
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
يوضح هذا البرنامج التعليمي تصنيف النص بدءًا من ملفات النص العادي المخزنة على القرص. ستقوم بتدريب مصنف ثنائي لأداء تحليل المشاعر على مجموعة بيانات IMDB. في نهاية دفتر الملاحظات ، هناك تمرين يمكنك تجربته ، حيث ستقوم بتدريب مصنف متعدد الفئات للتنبؤ بالعلامة الخاصة بسؤال البرمجة على Stack Overflow.
import matplotlib.pyplot as plt
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import losses
print(tf.__version__)
2.8.0-rc1
تحليل المشاعر
يقوم هذا الكمبيوتر الدفتري بتدريب نموذج تحليل المشاعر لتصنيف مراجعات الأفلام على أنها إيجابية أو سلبية ، بناءً على نص المراجعة. هذا مثال على تصنيف ثنائي - أو ثنائي - تصنيف ، وهو نوع مهم وقابل للتطبيق على نطاق واسع من مشاكل التعلم الآلي.
ستستخدم مجموعة بيانات استعراض الأفلام الكبيرة التي تحتوي على نص 50000 مراجعة للأفلام من قاعدة بيانات الأفلام على الإنترنت . يتم تقسيم هذه إلى 25000 مراجعة للتدريب و 25000 مراجعة للاختبار. مجموعات التدريب والاختبار متوازنة ، مما يعني أنها تحتوي على عدد متساوٍ من التقييمات الإيجابية والسلبية.
قم بتنزيل واستكشاف مجموعة بيانات IMDB
لنقم بتنزيل مجموعة البيانات واستخراجها ، ثم نستكشف بنية الدليل.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 6s 0us/step 84140032/84125825 [==============================] - 6s 0us/step
os.listdir(dataset_dir)
['test', 'README', 'imdbEr.txt', 'imdb.vocab', 'train']
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['neg', 'urls_neg.txt', 'unsup', 'unsupBow.feat', 'urls_unsup.txt', 'urls_pos.txt', 'labeledBow.feat', 'pos']
تحتوي aclImdb/train/pos و aclImdb/train/neg على العديد من الملفات النصية ، كل منها عبارة عن مراجعة لفيلم واحد. دعونا نلقي نظرة على واحد منهم.
sample_file = os.path.join(train_dir, 'pos/1181_9.txt')
with open(sample_file) as f:
print(f.read())
Rachel Griffiths writes and directs this award winning short film. A heartwarming story about coping with grief and cherishing the memory of those we've loved and lost. Although, only 15 minutes long, Griffiths manages to capture so much emotion and truth onto film in the short space of time. Bud Tingwell gives a touching performance as Will, a widower struggling to cope with his wife's death. Will is confronted by the harsh reality of loneliness and helplessness as he proceeds to take care of Ruth's pet cow, Tulip. The film displays the grief and responsibility one feels for those they have loved and lost. Good cinematography, great direction, and superbly acted. It will bring tears to all those who have lost a loved one, and survived.
قم بتحميل مجموعة البيانات
بعد ذلك ، ستقوم بتحميل البيانات من القرص وإعدادها بتنسيق مناسب للتدريب. للقيام بذلك ، سوف تستخدم الأداة المساعدة text_dataset_from_directory ، والتي تتوقع بنية الدليل على النحو التالي.
main_directory/
...class_a/
......a_text_1.txt
......a_text_2.txt
...class_b/
......b_text_1.txt
......b_text_2.txt
لإعداد مجموعة بيانات للتصنيف الثنائي ، ستحتاج إلى مجلدين على القرص ، يتوافقان مع class_a و class_b . ستكون هذه التقييمات الإيجابية والسلبية للأفلام ، والتي يمكن العثور عليها في aclImdb/train/pos و aclImdb/train/neg . نظرًا لأن مجموعة بيانات IMDB تحتوي على مجلدات إضافية ، فسوف تقوم بإزالتها قبل استخدام هذه الأداة المساعدة.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
بعد ذلك ، ستستخدم الأداة المساعدة text_dataset_from_directory لإنشاء ملف tf.data.Dataset . tf.data عبارة عن مجموعة قوية من الأدوات للعمل مع البيانات.
