| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Descripción general
Utilizando el TensorBoard incrustación proyector, puede representar gráficamente altas inclusiones dimensionales. Esto puede resultar útil para visualizar, examinar y comprender las capas de inserción.

En este tutorial, aprenderá a visualizar este tipo de capa entrenada.
Configuración
Para este tutorial, usaremos TensorBoard para visualizar una capa de incrustación generada para clasificar los datos de reseñas de películas.
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
%load_ext tensorboard
import os
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorboard.plugins import projector
Datos IMDB
Usaremos un conjunto de datos de 25,000 reseñas de películas de IMDB, cada una de las cuales tiene una etiqueta de opinión (positiva / negativa). Cada revisión se procesa previamente y se codifica como una secuencia de índices de palabras (números enteros). Para simplificar, las palabras se indexan por frecuencia general en el conjunto de datos, por ejemplo, el número entero "3" codifica la tercera palabra más frecuente que aparece en todas las revisiones. Esto permite operaciones de filtrado rápidas como: "solo considere las 10,000 palabras más comunes, pero elimine las 20 palabras más comunes".
Como convención, "0" no significa ninguna palabra específica, sino que se usa para codificar cualquier palabra desconocida. Más adelante en el tutorial, eliminaremos la fila para "0" en la visualización.
(train_data, test_data), info = tfds.load(
"imdb_reviews/subwords8k",
split=(tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True,
)
encoder = info.features["text"].encoder
# Shuffle and pad the data.
train_batches = train_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
test_batches = test_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
train_batch, train_labels = next(iter(train_batches))
Capa de incrustación de Keras
Una capa Keras incrustación se puede utilizar para entrenar a una inmersión para cada palabra en su vocabulario. Cada palabra (o subpalabra en este caso) se asociará con un vector de 16 dimensiones (o incrustación) que será entrenado por el modelo.
Ver este tutorial para aprender más sobre inclusiones de palabras.
# Create an embedding layer.
embedding_dim = 16
embedding = tf.keras.layers.Embedding(encoder.vocab_size, embedding_dim)
# Configure the embedding layer as part of a keras model.
model = tf.keras.Sequential(
[
embedding, # The embedding layer should be the first layer in a model.
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1),
]
)
# Compile model.
model.compile(
optimizer="adam",
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Train model for one epoch.
history = model.fit(
train_batches, epochs=1, validation_data=test_batches, validation_steps=20
)
2500/2500 [==============================] - 13s 5ms/step - loss: 0.5330 - accuracy: 0.6769 - val_loss: 0.4043 - val_accuracy: 0.7800
Guardando datos para TensorBoard
TensorBoard lee tensores y metadatos de los registros de tus proyectos de tensorflow. La ruta de acceso al directorio de registro se especifica con log_dir a continuación. Para este tutorial, vamos a utilizar /logs/imdb-example/ .
Para cargar los datos en Tensorboard, necesitamos guardar un punto de control de entrenamiento en ese directorio, junto con los metadatos que permiten la visualización de una capa específica de interés en el modelo.
# Set up a logs directory, so Tensorboard knows where to look for files.
log_dir='/logs/imdb-example/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# Save Labels separately on a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w") as f:
for subwords in encoder.subwords:
f.write("{}\n".format(subwords))
# Fill in the rest of the labels with "unknown".
for unknown in range(1, encoder.vocab_size - len(encoder.subwords)):
f.write("unknown #{}\n".format(unknown))
# Save the weights we want to analyze as a variable. Note that the first
# value represents any unknown word, which is not in the metadata, here
# we will remove this value.
weights = tf.Variable(model.layers[0].get_weights()[0][1:])
# Create a checkpoint from embedding, the filename and key are the
# name of the tensor.
checkpoint = tf.train.Checkpoint(embedding=weights)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
# Set up config.
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by `/.ATTRIBUTES/VARIABLE_VALUE`.
