
| | |  عرض على جيثب عرض على جيثب | | |
يحتوي هذا البرنامج التعليمي على رمز كامل لضبط BERT لإجراء تحليل المشاعر على مجموعة بيانات لمراجعات أفلام IMDB ذات النص العادي. بالإضافة إلى تدريب النموذج ، سوف تتعلم كيفية المعالجة المسبقة للنص بتنسيق مناسب.
في هذا دفتر الملاحظات ، سوف:
- قم بتحميل مجموعة بيانات IMDB
- قم بتحميل نموذج BERT من TensorFlow Hub
- قم ببناء النموذج الخاص بك عن طريق الجمع بين BERT والمصنف
- قم بتدريب نموذجك الخاص ، وقم بضبط BERT كجزء من ذلك
- احفظ النموذج الخاص بك واستخدمه لتصنيف الجمل
إذا كنت جديدا على العمل مع مجموعة البيانات IMDB، يرجى الاطلاع على تصنيف النص الأساسي لمزيد من التفاصيل.
حول بيرت
بيرت كانت وغيرها من البنى محول التشفير ناجحة بعنف على مجموعة متنوعة من المهام في البرمجة اللغوية العصبية (معالجة اللغة الطبيعية). يحسب تمثيلات الفضاء المتجه للغة الطبيعية المناسبة للاستخدام في نماذج التعلم العميق. تستخدم عائلة نماذج BERT بنية تشفير Transformer لمعالجة كل رمز مميز لنص الإدخال في السياق الكامل لجميع الرموز قبل وبعد ، ومن هنا جاء الاسم: تمثيلات التشفير ثنائي الاتجاه من المحولات.
عادةً ما يتم تدريب نماذج BERT مسبقًا على مجموعة كبيرة من النصوص ، ثم يتم ضبطها لمهام محددة.
يثبت
# A dependency of the preprocessing for BERT inputspip install -q -U tensorflow-text
سوف تستخدم محسن AdamW من tensorflow / نماذج .
pip install -q tf-models-official
import os
import shutil
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_text as text
from official.nlp import optimization # to create AdamW optimizer
import matplotlib.pyplot as plt
tf.get_logger().setLevel('ERROR')
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py:119: PkgResourcesDeprecationWarning: 0.18ubuntu0.18.04.1 is an invalid version and will not be supported in a future release PkgResourcesDeprecationWarning,
تحليل المشاعر
هذا الكمبيوتر الدفتري القطارات نموذج تحليل المشاعر إلى ويستعرض الفيلم تصنيف بأنها إيجابية أو سلبية، استنادا إلى نص المراجعة.
عليك استخدام واسع الفيلم الاستعراضي الإدراجات الذي يحتوي على النص من 50000 يستعرض الفيلم من قاعدة بيانات الأفلام على الإنترنت .
قم بتنزيل مجموعة بيانات IMDB
لنقم بتنزيل مجموعة البيانات واستخراجها ، ثم نستكشف بنية الدليل.
url = 'https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz'
dataset = tf.keras.utils.get_file('aclImdb_v1.tar.gz', url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
train_dir = os.path.join(dataset_dir, 'train')
# remove unused folders to make it easier to load the data
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 7s 0us/step 84140032/84125825 [==============================] - 7s 0us/step
بعد ذلك، سوف تستخدم text_dataset_from_directory أداة لإنشاء وصفت tf.data.Dataset .
تم بالفعل تقسيم مجموعة بيانات IMDB إلى تدريب واختبار ، لكنها تفتقر إلى مجموعة التحقق من الصحة. دعونا خلق مجموعة المصادقة باستخدام 80:20 انقسام بيانات التدريب باستخدام validation_split حجة أدناه.
AUTOTUNE = tf.data.AUTOTUNE
batch_size = 32
seed = 42
raw_train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
class_names = raw_train_ds.class_names
train_ds = raw_train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
Found 25000 files belonging to 2 classes. Using 20000 files for training. Found 25000 files belonging to 2 classes. Using 5000 files for validation. Found 25000 files belonging to 2 classes.
