| |
|
 GitHub でソースを表示 GitHub でソースを表示 |
概要
TensorBoard の Embedding Projector を使用すると、高次元埋め込みをグラフィカルに表現することができます。Embedding レイヤーの視覚化、調査、および理解に役立てられます。
このチュートリアルでは、この種のトレーニング済みのレイヤーを視覚化する方法を学習します。
セットアップ
このチュートリアルでは、TensorBoard を使用して、映画レビューデータを分類するために生成された Embedding レイヤーを視覚化します。
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
%load_ext tensorboard
import os
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorboard.plugins import projector
IMDB データ
IMDB が提供する、センチメント(肯定的/否定的)でラベル付けされた 25,000 件の映画レビューのデータセットを使用します。レビューは前処理済みであり、それぞれ単語インデックスのシーケンス(整数)としてエンコードされています。便宜上、単語はデータセット内の全体的な頻度によってインデックス付けされてるため、たとえば、整数「3」はデータ内で 3 番目に頻度の高い単語にエンコードされます。このため、「高頻度で使用される上位 10,000 個の単語のみを考慮し、高頻度で使用される上位 20 個を除去する」といったフィルタ操作を素早く行うことができます。
慣例として、「0」は特定の単語を表しませんが、任意の不明な単語をエンコードするのに使用されます。チュートリアルの後の方で、「0」の行を視覚化から取り除きます。
(train_data, test_data), info = tfds.load(
"imdb_reviews/subwords8k",
split=(tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True,
)
encoder = info.features["text"].encoder
# Shuffle and pad the data.
train_batches = train_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
test_batches = test_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
train_batch, train_labels = next(iter(train_batches))
Keras Embedding レイヤー
Keras Embedding レイヤーは、語彙の各単語に対して埋め込みをトレーニングするために使用できます。各単語(またはこの場合はサブ単語)は、モデルがトレーニングする 16 次元のベクトル(または埋め込み)に関連付けられます。
単語の埋め込みに関する詳細は、このチュートリアルをご覧ください。
# Create an embedding layer.
embedding_dim = 16
embedding = tf.keras.layers.Embedding(encoder.vocab_size, embedding_dim)
# Configure the embedding layer as part of a keras model.
model = tf.keras.Sequential(
[
embedding, # The embedding layer should be the first layer in a model.
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1),
]
)
# Compile model.
model.compile(
optimizer="adam",
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Train model for one epoch.
history = model.fit(
train_batches, epochs=1, validation_data=test_batches, validation_steps=20
)
2500/2500 [==============================] - 13s 5ms/step - loss: 0.5330 - accuracy: 0.6769 - val_loss: 0.4043 - val_accuracy: 0.7800
TensorBoard 用にデータを保存する
TensorBoard は、tensorflow プロジェクトのログからテンソルとメタデータを読み取ります。ログディレクトリへのパスは、以下のlog_dirで指定されます。このチュートリアルでは、/logs/imdb-example/ を使用します。
データを Tensorboard に読み込むには、モデル内の特定の対象レイヤーの視覚化を可能にするメタデータとともに、トレーニングチェックポイントをそのディレクトリに保存する必要があります。
# Set up a logs directory, so Tensorboard knows where to look for files.
log_dir='/logs/imdb-example/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# Save Labels separately on a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w") as f:
for subwords in encoder.subwords:
f.write("{}\n".format(subwords))
# Fill in the rest of the labels with "unknown".
for unknown in range(1, encoder.vocab_size - len(encoder.subwords)):
f.write("unknown #{}\n".format(unknown))
# Save the weights we want to analyze as a variable. Note that the first
# value represents any unknown word, which is not in the metadata, here
# we will remove this value.
weights = tf.Variable(model.layers[0].get_weights()[0][1:])
# Create a checkpoint from embedding, the filename and key are the
# name of the tensor.
checkpoint = tf.train.Checkpoint(embedding=weights)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
# Set up config.
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by `/.ATTRIBUTES/VARIABLE_VALUE`.
