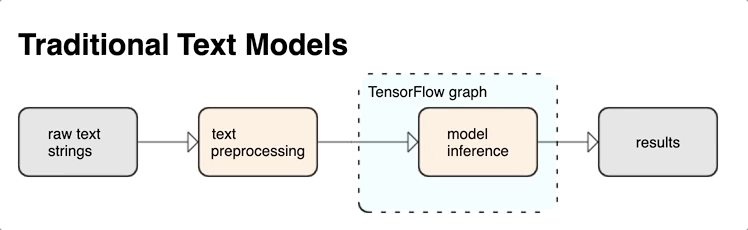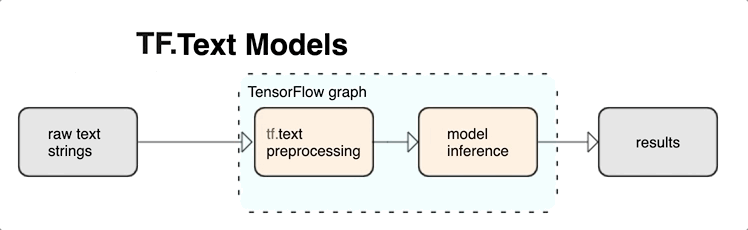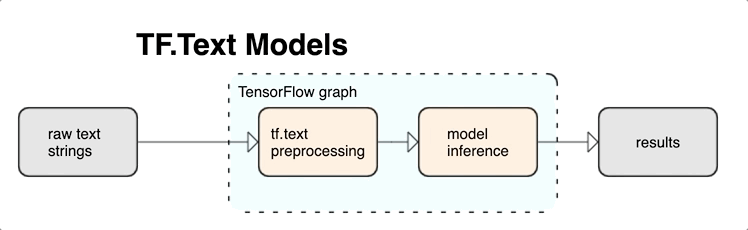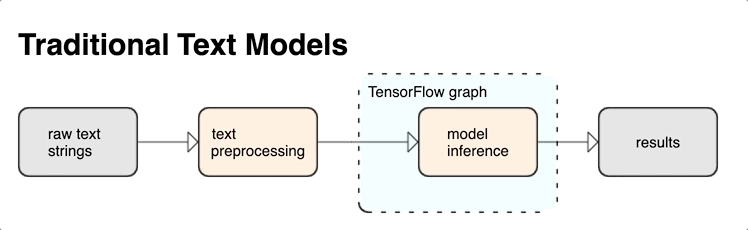
أدوات معالجة النصوص لـ TensorFlow
يوفر TensorFlow مكتبتين لمعالجة النص واللغة الطبيعية: KerasNLP و TensorFlow Text. KerasNLP هي مكتبة عالية المستوى لمعالجة اللغة الطبيعية (NLP) تتضمن نماذج حديثة قائمة على المحولات بالإضافة إلى أدوات الترميز ذات المستوى الأدنى. إنه الحل الموصى به لمعظم حالات استخدام البرمجة اللغوية العصبية. استنادًا إلى TensorFlow Text ، يقوم KerasNLP بتلخيص عمليات معالجة النصوص منخفضة المستوى في واجهة برمجة تطبيقات مصممة لسهولة الاستخدام. ولكن إذا كنت تفضل عدم العمل مع Keras API ، أو كنت بحاجة إلى الوصول إلى عمليات معالجة النصوص ذات المستوى الأدنى ، فيمكنك استخدام TensorFlow Text مباشرة.
KerasNLP
import keras_nlp import tensorflow_datasets as tfds imdb_train, imdb_test = tfds.load( "imdb_reviews", split=["train", "test"], as_supervised=True, batch_size=16, ) # Load a BERT model. classifier = keras_nlp.models.BertClassifier.from_preset("bert_base_en_uncased") # Fine-tune on IMDb movie reviews. classifier.fit(imdb_train, validation_data=imdb_test) # Predict two new examples. classifier.predict(["What an amazing movie!", "A total waste of my time."])
أسهل طريقة لبدء معالجة النص في TensorFlow هي استخدام KerasNLP. KerasNLP هي مكتبة لمعالجة اللغة الطبيعية تدعم سير العمل المبني من المكونات المعيارية التي تحتوي على أحدث الأوزان والبنيات المعدة مسبقًا. يمكنك استخدام مكونات KerasNLP مع تكوينها الجاهز. إذا كنت بحاجة إلى مزيد من التحكم ، فيمكنك تخصيص المكونات بسهولة. يؤكد KerasNLP على الحساب في الرسم البياني لجميع تدفقات العمل بحيث يمكنك توقع إنتاج سهل باستخدام نظام TensorFlow البيئي.
KerasNLP هو امتداد لـ Keras API الأساسية ، وجميع وحدات KerasNLP عالية المستوى عبارة عن طبقات أو نماذج. إذا كنت معتادًا على Keras ، فأنت تفهم بالفعل معظم KerasNLP.
لمعرفة المزيد ، راجع KerasNLP .
نص TensorFlow
import tensorflow as tf import tensorflow_text as tf_text def preprocess(vocab_lookup_table, example_text): # Normalize text tf_text.normalize_utf8(example_text) # Tokenize into words word_tokenizer = tf_text.WhitespaceTokenizer() tokens = word_tokenizer.tokenize(example_text) # Tokenize into subwords subword_tokenizer = tf_text.WordpieceTokenizer( vocab_lookup_table, token_out_type=tf.int64) subtokens = subword_tokenizer.tokenize(tokens).merge_dims(1, -1) # Apply padding padded_inputs = tf_text.pad_model_inputs(subtokens, max_seq_length=16) return padded_inputs
يوفر KerasNLP وحدات معالجة نصية عالية المستوى متوفرة كطبقات أو نماذج. إذا كنت بحاجة إلى الوصول إلى أدوات ذات مستوى أدنى ، فيمكنك استخدام TensorFlow Text. يوفر لك TensorFlow Text مجموعة غنية من العمليات والمكتبات لمساعدتك في العمل مع الإدخال في نموذج نصي مثل سلاسل النص الخام أو المستندات. يمكن لهذه المكتبات إجراء المعالجة المسبقة التي تتطلبها النماذج النصية بانتظام ، وتشمل ميزات أخرى مفيدة لنمذجة التسلسل.
يمكنك استخراج ميزات نصية وتركيبية قوية من داخل الرسم البياني TensorFlow كمدخل إلى شبكتك العصبية.
يوفر تكامل المعالجة المسبقة مع الرسم البياني TensorFlow الفوائد التالية:
- يسهل مجموعة أدوات كبيرة للعمل مع النص
- يسمح بالتكامل مع مجموعة كبيرة من أدوات TensorFlow لدعم المشاريع من تحديد المشكلة من خلال التدريب والتقييم والبدء
- يقلل من التعقيد في وقت التقديم ويمنع انحراف تقديم التدريب
بالإضافة إلى ما سبق ، لا داعي للقلق بشأن اختلاف الرمز المميز في التدريب عن الرمز المميز في الاستدلال ، أو إدارة البرامج النصية للمعالجة المسبقة.