| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Aperçu
Utilisation de la TensorBoard Embedding projecteur, vous pouvez représenter graphiquement incorporations de grande dimension. Cela peut être utile pour visualiser, examiner et comprendre vos couches d'incorporation.

Dans ce tutoriel, vous apprendrez à visualiser ce type de couche entraînée.
Installer
Pour ce didacticiel, nous utiliserons TensorBoard pour visualiser une couche d'intégration générée pour classer les données de critique de film.
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
%load_ext tensorboard
import os
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorboard.plugins import projector
Données IMDB
Nous utiliserons un ensemble de données de 25 000 critiques de films IMDB, chacune ayant une étiquette de sentiment (positive/négative). Chaque avis est prétraité et encodé sous la forme d'une séquence d'indices de mots (entiers). Pour plus de simplicité, les mots sont indexés par fréquence globale dans l'ensemble de données, par exemple l'entier "3" code le 3ème mot le plus fréquent apparaissant dans toutes les revues. Cela permet des opérations de filtrage rapides telles que : « ne considérer que les 10 000 mots les plus courants, mais éliminer les 20 mots les plus courants ».
Par convention, « 0 » ne représente aucun mot spécifique, mais est plutôt utilisé pour coder un mot inconnu. Plus tard dans le didacticiel, nous supprimerons la ligne pour « 0 » dans la visualisation.
(train_data, test_data), info = tfds.load(
"imdb_reviews/subwords8k",
split=(tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True,
)
encoder = info.features["text"].encoder
# Shuffle and pad the data.
train_batches = train_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
test_batches = test_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
train_batch, train_labels = next(iter(train_batches))
Couche d'intégration Keras
Un Keras Embedding couche peut être utilisé pour former un plongement pour chaque mot dans votre vocabulaire. Chaque mot (ou sous-mot dans ce cas) sera associé à un vecteur (ou plongement) à 16 dimensions qui sera entraîné par le modèle.
Voir ce tutoriel pour en savoir plus sur les mots incorporations.
# Create an embedding layer.
embedding_dim = 16
embedding = tf.keras.layers.Embedding(encoder.vocab_size, embedding_dim)
# Configure the embedding layer as part of a keras model.
model = tf.keras.Sequential(
[
embedding, # The embedding layer should be the first layer in a model.
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1),
]
)
# Compile model.
model.compile(
optimizer="adam",
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Train model for one epoch.
history = model.fit(
train_batches, epochs=1, validation_data=test_batches, validation_steps=20
)
2500/2500 [==============================] - 13s 5ms/step - loss: 0.5330 - accuracy: 0.6769 - val_loss: 0.4043 - val_accuracy: 0.7800
Enregistrement des données pour TensorBoard
TensorBoard lit les tenseurs et les métadonnées à partir des journaux de vos projets tensorflow. Le chemin vers le répertoire du journal est spécifié avec log_dir ci - dessous. Pour ce tutoriel, nous utiliserons /logs/imdb-example/ .
Afin de charger les données dans Tensorboard, nous devons enregistrer un point de contrôle d'entraînement dans ce répertoire, ainsi que des métadonnées qui permettent de visualiser une couche d'intérêt spécifique dans le modèle.
# Set up a logs directory, so Tensorboard knows where to look for files.
log_dir='/logs/imdb-example/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# Save Labels separately on a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w") as f:
for subwords in encoder.subwords:
f.write("{}\n".format(subwords))
# Fill in the rest of the labels with "unknown".
for unknown in range(1, encoder.vocab_size - len(encoder.subwords)):
f.write("unknown #{}\n".format(unknown))
# Save the weights we want to analyze as a variable. Note that the first
# value represents any unknown word, which is not in the metadata, here
# we will remove this value.
weights = tf.Variable(model.layers[0].get_weights()[0][1:])
# Create a checkpoint from embedding, the filename and key are the
# name of the tensor.
checkpoint = tf.train.Checkpoint(embedding=weights)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
# Set up config.
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by `/.ATTRIBUTES/VARIABLE_VALUE`.
