
| | |  عرض المصدر على جيثب عرض المصدر على جيثب |
هذا الكمبيوتر الدفتري يدرب تسلسل إلى تسلسل (seq2seq) نموذجا للترجمة من الإسبانية إلى الإنجليزية على أساس الفعالة النهج لالقائم على الاهتمام العصبية الترجمة الآلية . هذا مثال متقدم يفترض بعض المعرفة بما يلي:
- تسلسل لتسلسل النماذج
- أساسيات TensorFlow أسفل طبقة keras:
- العمل مع الموترات مباشرة
- كتابة مخصصة
keras.Modelالصورة وkeras.layers
في حين عفا عليها الزمن هذا الهيكل إلى حد ما فإنه لا يزال مشروعا مفيدا جدا للعمل من خلال الحصول على فهم أعمق لآليات الانتباه (قبل ان يتوجه الى محولات ).
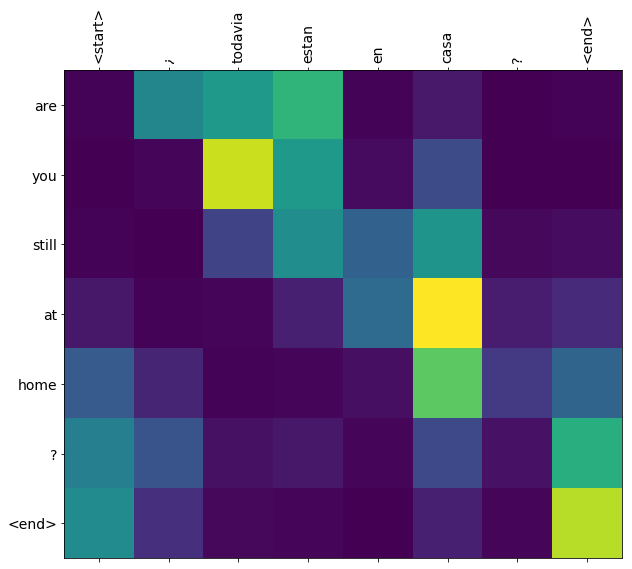
بعد تدريب نموذجية في هذا المحمول، وسوف تكون قادرة على إدخال الجملة الاسبانية، مثل، والعودة الترجمة الإنجليزية "¿todavia estan أون كاسا؟": "أنت لا تزال في المنزل"
النموذج الناتج هو أنه قابل للتصدير و tf.saved_model ، لذلك يمكن استخدامها في بيئات TensorFlow أخرى.
تعتبر جودة الترجمة معقولة بالنسبة لمثال لعبة ، ولكن ربما تكون حبكة الانتباه المتولدة أكثر إثارة للاهتمام. يوضح هذا أجزاء جملة الإدخال التي تحظى باهتمام النموذج أثناء الترجمة:
يثبت
pip install tensorflow_text
import numpy as np
import typing
from typing import Any, Tuple
import tensorflow as tf
import tensorflow_text as tf_text
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
يبني هذا البرنامج التعليمي بضع طبقات من البداية ، استخدم هذا المتغير إذا كنت تريد التبديل بين التطبيقات المخصصة والمضمنة.
use_builtins = True
يستخدم هذا البرنامج التعليمي الكثير من واجهات برمجة التطبيقات ذات المستوى المنخفض حيث يسهل الحصول على أشكال خاطئة. يستخدم هذا الفصل للتحقق من الأشكال في جميع أنحاء البرنامج التعليمي.
مدقق الشكل
class ShapeChecker():
def __init__(self):
# Keep a cache of every axis-name seen
self.shapes = {}
def __call__(self, tensor, names, broadcast=False):
if not tf.executing_eagerly():
return
if isinstance(names, str):
names = (names,)
shape = tf.shape(tensor)
rank = tf.rank(tensor)
if rank != len(names):
raise ValueError(f'Rank mismatch:\n'
f' found {rank}: {shape.numpy()}\n'
f' expected {len(names)}: {names}\n')
for i, name in enumerate(names):
if isinstance(name, int):
old_dim = name
else:
old_dim = self.shapes.get(name, None)
new_dim = shape[i]
if (broadcast and new_dim == 1):
continue
if old_dim is None:
# If the axis name is new, add its length to the cache.
self.shapes[name] = new_dim
continue
if new_dim != old_dim:
raise ValueError(f"Shape mismatch for dimension: '{name}'\n"
f" found: {new_dim}\n"
f" expected: {old_dim}\n")
البيانات
سنستخدم مجموعة بيانات اللغة التي تقدمها http://www.manythings.org/anki/ هذه بيانات يحتوي على أزواج الترجمة في شكل:
May I borrow this book? ¿Puedo tomar prestado este libro?
لديهم مجموعة متنوعة من اللغات المتاحة ، لكننا سنستخدم مجموعة البيانات الإنجليزية-الإسبانية.
قم بتنزيل وإعداد مجموعة البيانات
للراحة ، استضفنا نسخة من مجموعة البيانات هذه على Google Cloud ، ولكن يمكنك أيضًا تنزيل نسختك الخاصة. بعد تنزيل مجموعة البيانات ، إليك الخطوات التي سنتخذها لإعداد البيانات:
- إضافة بداية ونهاية رمزية إلى كل جملة.
- نظف الجمل بإزالة الأحرف الخاصة.
- قم بإنشاء فهرس للكلمات وعكس فهرس الكلمات (تعيين القواميس من كلمة → معرف ومعرف → كلمة).
- وسادة كل جملة لأقصى طول.
# Download the file
import pathlib
path_to_zip = tf.keras.utils.get_file(
'spa-eng.zip', origin='http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip',
extract=True)
path_to_file = pathlib.Path(path_to_zip).parent/'spa-eng/spa.txt'
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip 2646016/2638744 [==============================] - 0s 0us/step 2654208/2638744 [==============================] - 0s 0us/step
def load_data(path):
text = path.read_text(encoding='utf-8')
lines = text.splitlines()
pairs = [line.split('\t') for line in lines]
inp = [inp for targ, inp in pairs]
targ = [targ for targ, inp in pairs]
return targ, inp
targ, inp = load_data(path_to_file)
print(inp[-1])
Si quieres sonar como un hablante nativo, debes estar dispuesto a practicar diciendo la misma frase una y otra vez de la misma manera en que un músico de banjo practica el mismo fraseo una y otra vez hasta que lo puedan tocar correctamente y en el tiempo esperado.
print(targ[-1])
If you want to sound like a native speaker, you must be willing to practice saying the same sentence over and over in the same way that banjo players practice the same phrase over and over until they can play it correctly and at the desired tempo.
قم بإنشاء مجموعة بيانات tf.data
من هذه صفائف السلاسل يمكنك إنشاء tf.data.Dataset من السلاسل التي المراوغات ودفعات لهم بكفاءة:
BUFFER_SIZE = len(inp)
BATCH_SIZE = 64
dataset = tf.data.Dataset.from_tensor_slices((inp, targ)).shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE)
for example_input_batch, example_target_batch in dataset.take(1):
print(example_input_batch[:5])
print()
print(example_target_batch[:5])
break
tf.Tensor( [b'No s\xc3\xa9 lo que quiero.' b'\xc2\xbfDeber\xc3\xada repetirlo?' b'Tard\xc3\xa9 m\xc3\xa1s de 2 horas en traducir unas p\xc3\xa1ginas en ingl\xc3\xa9s.' b'A Tom comenz\xc3\xb3 a temerle a Mary.' b'Mi pasatiempo es la lectura.'], shape=(5,), dtype=string) tf.Tensor( [b"I don't know what I want." b'Should I repeat it?' b'It took me more than two hours to translate a few pages of English.' b'Tom became afraid of Mary.' b'My hobby is reading.'], shape=(5,), dtype=string)
معالجة النص
واحد من أهداف هذا البرنامج التعليمي هو بناء النموذج الذي يمكن أن تصدر في شكل tf.saved_model . لجعل هذا النموذج تصدير مفيدة ينبغي أن تأخذ tf.string المدخلات، والعودة tf.string المخرجات: جميع تجهيز النصوص يحدث داخل هذا النموذج.
التوحيد
يتعامل النموذج مع نص متعدد اللغات بمفردات محدودة. لذلك سيكون من المهم توحيد نص الإدخال.
الخطوة الأولى هي تسوية Unicode لتقسيم الأحرف المحركة واستبدال أحرف التوافق بمكافئاتها من ASCII.