عند تشغيل تجربة التعلم الآلي ، من الأفضل تقسيم مجموعة البيانات إلى ثلاثة أقسام: التدريب والتحقق من الصحة والاختبار .
تم بالفعل تقسيم مجموعة بيانات IMDB إلى تدريب واختبار ، لكنها تفتقر إلى مجموعة التحقق من الصحة. لنقم بإنشاء مجموعة تحقق باستخدام تقسيم 80:20 لبيانات التدريب باستخدام وسيطة validation_split أدناه.
batch_size = 32
seed = 42
raw_train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training.
كما ترى أعلاه ، يوجد 25000 مثال في مجلد التدريب ، ستستخدم 80٪ (أو 20000) منها للتدريب. كما سترى بعد قليل ، يمكنك تدريب نموذج عن طريق تمرير مجموعة بيانات مباشرة إلى model.fit . إذا كنت جديدًا على tf.data ، فيمكنك أيضًا التكرار عبر مجموعة البيانات وطباعة بعض الأمثلة على النحو التالي.
for text_batch, label_batch in raw_train_ds.take(1):
for i in range(3):
print("Review", text_batch.numpy()[i])
print("Label", label_batch.numpy()[i])
Review b'"Pandemonium" is a horror movie spoof that comes off more stupid than funny. Believe me when I tell you, I love comedies. Especially comedy spoofs. "Airplane", "The Naked Gun" trilogy, "Blazing Saddles", "High Anxiety", and "Spaceballs" are some of my favorite comedies that spoof a particular genre. "Pandemonium" is not up there with those films. Most of the scenes in this movie had me sitting there in stunned silence because the movie wasn\'t all that funny. There are a few laughs in the film, but when you watch a comedy, you expect to laugh a lot more than a few times and that\'s all this film has going for it. Geez, "Scream" had more laughs than this film and that was more of a horror film. How bizarre is that?<br /><br />*1/2 (out of four)' Label 0 Review b"David Mamet is a very interesting and a very un-equal director. His first movie 'House of Games' was the one I liked best, and it set a series of films with characters whose perspective of life changes as they get into complicated situations, and so does the perspective of the viewer.<br /><br />So is 'Homicide' which from the title tries to set the mind of the viewer to the usual crime drama. The principal characters are two cops, one Jewish and one Irish who deal with a racially charged area. The murder of an old Jewish shop owner who proves to be an ancient veteran of the Israeli Independence war triggers the Jewish identity in the mind and heart of the Jewish detective.<br /><br />This is were the flaws of the film are the more obvious. The process of awakening is theatrical and hard to believe, the group of Jewish militants is operatic, and the way the detective eventually walks to the final violent confrontation is pathetic. The end of the film itself is Mamet-like smart, but disappoints from a human emotional perspective.<br /><br />Joe Mantegna and William Macy give strong performances, but the flaws of the story are too evident to be easily compensated." Label 0 Review b'Great documentary about the lives of NY firefighters during the worst terrorist attack of all time.. That reason alone is why this should be a must see collectors item.. What shocked me was not only the attacks, but the"High Fat Diet" and physical appearance of some of these firefighters. I think a lot of Doctors would agree with me that,in the physical shape they were in, some of these firefighters would NOT of made it to the 79th floor carrying over 60 lbs of gear. Having said that i now have a greater respect for firefighters and i realize becoming a firefighter is a life altering job. The French have a history of making great documentary\'s and that is what this is, a Great Documentary.....' Label 1
لاحظ أن المراجعات تحتوي على نص خام (مع علامات ترقيم وعلامات HTML عرضية مثل <br/> ). سوف تظهر كيفية التعامل مع هذه في القسم التالي.
