
| | |  Ver en GitHub Ver en GitHub | | |
Este tutorial contiene código completo para ajustar BERT a fin de realizar análisis de sentimientos en un conjunto de datos de reseñas de películas IMDB de texto sin formato. Además de entrenar un modelo, aprenderá a preprocesar texto en un formato apropiado.
En este cuaderno, podrá:
- Cargar el conjunto de datos de IMDB
- Cargar un modelo BERT desde TensorFlow Hub
- Construya su propio modelo combinando BERT con un clasificador
- Entrene su propio modelo, afinando BERT como parte de eso
- Guarde su modelo y utilícelo para clasificar oraciones
Si eres nuevo en el trabajo con el conjunto de datos IMDB, consulte clasificación de texto básico para más detalles.
Sobre BERT
BERT y otras arquitecturas de codificador transformador han sido un gran éxito en una variedad de tareas en PNL (procesamiento del lenguaje natural). Calculan representaciones en el espacio vectorial del lenguaje natural que son adecuadas para su uso en modelos de aprendizaje profundo. La familia de modelos BERT utiliza la arquitectura de codificador Transformer para procesar cada token de texto de entrada en el contexto completo de todos los tokens antes y después, de ahí el nombre: Representaciones de codificador bidireccional de Transformers.
Los modelos BERT generalmente se entrenan previamente en un gran corpus de texto y luego se ajustan para tareas específicas.
Configuración
# A dependency of the preprocessing for BERT inputspip install -q -U tensorflow-text
Que va a utilizar el optimizador de AdamW tensorflow / modelos .
pip install -q tf-models-official
import os
import shutil
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_text as text
from official.nlp import optimization # to create AdamW optimizer
import matplotlib.pyplot as plt
tf.get_logger().setLevel('ERROR')
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py:119: PkgResourcesDeprecationWarning: 0.18ubuntu0.18.04.1 is an invalid version and will not be supported in a future release PkgResourcesDeprecationWarning,
Análisis de los sentimientos
Este cuaderno forma a un modelo de análisis de los sentimientos de críticas de películas Clasificar como positivo o negativo, con base en el texto de la revisión.
Vamos a usar la Gran Reseña de la película de conjunto de datos que contiene el texto de 50.000 reseñas de películas de la Internet Movie Database .
Descarga el conjunto de datos de IMDB
Descarguemos y extraigamos el conjunto de datos, luego exploremos la estructura del directorio.
url = 'https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz'
dataset = tf.keras.utils.get_file('aclImdb_v1.tar.gz', url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
train_dir = os.path.join(dataset_dir, 'train')
# remove unused folders to make it easier to load the data
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 7s 0us/step 84140032/84125825 [==============================] - 7s 0us/step
A continuación, se utilizará el text_dataset_from_directory utilidad para crear una etiqueta tf.data.Dataset .
El conjunto de datos de IMDB ya se ha dividido en entrenamiento y prueba, pero carece de un conjunto de validación. Vamos a crear un conjunto de validación utilizando una mezcla al 80/20 escisión de la formación de datos mediante el uso de la validation_split argumento a continuación.
AUTOTUNE = tf.data.AUTOTUNE
batch_size = 32
seed = 42
raw_train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
class_names = raw_train_ds.class_names
train_ds = raw_train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
Found 25000 files belonging to 2 classes. Using 20000 files for training. Found 25000 files belonging to 2 classes. Using 5000 files for validation. Found 25000 files belonging to 2 classes.
Echemos un vistazo a algunas reseñas.