دعونا نلقي نظرة على بعض المراجعات.
for text_batch, label_batch in train_ds.take(1):
for i in range(3):
print(f'Review: {text_batch.numpy()[i]}')
label = label_batch.numpy()[i]
print(f'Label : {label} ({class_names[label]})')
Review: b'"Pandemonium" is a horror movie spoof that comes off more stupid than funny. Believe me when I tell you, I love comedies. Especially comedy spoofs. "Airplane", "The Naked Gun" trilogy, "Blazing Saddles", "High Anxiety", and "Spaceballs" are some of my favorite comedies that spoof a particular genre. "Pandemonium" is not up there with those films. Most of the scenes in this movie had me sitting there in stunned silence because the movie wasn\'t all that funny. There are a few laughs in the film, but when you watch a comedy, you expect to laugh a lot more than a few times and that\'s all this film has going for it. Geez, "Scream" had more laughs than this film and that was more of a horror film. How bizarre is that?<br /><br />*1/2 (out of four)' Label : 0 (neg) Review: b"David Mamet is a very interesting and a very un-equal director. His first movie 'House of Games' was the one I liked best, and it set a series of films with characters whose perspective of life changes as they get into complicated situations, and so does the perspective of the viewer.<br /><br />So is 'Homicide' which from the title tries to set the mind of the viewer to the usual crime drama. The principal characters are two cops, one Jewish and one Irish who deal with a racially charged area. The murder of an old Jewish shop owner who proves to be an ancient veteran of the Israeli Independence war triggers the Jewish identity in the mind and heart of the Jewish detective.<br /><br />This is were the flaws of the film are the more obvious. The process of awakening is theatrical and hard to believe, the group of Jewish militants is operatic, and the way the detective eventually walks to the final violent confrontation is pathetic. The end of the film itself is Mamet-like smart, but disappoints from a human emotional perspective.<br /><br />Joe Mantegna and William Macy give strong performances, but the flaws of the story are too evident to be easily compensated." Label : 0 (neg) Review: b'Great documentary about the lives of NY firefighters during the worst terrorist attack of all time.. That reason alone is why this should be a must see collectors item.. What shocked me was not only the attacks, but the"High Fat Diet" and physical appearance of some of these firefighters. I think a lot of Doctors would agree with me that,in the physical shape they were in, some of these firefighters would NOT of made it to the 79th floor carrying over 60 lbs of gear. Having said that i now have a greater respect for firefighters and i realize becoming a firefighter is a life altering job. The French have a history of making great documentary\'s and that is what this is, a Great Documentary.....' Label : 1 (pos) 2021-12-01 12:17:32.795514: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
نماذج التحميل من TensorFlow Hub
هنا يمكنك اختيار طراز BERT الذي ستقوم بتحميله من TensorFlow Hub وضبطه. هناك العديد من طرز BERT المتاحة.
- بيرت-قاعدة ، Uncased و سبع نماذج مع الأوزان تدريب صدر من قبل المؤلفين بيرت الأصلية.
- BERTs صغيرة لها نفس الهيكل العام ولكن أقل و / أو كتل المحولات الصغيرة، والتي تتيح لك استكشاف المفاضلات بين السرعة والحجم والجودة.
- ALBERT : أربعة أحجام مختلفة من "A ايت بيرت" الذي يقلل من حجم نموذج (ولكن ليس وقت حساب) من خلال تبادل المعلمات بين الطبقات.
- بيرت الخبراء : ثمانية نماذج جميعا العمارة بيرت قاعدة ولكن العرض الاختيار بين مختلف المجالات ما قبل التدريب، وزيادة مواءمة بمهمة الهدف.
- الكترا لديه نفس العمارة كما بيرت (في ثلاثة أحجام مختلفة)، ولكن يحصل قبل المدربين كما الممي في انشاء يشبه الخصومة شبكة المولدة (GAN).
- بيرت مع الحديث-رؤساء الاهتمام وعن طريق بوابة الدنمركي [ قاعدة ، كبيرة ] لديه اثنين من التحسينات لجوهر العمارة محول.
يحتوي توثيق النموذج على TensorFlow Hub على مزيد من التفاصيل والمراجع إلى الأدبيات البحثية. اتبع الروابط أعلاه، أو انقر على tfhub.dev URL المطبوعة بعد إعدام خلية المقبل.