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
# Now run tensorboard against on log data we just saved.
%tensorboard --logdir /logs/imdb-example/
Análisis
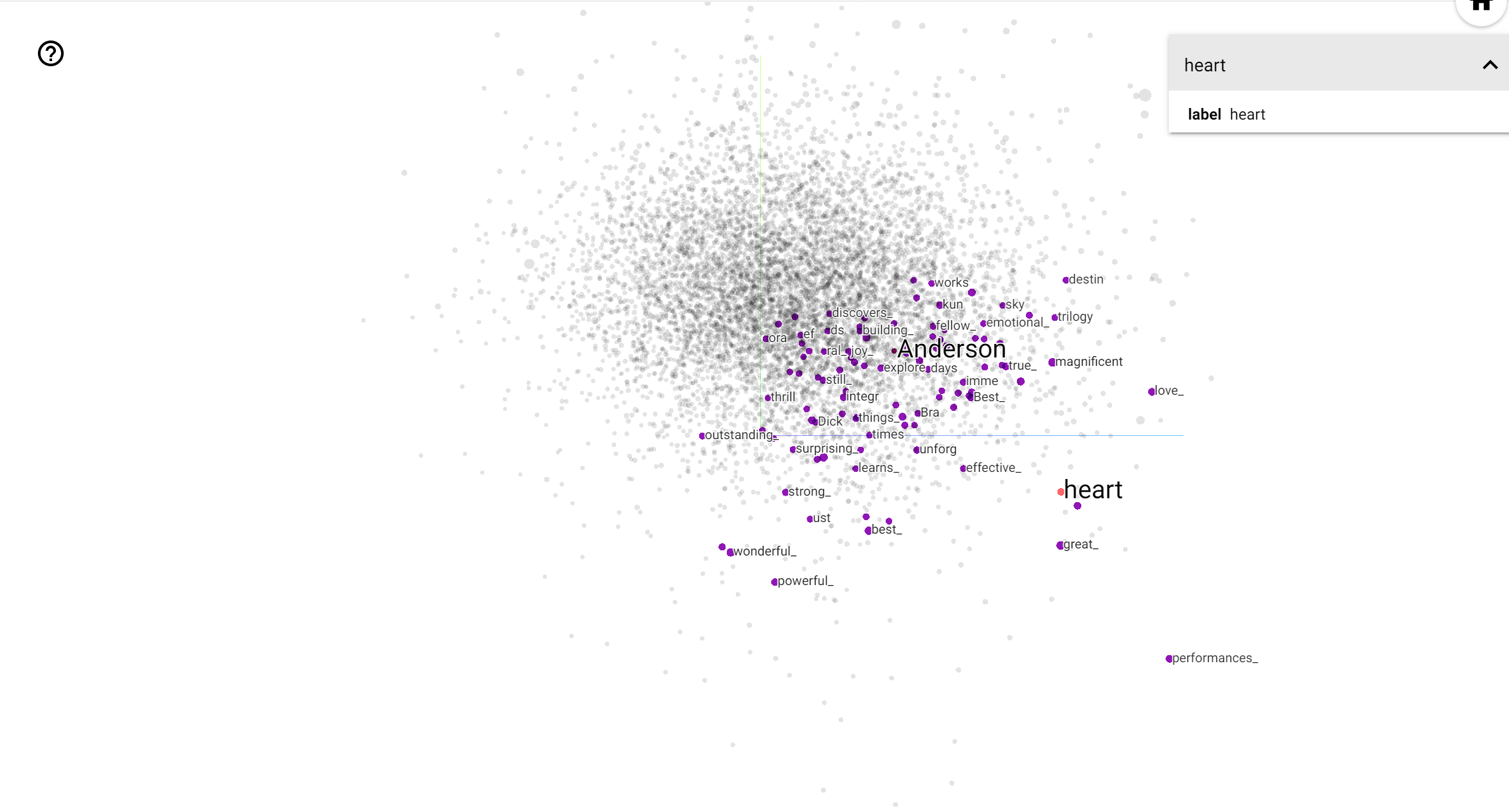
El proyector TensorBoard es una gran herramienta para interpretar y visualizar incrustaciones. El tablero permite a los usuarios buscar términos específicos y resalta las palabras adyacentes entre sí en el espacio incrustado (de baja dimensión). De este ejemplo podemos ver que Wes Anderson y Alfred Hitchcock son los dos términos más bien neutros, sino que se hace referencia en diferentes contextos.