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
# Now run tensorboard against on log data we just saved.
%tensorboard --logdir /logs/imdb-example/
Analyse
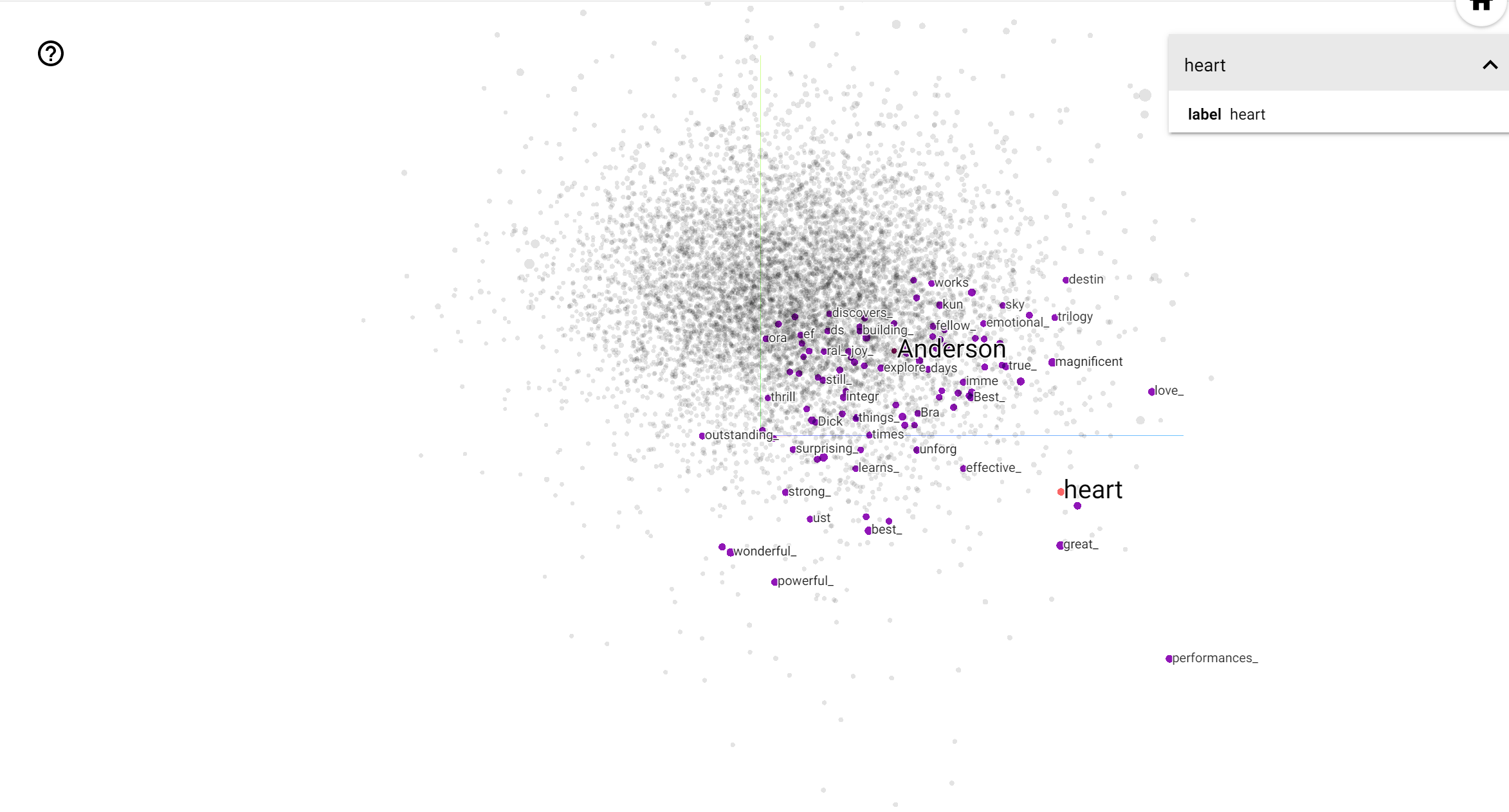
Le projecteur TensorBoard est un excellent outil pour interpréter et visualiser l'intégration. Le tableau de bord permet aux utilisateurs de rechercher des termes spécifiques et met en évidence les mots adjacents les uns aux autres dans l'espace d'intégration (de faible dimension). De cet exemple , nous pouvons voir que Wes Anderson et Alfred Hitchcock sont les deux termes plutôt neutres, mais ils sont référencés dans des contextes différents.