for text_batch, label_batch in train_ds.take(1):
for i in range(3):
print(f'Review: {text_batch.numpy()[i]}')
label = label_batch.numpy()[i]
print(f'Label : {label} ({class_names[label]})')
Review: b'"Pandemonium" is a horror movie spoof that comes off more stupid than funny. Believe me when I tell you, I love comedies. Especially comedy spoofs. "Airplane", "The Naked Gun" trilogy, "Blazing Saddles", "High Anxiety", and "Spaceballs" are some of my favorite comedies that spoof a particular genre. "Pandemonium" is not up there with those films. Most of the scenes in this movie had me sitting there in stunned silence because the movie wasn\'t all that funny. There are a few laughs in the film, but when you watch a comedy, you expect to laugh a lot more than a few times and that\'s all this film has going for it. Geez, "Scream" had more laughs than this film and that was more of a horror film. How bizarre is that?<br /><br />*1/2 (out of four)' Label : 0 (neg) Review: b"David Mamet is a very interesting and a very un-equal director. His first movie 'House of Games' was the one I liked best, and it set a series of films with characters whose perspective of life changes as they get into complicated situations, and so does the perspective of the viewer.<br /><br />So is 'Homicide' which from the title tries to set the mind of the viewer to the usual crime drama. The principal characters are two cops, one Jewish and one Irish who deal with a racially charged area. The murder of an old Jewish shop owner who proves to be an ancient veteran of the Israeli Independence war triggers the Jewish identity in the mind and heart of the Jewish detective.<br /><br />This is were the flaws of the film are the more obvious. The process of awakening is theatrical and hard to believe, the group of Jewish militants is operatic, and the way the detective eventually walks to the final violent confrontation is pathetic. The end of the film itself is Mamet-like smart, but disappoints from a human emotional perspective.<br /><br />Joe Mantegna and William Macy give strong performances, but the flaws of the story are too evident to be easily compensated." Label : 0 (neg) Review: b'Great documentary about the lives of NY firefighters during the worst terrorist attack of all time.. That reason alone is why this should be a must see collectors item.. What shocked me was not only the attacks, but the"High Fat Diet" and physical appearance of some of these firefighters. I think a lot of Doctors would agree with me that,in the physical shape they were in, some of these firefighters would NOT of made it to the 79th floor carrying over 60 lbs of gear. Having said that i now have a greater respect for firefighters and i realize becoming a firefighter is a life altering job. The French have a history of making great documentary\'s and that is what this is, a Great Documentary.....' Label : 1 (pos) 2021-12-01 12:17:32.795514: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
Carga de modelos desde TensorFlow Hub
Aquí puede elegir qué modelo BERT cargará desde TensorFlow Hub y ajustarlo. Hay varios modelos BERT disponibles.
- BERT-Base , sin entubar y siete más modelos con pesos capacitados dadas a conocer por los autores originales de BERT.
- BERTS pequeños tienen la misma arquitectura general pero menos y / o bloques de transformadores pequeños, lo que le permite explorar soluciones de compromiso entre velocidad, el tamaño y la calidad.
- ALBERT : cuatro tamaños diferentes de "A Lite BERT" que reduce el tamaño del modelo (pero no el tiempo de cálculo) mediante el intercambio de parámetros entre las capas.
- BERT Expertos : ocho modelos que todos tienen la arquitectura BERT-base, pero ofrecen una elección entre diferentes dominios pre-formación, para alinear más estrechamente con la tarea de destino.
- Electra tiene la misma arquitectura que el BERT (en tres tamaños diferentes), pero se pre-formó como un discriminador en una puesta a punto que se asemeja a una red Acusatorio generativo (GAN).
- BERT con hablar-Heads Atención y cerrada GELU [ de base , gran ] tiene dos mejoras en el núcleo de la arquitectura del transformador.
La documentación del modelo en TensorFlow Hub tiene más detalles y referencias a la literatura de investigación. Siga los enlaces de arriba o haga clic en el tfhub.dev URL impresa después de la siguiente ejecución celular.
La sugerencia es comenzar con un Small BERT (con menos parámetros) ya que son más rápidos de ajustar. Si le gusta un modelo pequeño pero con mayor precisión, ALBERT podría ser su próxima opción. Si desea una precisión aún mayor, elija uno de los tamaños clásicos de BERT o sus mejoras recientes como Electra, Talking Heads o BERT Expert.
Aparte de los modelos disponibles a continuación, existen múltiples versiones de los modelos que son más grandes y pueden producir incluso una mayor precisión, pero son demasiado grandes para ser puesto a punto en una sola GPU. Usted será capaz de hacer eso en las tareas COLA Resolver utilizando BERT en una colab TPU .
Verá en el código a continuación que cambiar la URL tfhub.dev es suficiente para probar cualquiera de estos modelos, porque todas las diferencias entre ellos están encapsuladas en SavedModels de TF Hub.
