
| |
|
 GitHub でソースを表示 GitHub でソースを表示 |
機械学習モデルを構築する際、レイヤーのドロップアウト率や学習率などのさまざまなハイパーパラメータを選択する必要があります。この判断によって制度などのモデルメトリックに影響があります。したがって、問題に最適なハイパーパラメータを特定することが機械学習ワークフローの重要なステップであり、多くの場合、実験が伴います。このプロセスは「ハイパーパラメータ最適化」または「ハイパーパラメータ調整」として知られています。
TensorBoard の HParams ダッシュボードには、ハイパーパラメータの最適な実験または最も有望なセットを特定するプロセスを支援するツールがいくつか提供されています。
このチュートリアルでは、次のステップに焦点を当てています。
- セットアップと HParams の要約を実験する
- ハイパーパラメータとメトリックをログするように TensorFlow 実行を適応させる
- 実行を開始し、1 つの親ディレクトリにすべてをログする
- TensorBoard の HParams ダッシュボードに結果を視覚化する
注意: HParams summary API とダッシュボード UI はプレビュー段階であるため、いずれ変更されます。
TF 2.0 をインストールし、TensorBoard ノートブック拡張機能を読み込んで起動します。
# Load the TensorBoard notebook extension
%load_ext tensorboard
# Clear any logs from previous runsrm -rf ./logs/
TensorFlow と TensorBoard HParams プラグインをインポートします。
import tensorflow as tf
from tensorboard.plugins.hparams import api as hp
FashionMNIST データセットをダウンロードし、スケーリングします。
fashion_mnist = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion_mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 8192/5148 [===============================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step
1. セットアップと HParams の実験要約を実験する
モデルの 3 つのハイパーパラメータを使って実験します。
- 最初の密レイヤーのユニット数
- ドロップアウトレイヤーのドロップアウト率
- オプティマイザ
試す値をリストして、実験構成を TensorBoard にログします。このステップはオプションですが、UI でハイパーパラメータをより正確にフィルタリングして表示するメトリックを指定できるようにドメイン情報を指定することができます。
HP_NUM_UNITS = hp.HParam('num_units', hp.Discrete([16, 32]))
HP_DROPOUT = hp.HParam('dropout', hp.RealInterval(0.1, 0.2))
HP_OPTIMIZER = hp.HParam('optimizer', hp.Discrete(['adam', 'sgd']))
METRIC_ACCURACY = 'accuracy'
with tf.summary.create_file_writer('logs/hparam_tuning').as_default():
hp.hparams_config(
hparams=[HP_NUM_UNITS, HP_DROPOUT, HP_OPTIMIZER],