الاقتراح هو أن تبدأ بـ Small BERT (مع عدد أقل من المعلمات) لأنها أسرع في ضبطها. إذا كنت تحب نموذجًا صغيرًا ولكن بدقة أعلى ، فقد يكون ALBERT هو خيارك التالي. إذا كنت تريد دقة أفضل ، فاختر أحد أحجام BERT الكلاسيكية أو تحسيناتها الحديثة مثل Electra أو Talking Heads أو BERT Expert.
وبصرف النظر عن النماذج المتاحة أدناه، هناك إصدارات متعددة من النماذج التي هي أكبر ويمكن أن تسفر عن دقة أفضل، ولكنها أكبر من أن يكون على GPU واحد صقلها. سوف تكون قادرة على القيام بذلك على المهام الغراء حل باستخدام بيرت على colab TPU .
سترى في الكود أدناه أن تبديل عنوان URL الخاص بـ tfhub.dev يكفي لتجربة أي من هذه النماذج ، لأن جميع الاختلافات بينها مغلفة في SavedModels من TF Hub.
اختر نموذج BERT لضبطه
bert_model_name = 'small_bert/bert_en_uncased_L-4_H-512_A-8'
map_name_to_handle = {
'bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/3',
'bert_en_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_cased_L-12_H-768_A-12/3',
'bert_multi_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_multi_cased_L-12_H-768_A-12/3',
'small_bert/bert_en_uncased_L-2_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-128_A-2/1',
'small_bert/bert_en_uncased_L-2_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-256_A-4/1',
'small_bert/bert_en_uncased_L-2_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-512_A-8/1',
'small_bert/bert_en_uncased_L-2_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-768_A-12/1',
'small_bert/bert_en_uncased_L-4_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-128_A-2/1',
'small_bert/bert_en_uncased_L-4_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-256_A-4/1',
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1',
'small_bert/bert_en_uncased_L-4_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-768_A-12/1',
'small_bert/bert_en_uncased_L-6_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-128_A-2/1',
'small_bert/bert_en_uncased_L-6_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-256_A-4/1',
'small_bert/bert_en_uncased_L-6_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-512_A-8/1',
'small_bert/bert_en_uncased_L-6_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-768_A-12/1',
'small_bert/bert_en_uncased_L-8_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-128_A-2/1',
'small_bert/bert_en_uncased_L-8_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-256_A-4/1',
'small_bert/bert_en_uncased_L-8_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-512_A-8/1',
'small_bert/bert_en_uncased_L-8_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-768_A-12/1',
'small_bert/bert_en_uncased_L-10_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-128_A-2/1',
'small_bert/bert_en_uncased_L-10_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-256_A-4/1',
'small_bert/bert_en_uncased_L-10_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-512_A-8/1',
'small_bert/bert_en_uncased_L-10_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-768_A-12/1',
'small_bert/bert_en_uncased_L-12_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-128_A-2/1',
'small_bert/bert_en_uncased_L-12_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-256_A-4/1',
'small_bert/bert_en_uncased_L-12_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-512_A-8/1',
'small_bert/bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-768_A-12/1',
'albert_en_base':
'https://tfhub.dev/tensorflow/albert_en_base/2',
'electra_small':
'https://tfhub.dev/google/electra_small/2',
'electra_base':
'https://tfhub.dev/google/electra_base/2',
'experts_pubmed':
'https://tfhub.dev/google/experts/bert/pubmed/2',
'experts_wiki_books':
'https://tfhub.dev/google/experts/bert/wiki_books/2',
'talking-heads_base':
'https://tfhub.dev/tensorflow/talkheads_ggelu_bert_en_base/1',
}
map_model_to_preprocess = {
'bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'bert_en_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_cased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'bert_multi_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_multi_cased_preprocess/3',
'albert_en_base':
'https://tfhub.dev/tensorflow/albert_en_preprocess/3',
'electra_small':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'electra_base':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'experts_pubmed':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'experts_wiki_books':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'talking-heads_base':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
}
tfhub_handle_encoder = map_name_to_handle[bert_model_name]
tfhub_handle_preprocess = map_model_to_preprocess[bert_model_name]
print(f'BERT model selected : {tfhub_handle_encoder}')
print(f'Preprocess model auto-selected: {tfhub_handle_preprocess}')
BERT model selected : https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Preprocess model auto-selected: https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3
نموذج المعالجة المسبقة
يجب تحويل مدخلات النص إلى معرفات رمزية رقمية وترتيبها في العديد من Tensors قبل إدخالها في BERT. يوفر TensorFlow Hub نموذج معالجة مسبقة مطابقًا لكل من نماذج BERT التي تمت مناقشتها أعلاه ، والتي تنفذ هذا التحول باستخدام TF ops من مكتبة TF.text. ليس من الضروري تشغيل كود Python النقي خارج نموذج TensorFlow الخاص بك إلى نص المعالجة المسبقة.