Elija un modelo BERT para ajustarlo
bert_model_name = 'small_bert/bert_en_uncased_L-4_H-512_A-8'
map_name_to_handle = {
'bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/3',
'bert_en_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_cased_L-12_H-768_A-12/3',
'bert_multi_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_multi_cased_L-12_H-768_A-12/3',
'small_bert/bert_en_uncased_L-2_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-128_A-2/1',
'small_bert/bert_en_uncased_L-2_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-256_A-4/1',
'small_bert/bert_en_uncased_L-2_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-512_A-8/1',
'small_bert/bert_en_uncased_L-2_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-768_A-12/1',
'small_bert/bert_en_uncased_L-4_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-128_A-2/1',
'small_bert/bert_en_uncased_L-4_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-256_A-4/1',
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1',
'small_bert/bert_en_uncased_L-4_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-768_A-12/1',
'small_bert/bert_en_uncased_L-6_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-128_A-2/1',
'small_bert/bert_en_uncased_L-6_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-256_A-4/1',
'small_bert/bert_en_uncased_L-6_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-512_A-8/1',
'small_bert/bert_en_uncased_L-6_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-768_A-12/1',
'small_bert/bert_en_uncased_L-8_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-128_A-2/1',
'small_bert/bert_en_uncased_L-8_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-256_A-4/1',
'small_bert/bert_en_uncased_L-8_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-512_A-8/1',
'small_bert/bert_en_uncased_L-8_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-768_A-12/1',
'small_bert/bert_en_uncased_L-10_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-128_A-2/1',
'small_bert/bert_en_uncased_L-10_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-256_A-4/1',
'small_bert/bert_en_uncased_L-10_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-512_A-8/1',
'small_bert/bert_en_uncased_L-10_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-768_A-12/1',
'small_bert/bert_en_uncased_L-12_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-128_A-2/1',
'small_bert/bert_en_uncased_L-12_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-256_A-4/1',
'small_bert/bert_en_uncased_L-12_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-512_A-8/1',
'small_bert/bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-768_A-12/1',
'albert_en_base':
'https://tfhub.dev/tensorflow/albert_en_base/2',
'electra_small':
'https://tfhub.dev/google/electra_small/2',
'electra_base':
'https://tfhub.dev/google/electra_base/2',
'experts_pubmed':
'https://tfhub.dev/google/experts/bert/pubmed/2',
'experts_wiki_books':
'https://tfhub.dev/google/experts/bert/wiki_books/2',
'talking-heads_base':
'https://tfhub.dev/tensorflow/talkheads_ggelu_bert_en_base/1',
}
map_model_to_preprocess = {
'bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'bert_en_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_cased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'bert_multi_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_multi_cased_preprocess/3',
'albert_en_base':
'https://tfhub.dev/tensorflow/albert_en_preprocess/3',
'electra_small':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'electra_base':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'experts_pubmed':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'experts_wiki_books':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'talking-heads_base':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
}
tfhub_handle_encoder = map_name_to_handle[bert_model_name]
tfhub_handle_preprocess = map_model_to_preprocess[bert_model_name]
print(f'BERT model selected : {tfhub_handle_encoder}')
print(f'Preprocess model auto-selected: {tfhub_handle_preprocess}')
BERT model selected : https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Preprocess model auto-selected: https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3
El modelo de preprocesamiento
Las entradas de texto deben transformarse en identificadores de token numéricos y organizarse en varios tensores antes de ingresar a BERT. TensorFlow Hub proporciona un modelo de preprocesamiento coincidente para cada uno de los modelos BERT discutidos anteriormente, que implementa esta transformación mediante operaciones TF de la biblioteca TF.text. No es necesario ejecutar código Python puro fuera de su modelo de TensorFlow para preprocesar el texto.
El modelo de preprocesamiento debe ser el referenciado por la documentación del modelo BERT, que puede leer en la URL impresa arriba. Para los modelos BERT del menú desplegable anterior, el modelo de preprocesamiento se selecciona automáticamente.
bert_preprocess_model = hub.KerasLayer(tfhub_handle_preprocess)
Probemos el modelo de preprocesamiento en algún texto y veamos el resultado:
text_test = ['this is such an amazing movie!']
text_preprocessed = bert_preprocess_model(text_test)
print(f'Keys : {list(text_preprocessed.keys())}')
print(f'Shape : {text_preprocessed["input_word_ids"].shape}')
print(f'Word Ids : {text_preprocessed["input_word_ids"][0, :12]}')
print(f'Input Mask : {text_preprocessed["input_mask"][0, :12]}')
print(f'Type Ids : {text_preprocessed["input_type_ids"][0, :12]}')
Keys : ['input_word_ids', 'input_mask', 'input_type_ids'] Shape : (1, 128) Word Ids : [ 101 2023 2003 2107 2019 6429 3185 999 102 0 0 0] Input Mask : [1 1 1 1 1 1 1 1 1 0 0 0] Type Ids : [0 0 0 0 0 0 0 0 0 0 0 0]
Como se puede ver, ahora tienes las 3 salidas del procesamiento previo que un modelo BERT usaría ( input_words_id , input_mask y input_type_ids ).