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
# Now run tensorboard against on log data we just saved.
%tensorboard --logdir /logs/imdb-example/
分析
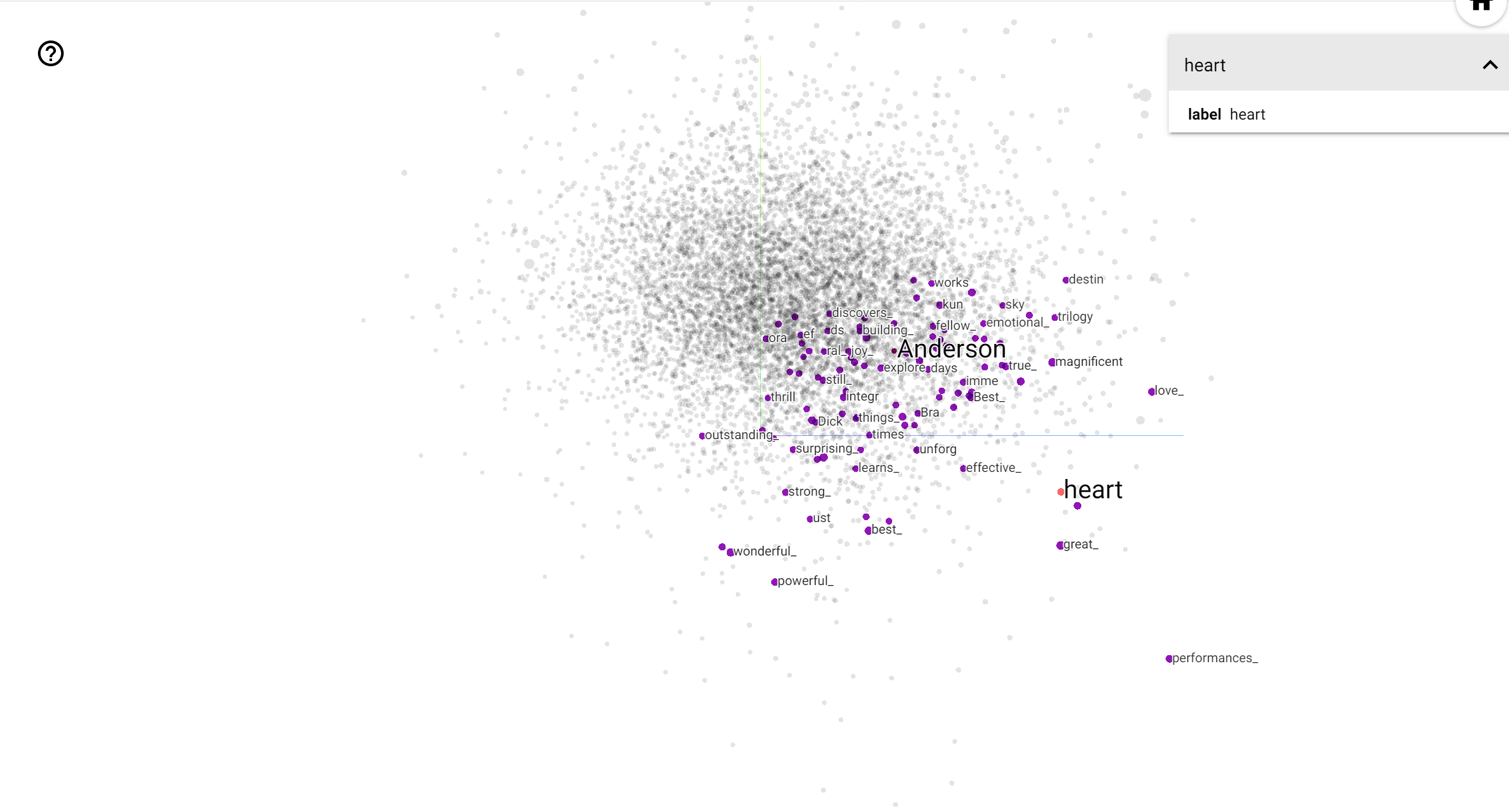
TensorBoard Projector は、データを分析し、埋め込みの値を解釈および視覚化するための優れたツールです。