يجب أن يكون نموذج المعالجة المسبقة هو النموذج المشار إليه في وثائق نموذج BERT ، والذي يمكنك قراءته على عنوان URL المطبوع أعلاه. بالنسبة لنماذج BERT من القائمة المنسدلة أعلاه ، يتم تحديد نموذج المعالجة المسبقة تلقائيًا.
bert_preprocess_model = hub.KerasLayer(tfhub_handle_preprocess)
لنجرب نموذج المعالجة المسبقة في بعض النصوص ونرى الإخراج:
text_test = ['this is such an amazing movie!']
text_preprocessed = bert_preprocess_model(text_test)
print(f'Keys : {list(text_preprocessed.keys())}')
print(f'Shape : {text_preprocessed["input_word_ids"].shape}')
print(f'Word Ids : {text_preprocessed["input_word_ids"][0, :12]}')
print(f'Input Mask : {text_preprocessed["input_mask"][0, :12]}')
print(f'Type Ids : {text_preprocessed["input_type_ids"][0, :12]}')
Keys : ['input_word_ids', 'input_mask', 'input_type_ids'] Shape : (1, 128) Word Ids : [ 101 2023 2003 2107 2019 6429 3185 999 102 0 0 0] Input Mask : [1 1 1 1 1 1 1 1 1 0 0 0] Type Ids : [0 0 0 0 0 0 0 0 0 0 0 0]
كما ترون، الآن لديك 3 المخرجات من تجهيزها أن نموذج بيرت سوف تستخدم ( input_words_id ، input_mask و input_type_ids ).
بعض النقاط المهمة الأخرى:
- يتم قطع الإدخال إلى 128 رمزًا مميزًا. يمكن تخصيص عدد من الرموز، ويمكنك ان ترى المزيد من التفاصيل حول حل المهام الغراء باستخدام بيرت على colab TPU .
- و
input_type_idsيكون لها سوى قيمة واحدة (0) لأن هذا هو إدخال جملة واحدة. لإدخال جملة متعددة ، سيكون لها رقم واحد لكل إدخال.
نظرًا لأن هذا المعالج النصي هو نموذج TensorFlow ، فيمكن تضمينه في النموذج الخاص بك مباشرةً.
استخدام نموذج بيرت
قبل وضع BERT في النموذج الخاص بك ، دعنا نلقي نظرة على مخرجاته. سوف تقوم بتحميله من TF Hub وترى القيم التي تم إرجاعها.