Algunos otros puntos importantes:
- La entrada se trunca a 128 tokens. El número de fichas se pueden personalizar, y se puede ver más detalles sobre las tareas Resolver cola con BERT en una colab TPU .
- Los
input_type_idssólo tienen un valor (0) porque se trata de una sola entrada de frase. Para una entrada de oración múltiple, tendría un número para cada entrada.
Dado que este preprocesador de texto es un modelo de TensorFlow, se puede incluir en su modelo directamente.
Usando el modelo BERT
Antes de poner BERT en su propio modelo, echemos un vistazo a sus resultados. Lo cargará desde TF Hub y verá los valores devueltos.
bert_model = hub.KerasLayer(tfhub_handle_encoder)
bert_results = bert_model(text_preprocessed)
print(f'Loaded BERT: {tfhub_handle_encoder}')
print(f'Pooled Outputs Shape:{bert_results["pooled_output"].shape}')
print(f'Pooled Outputs Values:{bert_results["pooled_output"][0, :12]}')
print(f'Sequence Outputs Shape:{bert_results["sequence_output"].shape}')
print(f'Sequence Outputs Values:{bert_results["sequence_output"][0, :12]}')
Loaded BERT: https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Pooled Outputs Shape:(1, 512) Pooled Outputs Values:[ 0.76262873 0.99280983 -0.1861186 0.36673835 0.15233682 0.65504444 0.9681154 -0.9486272 0.00216158 -0.9877732 0.0684272 -0.9763061 ] Sequence Outputs Shape:(1, 128, 512) Sequence Outputs Values:[[-0.28946388 0.3432126 0.33231565 ... 0.21300787 0.7102078 -0.05771166] [-0.28742015 0.31981024 -0.2301858 ... 0.58455074 -0.21329722 0.7269209 ] [-0.66157013 0.6887685 -0.87432927 ... 0.10877253 -0.26173282 0.47855264] ... [-0.2256118 -0.28925604 -0.07064401 ... 0.4756601 0.8327715 0.40025353] [-0.29824278 -0.27473143 -0.05450511 ... 0.48849759 1.0955356 0.18163344] [-0.44378197 0.00930723 0.07223766 ... 0.1729009 1.1833246 0.07897988]]
Los modelos BERT devuelven un mapa con 3 claves importantes: pooled_output , sequence_output , encoder_outputs :
-
pooled_outputrepresenta cada secuencia de entrada como un todo. La forma es[batch_size, H]. Puede pensar en esto como una incrustación para toda la revisión de la película. -
sequence_outputrepresenta cada entrada de ficha en el contexto. La forma es[batch_size, seq_length, H]. Puede pensar en esto como una inserción contextual para cada token en la reseña de la película. -
encoder_outputsson las activaciones de los intermediosLTransformador bloques.outputs["encoder_outputs"][i]es un tensor de la forma[batch_size, seq_length, 1024]con las salidas del i-ésimo bloque transformador, para0 <= i < L. El último valor de la lista es igual asequence_output.
Para la puesta a punto que se va a utilizar el pooled_output matriz.
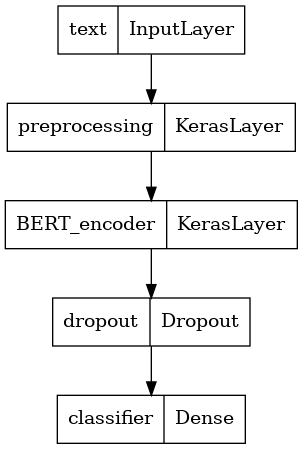
Define tu modelo
Creará un modelo ajustado muy simple, con el modelo de preprocesamiento, el modelo BERT seleccionado, una capa densa y una de abandono.
def build_classifier_model():
text_input = tf.keras.layers.Input(shape=(), dtype=tf.string, name='text')
preprocessing_layer = hub.KerasLayer(tfhub_handle_preprocess, name='preprocessing')
encoder_inputs = preprocessing_layer(text_input)
encoder = hub.KerasLayer(tfhub_handle_encoder, trainable=True, name='BERT_encoder')
outputs = encoder(encoder_inputs)
net = outputs['pooled_output']
net = tf.keras.layers.Dropout(0.1)(net)
net = tf.keras.layers.Dense(1, activation=None, name='classifier')(net)
return tf.keras.Model(text_input, net)
Comprobemos que el modelo se ejecuta con la salida del modelo de preprocesamiento.