و tensorflow_text تحتوي حزمة عملية يونيكود تطبيع:
example_text = tf.constant('¿Todavía está en casa?')
print(example_text.numpy())
print(tf_text.normalize_utf8(example_text, 'NFKD').numpy())
b'\xc2\xbfTodav\xc3\xada est\xc3\xa1 en casa?' b'\xc2\xbfTodavi\xcc\x81a esta\xcc\x81 en casa?'
سيكون تطبيع Unicode الخطوة الأولى في وظيفة توحيد النص:
def tf_lower_and_split_punct(text):
# Split accecented characters.
text = tf_text.normalize_utf8(text, 'NFKD')
text = tf.strings.lower(text)
# Keep space, a to z, and select punctuation.
text = tf.strings.regex_replace(text, '[^ a-z.?!,¿]', '')
# Add spaces around punctuation.
text = tf.strings.regex_replace(text, '[.?!,¿]', r' \0 ')
# Strip whitespace.
text = tf.strings.strip(text)
text = tf.strings.join(['[START]', text, '[END]'], separator=' ')
return text
print(example_text.numpy().decode())
print(tf_lower_and_split_punct(example_text).numpy().decode())
¿Todavía está en casa? [START] ¿ todavia esta en casa ? [END]
تحويل النص
سوف تكون ملفوفة هذه الوظيفة التوحيد حتى في tf.keras.layers.TextVectorization طبقة التي سوف تتعامل مع استخراج المفردات وتحويل إدخال النص إلى تسلسل الرموز.
max_vocab_size = 5000
input_text_processor = tf.keras.layers.TextVectorization(
standardize=tf_lower_and_split_punct,
max_tokens=max_vocab_size)
و TextVectorization طبقة والعديد من طبقات تجهيزها أخرى لها adapt طريقة. هذه الطريقة يقرأ حقبة واحدة من بيانات التدريب، ويعمل الكثير مثل Model.fix . هذا adapt طريقة تهيئة طبقة استنادا إلى البيانات. هنا تحدد المفردات:
input_text_processor.adapt(inp)
# Here are the first 10 words from the vocabulary:
input_text_processor.get_vocabulary()[:10]
['', '[UNK]', '[START]', '[END]', '.', 'que', 'de', 'el', 'a', 'no']
هذا هو الاسبانية TextVectorization طبقة، الآن بناء و .adapt() الإنجليزية احد:
output_text_processor = tf.keras.layers.TextVectorization(
standardize=tf_lower_and_split_punct,
max_tokens=max_vocab_size)
output_text_processor.adapt(targ)
output_text_processor.get_vocabulary()[:10]
['', '[UNK]', '[START]', '[END]', '.', 'the', 'i', 'to', 'you', 'tom']
الآن يمكن لهذه الطبقات تحويل مجموعة من السلاسل إلى مجموعة من معرفات الرمز المميز:
example_tokens = input_text_processor(example_input_batch)
example_tokens[:3, :10]
<tf.Tensor: shape=(3, 10), dtype=int64, numpy=
array([[ 2, 9, 17, 22, 5, 48, 4, 3, 0, 0],
[ 2, 13, 177, 1, 12, 3, 0, 0, 0, 0],
[ 2, 120, 35, 6, 290, 14, 2134, 506, 2637, 14]])>
و get_vocabulary يمكن استخدامها طريقة لتحويل معرفات رمزية إلى نص:
input_vocab = np.array(input_text_processor.get_vocabulary())
tokens = input_vocab[example_tokens[0].numpy()]
' '.join(tokens)
'[START] no se lo que quiero . [END] '
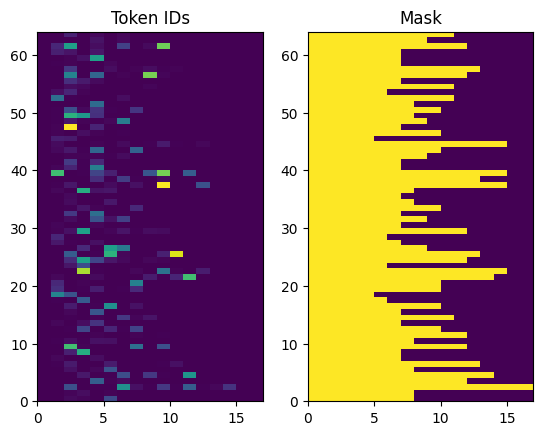
معرفات الرمز المميز التي تم إرجاعها غير مبطن. يمكن تحويل هذا بسهولة إلى قناع:
plt.subplot(1, 2, 1)
plt.pcolormesh(example_tokens)
plt.title('Token IDs')
plt.subplot(1, 2, 2)
plt.pcolormesh(example_tokens != 0)
plt.title('Mask')
Text(0.5, 1.0, 'Mask')
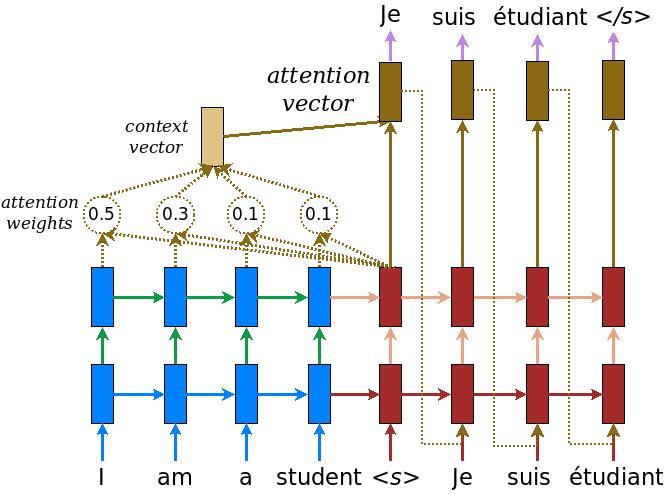
نموذج جهاز التشفير / وحدة فك التشفير
يوضح الرسم البياني التالي نظرة عامة على النموذج. في كل خطوة زمنية يتم دمج خرج مفكك الشفرة مع مجموع مرجح على المدخلات المشفرة ، للتنبؤ بالكلمة التالية. الرسم البياني والصيغ هم من الورق لونغ ل .
قبل الدخول فيه ، حدد بعض الثوابت للنموذج:
embedding_dim = 256
units = 1024
المشفر
ابدأ ببناء المشفر ، الجزء الأزرق من الرسم البياني أعلاه.
المشفر:
- يأخذ قائمة معرفات رمزية (من
input_text_processor). - يبدو حتى متجه تضمين لكل رمز (باستخدام
layers.Embedding). - يعالج التضمينات في سلسلة جديدة (باستخدام
layers.GRU). - عائدات:
- التسلسل المعالج. سيتم تمرير هذا إلى رأس الانتباه.
- الدولة الداخلية. سيتم استخدام هذا لتهيئة وحدة فك الترميز
class Encoder(tf.keras.layers.Layer):
def __init__(self, input_vocab_size, embedding_dim, enc_units):
super(Encoder, self).__init__()
self.enc_units = enc_units
self.input_vocab_size = input_vocab_size
# The embedding layer converts tokens to vectors
self.embedding = tf.keras.layers.Embedding(self.input_vocab_size,
embedding_dim)
# The GRU RNN layer processes those vectors sequentially.
self.gru = tf.keras.layers.GRU(self.enc_units,
# Return the sequence and state
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
def call(self, tokens, state=None):
shape_checker = ShapeChecker()
shape_checker(tokens, ('batch', 's'))
# 2. The embedding layer looks up the embedding for each token.
vectors = self.embedding(tokens)
shape_checker(vectors, ('batch', 's', 'embed_dim'))
# 3. The GRU processes the embedding sequence.
# output shape: (batch, s, enc_units)
# state shape: (batch, enc_units)
output, state = self.gru(vectors, initial_state=state)
shape_checker(output, ('batch', 's', 'enc_units'))
shape_checker(state, ('batch', 'enc_units'))
# 4. Returns the new sequence and its state.
return output, state
إليك كيف تتناسب معًا حتى الآن:
# Convert the input text to tokens.
example_tokens = input_text_processor(example_input_batch)
# Encode the input sequence.
encoder = Encoder(input_text_processor.vocabulary_size(),
embedding_dim, units)
example_enc_output, example_enc_state = encoder(example_tokens)
print(f'Input batch, shape (batch): {example_input_batch.shape}')
print(f'Input batch tokens, shape (batch, s): {example_tokens.shape}')
print(f'Encoder output, shape (batch, s, units): {example_enc_output.shape}')
print(f'Encoder state, shape (batch, units): {example_enc_state.shape}')
Input batch, shape (batch): (64,) Input batch tokens, shape (batch, s): (64, 14) Encoder output, shape (batch, s, units): (64, 14, 1024) Encoder state, shape (batch, units): (64, 1024)
يعيد المشفر حالته الداخلية بحيث يمكن استخدام حالته لتهيئة وحدة فك التشفير.