bert_model = hub.KerasLayer(tfhub_handle_encoder)
bert_results = bert_model(text_preprocessed)
print(f'Loaded BERT: {tfhub_handle_encoder}')
print(f'Pooled Outputs Shape:{bert_results["pooled_output"].shape}')
print(f'Pooled Outputs Values:{bert_results["pooled_output"][0, :12]}')
print(f'Sequence Outputs Shape:{bert_results["sequence_output"].shape}')
print(f'Sequence Outputs Values:{bert_results["sequence_output"][0, :12]}')
Loaded BERT: https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Pooled Outputs Shape:(1, 512) Pooled Outputs Values:[ 0.76262873 0.99280983 -0.1861186 0.36673835 0.15233682 0.65504444 0.9681154 -0.9486272 0.00216158 -0.9877732 0.0684272 -0.9763061 ] Sequence Outputs Shape:(1, 128, 512) Sequence Outputs Values:[[-0.28946388 0.3432126 0.33231565 ... 0.21300787 0.7102078 -0.05771166] [-0.28742015 0.31981024 -0.2301858 ... 0.58455074 -0.21329722 0.7269209 ] [-0.66157013 0.6887685 -0.87432927 ... 0.10877253 -0.26173282 0.47855264] ... [-0.2256118 -0.28925604 -0.07064401 ... 0.4756601 0.8327715 0.40025353] [-0.29824278 -0.27473143 -0.05450511 ... 0.48849759 1.0955356 0.18163344] [-0.44378197 0.00930723 0.07223766 ... 0.1729009 1.1833246 0.07897988]]
نماذج بيرت بإرجاع خريطة مع 3 مفاتيح هامة: pooled_output ، sequence_output ، encoder_outputs :
-
pooled_outputيمثل كل تسلسل المدخلات ككل. الشكل هو[batch_size, H]. يمكنك التفكير في هذا على أنه تضمين لمراجعة الفيلم بالكامل. -
sequence_outputيمثل كل المدخلات رمزية في هذا السياق. الشكل هو[batch_size, seq_length, H]. يمكنك التفكير في هذا على أنه تضمين سياقي لكل رمز مميز في مراجعة الفيلم. -
encoder_outputsهي التنشيط وسيطة منLكتل محول.outputs["encoder_outputs"][i]هو التنسور الشكل[batch_size, seq_length, 1024]مع مخرجات ط عشر كتلة محول، ل0 <= i < L. القيمة الأخيرة من قائمة تساويsequence_output.
لصقل كنت تسير على استخدام pooled_output مجموعة.
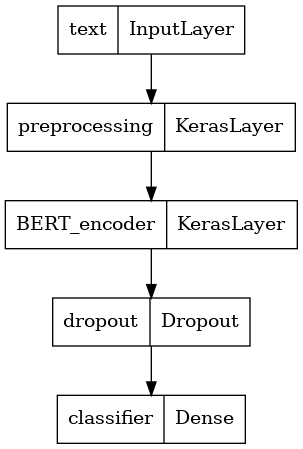
حدد نموذجك
ستنشئ نموذجًا بسيطًا للغاية مضبوطًا ، مع نموذج المعالجة المسبقة ، ونموذج BERT المحدد ، وطبقة واحدة كثيفة وطبقة Dropout.
def build_classifier_model():
text_input = tf.keras.layers.Input(shape=(), dtype=tf.string, name='text')
preprocessing_layer = hub.KerasLayer(tfhub_handle_preprocess, name='preprocessing')
encoder_inputs = preprocessing_layer(text_input)
encoder = hub.KerasLayer(tfhub_handle_encoder, trainable=True, name='BERT_encoder')
outputs = encoder(encoder_inputs)
net = outputs['pooled_output']
net = tf.keras.layers.Dropout(0.1)(net)
net = tf.keras.layers.Dense(1, activation=None, name='classifier')(net)
return tf.keras.Model(text_input, net)
دعنا نتحقق من أن النموذج يعمل مع إخراج نموذج المعالجة المسبقة.
classifier_model = build_classifier_model()
bert_raw_result = classifier_model(tf.constant(text_test))
print(tf.sigmoid(bert_raw_result))
tf.Tensor([[0.6749899]], shape=(1, 1), dtype=float32)
الناتج لا معنى له ، بالطبع ، لأن النموذج لم يتم تدريبه بعد.
دعنا نلقي نظرة على هيكل النموذج.
tf.keras.utils.plot_model(classifier_model)
تدريب نموذجي
لديك الآن كل القطع لتدريب نموذج ، بما في ذلك وحدة المعالجة المسبقة ، ومشفّر BERT ، والبيانات ، والمصنف.