classifier_model = build_classifier_model()
bert_raw_result = classifier_model(tf.constant(text_test))
print(tf.sigmoid(bert_raw_result))
tf.Tensor([[0.6749899]], shape=(1, 1), dtype=float32)
El resultado no tiene sentido, por supuesto, porque el modelo aún no se ha entrenado.
Echemos un vistazo a la estructura del modelo.
tf.keras.utils.plot_model(classifier_model)
Entrenamiento de modelos
Ahora tiene todas las piezas para entrenar un modelo, incluido el módulo de preprocesamiento, el codificador BERT, los datos y el clasificador.
Función de pérdida
Dado que este es un problema de clasificación binaria y el modelo de salida a una probabilidad (una capa de una sola unidad), que va a utilizar losses.BinaryCrossentropy función de pérdida.
loss = tf.keras.losses.BinaryCrossentropy(from_logits=True)
metrics = tf.metrics.BinaryAccuracy()
Optimizador
Para un ajuste fino, usemos el mismo optimizador con el que se entrenó originalmente BERT: los "Momentos adaptativos" (Adam). Este optimizador minimiza la pérdida de predicción y hace regularización por caries peso (sin uso de momentos), que también se conoce como AdamW .
Para la tasa de aprendizaje ( init_lr ), que va a utilizar el mismo horario que el BERT-capacitación previa: la descomposición lineal de una tasa inicial de aprendizaje teórico, con el prefijo con una fase lineal de calentamiento durante el primer 10% de la formación de los pasos ( num_warmup_steps ). De acuerdo con el documento BERT, la tasa de aprendizaje inicial es menor para el ajuste fino (mejor de 5e-5, 3e-5, 2e-5).
epochs = 5
steps_per_epoch = tf.data.experimental.cardinality(train_ds).numpy()
num_train_steps = steps_per_epoch * epochs
num_warmup_steps = int(0.1*num_train_steps)
init_lr = 3e-5
optimizer = optimization.create_optimizer(init_lr=init_lr,
num_train_steps=num_train_steps,
num_warmup_steps=num_warmup_steps,
optimizer_type='adamw')
Carga del modelo BERT y formación
Utilizando el classifier_model creó anteriormente, puede compilar el modelo con la pérdida, métrica y un optimizador.
classifier_model.compile(optimizer=optimizer,
loss=loss,
metrics=metrics)
print(f'Training model with {tfhub_handle_encoder}')
history = classifier_model.fit(x=train_ds,
validation_data=val_ds,
epochs=epochs)
Training model with https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Epoch 1/5 625/625 [==============================] - 91s 138ms/step - loss: 0.4776 - binary_accuracy: 0.7513 - val_loss: 0.3791 - val_binary_accuracy: 0.8380 Epoch 2/5 625/625 [==============================] - 85s 136ms/step - loss: 0.3266 - binary_accuracy: 0.8547 - val_loss: 0.3659 - val_binary_accuracy: 0.8486 Epoch 3/5 625/625 [==============================] - 86s 138ms/step - loss: 0.2521 - binary_accuracy: 0.8928 - val_loss: 0.3975 - val_binary_accuracy: 0.8518 Epoch 4/5 625/625 [==============================] - 86s 137ms/step - loss: 0.1910 - binary_accuracy: 0.9269 - val_loss: 0.4180 - val_binary_accuracy: 0.8522 Epoch 5/5 625/625 [==============================] - 86s 137ms/step - loss: 0.1509 - binary_accuracy: 0.9433 - val_loss: 0.4641 - val_binary_accuracy: 0.8522
Evaluar el modelo
Veamos cómo funciona el modelo. Se devolverán dos valores. Pérdida (un número que representa el error, los valores más bajos son mejores) y precisión.
