples: trainingDataset, batchSize: batchSize)
TrainingEpochs বস্তুটি যুগের একটি অসীম ক্রম। প্রতিটি যুগে IrisBatch es থাকে। আসুন প্রথম যুগের প্রথম উপাদানটি দেখি।
let firstTrainEpoch = trainingEpochs.next()!
let firstTrainBatch = firstTrainEpoch.first!.collated
let firstTrainFeatures = firstTrainBatch.features
let firstTrainLabels = firstTrainBatch.labels
print("First batch of features: \(firstTrainFeatures)")
print("firstTrainFeatures.shape: \(firstTrainFeatures.shape)")
print("First batch of labels: \(firstTrainLabels)")
print("firstTrainLabels.shape: \(firstTrainLabels.shape)")
First batch of features: [[5.1, 2.5, 3.0, 1.1], [6.4, 3.2, 4.5, 1.5], [4.9, 3.1, 1.5, 0.1], [5.0, 2.0, 3.5, 1.0], [6.3, 2.5, 5.0, 1.9], [6.7, 3.1, 5.6, 2.4], [4.9, 3.1, 1.5, 0.1], [7.7, 2.8, 6.7, 2.0], [6.7, 3.0, 5.0, 1.7], [7.2, 3.6, 6.1, 2.5], [4.8, 3.0, 1.4, 0.1], [5.2, 3.4, 1.4, 0.2], [5.0, 3.5, 1.3, 0.3], [4.9, 3.1, 1.5, 0.1], [5.0, 3.5, 1.6, 0.6], [6.7, 3.3, 5.7, 2.1], [7.7, 3.8, 6.7, 2.2], [6.2, 3.4, 5.4, 2.3], [4.8, 3.4, 1.6, 0.2], [6.0, 2.9, 4.5, 1.5], [5.0, 3.0, 1.6, 0.2], [6.3, 3.4, 5.6, 2.4], [5.1, 3.8, 1.9, 0.4], [4.8, 3.1, 1.6, 0.2], [7.6, 3.0, 6.6, 2.1], [5.7, 3.0, 4.2, 1.2], [6.3, 3.3, 6.0, 2.5], [5.6, 2.5, 3.9, 1.1], [5.0, 3.4, 1.6, 0.4], [6.1, 3.0, 4.9, 1.8], [5.0, 3.3, 1.4, 0.2], [6.3, 3.3, 4.7, 1.6]] firstTrainFeatures.shape: [32, 4] First batch of labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1] firstTrainLabels.shape: [32]
লক্ষ্য করুন যে প্রথম batchSize উদাহরণগুলির বৈশিষ্ট্যগুলিকে একত্রে (বা ব্যাচ করা ) firstTrainFeatures এ গোষ্ঠীভুক্ত করা হয়েছে এবং প্রথম batchSize উদাহরণগুলির লেবেলগুলি firstTrainLabels এ ব্যাচ করা হয়েছে।
আপনি পাইথনের ম্যাটপ্লটলিব ব্যবহার করে ব্যাচ থেকে কয়েকটি বৈশিষ্ট্য প্লট করে কিছু ক্লাস্টার দেখতে শুরু করতে পারেন:
let firstTrainFeaturesTransposed = firstTrainFeatures.transposed()
let petalLengths = firstTrainFeaturesTransposed[2].scalars
let sepalLengths = firstTrainFeaturesTransposed[0].scalars
plt.scatter(petalLengths, sepalLengths, c: firstTrainLabels.array.scalars)
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
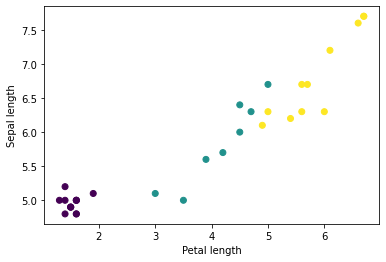
Use `print()` to show values.
মডেলের ধরন নির্বাচন করুন
মডেল কেন?