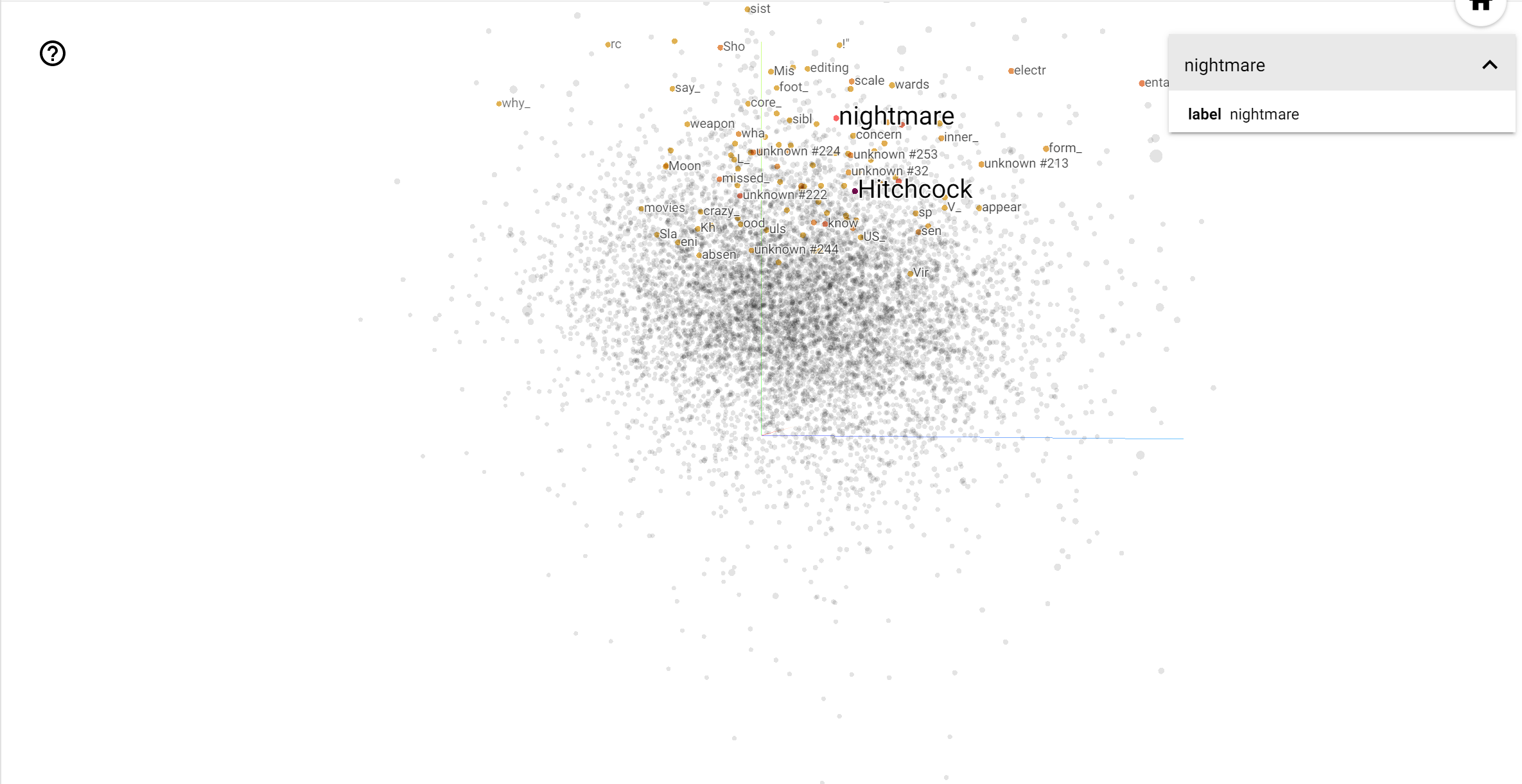
Dans cet espace, Hitchcock est plus proche de mots comme nightmare , ce qui est probablement dû au fait qu'il est connu comme le « maître du suspense », alors que Anderson est plus proche du mot heart , ce qui est conforme à son style sans relâche détaillée et réconfortante .