من الشائع أيضًا أن تقوم RNN بإرجاع حالتها بحيث يمكنها معالجة تسلسل عبر مكالمات متعددة. سترى المزيد من بناء وحدة فك التشفير.
رأس الانتباه
يستخدم مفكك التشفير الانتباه للتركيز بشكل انتقائي على أجزاء من تسلسل الإدخال. يأخذ الانتباه سلسلة من المتجهات كمدخلات لكل مثال ويعيد ناقل "انتباه" لكل مثال. هذه الطبقة اهتمام مشابهة ل layers.GlobalAveragePoling1D لكن طبقة الاهتمام ينفذ المتوسط الوزني.
لنلقِ نظرة على كيفية عمل ذلك:


أين:
- \(s\) هو مؤشر التشفير.
- \(t\) هو مؤشر فك.
- \(\alpha_{ts}\) هو الأوزان الاهتمام.
- \(h_s\) هو تسلسل النواتج التشفير يحضر إلى ( "مفتاح" الانتباه و "قيمة" في المصطلحات محول).
- \(h_t\) هي الدولة فك يحضر إلى التسلسل (انتباه "استعلام" في المصطلحات محول).
- \(c_t\) هو متجه السياق الناتجة عن ذلك.
- \(a_t\) هو الناتج النهائي يجمع بين "السياق" و "الاستعلام".
المعادلات:
- بحساب الأوزان الاهتمام، \(\alpha_{ts}\)، كما softmax عبر تسلسل الناتج التشفير و.
- تحسب متجه السياق كمجموع مرجح لمخرجات وحدة التشفير.
الأخير هو \(score\) وظيفة. وتتمثل مهمتها في حساب درجة لوغاريتمية قياسية لكل زوج من طلبات البحث الرئيسية. هناك طريقتان شائعتان:
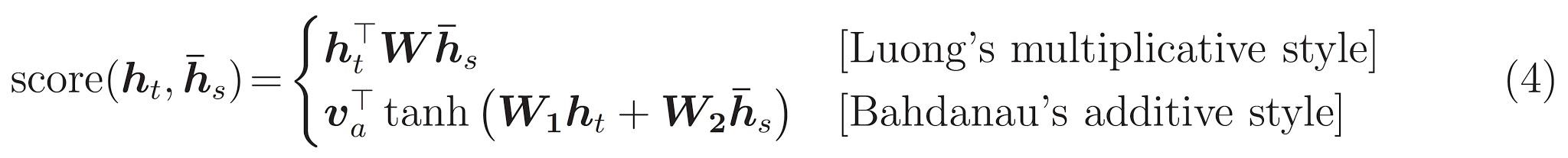
يستخدم هذا البرنامج التعليمي اهتماما Bahdanau في مضافة . يشمل TensorFlow تطبيقات على حد سواء كما layers.Attention و layers.AdditiveAttention . الطبقة تحت مقابض المصفوفات الوزن في زوج من layers.Dense طبقات، وتدعو تنفيذ المضمن.
class BahdanauAttention(tf.keras.layers.Layer):
def __init__(self, units):
super().__init__()
# For Eqn. (4), the Bahdanau attention
self.W1 = tf.keras.layers.Dense(units, use_bias=False)
self.W2 = tf.keras.layers.Dense(units, use_bias=False)
self.attention = tf.keras.layers.AdditiveAttention()
def call(self, query, value, mask):
shape_checker = ShapeChecker()
shape_checker(query, ('batch', 't', 'query_units'))
shape_checker(value, ('batch', 's', 'value_units'))
shape_checker(mask, ('batch', 's'))
# From Eqn. (4), `W1@ht`.
w1_query = self.W1(query)
shape_checker(w1_query, ('batch', 't', 'attn_units'))
# From Eqn. (4), `W2@hs`.
w2_key = self.W2(value)
shape_checker(w2_key, ('batch', 's', 'attn_units'))
query_mask = tf.ones(tf.shape(query)[:-1], dtype=bool)
value_mask = mask
context_vector, attention_weights = self.attention(
inputs = [w1_query, value, w2_key],
mask=[query_mask, value_mask],
return_attention_scores = True,
)
shape_checker(context_vector, ('batch', 't', 'value_units'))
shape_checker(attention_weights, ('batch', 't', 's'))
return context_vector, attention_weights
اختبر طبقة الانتباه
إنشاء BahdanauAttention طبقة:
attention_layer = BahdanauAttention(units)
تأخذ هذه الطبقة 3 مداخل:
- و
query: هذا سيتم إنشاؤها بواسطة وحدة فك الترميز، في وقت لاحق. - و
value: هذا وسوف يكون الناتج من التشفير. - و
mask: لاستبعاد الحشو،example_tokens != 0
(example_tokens != 0).shape
TensorShape([64, 14])
يتيح لك التنفيذ المتجه لطبقة الانتباه تمرير مجموعة من متواليات متجهات الاستعلام ومجموعة من متواليات القيمة. النتيجه هي:
- مجموعة متتاليات من متجهات النتائج بحجم الاستعلامات.
- خرائط والاهتمام دفعة، مع حجم
(query_length, value_length).
# Later, the decoder will generate this attention query
example_attention_query = tf.random.normal(shape=[len(example_tokens), 2, 10])
# Attend to the encoded tokens
context_vector, attention_weights = attention_layer(
query=example_attention_query,
value=example_enc_output,
mask=(example_tokens != 0))
print(f'Attention result shape: (batch_size, query_seq_length, units): {context_vector.shape}')
print(f'Attention weights shape: (batch_size, query_seq_length, value_seq_length): {attention_weights.shape}')
Attention result shape: (batch_size, query_seq_length, units): (64, 2, 1024) Attention weights shape: (batch_size, query_seq_length, value_seq_length): (64, 2, 14)
يجب أن الأوزان الاهتمام المبلغ إلى 1.0 لكل التسلسل.
وهنا الأوزان الاهتمام عبر متواليات في t=0 :
plt.subplot(1, 2, 1)
plt.pcolormesh(attention_weights[:, 0, :])
plt.title('Attention weights')
plt.subplot(1, 2, 2)
plt.pcolormesh(example_tokens != 0)
plt.title('Mask')
Text(0.5, 1.0, 'Mask')

بسبب التهيئة صغيرة عشوائية الأوزان اهتمام كلها قريبة إلى 1/(sequence_length) . إذا كنت في التكبير على أوزان للتسلسل واحد، يمكنك أن ترى أن هناك بعض الاختلافات الصغيرة أن هذا النموذج يمكن أن تتعلم لتوسيع، واستغلال.
attention_weights.shape
TensorShape([64, 2, 14])
attention_slice = attention_weights[0, 0].numpy()
attention_slice = attention_slice[attention_slice != 0]
plt.suptitle('Attention weights for one sequence')
plt.figure(figsize=(12, 6))
a1 = plt.subplot(1, 2, 1)
plt.bar(range(len(attention_slice)), attention_slice)
# freeze the xlim
plt.xlim(plt.xlim())
plt.xlabel('Attention weights')
a2 = plt.subplot(1, 2, 2)
plt.bar(range(len(attention_slice)), attention_slice)
plt.xlabel('Attention weights, zoomed')
# zoom in
top = max(a1.get_ylim())
zoom = 0.85*top
a2.set_ylim([0.90*top, top])
a1.plot(a1.get_xlim(), [zoom, zoom], color='k')
[<matplotlib.lines.Line2D at 0x7fb42c5b1090>] <Figure size 432x288 with 0 Axes>

جهاز فك التشفير
تتمثل مهمة وحدة فك التشفير في إنشاء تنبؤات لرمز الإخراج التالي.
- يتلقى مفكك التشفير إخراج جهاز التشفير بالكامل.
- يستخدم RNN لتتبع ما تم إنشاؤه حتى الآن.
- يستخدم ناتج RNN الخاص به كاستعلام للفت الانتباه على إخراج المشفر ، مما ينتج عنه متجه السياق.
- فهو يجمع بين ناتج RNN ومتجه السياق باستخدام المعادلة 3 (أدناه) لتوليد "متجه الانتباه".
- يقوم بإنشاء تنبؤات تسجيل الدخول للرمز المميز التالي بناءً على "متجه الانتباه".