فقدان وظيفة
منذ هذه مشكلة تصنيف الثنائية ونموذج إخراج احتمال (طبقة وحدة واحدة)، عليك استخدام losses.BinaryCrossentropy فقدان الوظيفة.
loss = tf.keras.losses.BinaryCrossentropy(from_logits=True)
metrics = tf.metrics.BinaryAccuracy()
محسن
من أجل الضبط الدقيق ، دعنا نستخدم نفس المُحسِّن الذي تم تدريب BERT عليه في الأصل: "اللحظات التكيفية" (آدم). هذه محسن يقلل من فقدان التنبؤ ولا تسوية من حيث الوزن وتسوس (لا تستخدم لحظات)، والذي يعرف أيضا باسم AdamW .
لمعدل التعلم ( init_lr )، سوف تستخدم نفس الجدول الزمني كما هو والتدريب ما قبل بيرت: تسوس خطية من معدل التعلم الأولي النظري، مسبوقة مع مرحلة الاحماء الخطية خلال أول 10٪ من تدريب خطوات ( num_warmup_steps ). تماشياً مع ورقة BERT ، يكون معدل التعلم الأولي أصغر للضبط الدقيق (أفضل من 5e-5 ، 3e-5 ، 2e-5).
epochs = 5
steps_per_epoch = tf.data.experimental.cardinality(train_ds).numpy()
num_train_steps = steps_per_epoch * epochs
num_warmup_steps = int(0.1*num_train_steps)
init_lr = 3e-5
optimizer = optimization.create_optimizer(init_lr=init_lr,
num_train_steps=num_train_steps,
num_warmup_steps=num_warmup_steps,
optimizer_type='adamw')
تحميل نموذج BERT والتدريب
باستخدام classifier_model قمت بإنشائها سابقا، يمكن ترجمة هذا النموذج مع الخسارة، متري ومحسن.
classifier_model.compile(optimizer=optimizer,
loss=loss,
metrics=metrics)
print(f'Training model with {tfhub_handle_encoder}')
history = classifier_model.fit(x=train_ds,
validation_data=val_ds,
epochs=epochs)
Training model with https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Epoch 1/5 625/625 [==============================] - 91s 138ms/step - loss: 0.4776 - binary_accuracy: 0.7513 - val_loss: 0.3791 - val_binary_accuracy: 0.8380 Epoch 2/5 625/625 [==============================] - 85s 136ms/step - loss: 0.3266 - binary_accuracy: 0.8547 - val_loss: 0.3659 - val_binary_accuracy: 0.8486 Epoch 3/5 625/625 [==============================] - 86s 138ms/step - loss: 0.2521 - binary_accuracy: 0.8928 - val_loss: 0.3975 - val_binary_accuracy: 0.8518 Epoch 4/5 625/625 [==============================] - 86s 137ms/step - loss: 0.1910 - binary_accuracy: 0.9269 - val_loss: 0.4180 - val_binary_accuracy: 0.8522 Epoch 5/5 625/625 [==============================] - 86s 137ms/step - loss: 0.1509 - binary_accuracy: 0.9433 - val_loss: 0.4641 - val_binary_accuracy: 0.8522
قم بتقييم النموذج
دعونا نرى كيف يعمل النموذج. سيتم إرجاع قيمتين. الخسارة (الرقم الذي يمثل الخطأ ، والقيم الأقل أفضل) ، والدقة.