loss, accuracy = classifier_model.evaluate(test_ds)
print(f'Loss: {loss}')
print(f'Accuracy: {accuracy}')
782/782 [==============================] - 61s 78ms/step - loss: 0.4495 - binary_accuracy: 0.8554 Loss: 0.4494614601135254 Accuracy: 0.8553599715232849
Trace la precisión y la pérdida a lo largo del tiempo
Basado en la History objeto devuelto por model.fit() . Puede trazar la pérdida de entrenamiento y validación para comparar, así como la precisión de entrenamiento y validación:
history_dict = history.history
print(history_dict.keys())
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
fig = plt.figure(figsize=(10, 6))
fig.tight_layout()
plt.subplot(2, 1, 1)
# r is for "solid red line"
plt.plot(epochs, loss, 'r', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
# plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(epochs, acc, 'r', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy']) <matplotlib.legend.Legend at 0x7fee7cdb4450>
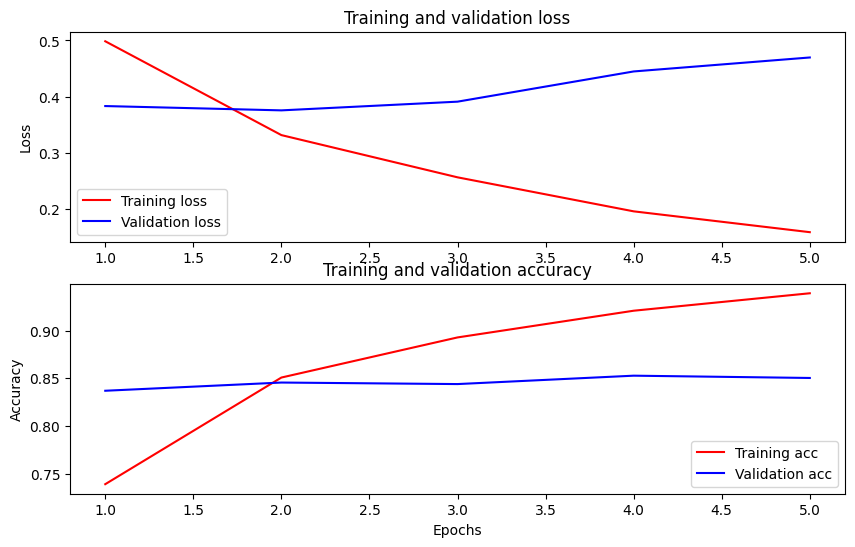
En este gráfico, las líneas rojas representan la pérdida y la precisión del entrenamiento, y las líneas azules son la pérdida y la precisión de la validación.
Exportar para inferencia
Ahora, simplemente guarde su modelo ajustado para usarlo más adelante.
dataset_name = 'imdb'
saved_model_path = './{}_bert'.format(dataset_name.replace('/', '_'))
classifier_model.save(saved_model_path, include_optimizer=False)
2021-12-01 12:26:06.207608: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Found untraced functions such as restored_function_body, restored_function_body, restored_function_body, restored_function_body, restored_function_body while saving (showing 5 of 310). These functions will not be directly callable after loading.
Recarguemos el modelo, para que puedas probarlo junto con el modelo que aún está en la memoria.
reloaded_model = tf.saved_model.load(saved_model_path)
Aquí puede probar su modelo en cualquier oración que desee, solo agregue a la variable de ejemplos a continuación.
def print_my_examples(inputs, results):
result_for_printing = \
[f'input: {inputs[i]:<30} : score: {results[i][0]:.6f}'
for i in range(len(inputs))]
print(*result_for_printing, sep='\n')
print()
examples = [
'this is such an amazing movie!', # this is the same sentence tried earlier
'The movie was great!',
'The movie was meh.',
'The movie was okish.',
'The movie was terrible...'
]
reloaded_results = tf.sigmoid(reloaded_model(tf.constant(examples)))
original_results = tf.sigmoid(classifier_model(tf.constant(examples)))
print('Results from the saved model:')
print_my_examples(examples, reloaded_results)
print('Results from the model in memory:')
print_my_examples(examples, original_results)
Results from the saved model: input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622 Results from the model in memory: input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622
Si desea utilizar su modelo en Porción del TF , recuerde que va a llamar a su SavedModel través de una de sus firmas con nombre. En Python, puede probarlos de la siguiente manera:
serving_results = reloaded_model \
.signatures['serving_default'](tf.constant(examples))
serving_results = tf.sigmoid(serving_results['classifier'])
print_my_examples(examples, serving_results)
input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622
Próximos pasos
Como siguiente paso, puede intentar resolver tareas cola con BERT en una clase particular de TPU , que se ejecuta en un TPU y cómo trabajar con múltiples entradas espectáculos.