التسميات هي 0 أو 1. لمعرفة أي منها يتوافق مع تقييمات الأفلام الإيجابية والسلبية ، يمكنك التحقق من خاصية class_names في مجموعة البيانات.
print("Label 0 corresponds to", raw_train_ds.class_names[0])
print("Label 1 corresponds to", raw_train_ds.class_names[1])
Label 0 corresponds to neg Label 1 corresponds to pos
بعد ذلك ، ستقوم بإنشاء مجموعة بيانات تحقق من الصحة والاختبار. ستستخدم المراجعات الخمسة آلاف المتبقية من مجموعة التدريب للتحقق من صحتها.
raw_val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
Found 25000 files belonging to 2 classes. Using 5000 files for validation.
raw_test_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
Found 25000 files belonging to 2 classes.
جهز مجموعة البيانات للتدريب
بعد ذلك ، ستقوم بتوحيد البيانات وترميزها وتوجيهها باستخدام طبقة tf.keras.layers.TextVectorization المفيدة.
يشير التوحيد القياسي إلى المعالجة المسبقة للنص ، عادةً لإزالة علامات الترقيم أو عناصر HTML لتبسيط مجموعة البيانات. يشير الترميز إلى تقسيم السلاسل إلى رموز (على سبيل المثال ، تقسيم جملة إلى كلمات فردية ، عن طريق تقسيمها على مسافة بيضاء). تشير Vectorization إلى تحويل الرموز المميزة إلى أرقام بحيث يمكن تغذيتها في شبكة عصبية. يمكن إنجاز كل هذه المهام باستخدام هذه الطبقة.
كما رأيت أعلاه ، تحتوي المراجعات على علامات HTML متنوعة مثل <br /> . لن تتم إزالة هذه العلامات بواسطة المعياري الافتراضي في طبقة TextVectorization (التي تحول النص إلى أحرف صغيرة وتقطع علامات الترقيم افتراضيًا ، ولكنها لا تجرد HTML). ستكتب وظيفة توحيد مخصصة لإزالة HTML.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation),
'')
بعد ذلك ، ستقوم بإنشاء طبقة TextVectorization . ستستخدم هذه الطبقة لتوحيد بياناتنا وترميزها وتوحيدها. يمكنك تعيين output_mode إلى int لإنشاء فهارس عدد صحيح فريد لكل رمز مميز.
لاحظ أنك تستخدم وظيفة التقسيم الافتراضية ، ووظيفة التقييس المخصصة التي حددتها أعلاه. ستحدد أيضًا بعض الثوابت للنموذج ، مثل أقصى sequence_length صريح ، والذي سيؤدي إلى قيام الطبقة بتبطين أو اقتطاع sequence_length لقيم طول التسلسل بالضبط.
max_features = 10000
sequence_length = 250
vectorize_layer = layers.TextVectorization(
standardize=custom_standardization,
max_tokens=max_features,
output_mode='int',
output_sequence_length=sequence_length)
بعد ذلك ، سوف تستدعي adapt ليناسب حالة طبقة المعالجة المسبقة لمجموعة البيانات. سيؤدي هذا إلى قيام النموذج ببناء فهرس من السلاسل إلى أعداد صحيحة.
# Make a text-only dataset (without labels), then call adapt
train_text = raw_train_ds.map(lambda x, y: x)
vectorize_layer.adapt(train_text)
لنقم بإنشاء دالة لمعرفة نتيجة استخدام هذه الطبقة في المعالجة المسبقة لبعض البيانات.
def vectorize_text(text, label):
text = tf.expand_dims(text, -1)
return vectorize_layer(text), label
# retrieve a batch (of 32 reviews and labels) from the dataset
text_batch, label_batch = next(iter(raw_train_ds))
first_review, first_label = text_batch[0], label_batch[0]
print("Review", first_review)
print("Label", raw_train_ds.class_names[first_label])
print("Vectorized review", vectorize_text(first_review, first_label))
Review tf.Tensor(b'Great movie - especially the music - Etta James - "At Last". This speaks volumes when you have finally found that special someone.', shape=(), dtype=string)
Label neg
Vectorized review (<tf.Tensor: shape=(1, 250), dtype=int64, numpy=
array([[ 86, 17, 260, 2, 222, 1, 571, 31, 229, 11, 2418,
1, 51, 22, 25, 404, 251, 12, 306, 282, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]])>, <tf.Tensor: shape=(), dtype=int32, numpy=0>)
كما ترى أعلاه ، تم استبدال كل رمز بعدد صحيح. يمكنك البحث عن الرمز (السلسلة) الذي يتوافق مع كل عدد صحيح من خلال استدعاء .get_vocabulary() على الطبقة.