metrics=[hp.Metric(METRIC_ACCURACY, display_name='Accuracy')],
)
このステップを省略する場合は、hparams[HP_DROPOUT] の代わりに hparams['dropout'] を指定するように、HParam 値を使用する箇所に文字列リテラル使用できます。
2. ハイパーパラメータとメトリックをログするように TensorFlow 実行を適応させる
モデルは、2 つの密レイヤーとその間にドロップアウトレイヤーを使用する、非常に簡単なモデルになります。トレーニングコードは似ていますが、ハイパーパラメータはハードコードされていません。その代わり、hparams ディクショナリにハイパーパラメータを指定し、トレーニング関数で使用します。
def train_test_model(hparams):
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(hparams[HP_NUM_UNITS], activation=tf.nn.relu),
tf.keras.layers.Dropout(hparams[HP_DROPOUT]),
tf.keras.layers.Dense(10, activation=tf.nn.softmax),
])
model.compile(
optimizer=hparams[HP_OPTIMIZER],
loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
)
model.fit(x_train, y_train, epochs=1) # Run with 1 epoch to speed things up for demo purposes
_, accuracy = model.evaluate(x_test, y_test)
return accuracy
実行のたびに、ハイパーパラメータと最終精度とともに、hparams の要約をログします。
def run(run_dir, hparams):
with tf.summary.create_file_writer(run_dir).as_default():
hp.hparams(hparams) # record the values used in this trial
accuracy = train_test_model(hparams)
tf.summary.scalar(METRIC_ACCURACY, accuracy, step=1)
Keras モジュールをトレーニングする際は、直接これらを書き込む代わりにコールバックを使用できます。
model.fit(
...,
callbacks=[
tf.keras.callbacks.TensorBoard(logdir), # log metrics
hp.KerasCallback(logdir, hparams), # log hparams
],
)
3. 実行を開始し、1 つの親ディレクトリにすべてをログする
様々なハイパーパラメータのセットを実験ごとに変更してトレーニングし、複数の実験を試せるようになりました。
簡単にするために、グリッド検索を使用します。離散パラメータのすべての組み合わせと実際値パラメータの上限と下限を試します。より複雑なシナリオでは、それぞれのハイパーパラメータの値をランダムに選択する方が効果的かもしれません(ランダム検索といいます)。より高度な手法も存在します。
実験をいくつか実行します。これには数分かかります。
session_num = 0
for num_units in HP_NUM_UNITS.domain.values:
for dropout_rate in (HP_DROPOUT.domain.min_value, HP_DROPOUT.domain.max_value):
