
Visão geral
O principal recurso do TensorBoard é sua GUI interativa. No entanto, às vezes os usuários querem ler programaticamente os registros de dados armazenados em TensorBoard, para fins tais como a realização de análises post-hoc e criar visualizações personalizadas dos dados de registo.
TensorBoard 2,3 suportes este caso de uso com tensorboard.data.experimental.ExperimentFromDev() . Ele permite acesso programático a de TensorBoard registros escalares . Esta página demonstra o uso básico desta nova API.
Configurar
Para utilizar a API programática, certifique-se de instalar pandas ao lado tensorboard .
Usaremos matplotlib e seaborn para parcelas personalizados neste guia, mas você pode escolher seu instrumento preferido para analisar e visualizar DataFrame s.
pip install tensorboard pandaspip install matplotlib seaborn
from packaging import version
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
from scipy import stats
import tensorboard as tb
major_ver, minor_ver, _ = version.parse(tb.__version__).release
assert major_ver >= 2 and minor_ver >= 3, \
"This notebook requires TensorBoard 2.3 or later."
print("TensorBoard version: ", tb.__version__)
TensorBoard version: 2.3.0a20200626
Carregando escalares TensorBoard como um pandas.DataFrame
Uma vez que um logdir TensorBoard foi carregado para TensorBoard.dev, torna-se aquilo que se referem como um experimento. Cada experimento tem um ID exclusivo, que pode ser encontrado no URL TensorBoard.dev do experimento. Para a nossa demonstração abaixo, vamos usar um experimento de TensorBoard.dev em: https://tensorboard.dev/experiment/c1KCv3X3QvGwaXfgX1c4tg
experiment_id = "c1KCv3X3QvGwaXfgX1c4tg"
experiment = tb.data.experimental.ExperimentFromDev(experiment_id)
df = experiment.get_scalars()
df
df é um pandas.DataFrame que contém todos os registros escalares do experimento.
As colunas da DataFrame são:
-
run: cada um corresponde executar a um subdiretório do logdir originais. Neste experimento, cada execução é de um treinamento completo de uma rede neural convolucional (CNN) no conjunto de dados MNIST com um determinado tipo de otimizador (um hiperparâmetro de treinamento). EstaDataFramecontém múltiplos tais execuções, o que corresponde a pistas de formação repetidas sob diferentes tipos optimizer. -
tag: esta descreve o que ovalueno mesmo meio de linhas, ou seja, que o valor da métrica representa na linha. Neste experimento, temos apenas duas marcas exclusivas:epoch_accuracyeepoch_losspela precisão e perda de métricas, respectivamente. -
step: Este é um número que reflete a ordem de série da linha correspondente no seu funcionamento. Aquisteprealmente se refere ao número de época. Se você deseja obter a data e hora, além dosstepvalores, você pode usar a palavra-chave argumentoinclude_wall_time=Trueao chamarget_scalars(). -
value: Este é o valor numérico real de juros. Como descrito acima, cadavaluenesse particularDataFrameé uma qualquer perda ou uma precisão, dependendo datagda linha.
print(df["run"].unique())
print(df["tag"].unique())
['adam,run_1/train' 'adam,run_1/validation' 'adam,run_2/train' 'adam,run_2/validation' 'adam,run_3/train' 'adam,run_3/validation' 'adam,run_4/train' 'adam,run_4/validation' 'adam,run_5/train' 'adam,run_5/validation' 'rmsprop,run_1/train' 'rmsprop,run_1/validation' 'rmsprop,run_2/train' 'rmsprop,run_2/validation' 'rmsprop,run_3/train' 'rmsprop,run_3/validation' 'rmsprop,run_4/train' 'rmsprop,run_4/validation' 'rmsprop,run_5/train' 'rmsprop,run_5/validation' 'sgd,run_1/train' 'sgd,run_1/validation' 'sgd,run_2/train' 'sgd,run_2/validation' 'sgd,run_3/train' 'sgd,run_3/validation' 'sgd,run_4/train' 'sgd,run_4/validation' 'sgd,run_5/train' 'sgd,run_5/validation'] ['epoch_accuracy' 'epoch_loss']
Obtendo um DataFrame dinâmico (formato amplo)
Na nossa experiência, as duas etiquetas ( epoch_loss e epoch_accuracy ) estão presentes no mesmo conjunto de passos em cada execução. Isto faz com que seja possível obter uma "vasta-forma" DataFrame directamente a partir get_scalars() usando o pivot=True argumento palavra-chave. A ampla forma DataFrame tem todas as suas marcas incluídos como colunas da trama de dados, o que é mais conveniente para trabalhar com, em alguns casos, incluindo este.
No entanto, cuidado que se a condição de ter conjuntos de uniformes de valores passo em todas as marcas em todas as corridas não for atendida, usando pivot=True irá resultar em um erro.
dfw = experiment.get_scalars(pivot=True)
dfw
Note-se que em vez de uma única coluna "valor", a toda a forma de trama de dados inclui as duas etiquetas (métricas) como suas colunas explicitamente: epoch_accuracy e epoch_loss .