print("1287 ---> ",vectorize_layer.get_vocabulary()[1287])
print(" 313 ---> ",vectorize_layer.get_vocabulary()[313])
print('Vocabulary size: {}'.format(len(vectorize_layer.get_vocabulary())))
1287 ---> silent 313 ---> night Vocabulary size: 10000
أنت جاهز تقريبًا لتدريب نموذجك. كخطوة نهائية للمعالجة المسبقة ، ستقوم بتطبيق طبقة TextVectorization التي قمت بإنشائها مسبقًا على مجموعة بيانات القطار والتحقق من الصحة والاختبار.
train_ds = raw_train_ds.map(vectorize_text)
val_ds = raw_val_ds.map(vectorize_text)
test_ds = raw_test_ds.map(vectorize_text)
تكوين مجموعة البيانات للأداء
هاتان طريقتان مهمتان يجب عليك استخدامهما عند تحميل البيانات للتأكد من أن الإدخال / الإخراج لا يصبح محظورًا.
.cache() يحتفظ بالبيانات في الذاكرة بعد تحميلها خارج القرص. سيضمن ذلك عدم تحول مجموعة البيانات إلى عنق زجاجة أثناء تدريب نموذجك. إذا كانت مجموعة البيانات الخاصة بك كبيرة جدًا بحيث لا يمكن وضعها في الذاكرة ، فيمكنك أيضًا استخدام هذه الطريقة لإنشاء ذاكرة تخزين مؤقت على القرص ذات أداء فعال ، والتي تعد أكثر كفاءة في القراءة من العديد من الملفات الصغيرة.
.prefetch() يتداخل مع المعالجة المسبقة للبيانات وتنفيذ النموذج أثناء التدريب.
يمكنك معرفة المزيد حول كلتا الطريقتين ، بالإضافة إلى كيفية تخزين البيانات مؤقتًا على القرص في دليل أداء البيانات .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
قم بإنشاء النموذج
حان الوقت لإنشاء شبكتك العصبية:
embedding_dim = 16
model = tf.keras.Sequential([
layers.Embedding(max_features + 1, embedding_dim),
layers.Dropout(0.2),
layers.GlobalAveragePooling1D(),
layers.Dropout(0.2),
layers.Dense(1)])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 16) 160016
dropout (Dropout) (None, None, 16) 0
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dropout_1 (Dropout) (None, 16) 0
dense (Dense) (None, 1) 17
=================================================================
Total params: 160,033
Trainable params: 160,033
Non-trainable params: 0
_________________________________________________________________
يتم تكديس الطبقات بالتسلسل لبناء المصنف:
- الطبقة الأولى هي طبقة
Embedding. تأخذ هذه الطبقة المراجعات المشفرة بعدد صحيح وتبحث عن متجه تضمين لكل فهرس كلمة. يتم تعلم هذه النواقل باعتبارها نموذج القطارات. تضيف المتجهات بعدًا إلى صفيف الإخراج. الأبعاد الناتجة هي:(batch, sequence, embedding). لمعرفة المزيد حول حفلات الزفاف ، راجع البرنامج التعليمي لكلمة التضمين . - بعد ذلك ، تقوم طبقة
GlobalAveragePooling1Dبإرجاع متجه إخراج بطول ثابت لكل مثال عن طريق حساب المتوسط على بُعد التسلسل. هذا يسمح للنموذج بالتعامل مع المدخلات ذات الطول المتغير ، بأبسط طريقة ممكنة. - يتم تمرير متجه الخرج بطول ثابت عبر طبقة متصلة بالكامل (
Dense) تحتوي على 16 وحدة مخفية. - الطبقة الأخيرة متصلة بكثافة مع عقدة خرج واحدة.
وظيفة الخسارة والمحسن
يحتاج النموذج إلى وظيفة خسارة ومحسن للتدريب. نظرًا لأن هذه مشكلة تصنيف ثنائي وأن النموذج ينتج احتمالية (طبقة أحادية الوحدة مع تنشيط السيني) ، فسوف تستخدم losses.BinaryCrossentropy .