هنا هو Decoder الطبقة ومهيئ لها. يقوم المُهيئ بإنشاء جميع الطبقات الضرورية.
class Decoder(tf.keras.layers.Layer):
def __init__(self, output_vocab_size, embedding_dim, dec_units):
super(Decoder, self).__init__()
self.dec_units = dec_units
self.output_vocab_size = output_vocab_size
self.embedding_dim = embedding_dim
# For Step 1. The embedding layer convets token IDs to vectors
self.embedding = tf.keras.layers.Embedding(self.output_vocab_size,
embedding_dim)
# For Step 2. The RNN keeps track of what's been generated so far.
self.gru = tf.keras.layers.GRU(self.dec_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
# For step 3. The RNN output will be the query for the attention layer.
self.attention = BahdanauAttention(self.dec_units)
# For step 4. Eqn. (3): converting `ct` to `at`
self.Wc = tf.keras.layers.Dense(dec_units, activation=tf.math.tanh,
use_bias=False)
# For step 5. This fully connected layer produces the logits for each
# output token.
self.fc = tf.keras.layers.Dense(self.output_vocab_size)
و call طريقة لهذه الطبقة يأخذ وإرجاع التنسورات متعددة. قم بتنظيمها في فئات حاوية بسيطة:
class DecoderInput(typing.NamedTuple):
new_tokens: Any
enc_output: Any
mask: Any
class DecoderOutput(typing.NamedTuple):
logits: Any
attention_weights: Any
هنا هو تنفيذ call الأسلوب:
def call(self,
inputs: DecoderInput,
state=None) -> Tuple[DecoderOutput, tf.Tensor]:
shape_checker = ShapeChecker()
shape_checker(inputs.new_tokens, ('batch', 't'))
shape_checker(inputs.enc_output, ('batch', 's', 'enc_units'))
shape_checker(inputs.mask, ('batch', 's'))
if state is not None:
shape_checker(state, ('batch', 'dec_units'))
# Step 1. Lookup the embeddings
vectors = self.embedding(inputs.new_tokens)
shape_checker(vectors, ('batch', 't', 'embedding_dim'))
# Step 2. Process one step with the RNN
rnn_output, state = self.gru(vectors, initial_state=state)
shape_checker(rnn_output, ('batch', 't', 'dec_units'))
shape_checker(state, ('batch', 'dec_units'))
# Step 3. Use the RNN output as the query for the attention over the
# encoder output.
context_vector, attention_weights = self.attention(
query=rnn_output, value=inputs.enc_output, mask=inputs.mask)
shape_checker(context_vector, ('batch', 't', 'dec_units'))
shape_checker(attention_weights, ('batch', 't', 's'))
# Step 4. Eqn. (3): Join the context_vector and rnn_output
# [ct; ht] shape: (batch t, value_units + query_units)
context_and_rnn_output = tf.concat([context_vector, rnn_output], axis=-1)
# Step 4. Eqn. (3): `at = tanh(Wc@[ct; ht])`
attention_vector = self.Wc(context_and_rnn_output)
shape_checker(attention_vector, ('batch', 't', 'dec_units'))
# Step 5. Generate logit predictions:
logits = self.fc(attention_vector)
shape_checker(logits, ('batch', 't', 'output_vocab_size'))
return DecoderOutput(logits, attention_weights), state
Decoder.call = call
التشفير عمليات تسلسل لها مدخلات الكامل مع مكالمة واحدة إلى RNN لها. هذا تنفيذ فك تستطيع أن تفعل ذلك أيضا للتدريب الفعال. لكن هذا البرنامج التعليمي سيعمل على تشغيل وحدة فك التشفير في حلقة لعدة أسباب:
- المرونة: تمنحك كتابة الحلقة تحكمًا مباشرًا في إجراء التدريب.
- وضوح: من الممكن أن تفعل الحيل اخفاء واستخدام
layers.RNN، أوtfa.seq2seqواجهات برمجة التطبيقات لحزم كل هذا في مكالمة واحدة. لكن كتابتها في شكل حلقة قد يكون أوضح.- ويتجلى حلقة تدريبية مجانية في الجيل نص tutiorial.
حاول الآن استخدام وحدة فك الترميز هذه.
decoder = Decoder(output_text_processor.vocabulary_size(),
embedding_dim, units)
يأخذ جهاز فك التشفير 4 مدخلات.
-
new_tokens- ورمز الماضي ولدت. تهيئة وحدة فك الترميز مع"[START]"رمز. -
enc_output- ولدت بعد وEncoder. -
mask- A موتر منطقية تشير إلى حيثtokens != 0 -
state- والسابقstateالناتج من وحدة فك الترميز (الحالة الداخلية RNN وحدة فك الترميز ل). تمريرNoneلصفر تهيئة عليه. يقوم الورق الأصلي بتهيئته من حالة RNN النهائية لجهاز التشفير.
# Convert the target sequence, and collect the "[START]" tokens
example_output_tokens = output_text_processor(example_target_batch)
start_index = output_text_processor.get_vocabulary().index('[START]')
first_token = tf.constant([[start_index]] * example_output_tokens.shape[0])
# Run the decoder
dec_result, dec_state = decoder(
inputs = DecoderInput(new_tokens=first_token,
enc_output=example_enc_output,
mask=(example_tokens != 0)),
state = example_enc_state
)
print(f'logits shape: (batch_size, t, output_vocab_size) {dec_result.logits.shape}')
print(f'state shape: (batch_size, dec_units) {dec_state.shape}')
logits shape: (batch_size, t, output_vocab_size) (64, 1, 5000) state shape: (batch_size, dec_units) (64, 1024)
قم بتجربة رمز وفقًا للسجلات:
sampled_token = tf.random.categorical(dec_result.logits[:, 0, :], num_samples=1)
فك شفرة الرمز باعتباره الكلمة الأولى في الإخراج:
vocab = np.array(output_text_processor.get_vocabulary())
first_word = vocab[sampled_token.numpy()]
first_word[:5]
array([['already'],
['plants'],
['pretended'],
['convince'],
['square']], dtype='<U16')
استخدم الآن وحدة فك التشفير لإنشاء مجموعة ثانية من السجلات.
- تمرير نفس
enc_outputوmask، وهذه لم تتغير. - تمرير عينات رمزية كما
new_tokens. - تمرير
decoder_stateفك عاد آخر مرة، لذلك تواصل RNN مع ذاكرة من النقطة التي توقفت عندها في المرة السابقة.
dec_result, dec_state = decoder(
DecoderInput(sampled_token,
example_enc_output,
mask=(example_tokens != 0)),
state=dec_state)
sampled_token = tf.random.categorical(dec_result.logits[:, 0, :], num_samples=1)
first_word = vocab[sampled_token.numpy()]
first_word[:5]
array([['nap'],
['mean'],
['worker'],
['passage'],
['baked']], dtype='<U16')
تمرين
الآن بعد أن أصبح لديك جميع مكونات النموذج ، حان الوقت لبدء تدريب النموذج. انك سوف تحتاج:
- وظيفة الخسارة والمحسن لأداء التحسين.
- وظيفة خطوة تدريب تحدد كيفية تحديث النموذج لكل دفعة إدخال / هدف.
- حلقة تدريب لقيادة التدريب وحفظ نقاط التفتيش.
تحديد وظيفة الخسارة
class MaskedLoss(tf.keras.losses.Loss):
def __init__(self):
self.name = 'masked_loss'
self.loss = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction='none')
def __call__(self, y_true, y_pred):
shape_checker = ShapeChecker()
shape_checker(y_true, ('batch', 't'))
shape_checker(y_pred, ('batch', 't', 'logits'))
# Calculate the loss for each item in the batch.
loss = self.loss(y_true, y_pred)
shape_checker(loss, ('batch', 't'))
# Mask off the losses on padding.
mask = tf.cast(y_true != 0, tf.float32)
shape_checker(mask, ('batch', 't'))
loss *= mask
# Return the total.
return tf.reduce_sum(loss)
نفذ خطوة التدريب
تبدأ مع فئة النموذج، وسيتم تنفيذ عملية التدريب كما train_step الطريقة على هذا النموذج. انظر تخصيص تناسب لمزيد من التفاصيل.