for optimizer in HP_OPTIMIZER.domain.values:
hparams = {
HP_NUM_UNITS: num_units,
HP_DROPOUT: dropout_rate,
HP_OPTIMIZER: optimizer,
}
run_name = "run-%d" % session_num
print('--- Starting trial: %s' % run_name)
print({h.name: hparams[h] for h in hparams})
run('logs/hparam_tuning/' + run_name, hparams)
session_num += 1
--- Starting trial: run-0
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 62us/sample - loss: 0.6872 - accuracy: 0.7564
10000/10000 [==============================] - 0s 35us/sample - loss: 0.4806 - accuracy: 0.8321
--- Starting trial: run-1
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9428 - accuracy: 0.6769
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6519 - accuracy: 0.7770
--- Starting trial: run-2
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 60us/sample - loss: 0.8158 - accuracy: 0.7078
10000/10000 [==============================] - 0s 36us/sample - loss: 0.5309 - accuracy: 0.8154
--- Starting trial: run-3
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 50us/sample - loss: 1.1465 - accuracy: 0.6019
10000/10000 [==============================] - 0s 36us/sample - loss: 0.7007 - accuracy: 0.7683
--- Starting trial: run-4
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 65us/sample - loss: 0.6178 - accuracy: 0.7849
10000/10000 [==============================] - 0s 38us/sample - loss: 0.4645 - accuracy: 0.8395
--- Starting trial: run-5
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 55us/sample - loss: 0.8989 - accuracy: 0.6896
10000/10000 [==============================] - 0s 37us/sample - loss: 0.6335 - accuracy: 0.7853
--- Starting trial: run-6
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 64us/sample - loss: 0.6404 - accuracy: 0.7782
