
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
En el aprendizaje automático, para mejorar algo, a menudo es necesario poder medirlo. TensorBoard es una herramienta para proporcionar las medidas y visualizaciones necesarias durante el flujo de trabajo de aprendizaje automático. Permite rastrear métricas de experimentos como pérdida y precisión, visualizar el gráfico del modelo, proyectar incrustaciones en un espacio dimensional inferior y mucho más.
Esta guía de inicio rápido le mostrará cómo comenzar rápidamente con TensorBoard. Las guías restantes en este sitio web brindan más detalles sobre capacidades específicas, muchas de las cuales no se incluyen aquí.
# Load the TensorBoard notebook extension
%load_ext tensorboard
import tensorflow as tf
import datetime
# Clear any logs from previous runsrm -rf ./logs/
Utilizando el MNIST conjunto de datos como el ejemplo, normalizar los datos y escribir una función que crea un modelo simple de Keras para clasificar las imágenes en 10 clases.
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
def create_model():
return tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] - 0s 0us/step
Usando TensorBoard con Keras Model.fit ()
Al entrenar con Keras de Model.fit () , añadiendo el tf.keras.callbacks.TensorBoard devolución de llamada asegura que los registros son creados y almacenados. Además, permitir histograma cálculo cada época con histogram_freq=1 (esto es desactivada por defecto)
Coloque los registros en un subdirectorio con marca de tiempo para permitir una fácil selección de diferentes ejecuciones de entrenamiento.
model = create_model()
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
log_dir = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
model.fit(x=x_train,
y=y_train,
epochs=5,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback])