هنا train_step الأسلوب هو التفاف حول _train_step التنفيذ والتي سوف تأتي لاحقا. ويشمل هذا المجمع التحول إلى تشغيل وإيقاف tf.function تجميع، لجعل التصحيح أسهل.
class TrainTranslator(tf.keras.Model):
def __init__(self, embedding_dim, units,
input_text_processor,
output_text_processor,
use_tf_function=True):
super().__init__()
# Build the encoder and decoder
encoder = Encoder(input_text_processor.vocabulary_size(),
embedding_dim, units)
decoder = Decoder(output_text_processor.vocabulary_size(),
embedding_dim, units)
self.encoder = encoder
self.decoder = decoder
self.input_text_processor = input_text_processor
self.output_text_processor = output_text_processor
self.use_tf_function = use_tf_function
self.shape_checker = ShapeChecker()
def train_step(self, inputs):
self.shape_checker = ShapeChecker()
if self.use_tf_function:
return self._tf_train_step(inputs)
else:
return self._train_step(inputs)
عموما لتنفيذ Model.train_step الطريقة على النحو التالي:
- الحصول على دفعة من
input_text, target_textمنtf.data.Dataset. - قم بتحويل مدخلات النص الخام تلك إلى رموز وأقنعة.
- تشغيل التشفير على
input_tokensللحصول علىencoder_outputوencoder_state. - تهيئة حالة وحدة فك التشفير والخسارة.
- حلقة على
target_tokens:- قم بتشغيل وحدة فك الترميز خطوة واحدة في كل مرة.
- احسب الخسارة لكل خطوة.
- تراكم متوسط الخسارة.
- حساب الانحدار من الخسارة واستخدام محسن لتطبيق التحديثات على النموذج
trainable_variables.
و _preprocess الطريقة، وأضاف أدناه، تنفذ خطوات رقم 1 ورقم 2:
def _preprocess(self, input_text, target_text):
self.shape_checker(input_text, ('batch',))
self.shape_checker(target_text, ('batch',))
# Convert the text to token IDs
input_tokens = self.input_text_processor(input_text)
target_tokens = self.output_text_processor(target_text)
self.shape_checker(input_tokens, ('batch', 's'))
self.shape_checker(target_tokens, ('batch', 't'))
# Convert IDs to masks.
input_mask = input_tokens != 0
self.shape_checker(input_mask, ('batch', 's'))
target_mask = target_tokens != 0
self.shape_checker(target_mask, ('batch', 't'))
return input_tokens, input_mask, target_tokens, target_mask
TrainTranslator._preprocess = _preprocess
و _train_step الطريقة، وأضاف أدناه، ويعالج الخطوات المتبقية باستثناء بالفعل بتشغيل وحدة فك الترميز:
def _train_step(self, inputs):
input_text, target_text = inputs
(input_tokens, input_mask,
target_tokens, target_mask) = self._preprocess(input_text, target_text)
max_target_length = tf.shape(target_tokens)[1]
with tf.GradientTape() as tape:
# Encode the input
enc_output, enc_state = self.encoder(input_tokens)
self.shape_checker(enc_output, ('batch', 's', 'enc_units'))
self.shape_checker(enc_state, ('batch', 'enc_units'))
# Initialize the decoder's state to the encoder's final state.
# This only works if the encoder and decoder have the same number of
# units.
dec_state = enc_state
loss = tf.constant(0.0)
for t in tf.range(max_target_length-1):
# Pass in two tokens from the target sequence:
# 1. The current input to the decoder.
# 2. The target for the decoder's next prediction.
new_tokens = target_tokens[:, t:t+2]
step_loss, dec_state = self._loop_step(new_tokens, input_mask,
enc_output, dec_state)
loss = loss + step_loss
# Average the loss over all non padding tokens.
average_loss = loss / tf.reduce_sum(tf.cast(target_mask, tf.float32))
# Apply an optimization step
variables = self.trainable_variables
gradients = tape.gradient(average_loss, variables)
self.optimizer.apply_gradients(zip(gradients, variables))
# Return a dict mapping metric names to current value
return {'batch_loss': average_loss}
TrainTranslator._train_step = _train_step
و _loop_step الطريقة، وأضاف أدناه، تنفيذ وحدة فك الترميز ويحسب الخسارة الإضافية ودولة فك الجديدة ( dec_state ).
def _loop_step(self, new_tokens, input_mask, enc_output, dec_state):
input_token, target_token = new_tokens[:, 0:1], new_tokens[:, 1:2]
# Run the decoder one step.
decoder_input = DecoderInput(new_tokens=input_token,
enc_output=enc_output,
mask=input_mask)
dec_result, dec_state = self.decoder(decoder_input, state=dec_state)
self.shape_checker(dec_result.logits, ('batch', 't1', 'logits'))
self.shape_checker(dec_result.attention_weights, ('batch', 't1', 's'))
self.shape_checker(dec_state, ('batch', 'dec_units'))
# `self.loss` returns the total for non-padded tokens
y = target_token
y_pred = dec_result.logits
step_loss = self.loss(y, y_pred)
return step_loss, dec_state
TrainTranslator._loop_step = _loop_step
اختبر خطوة التدريب
بناء TrainTranslator ، وتكوينه لتدريب باستخدام Model.compile الأسلوب:
translator = TrainTranslator(
embedding_dim, units,
input_text_processor=input_text_processor,
output_text_processor=output_text_processor,
use_tf_function=False)
# Configure the loss and optimizer
translator.compile(
optimizer=tf.optimizers.Adam(),
loss=MaskedLoss(),
)
اختبار ل train_step . بالنسبة لنموذج نصي مثل هذا ، يجب أن تبدأ الخسارة بالقرب من:
np.log(output_text_processor.vocabulary_size())
8.517193191416236
%%time
for n in range(10):
print(translator.train_step([example_input_batch, example_target_batch]))
print()
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.5849695>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.55271>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.4929113>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.3296022>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=6.80437>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=5.000246>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=5.8740363>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.794589>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.3175836>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.108163>}
CPU times: user 5.49 s, sys: 0 ns, total: 5.49 s
Wall time: 5.45 s
في حين أنه من الأسهل لتصحيح دون tf.function يفعل إعطاء دفعة الأداء. حتى الآن أن _train_step طريقة يعمل، حاول tf.function الملفوفة _tf_train_step ، لتعظيم الأداء أثناء التدريب:
@tf.function(input_signature=[[tf.TensorSpec(dtype=tf.string, shape=[None]),
tf.TensorSpec(dtype=tf.string, shape=[None])]])
def _tf_train_step(self, inputs):
return self._train_step(inputs)
TrainTranslator._tf_train_step = _tf_train_step
translator.use_tf_function = True
ستكون المكالمة الأولى بطيئة ، لأنها تتعقب الوظيفة.
translator.train_step([example_input_batch, example_target_batch])
2021-12-04 12:09:48.074769: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/PartitionedCall was passed variant from gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:09:48.180156: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] layout failed: OUT_OF_RANGE: src_output = 25, but num_outputs is only 25
2021-12-04 12:09:48.285846: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] tfg_optimizer{} failed: INVALID_ARGUMENT: Input 6 of node gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/PartitionedCall was passed variant from gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
when importing GraphDef to MLIR module in GrapplerHook
2021-12-04 12:09:48.307794: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/PartitionedCall was passed variant from gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:09:48.425447: W tensorflow/core/common_runtime/process_function_library_runtime.cc:866] Ignoring multi-device function optimization failure: INVALID_ARGUMENT: Input 1 of node while/body/_1/while/TensorListPushBack_56 was passed float from while/body/_1/while/decoder_1/gru_3/PartitionedCall:6 incompatible with expected variant.
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.045638>}
ولكن بعد ذلك انها عادة ما تكون 2-3x أسرع من حريصة train_step الأسلوب:
%%time
for n in range(10):
print(translator.train_step([example_input_batch, example_target_batch]))
print()
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.1098256>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.169871>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.139249>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.0410743>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.9664454>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.895707>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.8154407>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.7583396>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.6986444>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.640298>}
CPU times: user 4.4 s, sys: 960 ms, total: 5.36 s
Wall time: 1.67 s
الاختبار الجيد للنموذج الجديد هو معرفة أنه يمكن أن يتسع لمجموعة واحدة من المدخلات. جربها ، يجب أن تذهب الخسارة بسرعة إلى الصفر:
losses = []
for n in range(100):
print('.', end='')
logs = translator.train_step([example_input_batch, example_target_batch])
losses.append(logs['batch_loss'].numpy())
print()
plt.plot(losses)
.................................................................................................... [<matplotlib.lines.Line2D at 0x7fb427edf210>]

الآن بعد أن أصبحت واثقًا من أن خطوة التدريب تعمل ، قم بإنشاء نسخة جديدة من النموذج للتدريب من البداية:
train_translator = TrainTranslator(
embedding_dim, units,
input_text_processor=input_text_processor,
output_text_processor=output_text_processor)
# Configure the loss and optimizer
train_translator.compile(
optimizer=tf.optimizers.Adam(),
loss=MaskedLoss(),
)
تدريب النموذج
بينما لا يوجد شيء خاطئ مع الكتابة الخاصة حلقة التدريب المخصصة، وتنفيذ Model.train_step الطريقة، كما هو الحال في الجزء السابق، ويسمح لك لتشغيل Model.fit وتجنب إعادة كتابة كل هذا الرمز المرجل لوحة.