একটি মডেল বৈশিষ্ট্য এবং লেবেল মধ্যে একটি সম্পর্ক. আইরিস শ্রেণীবিভাগের সমস্যার জন্য, মডেলটি সেপাল এবং পাপড়ির পরিমাপ এবং পূর্বাভাসিত আইরিস প্রজাতির মধ্যে সম্পর্ককে সংজ্ঞায়িত করে। কিছু সাধারণ মডেলকে বীজগণিতের কয়েকটি লাইন দিয়ে বর্ণনা করা যেতে পারে, কিন্তু জটিল মেশিন লার্নিং মডেলগুলিতে প্রচুর পরিমাণে পরামিতি থাকে যা সংক্ষিপ্ত করা কঠিন।
আপনি মেশিন লার্নিং ব্যবহার না করে চারটি বৈশিষ্ট্য এবং আইরিস প্রজাতির মধ্যে সম্পর্ক নির্ধারণ করতে পারেন? যে, আপনি একটি মডেল তৈরি করতে ঐতিহ্যগত প্রোগ্রামিং কৌশল (উদাহরণস্বরূপ, অনেক শর্তসাপেক্ষ বিবৃতি) ব্যবহার করতে পারেন? সম্ভবত—যদি আপনি একটি নির্দিষ্ট প্রজাতির পাপড়ি এবং সিপাল পরিমাপের মধ্যে সম্পর্ক নির্ধারণের জন্য যথেষ্ট দীর্ঘ ডেটাসেট বিশ্লেষণ করেন। এবং এটি আরও জটিল ডেটাসেটে কঠিন-হয়ত অসম্ভব হয়ে ওঠে। একটি ভাল মেশিন লার্নিং পদ্ধতি আপনার জন্য মডেল নির্ধারণ করে । আপনি যদি সঠিক মেশিন লার্নিং মডেল টাইপের মধ্যে যথেষ্ট প্রতিনিধি উদাহরণ প্রদান করেন, তাহলে প্রোগ্রামটি আপনার জন্য সম্পর্ক খুঁজে বের করবে।
মডেল নির্বাচন করুন
আমাদের প্রশিক্ষণের জন্য মডেল নির্বাচন করতে হবে। অনেক ধরণের মডেল রয়েছে এবং একটি ভাল বাছাই করতে অভিজ্ঞতা লাগে। এই টিউটোরিয়ালটি আইরিস শ্রেণীবিভাগ সমস্যা সমাধানের জন্য একটি নিউরাল নেটওয়ার্ক ব্যবহার করে। নিউরাল নেটওয়ার্ক বৈশিষ্ট্য এবং লেবেলের মধ্যে জটিল সম্পর্ক খুঁজে পেতে পারে। এটি একটি উচ্চ-গঠিত গ্রাফ, এক বা একাধিক লুকানো স্তরে সংগঠিত। প্রতিটি লুকানো স্তর এক বা একাধিক নিউরন নিয়ে গঠিত। নিউরাল নেটওয়ার্কের বেশ কয়েকটি বিভাগ রয়েছে এবং এই প্রোগ্রামটি একটি ঘন, বা সম্পূর্ণ-সংযুক্ত নিউরাল নেটওয়ার্ক ব্যবহার করে: একটি স্তরের নিউরনগুলি পূর্ববর্তী স্তরের প্রতিটি নিউরন থেকে ইনপুট সংযোগ গ্রহণ করে। উদাহরণস্বরূপ, চিত্র 2 একটি ইনপুট স্তর, দুটি লুকানো স্তর এবং একটি আউটপুট স্তর সমন্বিত একটি ঘন নিউরাল নেটওয়ার্ককে চিত্রিত করে:
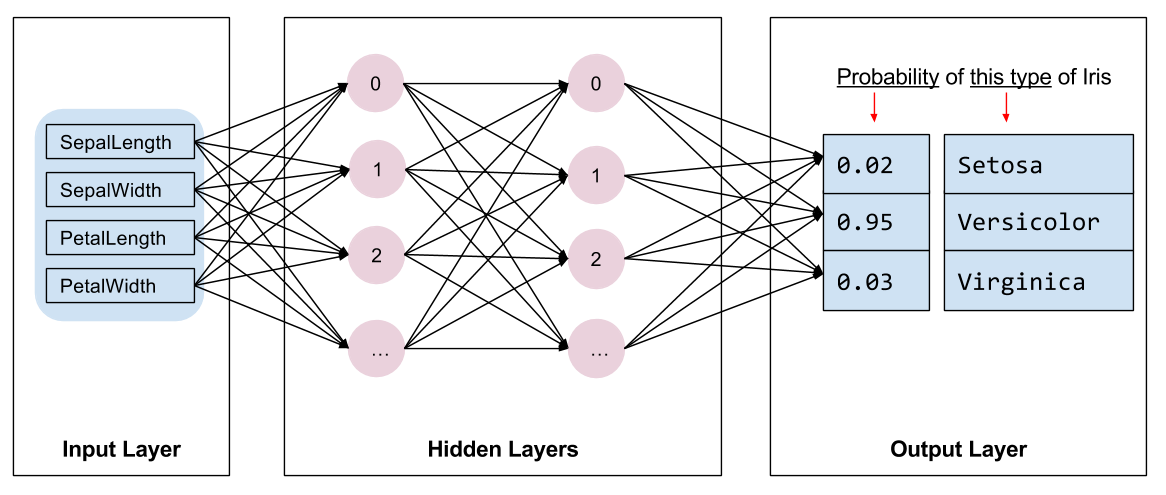 |
| চিত্র 2. বৈশিষ্ট্য, লুকানো স্তর এবং পূর্বাভাস সহ একটি নিউরাল নেটওয়ার্ক। |
যখন চিত্র 2 থেকে মডেলটিকে প্রশিক্ষিত করা হয় এবং একটি লেবেলবিহীন উদাহরণ খাওয়ানো হয়, তখন এটি তিনটি ভবিষ্যদ্বাণী দেয়: সম্ভাবনা যে এই ফুলটি প্রদত্ত আইরিস প্রজাতি। এই ভবিষ্যদ্বাণীকে অনুমান বলা হয়। এই উদাহরণের জন্য, আউটপুট পূর্বাভাসের যোগফল হল 1.0। চিত্র 2-এ, এই ভবিষ্যদ্বাণীটি ভেঙে যায়: Iris setosa- এর জন্য 0.02 , Iris versicolor- এর জন্য 0.95 , এবং Iris virginica- এর জন্য 0.03 ৷ এর মানে হল মডেলটি ভবিষ্যদ্বাণী করেছে—৯৫% সম্ভাবনার সঙ্গে—যে একটি লেবেলবিহীন উদাহরণ ফুল হল একটি আইরিস ভার্সিকলার ।