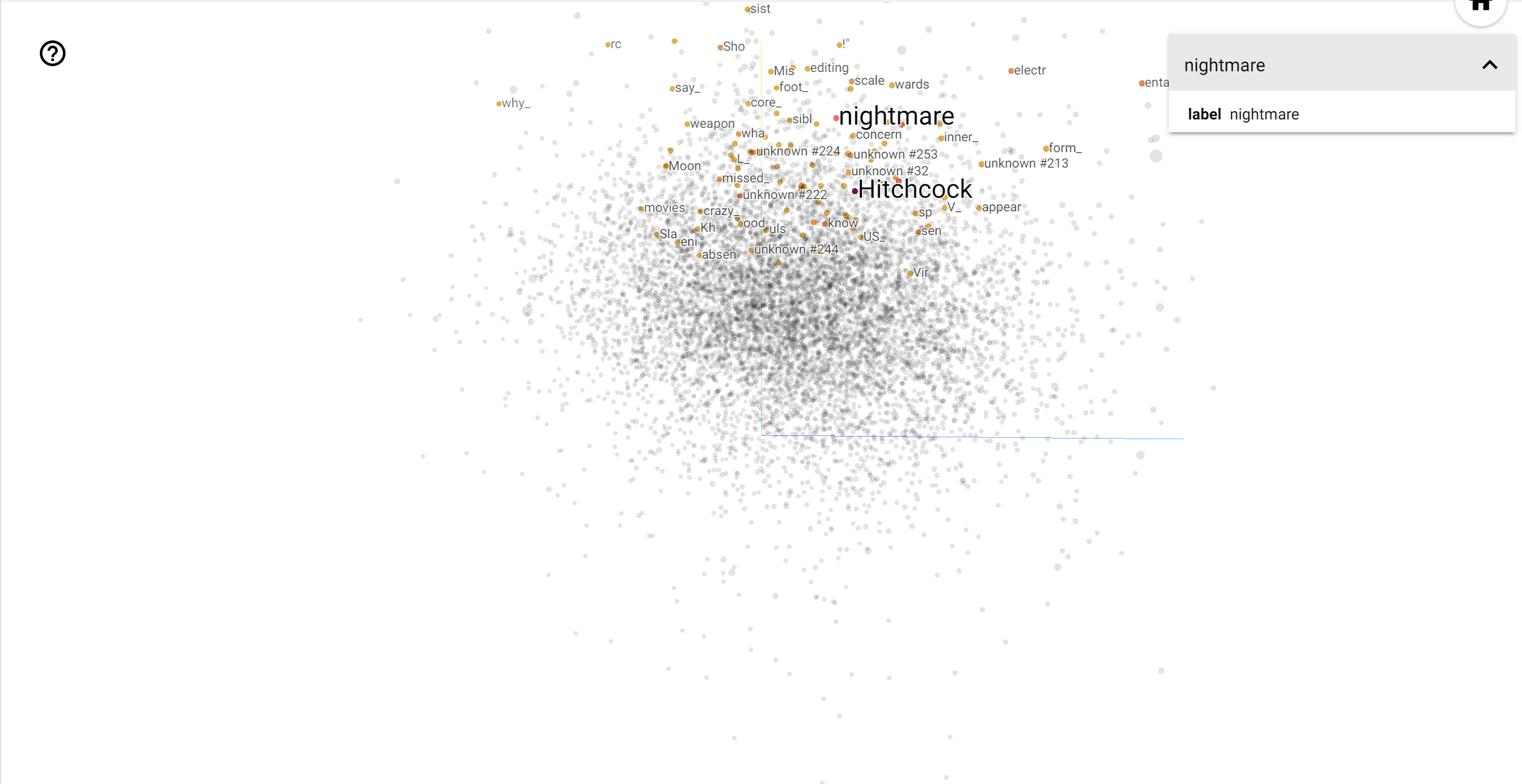
En este espacio, Hitchcock se acerca más a palabras como nightmare , que es probablemente debido al hecho de que se le conoce como el "maestro del suspenso", mientras que Anderson está más cerca de la palabra heart , lo cual es consistente con su estilo y sin descanso se detalla reconfortante .