الآن ، قم بتكوين النموذج لاستخدام مُحسِّن ووظيفة خسارة:
model.compile(loss=losses.BinaryCrossentropy(from_logits=True),
optimizer='adam',
metrics=tf.metrics.BinaryAccuracy(threshold=0.0))
تدريب النموذج
ستقوم بتدريب النموذج عن طريق تمرير كائن dataset إلى طريقة الملاءمة.
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs)
Epoch 1/10 625/625 [==============================] - 4s 4ms/step - loss: 0.6644 - binary_accuracy: 0.6894 - val_loss: 0.6159 - val_binary_accuracy: 0.7696 Epoch 2/10 625/625 [==============================] - 2s 4ms/step - loss: 0.5494 - binary_accuracy: 0.8020 - val_loss: 0.4993 - val_binary_accuracy: 0.8226 Epoch 3/10 625/625 [==============================] - 2s 3ms/step - loss: 0.4450 - binary_accuracy: 0.8447 - val_loss: 0.4205 - val_binary_accuracy: 0.8466 Epoch 4/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3778 - binary_accuracy: 0.8659 - val_loss: 0.3740 - val_binary_accuracy: 0.8618 Epoch 5/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3357 - binary_accuracy: 0.8785 - val_loss: 0.3451 - val_binary_accuracy: 0.8678 Epoch 6/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3055 - binary_accuracy: 0.8885 - val_loss: 0.3260 - val_binary_accuracy: 0.8700 Epoch 7/10 625/625 [==============================] - 2s 3ms/step - loss: 0.2817 - binary_accuracy: 0.8971 - val_loss: 0.3126 - val_binary_accuracy: 0.8730 Epoch 8/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2616 - binary_accuracy: 0.9034 - val_loss: 0.3037 - val_binary_accuracy: 0.8754 Epoch 9/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2458 - binary_accuracy: 0.9110 - val_loss: 0.2965 - val_binary_accuracy: 0.8788 Epoch 10/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2319 - binary_accuracy: 0.9158 - val_loss: 0.2920 - val_binary_accuracy: 0.8792
قم بتقييم النموذج
دعونا نرى كيف يعمل النموذج. سيتم إرجاع قيمتين. الخسارة (رقم يمثل خطأنا ، والقيم الأقل هي الأفضل) والدقة.
loss, accuracy = model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
782/782 [==============================] - 2s 2ms/step - loss: 0.3104 - binary_accuracy: 0.8735 Loss: 0.3104138672351837 Accuracy: 0.873520016670227
هذا النهج الساذج إلى حد ما يحقق دقة تبلغ حوالي 86٪.
أنشئ مخططًا للدقة والخسارة بمرور الوقت
model.fit() كائن History يحتوي على قاموس بكل ما حدث أثناء التدريب:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy'])
هناك أربعة إدخالات: واحد لكل مقياس يتم مراقبته أثناء التدريب والتحقق من الصحة. يمكنك استخدام هذه لتخطيط فقدان التدريب والتحقق من الصحة للمقارنة ، بالإضافة إلى دقة التدريب والتحقق من الصحة:
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
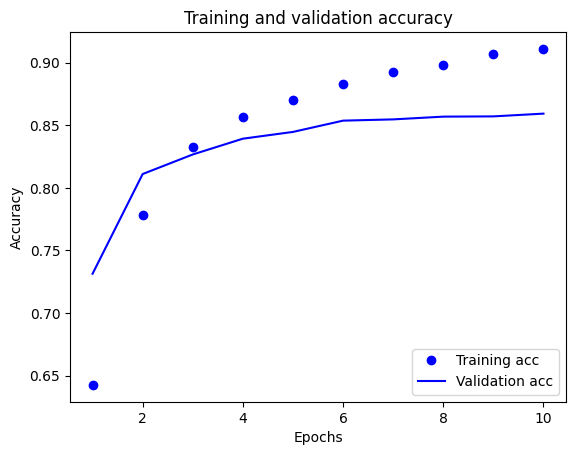
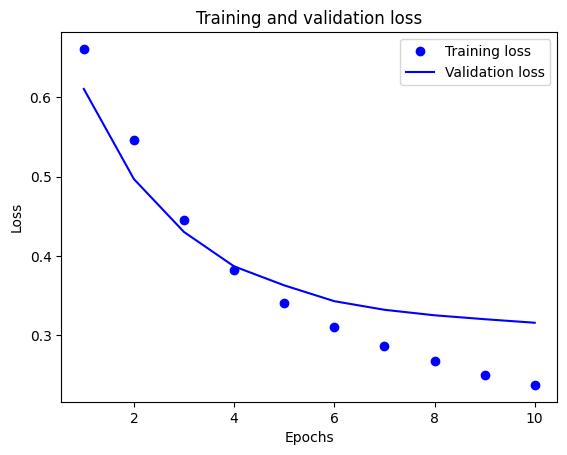
في هذه المؤامرة ، تمثل النقاط خسارة التدريب ودقته ، والخطوط الصلبة هي فقدان التحقق من الصحة والدقة.