টেনসরফ্লো ডিপ লার্নিং লাইব্রেরির জন্য সুইফট ব্যবহার করে একটি মডেল তৈরি করুন
সুইফ্ট ফর টেনসরফ্লো ডিপ লার্নিং লাইব্রেরি আদিম স্তরগুলিকে সংজ্ঞায়িত করে এবং সেগুলিকে একত্রিত করার জন্য কনভেনশনগুলিকে সংজ্ঞায়িত করে, যা মডেলগুলি তৈরি করা এবং পরীক্ষা করা সহজ করে তোলে৷
একটি মডেল হল একটি struct যা Layer সাথে মানানসই, যার মানে হল এটি একটি callAsFunction(_:) পদ্ধতিকে সংজ্ঞায়িত করে যা ইনপুট Tensor s কে Tensor s আউটপুট করতে ম্যাপ করে। callAsFunction(_:) পদ্ধতি প্রায়শই সাবলেয়ারের মাধ্যমে ইনপুটকে সিকোয়েন্স করে। আসুন একটি IrisModel সংজ্ঞায়িত করি যা তিনটি Dense সাবলেয়ারের মাধ্যমে ইনপুটকে সিকোয়েন্স করে।
import TensorFlow
let hiddenSize: Int = 10
struct IrisModel: Layer {
var layer1 = Dense<Float>(inputSize: 4, outputSize: hiddenSize, activation: relu)
var layer2 = Dense<Float>(inputSize: hiddenSize, outputSize: hiddenSize, activation: relu)
var layer3 = Dense<Float>(inputSize: hiddenSize, outputSize: 3)
@differentiable
func callAsFunction(_ input: Tensor<Float>) -> Tensor<Float> {
return input.sequenced(through: layer1, layer2, layer3)
}
}
var model = IrisModel()
অ্যাক্টিভেশন ফাংশন স্তরের প্রতিটি নোডের আউটপুট আকৃতি নির্ধারণ করে। এই অ-রৈখিকতাগুলি গুরুত্বপূর্ণ—এগুলি ছাড়া মডেলটি একটি একক স্তরের সমতুল্য হবে৷ অনেকগুলি উপলব্ধ অ্যাক্টিভেশন রয়েছে, তবে লুকানো স্তরগুলির জন্য ReLU সাধারণ।
লুকানো স্তর এবং নিউরনের আদর্শ সংখ্যা সমস্যা এবং ডেটাসেটের উপর নির্ভর করে। মেশিন লার্নিংয়ের অনেক দিকগুলির মতো, নিউরাল নেটওয়ার্কের সর্বোত্তম আকৃতি বাছাই করার জন্য জ্ঞান এবং পরীক্ষা-নিরীক্ষার মিশ্রণ প্রয়োজন। একটি সাধারণ নিয়ম হিসাবে, লুকানো স্তর এবং নিউরনের সংখ্যা বৃদ্ধি সাধারণত একটি আরও শক্তিশালী মডেল তৈরি করে, যার জন্য কার্যকরভাবে প্রশিক্ষণের জন্য আরও ডেটা প্রয়োজন।
মডেল ব্যবহার করে
আসুন এই মডেলটি বৈশিষ্ট্যগুলির একটি ব্যাচের সাথে কী করে তা দ্রুত দেখে নেওয়া যাক:
// Apply the model to a batch of features.