هذا البرنامج التعليمي القطارات فقط لبضع العهود، لذلك استخدام callbacks.Callback لجمع تاريخ خسائر دفعة، بتهمة التآمر:
class BatchLogs(tf.keras.callbacks.Callback):
def __init__(self, key):
self.key = key
self.logs = []
def on_train_batch_end(self, n, logs):
self.logs.append(logs[self.key])
batch_loss = BatchLogs('batch_loss')
train_translator.fit(dataset, epochs=3,
callbacks=[batch_loss])
Epoch 1/3
2021-12-04 12:10:11.617839: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/PartitionedCall was passed variant from StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:10:11.737105: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] layout failed: OUT_OF_RANGE: src_output = 25, but num_outputs is only 25
2021-12-04 12:10:11.855054: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] tfg_optimizer{} failed: INVALID_ARGUMENT: Input 6 of node StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/PartitionedCall was passed variant from StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
when importing GraphDef to MLIR module in GrapplerHook
2021-12-04 12:10:11.878896: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/PartitionedCall was passed variant from StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:10:12.004755: W tensorflow/core/common_runtime/process_function_library_runtime.cc:866] Ignoring multi-device function optimization failure: INVALID_ARGUMENT: Input 1 of node StatefulPartitionedCall/while/body/_59/while/TensorListPushBack_56 was passed float from StatefulPartitionedCall/while/body/_59/while/decoder_2/gru_5/PartitionedCall:6 incompatible with expected variant.
1859/1859 [==============================] - 349s 185ms/step - batch_loss: 2.0443
Epoch 2/3
1859/1859 [==============================] - 350s 188ms/step - batch_loss: 1.0382
Epoch 3/3
1859/1859 [==============================] - 343s 184ms/step - batch_loss: 0.8085
<keras.callbacks.History at 0x7fb42c3eda10>
plt.plot(batch_loss.logs)
plt.ylim([0, 3])
plt.xlabel('Batch #')
plt.ylabel('CE/token')
Text(0, 0.5, 'CE/token')
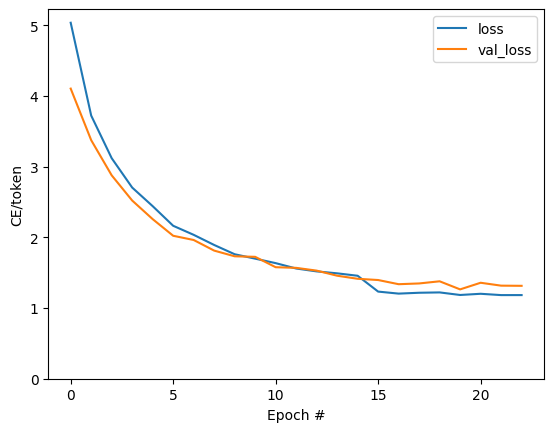
القفزات المرئية في الحبكة هي في حدود العصر.
ترجمة
والآن بعد أن يتم تدريب نموذج، وتنفيذ وظيفة لتنفيذ كامل text => text الترجمة.
لهذا احتياجات نموذج لقلب text => token IDs الخرائط التي تقدمها output_text_processor . يحتاج أيضًا إلى معرفة معرفات الرموز المميزة الخاصة. يتم تنفيذ كل هذا في المنشئ للفئة الجديدة. سيتبع تنفيذ طريقة الترجمة الفعلية.
بشكل عام ، هذا مشابه لحلقة التدريب ، باستثناء أن المدخلات إلى مفكك الشفرة في كل خطوة زمنية هي عينة من آخر تنبؤ لجهاز فك التشفير.
class Translator(tf.Module):
def __init__(self, encoder, decoder, input_text_processor,
output_text_processor):
self.encoder = encoder
self.decoder = decoder
self.input_text_processor = input_text_processor
self.output_text_processor = output_text_processor
self.output_token_string_from_index = (
tf.keras.layers.StringLookup(
vocabulary=output_text_processor.get_vocabulary(),
mask_token='',
invert=True))
# The output should never generate padding, unknown, or start.
index_from_string = tf.keras.layers.StringLookup(
vocabulary=output_text_processor.get_vocabulary(), mask_token='')
token_mask_ids = index_from_string(['', '[UNK]', '[START]']).numpy()
token_mask = np.zeros([index_from_string.vocabulary_size()], dtype=np.bool)
token_mask[np.array(token_mask_ids)] = True
self.token_mask = token_mask
self.start_token = index_from_string(tf.constant('[START]'))
self.end_token = index_from_string(tf.constant('[END]'))
translator = Translator(
encoder=train_translator.encoder,
decoder=train_translator.decoder,
input_text_processor=input_text_processor,
output_text_processor=output_text_processor,
)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:21: DeprecationWarning: `np.bool` is a deprecated alias for the builtin `bool`. To silence this warning, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
تحويل معرفات الرمز المميز إلى نص
الطريقة الأولى لتنفيذ هو tokens_to_text التي المتحولين من معرفات رمزية إلى نص مقروء الإنسان.
def tokens_to_text(self, result_tokens):
shape_checker = ShapeChecker()
shape_checker(result_tokens, ('batch', 't'))
result_text_tokens = self.output_token_string_from_index(result_tokens)
shape_checker(result_text_tokens, ('batch', 't'))
result_text = tf.strings.reduce_join(result_text_tokens,
axis=1, separator=' ')
shape_checker(result_text, ('batch'))
result_text = tf.strings.strip(result_text)
shape_checker(result_text, ('batch',))
return result_text
Translator.tokens_to_text = tokens_to_text
أدخل بعض معرفات الرموز المميزة العشوائية واطلع على ما يولده:
example_output_tokens = tf.random.uniform(
shape=[5, 2], minval=0, dtype=tf.int64,
maxval=output_text_processor.vocabulary_size())
translator.tokens_to_text(example_output_tokens).numpy()
array([b'vain mysteries', b'funny ham', b'drivers responding',
b'mysterious ignoring', b'fashion votes'], dtype=object)
عينة من توقعات وحدة فك التشفير
تأخذ هذه الوظيفة مخرجات اللوغاريتم الخاصة بوحدة فك التشفير وعينات من معرفات الرمز المميز من هذا التوزيع:
def sample(self, logits, temperature):
shape_checker = ShapeChecker()
# 't' is usually 1 here.
shape_checker(logits, ('batch', 't', 'vocab'))
shape_checker(self.token_mask, ('vocab',))
token_mask = self.token_mask[tf.newaxis, tf.newaxis, :]
shape_checker(token_mask, ('batch', 't', 'vocab'), broadcast=True)
# Set the logits for all masked tokens to -inf, so they are never chosen.
logits = tf.where(self.token_mask, -np.inf, logits)
if temperature == 0.0:
new_tokens = tf.argmax(logits, axis=-1)
else:
logits = tf.squeeze(logits, axis=1)
new_tokens = tf.random.categorical(logits/temperature,
num_samples=1)
shape_checker(new_tokens, ('batch', 't'))
return new_tokens
Translator.sample = sample
اختبر تشغيل هذه الوظيفة على بعض المدخلات العشوائية:
example_logits = tf.random.normal([5, 1, output_text_processor.vocabulary_size()])
example_output_tokens = translator.sample(example_logits, temperature=1.0)
example_output_tokens
<tf.Tensor: shape=(5, 1), dtype=int64, numpy=
array([[4506],
[3577],
[2961],
[4586],
[ 944]])>
نفِّذ حلقة الترجمة
فيما يلي تنفيذ كامل لحلقة ترجمة النص إلى نص.
هذا التطبيق بجمع النتائج في قوائم الثعبان، وقبل استخدام tf.concat للانضمام اليهم في التنسورات.