لاحظ أن فقدان التدريب يتناقص مع كل فترة وتزداد دقة التدريب مع كل فترة. هذا متوقع عند استخدام تحسين النسب المتدرج - يجب أن يقلل الكمية المرغوبة في كل تكرار.
هذا ليس هو الحال بالنسبة لفقدان التحقق من الصحة والدقة - يبدو أنهم وصلوا إلى الذروة قبل دقة التدريب. هذا مثال على التخصيص الزائد: يعمل النموذج بشكل أفضل على بيانات التدريب مقارنةً بالبيانات التي لم يسبق لها مثيل من قبل. بعد هذه النقطة ، يقوم النموذج بإفراط في التحسين ويتعلم التمثيلات الخاصة ببيانات التدريب التي لا يتم تعميمها لاختبار البيانات.
بالنسبة لهذه الحالة بالذات ، يمكنك منع فرط التجهيز ببساطة عن طريق إيقاف التدريب عندما لا تزداد دقة التحقق من الصحة. طريقة واحدة للقيام بذلك هي استخدام tf.keras.callbacks.EarlyStopping callback.
تصدير النموذج
في الكود أعلاه ، قمت بتطبيق طبقة TextVectorization على مجموعة البيانات قبل تغذية النص إلى النموذج. إذا كنت ترغب في جعل النموذج الخاص بك قادرًا على معالجة السلاسل الأولية (على سبيل المثال ، لتبسيط نشره) ، يمكنك تضمين طبقة TextVectorization داخل النموذج الخاص بك. للقيام بذلك ، يمكنك إنشاء نموذج جديد باستخدام الأوزان التي قمت بتدريبها للتو.
export_model = tf.keras.Sequential([
vectorize_layer,
model,
layers.Activation('sigmoid')
])
export_model.compile(
loss=losses.BinaryCrossentropy(from_logits=False), optimizer="adam", metrics=['accuracy']
)
# Test it with `raw_test_ds`, which yields raw strings
loss, accuracy = export_model.evaluate(raw_test_ds)
print(accuracy)
782/782 [==============================] - 3s 4ms/step - loss: 0.3104 - accuracy: 0.8735 0.873520016670227
الاستدلال على البيانات الجديدة
للحصول على تنبؤات لأمثلة جديدة ، يمكنك ببساطة استدعاء model.predict() .
examples = [
"The movie was great!",
"The movie was okay.",
"The movie was terrible..."
]
export_model.predict(examples)
array([[0.60320234],
[0.4262717 ],
[0.34439093]], dtype=float32)
يتيح لك تضمين منطق المعالجة المسبقة للنص داخل نموذجك تصدير نموذج للإنتاج يبسط النشر ويقلل من احتمالية انحراف التدريب / الاختبار .