let firstTrainPredictions = model(firstTrainFeatures)
print(firstTrainPredictions[0..<5])
[[ 1.1514063, -0.7520321, -0.6730235], [ 1.4915676, -0.9158071, -0.9957161], [ 1.0549936, -0.7799266, -0.410466], [ 1.1725322, -0.69009197, -0.8345413], [ 1.4870572, -0.8644099, -1.0958937]]
এখানে, প্রতিটি উদাহরণ প্রতিটি ক্লাসের জন্য একটি লগিট প্রদান করে।
প্রতিটি শ্রেণীর জন্য এই লগিটগুলিকে একটি সম্ভাব্যতায় রূপান্তর করতে, সফটম্যাক্স ফাংশনটি ব্যবহার করুন:
print(softmax(firstTrainPredictions[0..<5]))
[[ 0.7631462, 0.11375094, 0.123102814], [ 0.8523791, 0.076757915, 0.07086295], [ 0.7191151, 0.11478964, 0.16609532], [ 0.77540654, 0.12039323, 0.10420021], [ 0.8541314, 0.08133837, 0.064530246]]
ক্লাস জুড়ে argmax নেওয়া আমাদের পূর্বাভাসিত ক্লাস সূচক দেয়। কিন্তু, মডেলটি এখনও প্রশিক্ষিত হয়নি, তাই এগুলি ভাল ভবিষ্যদ্বাণী নয়।
print("Prediction: \(firstTrainPredictions.argmax(squeezingAxis: 1))")
print(" Labels: \(firstTrainLabels)")
Prediction: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1]
মডেলকে প্রশিক্ষণ দিন
প্রশিক্ষণ হল মেশিন লার্নিং এর পর্যায় যখন মডেলটি ধীরে ধীরে অপ্টিমাইজ করা হয়, বা মডেল ডেটাসেট শিখে । লক্ষ্য হল অদেখা ডেটা সম্পর্কে ভবিষ্যদ্বাণী করার জন্য প্রশিক্ষণ ডেটাসেটের কাঠামো সম্পর্কে পর্যাপ্ত জ্ঞান অর্জন করা। আপনি যদি প্রশিক্ষণ ডেটাসেট সম্পর্কে খুব বেশি কিছু শিখেন, তাহলে ভবিষ্যদ্বাণীগুলি কেবলমাত্র এটি দেখা ডেটার জন্য কাজ করে এবং সাধারণীকরণযোগ্য হবে না। এই সমস্যাটিকে ওভারফিটিং বলা হয়—এটি একটি সমস্যার সমাধান কীভাবে করা যায় তা বোঝার পরিবর্তে উত্তরগুলি মুখস্থ করার মতো।
আইরিস শ্রেণীবিভাগ সমস্যা হল তত্ত্বাবধানে মেশিন লার্নিং এর একটি উদাহরণ: মডেলটি এমন উদাহরণ থেকে প্রশিক্ষিত হয় যেখানে লেবেল রয়েছে। তত্ত্বাবধানহীন মেশিন লার্নিং- এ, উদাহরণগুলিতে লেবেল থাকে না। পরিবর্তে, মডেলটি সাধারণত বৈশিষ্ট্যগুলির মধ্যে নিদর্শন খুঁজে পায়।
একটি ক্ষতি ফাংশন চয়ন করুন
প্রশিক্ষণ এবং মূল্যায়ন উভয় পর্যায়েই মডেলের ক্ষতি গণনা করা প্রয়োজন। এটি পরিমাপ করে যে মডেলের ভবিষ্যদ্বাণীগুলি পছন্দসই লেবেল থেকে কতটা বন্ধ, অন্য কথায়, মডেলটি কতটা খারাপ পারফর্ম করছে৷ আমরা এই মানটি কমাতে বা অপ্টিমাইজ করতে চাই।
আমাদের মডেল softmaxCrossEntropy(logits:labels:) ফাংশন ব্যবহার করে এর ক্ষতি গণনা করবে যা মডেলের শ্রেণী সম্ভাব্যতা পূর্বাভাস এবং পছন্দসই লেবেল নেয় এবং উদাহরণ জুড়ে গড় ক্ষতি ফেরত দেয়।
চলুন বর্তমান অপ্রশিক্ষিত মডেলের জন্য ক্ষতি গণনা করা যাক:
let untrainedLogits = model(firstTrainFeatures)
let untrainedLoss = softmaxCrossEntropy(logits: untrainedLogits, labels: firstTrainLabels)