هذا التطبيق unrolls ثابت الرسم البياني إلى max_length التكرار. هذا جيد مع الإعدام الشغوف في بيثون.
def translate_unrolled(self,
input_text, *,
max_length=50,
return_attention=True,
temperature=1.0):
batch_size = tf.shape(input_text)[0]
input_tokens = self.input_text_processor(input_text)
enc_output, enc_state = self.encoder(input_tokens)
dec_state = enc_state
new_tokens = tf.fill([batch_size, 1], self.start_token)
result_tokens = []
attention = []
done = tf.zeros([batch_size, 1], dtype=tf.bool)
for _ in range(max_length):
dec_input = DecoderInput(new_tokens=new_tokens,
enc_output=enc_output,
mask=(input_tokens!=0))
dec_result, dec_state = self.decoder(dec_input, state=dec_state)
attention.append(dec_result.attention_weights)
new_tokens = self.sample(dec_result.logits, temperature)
# If a sequence produces an `end_token`, set it `done`
done = done | (new_tokens == self.end_token)
# Once a sequence is done it only produces 0-padding.
new_tokens = tf.where(done, tf.constant(0, dtype=tf.int64), new_tokens)
# Collect the generated tokens
result_tokens.append(new_tokens)
if tf.executing_eagerly() and tf.reduce_all(done):
break
# Convert the list of generates token ids to a list of strings.
result_tokens = tf.concat(result_tokens, axis=-1)
result_text = self.tokens_to_text(result_tokens)
if return_attention:
attention_stack = tf.concat(attention, axis=1)
return {'text': result_text, 'attention': attention_stack}
else:
return {'text': result_text}
Translator.translate = translate_unrolled
قم بتشغيله بإدخال بسيط:
%%time
input_text = tf.constant([
'hace mucho frio aqui.', # "It's really cold here."
'Esta es mi vida.', # "This is my life.""
])
result = translator.translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its a long cold here . this is my life . CPU times: user 165 ms, sys: 4.37 ms, total: 169 ms Wall time: 164 ms
إذا كنت ترغب في تصدير هذا النموذج سوف تحتاج إلى التفاف هذه الطريقة في tf.function . يحتوي هذا التنفيذ الأساسي على بعض المشكلات إذا حاولت القيام بذلك:
- الرسوم البيانية الناتجة كبيرة جدًا وتستغرق بضع ثوانٍ في الإنشاء أو الحفظ أو التحميل.
- لا يمكنك كسر من حلقة بسطه بشكل ثابت، لذلك سيتم تشغيله دائما
max_lengthالتكرار، حتى لو تتم جميع النواتج. ولكن حتى مع ذلك ، يكون أسرع بشكل هامشي من التنفيذ المتلهف.
@tf.function(input_signature=[tf.TensorSpec(dtype=tf.string, shape=[None])])
def tf_translate(self, input_text):
return self.translate(input_text)
Translator.tf_translate = tf_translate
تشغيل tf.function مرة واحدة لترجمة ذلك:
%%time
result = translator.tf_translate(
input_text = input_text)
CPU times: user 18.8 s, sys: 0 ns, total: 18.8 s Wall time: 18.7 s
%%time
result = translator.tf_translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its very cold here . this is my life . CPU times: user 175 ms, sys: 0 ns, total: 175 ms Wall time: 88 ms
[اختياري] استخدم حلقة رمزية
def translate_symbolic(self,
input_text,
*,
max_length=50,
return_attention=True,
temperature=1.0):
shape_checker = ShapeChecker()
shape_checker(input_text, ('batch',))
batch_size = tf.shape(input_text)[0]
# Encode the input
input_tokens = self.input_text_processor(input_text)
shape_checker(input_tokens, ('batch', 's'))
enc_output, enc_state = self.encoder(input_tokens)
shape_checker(enc_output, ('batch', 's', 'enc_units'))
shape_checker(enc_state, ('batch', 'enc_units'))
# Initialize the decoder
dec_state = enc_state
new_tokens = tf.fill([batch_size, 1], self.start_token)
shape_checker(new_tokens, ('batch', 't1'))
# Initialize the accumulators
result_tokens = tf.TensorArray(tf.int64, size=1, dynamic_size=True)
attention = tf.TensorArray(tf.float32, size=1, dynamic_size=True)
done = tf.zeros([batch_size, 1], dtype=tf.bool)
shape_checker(done, ('batch', 't1'))
for t in tf.range(max_length):
dec_input = DecoderInput(
new_tokens=new_tokens, enc_output=enc_output, mask=(input_tokens != 0))
dec_result, dec_state = self.decoder(dec_input, state=dec_state)
shape_checker(dec_result.attention_weights, ('batch', 't1', 's'))
attention = attention.write(t, dec_result.attention_weights)
new_tokens = self.sample(dec_result.logits, temperature)
shape_checker(dec_result.logits, ('batch', 't1', 'vocab'))
shape_checker(new_tokens, ('batch', 't1'))
# If a sequence produces an `end_token`, set it `done`
done = done | (new_tokens == self.end_token)
# Once a sequence is done it only produces 0-padding.
new_tokens = tf.where(done, tf.constant(0, dtype=tf.int64), new_tokens)
# Collect the generated tokens
result_tokens = result_tokens.write(t, new_tokens)
if tf.reduce_all(done):
break
# Convert the list of generated token ids to a list of strings.
result_tokens = result_tokens.stack()
shape_checker(result_tokens, ('t', 'batch', 't0'))
result_tokens = tf.squeeze(result_tokens, -1)
result_tokens = tf.transpose(result_tokens, [1, 0])
shape_checker(result_tokens, ('batch', 't'))
result_text = self.tokens_to_text(result_tokens)
shape_checker(result_text, ('batch',))
if return_attention:
attention_stack = attention.stack()
shape_checker(attention_stack, ('t', 'batch', 't1', 's'))
attention_stack = tf.squeeze(attention_stack, 2)
shape_checker(attention_stack, ('t', 'batch', 's'))
attention_stack = tf.transpose(attention_stack, [1, 0, 2])
shape_checker(attention_stack, ('batch', 't', 's'))
return {'text': result_text, 'attention': attention_stack}
else:
return {'text': result_text}
Translator.translate = translate_symbolic
استخدم التطبيق الأولي قوائم بايثون لتجميع المخرجات. هذه الاستخدامات tf.range باسم مكرر حلقة، مما يسمح tf.autograph لتحويل الحلقة. أكبر تغيير في هذا التطبيق هو استخدام tf.TensorArray بدلا من الثعبان list لالتنسورات تتراكم. tf.TensorArray مطلوب لجمع عدد متغير من التنسورات في وضع الرسم البياني.
مع التنفيذ الحثيث ، يعمل هذا التنفيذ على قدم المساواة مع الأصل:
%%time
result = translator.translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its very cold here . this is my life . CPU times: user 175 ms, sys: 0 ns, total: 175 ms Wall time: 170 ms
ولكن عند الانتهاء من ذلك في tf.function ستلاحظ اثنين من الخلافات.
@tf.function(input_signature=[tf.TensorSpec(dtype=tf.string, shape=[None])])
def tf_translate(self, input_text):
return self.translate(input_text)
Translator.tf_translate = tf_translate
أولا: إنشاء الرسم البياني هو أسرع بكثير (~ 10X)، لأنه لا يخلق max_iterations نسخ من النموذج.
%%time
result = translator.tf_translate(
input_text = input_text)
CPU times: user 1.79 s, sys: 0 ns, total: 1.79 s Wall time: 1.77 s
ثانيًا: الوظيفة المترجمة تكون أسرع بكثير في المدخلات الصغيرة (5x في هذا المثال) ، لأنها يمكن أن تنفصل عن الحلقة.
%%time
result = translator.tf_translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its very cold here . this is my life . CPU times: user 40.1 ms, sys: 0 ns, total: 40.1 ms Wall time: 17.1 ms
تصور العملية
الأوزان الاهتمام إرجاعها بواسطة translate عرض طريقة حيث كان النموذج "يبحث" عندما ولدت كل رمز الانتاج.