Salvando o DataFrame como CSV
pandas.DataFrame tem boa interoperabilidade com CSV . Você pode armazená-lo como um arquivo CSV local e carregá-lo novamente mais tarde. Por exemplo:
csv_path = '/tmp/tb_experiment_1.csv'
dfw.to_csv(csv_path, index=False)
dfw_roundtrip = pd.read_csv(csv_path)
pd.testing.assert_frame_equal(dfw_roundtrip, dfw)
Execução de visualização personalizada e análise estatística
# Filter the DataFrame to only validation data, which is what the subsequent
# analyses and visualization will be focused on.
dfw_validation = dfw[dfw.run.str.endswith("/validation")]
# Get the optimizer value for each row of the validation DataFrame.
optimizer_validation = dfw_validation.run.apply(lambda run: run.split(",")[0])
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
sns.lineplot(data=dfw_validation, x="step", y="epoch_accuracy",
hue=optimizer_validation).set_title("accuracy")
plt.subplot(1, 2, 2)
sns.lineplot(data=dfw_validation, x="step", y="epoch_loss",
hue=optimizer_validation).set_title("loss")
Text(0.5, 1.0, 'loss')
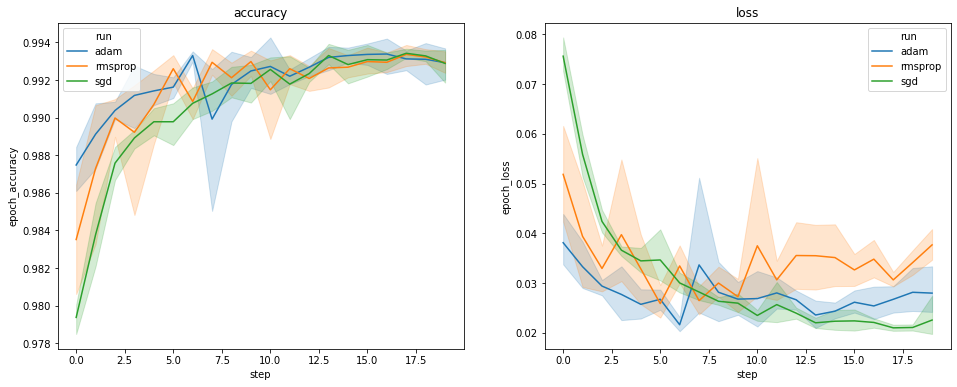
Os gráficos acima mostram os cursos de tempo de precisão e perda de validação. Cada curva mostra a média em 5 execuções em um tipo de otimizador. Graças a uma característica embutido de seaborn.lineplot() , cada curva também exibe ± um desvio padrão em torno da média, o que nos dá uma ideia clara do variabilidade nestas curvas e a significância das diferenças entre os três tipos optimizer. Essa visualização da variabilidade ainda não é compatível com a GUI do TensorBoard.
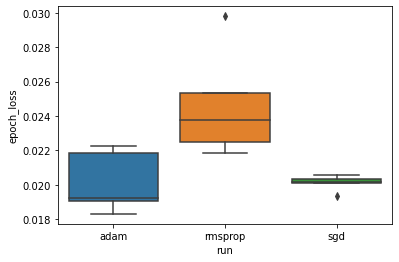
Queremos estudar a hipótese de que a perda mínima de validação difere significativamente entre os otimizadores "adam", "rmsprop" e "sgd". Portanto, extraímos um DataFrame para a perda mínima de validação em cada um dos otimizadores.
Em seguida, fazemos um boxplot para visualizar a diferença nas perdas mínimas de validação.
adam_min_val_loss = dfw_validation.loc[optimizer_validation=="adam", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
rmsprop_min_val_loss = dfw_validation.loc[optimizer_validation=="rmsprop", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
sgd_min_val_loss = dfw_validation.loc[optimizer_validation=="sgd", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
min_val_loss = pd.concat([adam_min_val_loss, rmsprop_min_val_loss, sgd_min_val_loss])
sns.boxplot(data=min_val_loss, y="epoch_loss",
x=min_val_loss.run.apply(lambda run: run.split(",")[0]))
<matplotlib.axes._subplots.AxesSubplot at 0x7f5e017c8150>
# Perform pairwise comparisons between the minimum validation losses
# from the three optimizers.
_, p_adam_vs_rmsprop = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
rmsprop_min_val_loss["epoch_loss"])
_, p_adam_vs_sgd = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
_, p_rmsprop_vs_sgd = stats.ttest_ind(
rmsprop_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
print("adam vs. rmsprop: p = %.4f" % p_adam_vs_rmsprop)
print("adam vs. sgd: p = %.4f" % p_adam_vs_sgd)
print("rmsprop vs. sgd: p = %.4f" % p_rmsprop_vs_sgd)
adam vs. rmsprop: p = 0.0244 adam vs. sgd: p = 0.9749 rmsprop vs. sgd: p = 0.0135
Portanto, a um nível de significância de 0,05, nossa análise confirma nossa hipótese de que a perda mínima de validação é significativamente maior (ou seja, pior) no otimizador rmsprop em comparação com os outros dois otimizadores incluídos em nosso experimento.
Em resumo, este tutorial fornece um exemplo de como acessar os dados escalares como panda.DataFrame s de TensorBoard.dev. Ele demonstra o tipo de análises flexíveis e poderosas e visualização que você pode fazer com a DataFrame s.