print("Loss test: \(untrainedLoss)")
Loss test: 1.7598655
একটি অপ্টিমাইজার তৈরি করুন
একটি অপ্টিমাইজার loss ফাংশন কমানোর জন্য মডেলের ভেরিয়েবলে গণনা করা গ্রেডিয়েন্ট প্রয়োগ করে। আপনি ক্ষতি ফাংশনটিকে একটি বাঁকা পৃষ্ঠ হিসাবে ভাবতে পারেন (চিত্র 3 দেখুন) এবং আমরা চারপাশে হেঁটে এর সর্বনিম্ন বিন্দু খুঁজে পেতে চাই। গ্রেডিয়েন্টগুলি খাড়া চড়ার দিকে নির্দেশ করে—তাই আমরা বিপরীত পথে ভ্রমণ করব এবং পাহাড়ের নিচে চলে যাব। পুনরাবৃত্তিমূলকভাবে প্রতিটি ব্যাচের জন্য ক্ষতি এবং গ্রেডিয়েন্ট গণনা করে, আমরা প্রশিক্ষণের সময় মডেলটি সামঞ্জস্য করব। ধীরে ধীরে, মডেলটি ক্ষতি কমাতে ওজন এবং পক্ষপাতের সর্বোত্তম সমন্বয় খুঁজে পাবে। এবং ক্ষতি যত কম হবে, মডেলের ভবিষ্যদ্বাণী তত ভাল হবে।
 |
| চিত্র 3. অপ্টিমাইজেশান অ্যালগরিদমগুলি 3D স্পেসে সময়ের সাথে সাথে কল্পনা করা হয়েছে৷ (সূত্র: স্ট্যানফোর্ড ক্লাস CS231n , MIT লাইসেন্স, চিত্র ক্রেডিট: অ্যালেক র্যাডফোর্ড ) |
টেনসরফ্লো-এর জন্য সুইফট-এ প্রশিক্ষণের জন্য অনেক অপ্টিমাইজেশান অ্যালগরিদম উপলব্ধ রয়েছে। এই মডেলটি SGD অপ্টিমাইজার ব্যবহার করে যা স্টোকাস্টিক গ্রেডিয়েন্ট ডিসেন্ট (SGD) অ্যালগরিদম প্রয়োগ করে। learningRate পাহাড়ের নিচে প্রতিটি পুনরাবৃত্তির জন্য ধাপের আকার নির্ধারণ করে। এটি একটি হাইপারপ্যারামিটার যা আপনি সাধারণত আরও ভাল ফলাফল অর্জনের জন্য সামঞ্জস্য করবেন।
let optimizer = SGD(for: model, learningRate: 0.01)
একটি একক গ্রেডিয়েন্ট ডিসেন্ট পদক্ষেপ নিতে optimizer ব্যবহার করা যাক। প্রথমত, আমরা মডেলের সাপেক্ষে ক্ষতির গ্রেডিয়েন্ট গণনা করি:
let (loss, grads) = valueWithGradient(at: model) { model -> Tensor<Float> in
let logits = model(firstTrainFeatures)
return softmaxCrossEntropy(logits: logits, labels: firstTrainLabels)
}
print("Current loss: \(loss)")
Current loss: 1.7598655
এর পরে, আমরা গ্রেডিয়েন্টটি পাস করি যা আমরা কেবলমাত্র অপ্টিমাইজারে গণনা করেছি, যা সেই অনুযায়ী মডেলের পার্থক্যযোগ্য ভেরিয়েবলগুলিকে আপডেট করে:
optimizer.update(&model, along: grads)
যদি আমরা আবার ক্ষতি গণনা করি, তবে এটি ছোট হওয়া উচিত, কারণ গ্রেডিয়েন্ট ডিসেন্ট ধাপগুলি (সাধারণত) ক্ষতি হ্রাস করে:
let logitsAfterOneStep = model(firstTrainFeatures)
let lossAfterOneStep = softmaxCrossEntropy(logits: logitsAfterOneStep, labels: firstTrainLabels)
print("Next loss: \(lossAfterOneStep)")
Next loss: 1.5318773
প্রশিক্ষণ লুপ
জায়গায় সব টুকরা সঙ্গে, মডেল প্রশিক্ষণের জন্য প্রস্তুত! একটি প্রশিক্ষণ লুপ মডেলটিতে ডেটাসেট উদাহরণগুলিকে ফিড করে যাতে এটি আরও ভাল ভবিষ্যদ্বাণী করতে সহায়তা করে। নিম্নলিখিত কোড ব্লক এই প্রশিক্ষণ পদক্ষেপ সেট আপ করে:
- প্রতিটি যুগে পুনরাবৃত্তি করুন। একটি যুগ হল ডেটাসেটের মধ্য দিয়ে এক পাস।