لذلك يجب أن يعيد مجموع الانتباه على المدخلات جميع الآحاد:
a = result['attention'][0]
print(np.sum(a, axis=-1))
[1.0000001 0.99999994 1. 0.99999994 1. 0.99999994]
فيما يلي توزيع الانتباه لخطوة الإخراج الأولى للمثال الأول. لاحظ كيف أصبح الاهتمام الآن أكثر تركيزًا مما كان عليه بالنسبة للنموذج غير المدرب:
_ = plt.bar(range(len(a[0, :])), a[0, :])

نظرًا لوجود بعض المحاذاة التقريبية بين كلمات الإدخال والإخراج ، فإنك تتوقع تركيز الانتباه بالقرب من القطر:
plt.imshow(np.array(a), vmin=0.0)
<matplotlib.image.AxesImage at 0x7faf2886ced0>

إليك بعض التعليمات البرمجية لإنشاء مخطط اهتمام أفضل:
مؤامرات الانتباه المسمى
def plot_attention(attention, sentence, predicted_sentence):
sentence = tf_lower_and_split_punct(sentence).numpy().decode().split()
predicted_sentence = predicted_sentence.numpy().decode().split() + ['[END]']
fig = plt.figure(figsize=(10, 10))
ax = fig.add_subplot(1, 1, 1)
attention = attention[:len(predicted_sentence), :len(sentence)]
ax.matshow(attention, cmap='viridis', vmin=0.0)
fontdict = {'fontsize': 14}
ax.set_xticklabels([''] + sentence, fontdict=fontdict, rotation=90)
ax.set_yticklabels([''] + predicted_sentence, fontdict=fontdict)
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
ax.set_xlabel('Input text')
ax.set_ylabel('Output text')
plt.suptitle('Attention weights')
i=0
plot_attention(result['attention'][i], input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app
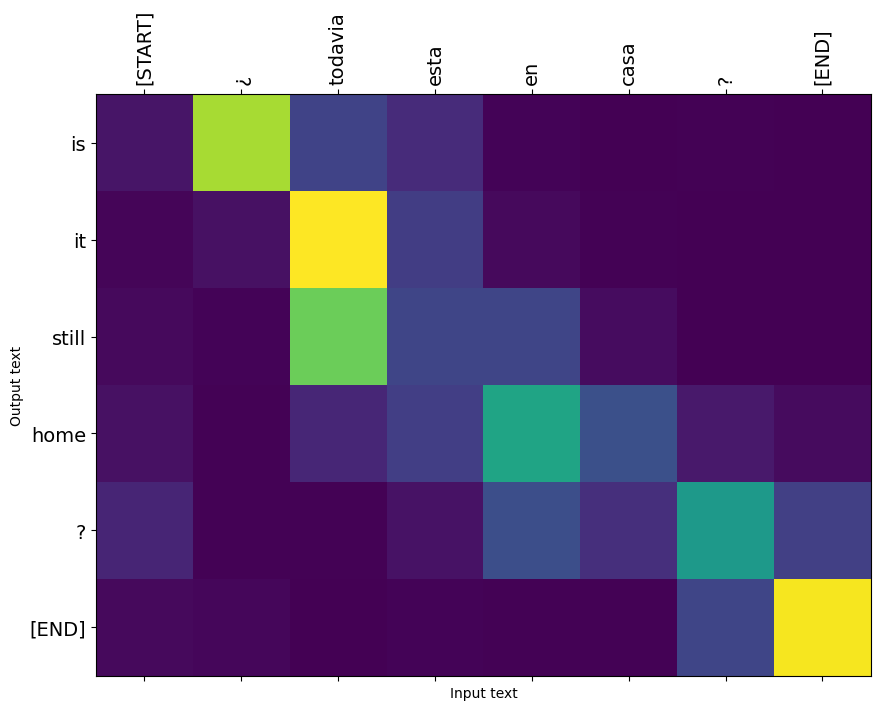
ترجم بضع جمل أخرى ورسمها:
%%time
three_input_text = tf.constant([
# This is my life.
'Esta es mi vida.',
# Are they still home?
'¿Todavía están en casa?',
# Try to find out.'
'Tratar de descubrir.',
])
result = translator.tf_translate(three_input_text)
for tr in result['text']:
print(tr.numpy().decode())
print()
this is my life . are you still at home ? all about killed . CPU times: user 78 ms, sys: 23 ms, total: 101 ms Wall time: 23.1 ms
result['text']
<tf.Tensor: shape=(3,), dtype=string, numpy=
array([b'this is my life .', b'are you still at home ?',
b'all about killed .'], dtype=object)>
i = 0
plot_attention(result['attention'][i], three_input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app

i = 1
plot_attention(result['attention'][i], three_input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app

i = 2
plot_attention(result['attention'][i], three_input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app

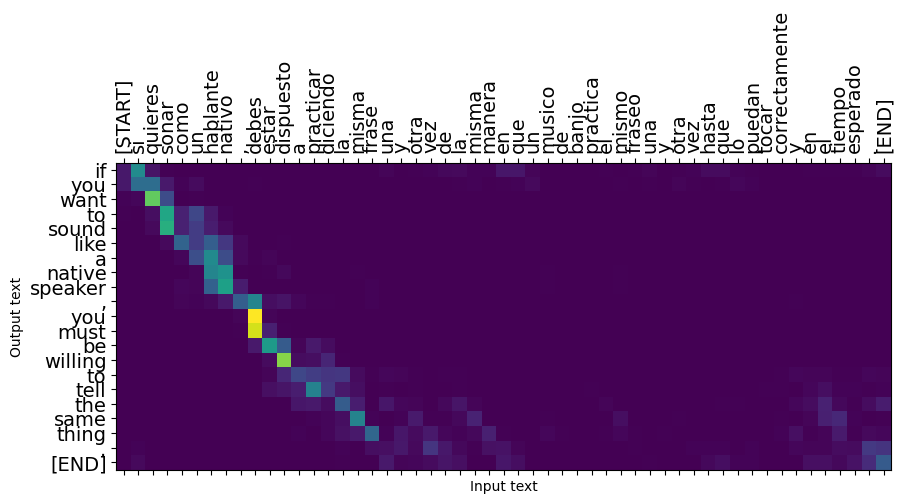
غالبًا ما تعمل الجمل القصيرة جيدًا ، ولكن إذا كانت المدخلات طويلة جدًا ، يفقد النموذج التركيز ويتوقف عن تقديم تنبؤات معقولة. هناك سببان رئيسيان لهذا:
- تم تدريب النموذج بإجبار المعلم على تغذية الرمز الصحيح في كل خطوة ، بغض النظر عن تنبؤات النموذج. يمكن جعل النموذج أكثر قوة إذا تم تغذية تنبؤاته الخاصة به في بعض الأحيان.
- يمكن للنموذج الوصول إلى مخرجاته السابقة فقط من خلال حالة RNN. في حالة تلف حالة RNN ، فلا توجد طريقة لاسترداد النموذج. المحولات حل هذه باستخدام الاهتمام الذاتي في وفك التشفير.
long_input_text = tf.constant([inp[-1]])
import textwrap
print('Expected output:\n', '\n'.join(textwrap.wrap(targ[-1])))
Expected output: If you want to sound like a native speaker, you must be willing to practice saying the same sentence over and over in the same way that banjo players practice the same phrase over and over until they can play it correctly and at the desired tempo.
result = translator.tf_translate(long_input_text)
i = 0
plot_attention(result['attention'][i], long_input_text[i], result['text'][i])
_ = plt.suptitle('This never works')
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app
يصدر
وبمجرد الانتهاء من نموذج كنت راضيا قد ترغب في تصديره باعتباره tf.saved_model للاستخدام خارج هذا البرنامج الثعبان الذي أنشأه.
منذ هذا النموذج هو فئة فرعية من tf.Module (من خلال keras.Model )، ويتم تصنيف جميع وظائف للتصدير في tf.function نموذج يجب تصدير نظيفة مع tf.saved_model.save :
والآن بعد أن تم إرجاع الوظيفة التي يمكن تصديرها باستخدام saved_model.save :
tf.saved_model.save(translator, 'translator',
signatures={'serving_default': translator.tf_translate})
2021-12-04 12:27:54.310890: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Found untraced functions such as encoder_2_layer_call_fn, encoder_2_layer_call_and_return_conditional_losses, decoder_2_layer_call_fn, decoder_2_layer_call_and_return_conditional_losses, embedding_4_layer_call_fn while saving (showing 5 of 60). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: translator/assets INFO:tensorflow:Assets written to: translator/assets
reloaded = tf.saved_model.load('translator')
result = reloaded.tf_translate(three_input_text)
%%time
result = reloaded.tf_translate(three_input_text)
for tr in result['text']:
print(tr.numpy().decode())
print()
this is my life . are you still at home ? find out about to find out . CPU times: user 42.8 ms, sys: 7.69 ms, total: 50.5 ms Wall time: 20 ms
الخطوات التالية
- تحميل مجموعة بيانات مختلفة لتجربة مع ترجمات، على سبيل المثال، الإنجليزية إلى الألمانية أو الإنجليزية إلى الفرنسية.
- جرب التدريب على مجموعة بيانات أكبر ، أو استخدم المزيد من العصور.
- حاول محول البرنامج التعليمي الذي ينفذ مهمة الترجمة مماثلة ولكن يستخدم طبقات محول بدلا من RNNs. يستخدم هذا الإصدار أيضا
text.BertTokenizerلتنفيذ wordpiece tokenization. - إلقاء نظرة على tensorflow_addons.seq2seq لتنفيذ هذا النوع من تسلسل تسلسل نموذج. و
tfa.seq2seqتتضمن حزمة وظائف مستوى أعلى مثلseq2seq.BeamSearchDecoder.