Train on 60000 samples, validate on 10000 samples Epoch 1/5 60000/60000 [==============================] - 15s 246us/sample - loss: 0.2217 - accuracy: 0.9343 - val_loss: 0.1019 - val_accuracy: 0.9685 Epoch 2/5 60000/60000 [==============================] - 14s 229us/sample - loss: 0.0975 - accuracy: 0.9698 - val_loss: 0.0787 - val_accuracy: 0.9758 Epoch 3/5 60000/60000 [==============================] - 14s 231us/sample - loss: 0.0718 - accuracy: 0.9771 - val_loss: 0.0698 - val_accuracy: 0.9781 Epoch 4/5 60000/60000 [==============================] - 14s 227us/sample - loss: 0.0540 - accuracy: 0.9820 - val_loss: 0.0685 - val_accuracy: 0.9795 Epoch 5/5 60000/60000 [==============================] - 14s 228us/sample - loss: 0.0433 - accuracy: 0.9862 - val_loss: 0.0623 - val_accuracy: 0.9823 <tensorflow.python.keras.callbacks.History at 0x7fc8a5ee02e8>
Inicie TensorBoard a través de la línea de comandos o dentro de la experiencia de una computadora portátil. Generalmente, las dos interfaces son iguales. En los portátiles, utilice el %tensorboard mágica línea. En la línea de comando, ejecute el mismo comando sin "%".
%tensorboard --logdir logs/fit
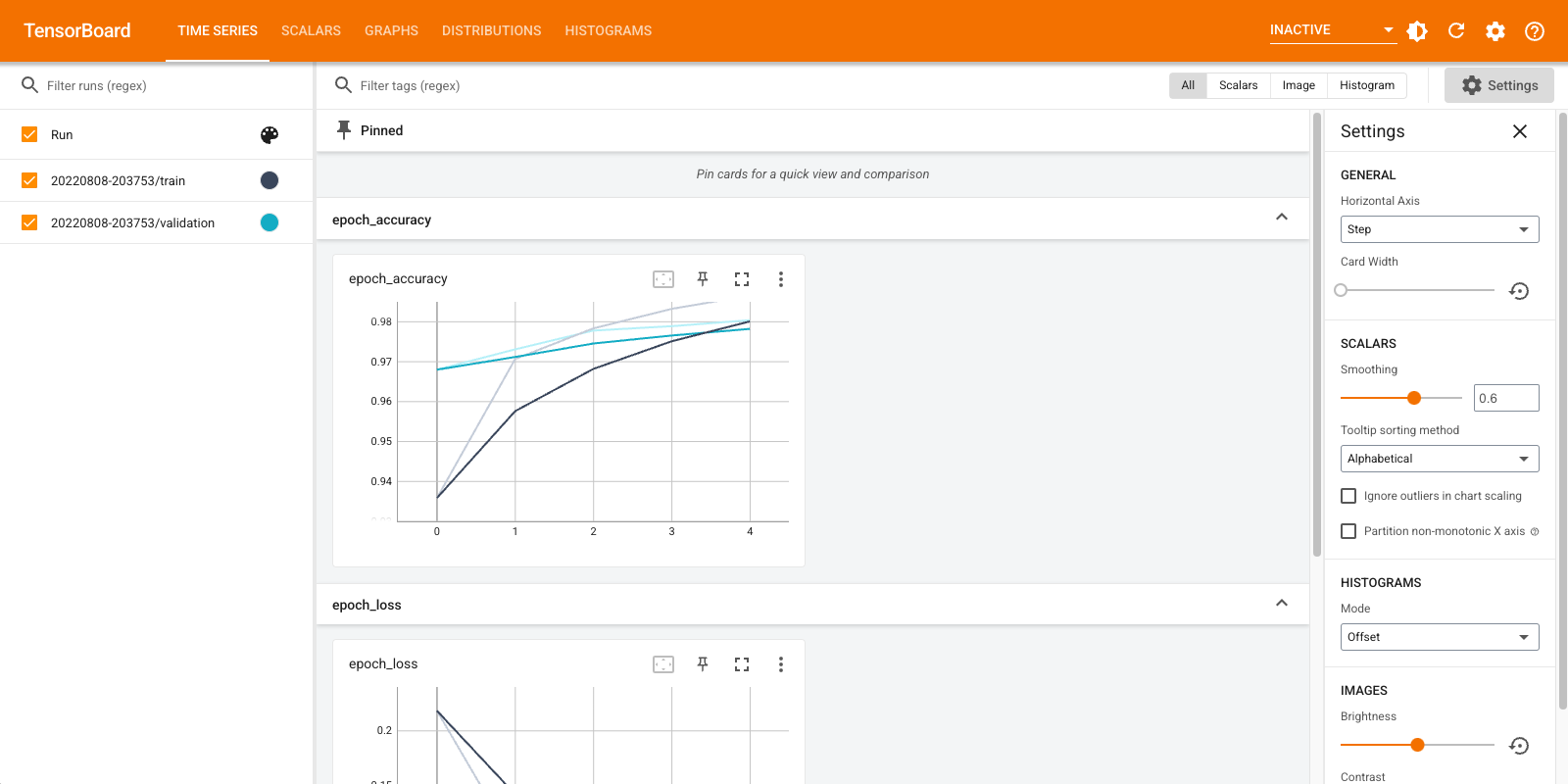
Una breve descripción general de los paneles que se muestran (pestañas en la barra de navegación superior):
- Los espectáculos del tablero de instrumentos escalares cómo la pérdida y la métrica cambian con cada época. También puede usarlo para realizar un seguimiento de la velocidad de entrenamiento, la tasa de aprendizaje y otros valores escalares.
- El tablero de instrumentos gráficos ayuda a visualizar su modelo. En este caso, se muestra el gráfico de capas de Keras que puede ayudarlo a asegurarse de que se construya correctamente.
- Las distribuciones e histogramas muestran la distribución cuadros de mando de un tensor con el tiempo. Esto puede resultar útil para visualizar ponderaciones y sesgos y verificar que estén cambiando de la forma esperada.
Los complementos de TensorBoard adicionales se habilitan automáticamente cuando registra otros tipos de datos. Por ejemplo, la devolución de llamada de Keras TensorBoard también le permite registrar imágenes e incrustaciones. Puedes ver qué otros complementos están disponibles en TensorBoard haciendo clic en el menú desplegable "inactivo" hacia la parte superior derecha.
Usar TensorBoard con otros métodos
Al entrenar con métodos tales como tf.GradientTape() , el uso tf.summary para registrar la información requerida.