- একটি যুগের মধ্যে, প্রশিক্ষণ যুগের প্রতিটি ব্যাচের উপর পুনরাবৃত্তি করুন
- ব্যাচটি সমন্বিত করুন এবং এর বৈশিষ্ট্যগুলি (
x) এবং লেবেল (y) ধরুন। - সমন্বিত ব্যাচের বৈশিষ্ট্যগুলি ব্যবহার করে, একটি ভবিষ্যদ্বাণী করুন এবং লেবেলের সাথে এটি তুলনা করুন৷ ভবিষ্যদ্বাণীর ভুলতা পরিমাপ করুন এবং মডেলের ক্ষতি এবং গ্রেডিয়েন্ট গণনা করতে এটি ব্যবহার করুন।
- মডেলের ভেরিয়েবল আপডেট করতে গ্রেডিয়েন্ট ডিসেন্ট ব্যবহার করুন।
- ভিজ্যুয়ালাইজেশন জন্য কিছু পরিসংখ্যান ট্র্যাক রাখুন.
- প্রতিটি যুগের জন্য পুনরাবৃত্তি করুন।
epochCount ভেরিয়েবল হল ডেটাসেট সংগ্রহের উপর লুপ করার সংখ্যা। কাউন্টার-স্বজ্ঞাতভাবে, একটি মডেলকে দীর্ঘক্ষণ প্রশিক্ষণ দেওয়া একটি ভাল মডেলের গ্যারান্টি দেয় না। epochCount একটি হাইপারপ্যারামিটার যা আপনি টিউন করতে পারেন। সঠিক সংখ্যা নির্বাচন করার জন্য সাধারণত অভিজ্ঞতা এবং পরীক্ষা উভয়েরই প্রয়োজন হয়।
let epochCount = 500
var trainAccuracyResults: [Float] = []
var trainLossResults: [Float] = []
func accuracy(predictions: Tensor<Int32>, truths: Tensor<Int32>) -> Float {
return Tensor<Float>(predictions .== truths).mean().scalarized()
}
for (epochIndex, epoch) in trainingEpochs.prefix(epochCount).enumerated() {
var epochLoss: Float = 0
var epochAccuracy: Float = 0
var batchCount: Int = 0
for batchSamples in epoch {
let batch = batchSamples.collated
let (loss, grad) = valueWithGradient(at: model) { (model: IrisModel) -> Tensor<Float> in
let logits = model(batch.features)
return softmaxCrossEntropy(logits: logits, labels: batch.labels)
}
optimizer.update(&model, along: grad)
let logits = model(batch.features)
epochAccuracy += accuracy(predictions: logits.argmax(squeezingAxis: 1), truths: batch.labels)
epochLoss += loss.scalarized()
batchCount += 1
}
epochAccuracy /= Float(batchCount)
epochLoss /= Float(batchCount)
trainAccuracyResults.append(epochAccuracy)
trainLossResults.append(epochLoss)
if epochIndex % 50 == 0 {
print("Epoch \(epochIndex): Loss: \(epochLoss), Accuracy: \(epochAccuracy)")
}
}
Epoch 0: Loss: 1.475254, Accuracy: 0.34375 Epoch 50: Loss: 0.91668004, Accuracy: 0.6458333 Epoch 100: Loss: 0.68662673, Accuracy: 0.6979167 Epoch 150: Loss: 0.540665, Accuracy: 0.6979167 Epoch 200: Loss: 0.46283028, Accuracy: 0.6979167 Epoch 250: Loss: 0.4134724, Accuracy: 0.8229167 Epoch 300: Loss: 0.35054502, Accuracy: 0.8958333 Epoch 350: Loss: 0.2731444, Accuracy: 0.9375 Epoch 400: Loss: 0.23622067, Accuracy: 0.96875 Epoch 450: Loss: 0.18956228, Accuracy: 0.96875
সময়ের সাথে ক্ষতির ফাংশনটি কল্পনা করুন