ダッシュボードでは特定の語を検索でき、埋め込み空間内の近接する単語を強調表示することができます。この例からは、Wes Anderson と Alfred Hitchcock がともに中立した語であることがわかりますが、異なる文脈で参照されています。
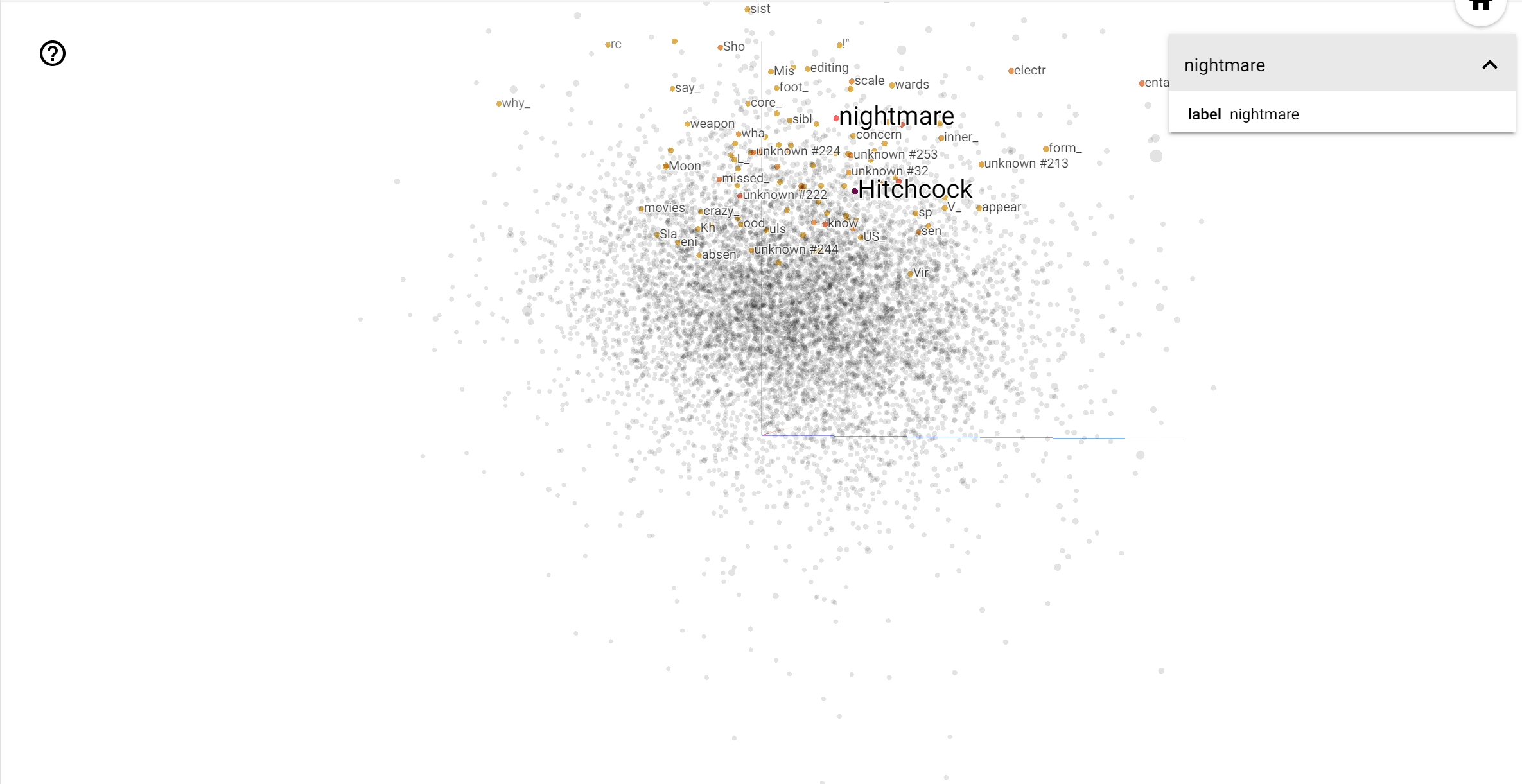
この空間では、ヒッチコックは nightmare のような単語に近接しています。これは、彼が「サスペンスのマスター」として知られているためと思われます。アンダーソンは heart という単語と近接しています。これは彼の執拗に詳細で心温まるスタイルと一致しています。