هناك اختلاف في الأداء يجب مراعاته عند اختيار مكان تطبيق طبقة TextVectorization. يتيح لك استخدامه خارج النموذج الخاص بك القيام بمعالجة غير متزامنة لوحدة المعالجة المركزية وتخزين بياناتك مؤقتًا عند التدريب على وحدة معالجة الرسومات. لذلك ، إذا كنت تقوم بتدريب النموذج الخاص بك على وحدة معالجة الرسومات ، فربما ترغب في استخدام هذا الخيار للحصول على أفضل أداء أثناء تطوير النموذج الخاص بك ، ثم قم بالتبديل إلى تضمين طبقة TextVectorization داخل النموذج الخاص بك عندما تكون جاهزًا للتحضير للنشر .
قم بزيارة هذا البرنامج التعليمي لمعرفة المزيد حول حفظ النماذج.
تمرين: تصنيف متعدد الفئات لأسئلة Stack Overflow
أظهر هذا البرنامج التعليمي كيفية تدريب مصنف ثنائي من البداية على مجموعة بيانات IMDB. كتمرين ، يمكنك تعديل هذا الكمبيوتر الدفتري لتدريب مصنف متعدد الفئات للتنبؤ بعلامة سؤال البرمجة على Stack Overflow .
تم إعداد مجموعة بيانات لتستخدمها تحتوي على عدة آلاف من أسئلة البرمجة (على سبيل المثال ، "كيف يمكنني فرز قاموس حسب القيمة في Python؟") تم نشرها في Stack Overflow. يتم تصنيف كل منها بعلامة واحدة بالضبط (إما Python أو CSharp أو JavaScript أو Java). مهمتك هي أن تأخذ سؤالاً كمدخلات ، وتوقع العلامة المناسبة ، في هذه الحالة ، Python.
تحتوي مجموعة البيانات التي ستعمل معها على عدة آلاف من الأسئلة المستخرجة من مجموعة بيانات Stack Overflow العامة الأكبر حجمًا على BigQuery ، والتي تحتوي على أكثر من 17 مليون مشاركة.
بعد تنزيل مجموعة البيانات ، ستجد أنها تحتوي على بنية دليل مشابهة لمجموعة بيانات IMDB التي عملت معها سابقًا:
train/
...python/
......0.txt
......1.txt
...javascript/
......0.txt
......1.txt
...csharp/
......0.txt
......1.txt
...java/
......0.txt
......1.txt
لإكمال هذا التمرين ، يجب عليك تعديل دفتر الملاحظات هذا للعمل مع مجموعة بيانات Stack Overflow عن طريق إجراء التعديلات التالية:
في الجزء العلوي من دفتر ملاحظاتك ، قم بتحديث الكود الذي يقوم بتنزيل مجموعة بيانات IMDB برمز لتنزيل مجموعة بيانات Stack Overflow التي تم إعدادها بالفعل. نظرًا لأن مجموعة بيانات Stack Overflow لها بنية دليل مماثلة ، فلن تحتاج إلى إجراء العديد من التعديلات.
قم بتعديل الطبقة الأخيرة من نموذجك إلى
Dense(4)، حيث توجد الآن أربع فئات إخراج.عند تجميع النموذج ، قم بتغيير الخسارة إلى
tf.keras.losses.SparseCategoricalCrossentropy. هذه هي دالة الخسارة الصحيحة لاستخدامها في مشكلة التصنيف متعدد الفئات ، عندما تكون تسميات كل فئة أعدادًا صحيحة (في هذه الحالة ، يمكن أن تكون 0 أو 1 أو 2 أو 3 ). بالإضافة إلى ذلك ، قم بتغيير المقاييس إلىmetrics=['accuracy']، نظرًا لأن هذه مشكلة تصنيف متعددة الفئات (لا يتم استخدامtf.metrics.BinaryAccuracyإلا للمصنفات الثنائية).عند تخطيط الدقة بمرور الوقت ، قم بتغيير
binary_accuracyوval_binary_accuracyإلىaccuracyوval_accuracy، على التوالي.بمجرد اكتمال هذه التغييرات ، ستتمكن من تدريب مصنف متعدد الفئات.
تعلم المزيد
قدم هذا البرنامج التعليمي تصنيف النص من البداية. لمعرفة المزيد حول سير عمل تصنيف النص بشكل عام ، راجع دليل تصنيف النص من Google Developers.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.