মডেলের প্রশিক্ষণের অগ্রগতি মুদ্রণ করা সহায়ক হলেও, এই অগ্রগতি দেখতে প্রায়ই আরও সহায়ক। আমরা পাইথনের matplotlib মডিউল ব্যবহার করে মৌলিক চার্ট তৈরি করতে পারি।
এই চার্টগুলিকে ব্যাখ্যা করার জন্য কিছু অভিজ্ঞতা লাগে, কিন্তু আপনি সত্যিই দেখতে চান যে ক্ষতি কমে যায় এবং নির্ভুলতা বেড়ে যায়।
plt.figure(figsize: [12, 8])
let accuracyAxes = plt.subplot(2, 1, 1)
accuracyAxes.set_ylabel("Accuracy")
accuracyAxes.plot(trainAccuracyResults)
let lossAxes = plt.subplot(2, 1, 2)
lossAxes.set_ylabel("Loss")
lossAxes.set_xlabel("Epoch")
lossAxes.plot(trainLossResults)
plt.show()
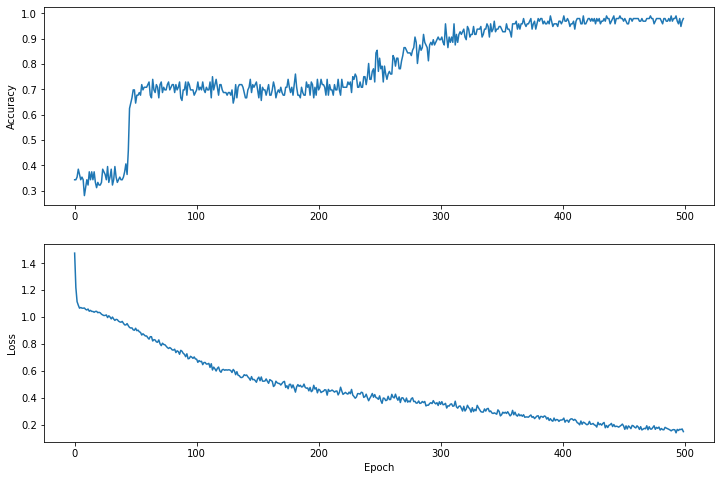
Use `print()` to show values.
উল্লেখ্য যে গ্রাফগুলির y-অক্ষগুলি শূন্য-ভিত্তিক নয়।
মডেলের কার্যকারিতা মূল্যায়ন করুন
এখন যেহেতু মডেলটি প্রশিক্ষিত, আমরা এর কার্যকারিতার কিছু পরিসংখ্যান পেতে পারি।
মূল্যায়ন মানে মডেলটি কতটা কার্যকরভাবে ভবিষ্যদ্বাণী করে তা নির্ধারণ করা। আইরিস শ্রেণীবিভাগে মডেলের কার্যকারিতা নির্ধারণ করতে, মডেলের কাছে কিছু সেপাল এবং পাপড়ি পরিমাপ পাস করুন এবং মডেলকে ভবিষ্যদ্বাণী করতে বলুন যে তারা কোন আইরিস প্রজাতির প্রতিনিধিত্ব করে। তারপর প্রকৃত লেবেলের বিপরীতে মডেলের ভবিষ্যদ্বাণী তুলনা করুন। উদাহরণস্বরূপ, অর্ধেক ইনপুট উদাহরণে সঠিক প্রজাতি বাছাই করা একটি মডেলের যথার্থতা 0.5 । চিত্র 4 একটি সামান্য বেশি কার্যকরী মডেল দেখায়, 80% নির্ভুলতায় 5টির মধ্যে 4টি ভবিষ্যদ্বাণী সঠিক হয়েছে:
| উদাহরণ বৈশিষ্ট্য | লেবেল | মডেল ভবিষ্যদ্বাণী | |||
|---|---|---|---|---|---|
| ৫.৯ | 3.0 | 4.3 | 1.5 | 1 | 1 |
| ৬.৯ | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| চিত্র 4. একটি আইরিস ক্লাসিফায়ার যা 80% সঠিক। | |||||
পরীক্ষার ডেটাসেট সেটআপ করুন
মডেলের মূল্যায়ন মডেল প্রশিক্ষণের অনুরূপ। সবচেয়ে বড় পার্থক্য হল উদাহরণগুলি প্রশিক্ষণ সেটের পরিবর্তে একটি পৃথক পরীক্ষার সেট থেকে আসে। একটি মডেলের কার্যকারিতা মোটামুটিভাবে মূল্যায়ন করার জন্য, একটি মডেলের মূল্যায়ন করার জন্য ব্যবহৃত উদাহরণগুলি মডেলটিকে প্রশিক্ষণের জন্য ব্যবহৃত উদাহরণ থেকে আলাদা হতে হবে।
পরীক্ষার ডেটাসেটের সেটআপ প্রশিক্ষণ ডেটাসেটের সেটআপের অনুরূপ। http://download.tensorflow.org/data/iris_test.csv থেকে পরীক্ষার সেট ডাউনলোড করুন:
let testDataFilename = "iris_test.csv"
download(from: "http://download.tensorflow.org/data/iris_test.csv", to: testDataFilename)
এখন এটিকে IrisBatch es-এর একটি অ্যারেতে লোড করুন:
let testDataset = loadIrisDatasetFromCSV(
contentsOf: testDataFilename, hasHeader: true,
featureColumns: [0, 1, 2, 3], labelColumns: [4]).inBatches(of: batchSize)
পরীক্ষার ডেটাসেটে মডেলটি মূল্যায়ন করুন