loss, accuracy = classifier_model.evaluate(test_ds)
print(f'Loss: {loss}')
print(f'Accuracy: {accuracy}')
782/782 [==============================] - 61s 78ms/step - loss: 0.4495 - binary_accuracy: 0.8554 Loss: 0.4494614601135254 Accuracy: 0.8553599715232849
ارسم الدقة والخسارة بمرور الوقت
واستنادا إلى History كائن تم إرجاعه من قبل model.fit() . يمكنك رسم مخطط خسارة التدريب والتحقق من الصحة للمقارنة ، بالإضافة إلى دقة التدريب والتحقق من الصحة:
history_dict = history.history
print(history_dict.keys())
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
fig = plt.figure(figsize=(10, 6))
fig.tight_layout()
plt.subplot(2, 1, 1)
# r is for "solid red line"
plt.plot(epochs, loss, 'r', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
# plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(epochs, acc, 'r', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy']) <matplotlib.legend.Legend at 0x7fee7cdb4450>
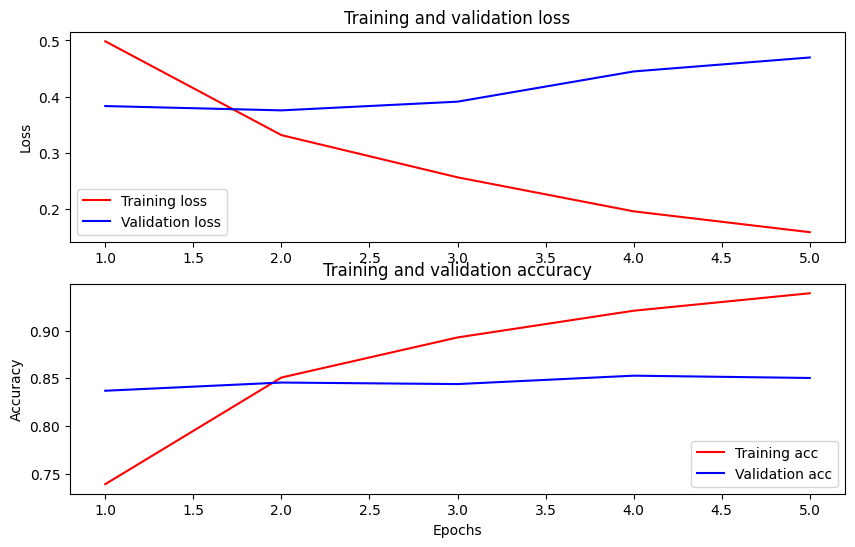
في هذه المؤامرة ، تمثل الخطوط الحمراء خسارة التدريب ودقته ، والخطوط الزرقاء هي فقدان التحقق من الصحة والدقة.
تصدير للاستدلال
أنت الآن تقوم فقط بحفظ نموذجك الدقيق لاستخدامه لاحقًا.
dataset_name = 'imdb'
saved_model_path = './{}_bert'.format(dataset_name.replace('/', '_'))
classifier_model.save(saved_model_path, include_optimizer=False)
2021-12-01 12:26:06.207608: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Found untraced functions such as restored_function_body, restored_function_body, restored_function_body, restored_function_body, restored_function_body while saving (showing 5 of 310). These functions will not be directly callable after loading.
دعنا نعيد تحميل النموذج ، حتى تتمكن من تجربته جنبًا إلى جنب مع النموذج الذي لا يزال في الذاكرة.
reloaded_model = tf.saved_model.load(saved_model_path)
هنا يمكنك اختبار النموذج الخاص بك على أي جملة تريدها ، فقط أضف إلى متغير الأمثلة أدناه.
def print_my_examples(inputs, results):
result_for_printing = \
[f'input: {inputs[i]:<30} : score: {results[i][0]:.6f}'
for i in range(len(inputs))]
print(*result_for_printing, sep='\n')
print()
examples = [
'this is such an amazing movie!', # this is the same sentence tried earlier
'The movie was great!',
'The movie was meh.',
'The movie was okish.',
'The movie was terrible...'
]
reloaded_results = tf.sigmoid(reloaded_model(tf.constant(examples)))
original_results = tf.sigmoid(classifier_model(tf.constant(examples)))
print('Results from the saved model:')
print_my_examples(examples, reloaded_results)
print('Results from the model in memory:')
print_my_examples(examples, original_results)
Results from the saved model: input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622 Results from the model in memory: input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622
إذا كنت ترغب في استخدام النموذج الخاص بك على TF التي تخدم ، وتذكر أنه سيدعو SavedModel من خلال واحدة من التوقيعات على اسمه. في Python ، يمكنك اختبارها على النحو التالي:
serving_results = reloaded_model \
.signatures['serving_default'](tf.constant(examples))
serving_results = tf.sigmoid(serving_results['classifier'])
print_my_examples(examples, serving_results)
input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622
الخطوات التالية
وكخطوة تالية، يمكنك محاولة حل المهام الغراء باستخدام بيرت على البرنامج التعليمي TPU ، الذي يمتد على TPU ويظهر لك كيفية العمل مع مدخلات متعددة.