10000/10000 [==============================] - 0s 37us/sample - loss: 0.4802 - accuracy: 0.8265
--- Starting trial: run-7
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9633 - accuracy: 0.6703
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6516 - accuracy: 0.7755
4. TensorBoard の HParams ダッシュボードに結果を視覚化する
HParams ダッシュボードを開けるようになったので、TensorBoard を起動して上部にある「HParams」をクリックします。
%tensorboard --logdir logs/hparam_tuning
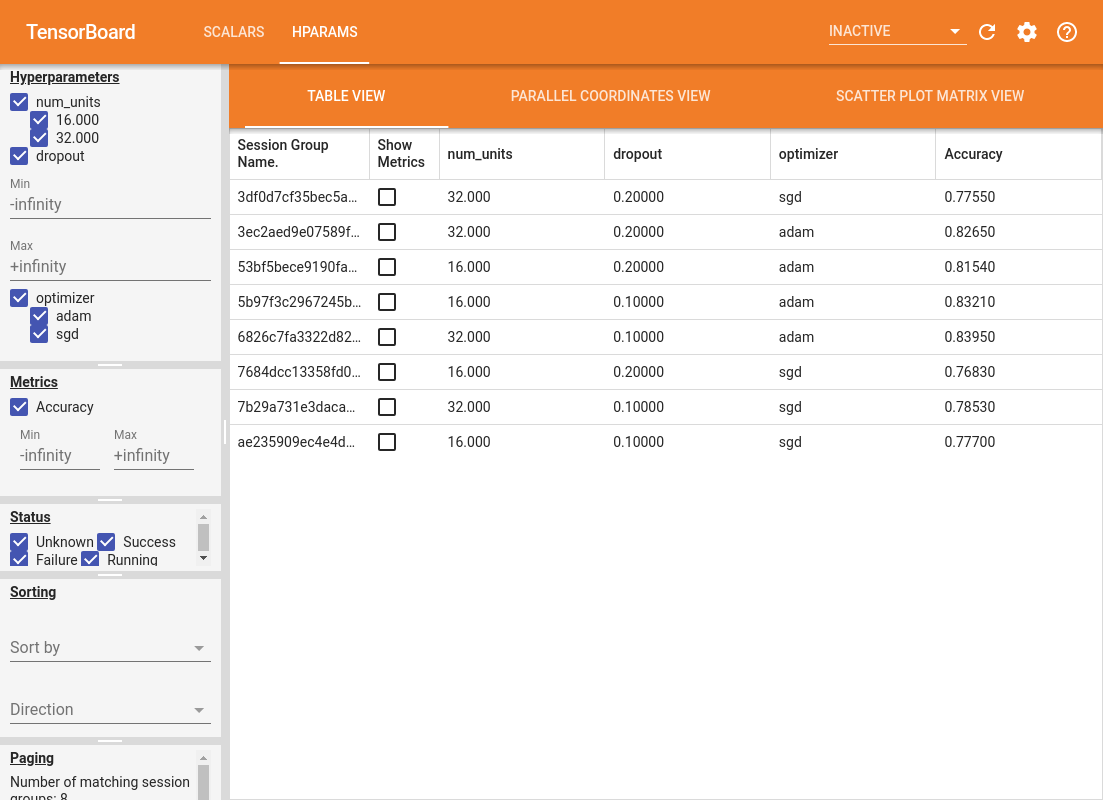
ダッシュボードの左ペインには、HParams ダッシュボードのすべてのビューで有効化されているフィルタ機能があります。
- ダッシュボードに表示するハイパーパラメータ/メトリックのフィルタリング
- ダッシュボードに表示するハイパーパラメータ/メトリックの値のフィルタリング
- 実行ステータスによるフィルタリング(実行中、成功、など)
- テーブルビューのハイパーパラメータ/メトリックの並べ替え
- 表示するセッショングループの数(実験が多数ある場合のパフォーマンスに役立ちます)
HParams ダッシュボードには 3 つのビューがあり、さまざまな有益な情報が表示されます。
- テーブルビュー には、実行、実行のハイパーパラメータ、およびメトリックがリストされます。
- 平行座標ビューには、各実行がハイパーパラメータとメトリックの軸を通る線として表示されます。任意の軸をクリックしてドラッグして領域をマークすると、それを通過する実行のみを強調して表示するできます。これはどのハイパーパラメータのグループが最も重要であるかを特定する上で役立ちます。軸自体は、ドラッグして並べ替えることができます。
- 散布図ビューには、各ハイパーパラメータ/メトリックを各メトリックと比較したプロットが表示されます。こうすることで、相関関係を識別するのに役立ちます。クリックアンドドラッグして特定のプロットの領域を選択すると、ほかのプロットのそれらのセッションを強調して表示できます。
テーブル行、平行座標線、および散布図マーケットはクリック可能で、メトリックのプロットをそのセッションのトレーニングステップの関数として表示することができます(このチュートリアルでは、実行ごとに 1 つのステップのみが使用されています)。
HParams ダッシュボードの機能をさらに探るには、より多くの実験を使用した生成済みのログをダウンロードしてください。
wget -q 'https://storage.googleapis.com/download.tensorflow.org/tensorboard/hparams_demo_logs.zip'unzip -q hparams_demo_logs.zip -d logs/hparam_demo
TensorBoard でログを表示します。
%tensorboard --logdir logs/hparam_demo
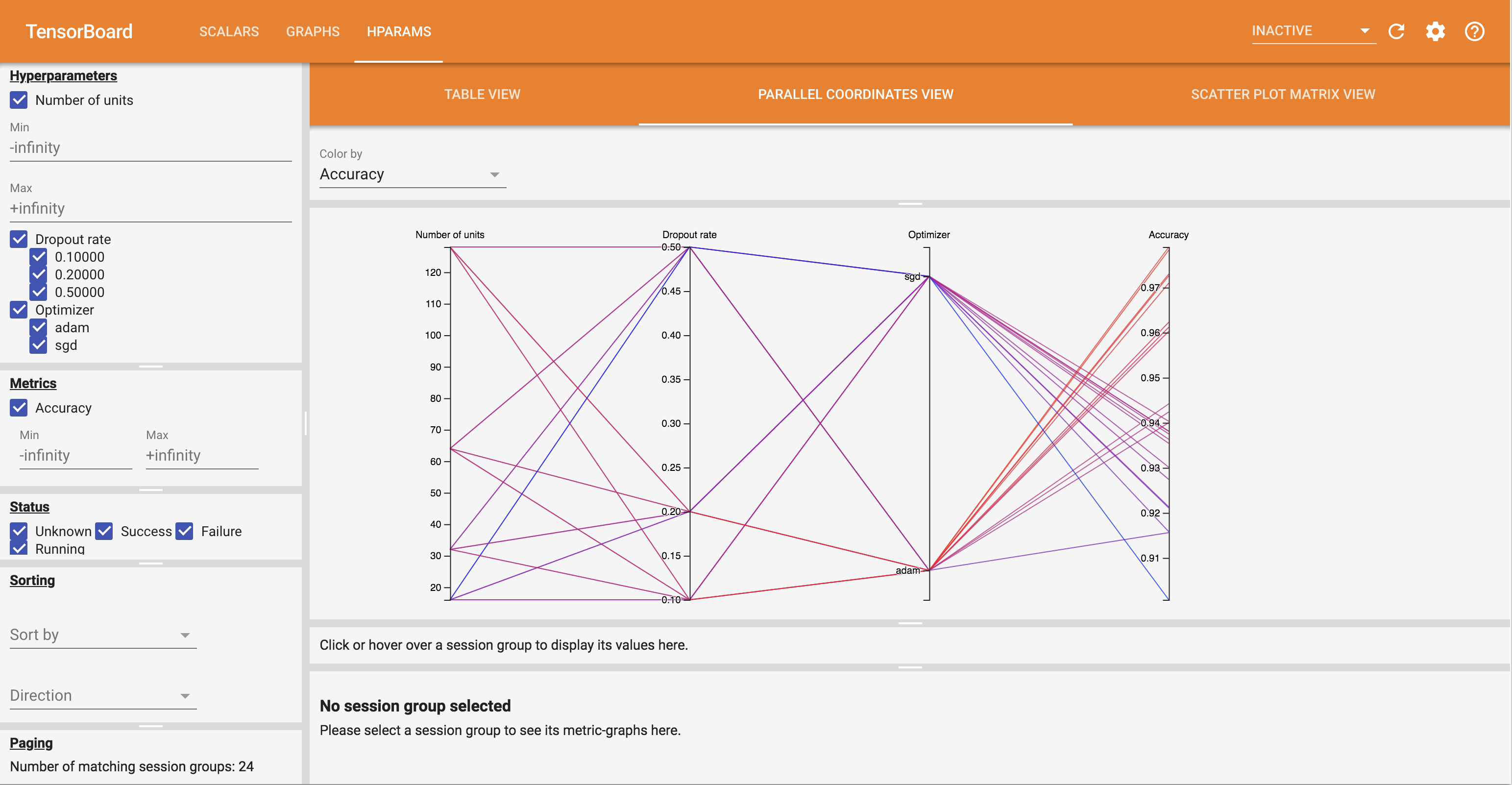
HParams ダッシュボードのさまざまなビューを試してみてください。
たとえば、平行座標ビューに移動して、精度軸をクリックアンドドラッグすると、精度の最も高い実行を選択できます。こういった実行はオプティマイザ軸の「adam」を通過するため、実験では「sgd」よりも「adam」の方がより高い性能を見せたと結論付けることができます。