প্রশিক্ষণ পর্যায়ে ভিন্ন, মডেল শুধুমাত্র পরীক্ষার ডেটার একটি একক যুগের মূল্যায়ন করে। নিম্নলিখিত কোড কক্ষে, আমরা পরীক্ষার সেটের প্রতিটি উদাহরণের উপর পুনরাবৃত্তি করি এবং প্রকৃত লেবেলের সাথে মডেলের পূর্বাভাস তুলনা করি। এটি সম্পূর্ণ পরীক্ষা সেট জুড়ে মডেলের নির্ভুলতা পরিমাপ করতে ব্যবহৃত হয়।
// NOTE: Only a single batch will run in the loop since the batchSize we're using is larger than the test set size
for batchSamples in testDataset {
let batch = batchSamples.collated
let logits = model(batch.features)
let predictions = logits.argmax(squeezingAxis: 1)
print("Test batch accuracy: \(accuracy(predictions: predictions, truths: batch.labels))")
}
Test batch accuracy: 0.96666664
আমরা প্রথম ব্যাচে দেখতে পারি, উদাহরণস্বরূপ, মডেলটি সাধারণত সঠিক:
let firstTestBatch = testDataset.first!.collated
let firstTestBatchLogits = model(firstTestBatch.features)
let firstTestBatchPredictions = firstTestBatchLogits.argmax(squeezingAxis: 1)
print(firstTestBatchPredictions)
print(firstTestBatch.labels)
[1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 2, 1, 1, 0, 1, 2, 1] [1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 1, 1, 1, 0, 1, 2, 1]
ভবিষ্যদ্বাণী করতে প্রশিক্ষিত মডেল ব্যবহার করুন
আমরা একটি মডেলকে প্রশিক্ষিত করেছি এবং দেখিয়েছি যে আইরিস প্রজাতির শ্রেণীবিভাগে এটি ভাল - কিন্তু নিখুঁত নয়। এখন লেবেলবিহীন উদাহরণে কিছু ভবিষ্যদ্বাণী করতে প্রশিক্ষিত মডেল ব্যবহার করা যাক; অর্থাৎ, বৈশিষ্ট্য ধারণ করে এমন উদাহরণে কিন্তু লেবেল নয়।
বাস্তব জীবনে, লেবেলবিহীন উদাহরণগুলি অ্যাপ, CSV ফাইল এবং ডেটা ফিড সহ অনেকগুলি বিভিন্ন উত্স থেকে আসতে পারে৷ আপাতত, আমরা তাদের লেবেলগুলির পূর্বাভাস দিতে ম্যানুয়ালি তিনটি লেবেলবিহীন উদাহরণ প্রদান করতে যাচ্ছি। স্মরণ করুন, লেবেল নম্বরগুলি একটি নামযুক্ত প্রতিনিধিত্বের সাথে ম্যাপ করা হয়েছে:
-
0: আইরিস সেটোসা -
1: আইরিস ভার্সিকলার -
2: আইরিস ভার্জিনিকা
let unlabeledDataset: Tensor<Float> =
[[5.1, 3.3, 1.7, 0.5],
[5.9, 3.0, 4.2, 1.5],
[6.9, 3.1, 5.4, 2.1]]
let unlabeledDatasetPredictions = model(unlabeledDataset)
for i in 0..<unlabeledDatasetPredictions.shape[0] {
let logits = unlabeledDatasetPredictions[i]
let classIdx = logits.argmax().scalar!
print("Example \(i) prediction: \(classNames[Int(classIdx)]) (\(softmax(logits)))")
}
Example 0 prediction: Iris setosa ([ 0.98731947, 0.012679046, 1.4035809e-06]) Example 1 prediction: Iris versicolor ([0.005065103, 0.85957265, 0.13536224]) Example 2 prediction: Iris virginica ([2.9613977e-05, 0.2637373, 0.73623306])