Utilizar el mismo conjunto de datos que el anterior, pero convertirlo en tf.data.Dataset para aprovechar las capacidades de procesamiento por lotes:
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
train_dataset = train_dataset.shuffle(60000).batch(64)
test_dataset = test_dataset.batch(64)
El código de la formación sigue la guía de inicio rápido avanzado tutorial, pero muestra cómo acceder a las métricas TensorBoard. Elija pérdida y optimizador:
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()
Cree métricas con estado que se pueden usar para acumular valores durante el entrenamiento y registrarlas en cualquier momento:
# Define our metrics
train_loss = tf.keras.metrics.Mean('train_loss', dtype=tf.float32)
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('train_accuracy')
test_loss = tf.keras.metrics.Mean('test_loss', dtype=tf.float32)
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('test_accuracy')
Defina las funciones de entrenamiento y prueba:
def train_step(model, optimizer, x_train, y_train):
with tf.GradientTape() as tape:
predictions = model(x_train, training=True)
loss = loss_object(y_train, predictions)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
train_loss(loss)
train_accuracy(y_train, predictions)
def test_step(model, x_test, y_test):
predictions = model(x_test)
loss = loss_object(y_test, predictions)
test_loss(loss)
test_accuracy(y_test, predictions)
Configure redactores de resúmenes para escribir los resúmenes en el disco en un directorio de registros diferente:
current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
train_log_dir = 'logs/gradient_tape/' + current_time + '/train'
test_log_dir = 'logs/gradient_tape/' + current_time + '/test'
train_summary_writer = tf.summary.create_file_writer(train_log_dir)
test_summary_writer = tf.summary.create_file_writer(test_log_dir)
Empezar a entrenar. Utilice tf.summary.scalar() para registrar métricas (pérdida y precisión) durante el entrenamiento / prueba en el ámbito de los escritores de resumen para escribir los resúmenes en el disco. Tiene control sobre qué métricas registrar y con qué frecuencia hacerlo. Otros tf.summary funciones habilita el registro de otros tipos de datos.
model = create_model() # reset our model
EPOCHS = 5
for epoch in range(EPOCHS):
for (x_train, y_train) in train_dataset:
train_step(model, optimizer, x_train, y_train)
with train_summary_writer.as_default():
tf.summary.scalar('loss', train_loss.result(), step=epoch)
tf.summary.scalar('accuracy', train_accuracy.result(), step=epoch)
for (x_test, y_test) in test_dataset:
test_step(model, x_test, y_test)
with test_summary_writer.as_default():
tf.summary.scalar('loss', test_loss.result(), step=epoch)
tf.summary.scalar('accuracy', test_accuracy.result(), step=epoch)
template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'
print (template.format(epoch+1,
train_loss.result(),
train_accuracy.result()*100,
test_loss.result(),
test_accuracy.result()*100))
# Reset metrics every epoch
train_loss.reset_states()
test_loss.reset_states()
train_accuracy.reset_states()
test_accuracy.reset_states()
Epoch 1, Loss: 0.24321186542510986, Accuracy: 92.84333801269531, Test Loss: 0.13006582856178284, Test Accuracy: 95.9000015258789 Epoch 2, Loss: 0.10446818172931671, Accuracy: 96.84833526611328, Test Loss: 0.08867532759904861, Test Accuracy: 97.1199951171875 Epoch 3, Loss: 0.07096975296735764, Accuracy: 97.80166625976562, Test Loss: 0.07875105738639832, Test Accuracy: 97.48999786376953 Epoch 4, Loss: 0.05380449816584587, Accuracy: 98.34166717529297, Test Loss: 0.07712937891483307, Test Accuracy: 97.56999969482422 Epoch 5, Loss: 0.041443776339292526, Accuracy: 98.71833038330078, Test Loss: 0.07514958828687668, Test Accuracy: 97.5
Abra TensorBoard nuevamente, esta vez apuntándolo al nuevo directorio de registro. También podríamos haber iniciado TensorBoard para monitorear el entrenamiento mientras avanza.
%tensorboard --logdir logs/gradient_tape
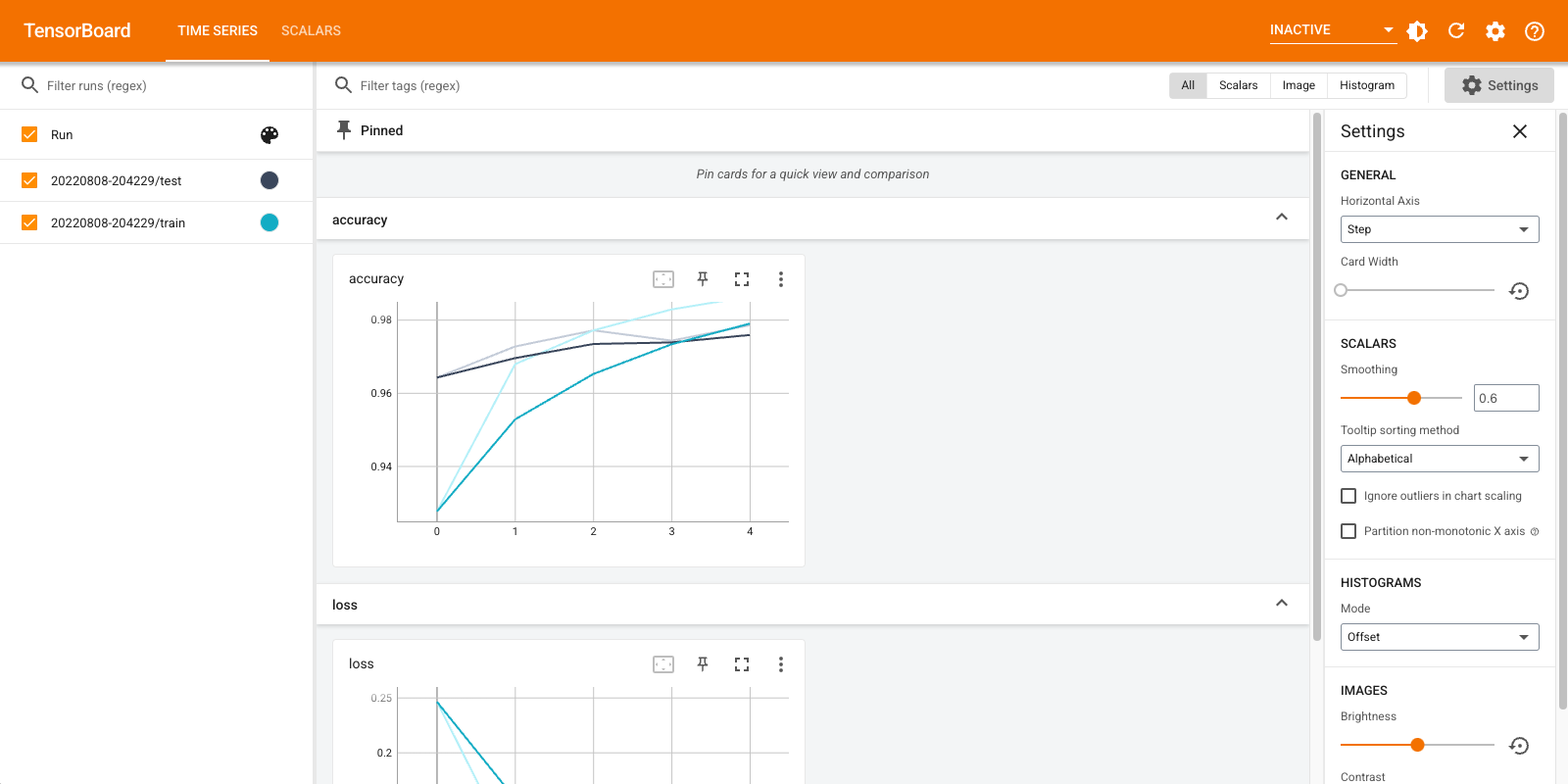
¡Eso es! Ahora ha visto cómo utilizar TensorBoard tanto a través de la devolución de llamada Keras ya través de tf.summary para más escenarios personalizados.
TensorBoard.dev: aloje y comparta los resultados de su experimento de AA
TensorBoard.dev es un servicio público y gratuito que le permite actualiza sus datos TensorBoard y obtener un enlace permanente que puede ser compartida con todos en trabajos académicos, blogs, redes sociales, etc. Esto puede permitir una mejor reproducibilidad y la colaboración.
Para usar TensorBoard.dev, ejecute el siguiente comando:
!tensorboard dev upload \
--logdir logs/fit \
--name "(optional) My latest experiment" \
--description "(optional) Simple comparison of several hyperparameters" \
--one_shot
Tenga en cuenta que esta invocación utiliza el prefijo de admiración ( ! ) Para invocar la cáscara y no al porcentaje prefijo ( % ) para invocar la magia colab. Al invocar este comando desde la línea de comandos, no es necesario ningún prefijo.
Ver un ejemplo aquí .
Para más detalles sobre cómo utilizar TensorBoard.dev, ver https://tensorboard.dev/#get-started