
Copyright 2021 Les auteurs TF-Agents.
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
introduction
Cet exemple montre comment former un RENFORCER agent sur l'environnement Cartpole en utilisant la bibliothèque TF-agents, similaire au tutoriel DQN .
Nous vous guiderons à travers tous les composants d'un pipeline d'apprentissage par renforcement (RL) pour la formation, l'évaluation et la collecte de données.
Installer
Si vous n'avez pas installé les dépendances suivantes, exécutez :
sudo apt-get updatesudo apt-get install -y xvfb ffmpeg freeglut3-devpip install 'imageio==2.4.0'pip install pyvirtualdisplaypip install tf-agents[reverb]pip install pyglet xvfbwrapper
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import numpy as np
import PIL.Image
import pyvirtualdisplay
import reverb
import tensorflow as tf
from tf_agents.agents.reinforce import reinforce_agent
from tf_agents.drivers import py_driver
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import py_tf_eager_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import trajectory
from tf_agents.utils import common
# Set up a virtual display for rendering OpenAI gym environments.
display = pyvirtualdisplay.Display(visible=0, size=(1400, 900)).start()
Hyperparamètres
env_name = "CartPole-v0" # @param {type:"string"}
num_iterations = 250 # @param {type:"integer"}
collect_episodes_per_iteration = 2 # @param {type:"integer"}
replay_buffer_capacity = 2000 # @param {type:"integer"}
fc_layer_params = (100,)
learning_rate = 1e-3 # @param {type:"number"}
log_interval = 25 # @param {type:"integer"}
num_eval_episodes = 10 # @param {type:"integer"}
eval_interval = 50 # @param {type:"integer"}
Environnement
Les environnements dans RL représentent la tâche ou le problème que nous essayons de résoudre. Environnements standard peuvent être facilement créés en TF-agents en utilisant des suites . Nous avons différentes suites pour les environnements de chargement provenant de sources telles que le Gym OpenAI, Atari, contrôle DM, etc., étant donné un nom d'environnement de chaîne.
Chargeons maintenant l'environnement CartPole à partir de la suite OpenAI Gym.
env = suite_gym.load(env_name)
Nous pouvons rendre cet environnement pour voir à quoi il ressemble. Un poteau à oscillation libre est attaché à un chariot. Le but est de déplacer le chariot à droite ou à gauche afin de garder le poteau pointé vers le haut.
env.reset()
PIL.Image.fromarray(env.render())
Le time_step = environment.step(action) déclaration prend des action dans l'environnement. Le TimeStep tuple retourné contient l' observation suivante et la récompense pour cette action de l'environnement. Le time_step_spec() et action_spec() méthodes dans l'environnement renvoient les spécifications (types, formes, hors limites) de la time_step et l' action respectivement.
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(4,), dtype=dtype('float32'), name='observation', minimum=[-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], maximum=[4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38])
Action Spec:
BoundedArraySpec(shape=(), dtype=dtype('int64'), name='action', minimum=0, maximum=1)
Ainsi, nous voyons que l'observation est un tableau de 4 flotteurs : la position et la vitesse du chariot, et la position angulaire et la vitesse du pôle. , La Depuis que deux actions sont possibles (déplacer vers la gauche ou à droite déplacer) action_spec est un scalaire où 0 signifie « aller à gauche » et 1 signifie « droit de déplacement. »
time_step = env.reset()
print('Time step:')
print(time_step)
action = np.array(1, dtype=np.int32)
next_time_step = env.step(action)
print('Next time step:')
print(next_time_step)
Time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02284177, -0.04785635, 0.04171623, 0.04942273], dtype=float32),
'reward': array(0., dtype=float32),
'step_type': array(0, dtype=int32)})
Next time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02188464, 0.14664337, 0.04270469, -0.22981201], dtype=float32),
'reward': array(1., dtype=float32),
'step_type': array(1, dtype=int32)})
Habituellement, nous créons deux environnements : un pour la formation et un pour l'évaluation. La plupart des environnements sont écrits en Python pur, mais ils peuvent être facilement convertis en utilisant le tensorflow TFPyEnvironment emballage. L'API de l' environnement d' origine utilise des tableaux numpy, le TFPyEnvironment convertit en / de Tensors pour vous d'interagir plus facilement avec les politiques et les agents tensorflow.
train_py_env = suite_gym.load(env_name)
eval_py_env = suite_gym.load(env_name)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
Agent
L'algorithme que nous utilisons pour résoudre un problème de RL est représenté comme un Agent . En plus de l'agent RENFORCER, TF-agents fournit des implémentations standard d'une variété d' Agents tels que DQN , GPDD , TD3 , PPO et SAC .
Pour créer un agent RENFORCER, nous avons d' abord besoin d' un Actor Network qui peut apprendre à prédire l'action donnée une observation de l'environnement.
Nous pouvons facilement créer un Actor Network en utilisant les spécifications des observations et des actions. Nous pouvons spécifier les couches du réseau qui, dans cet exemple, est le fc_layer_params argument défini sur un tuple de ints représentant les tailles de chaque couche cachée (voir la section hyperparam'etres ci - dessus).
actor_net = actor_distribution_network.ActorDistributionNetwork(
train_env.observation_spec(),
train_env.action_spec(),
fc_layer_params=fc_layer_params)
Nous avons également besoin d' un optimizer pour former le réseau que nous venons de créer, et une train_step_counter variable pour garder une trace de combien de fois le réseau a été mis à jour.
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
train_step_counter = tf.Variable(0)
tf_agent = reinforce_agent.ReinforceAgent(
train_env.time_step_spec(),
train_env.action_spec(),
actor_network=actor_net,
optimizer=optimizer,
normalize_returns=True,
train_step_counter=train_step_counter)
tf_agent.initialize()
Stratégies
Dans TF-agents, les politiques représentent la notion classique des politiques dans RL: étant donné un time_step produire une action ou d' une distribution sur actions. La principale méthode est policy_step = policy.action(time_step) où policy_step est un tuple nommé PolicyStep(action, state, info) . Le policy_step.action est une action à appliquer à l'environnement, l' state représente l'état des politiques stateful (RNN) et les info peuvent contenir des informations auxiliaires telles que les probabilités de journal des actions.
Les agents contiennent deux stratégies : la stratégie principale utilisée pour l'évaluation/le déploiement (agent.policy) et une autre stratégie utilisée pour la collecte de données (agent.collect_policy).
eval_policy = tf_agent.policy
collect_policy = tf_agent.collect_policy
Métriques et évaluation
La mesure la plus couramment utilisée pour évaluer une politique est le rendement moyen. Le retour est la somme des récompenses obtenues lors de l'exécution d'une politique dans un environnement pour un épisode, et nous en faisons généralement la moyenne sur quelques épisodes. Nous pouvons calculer la métrique de rendement moyen comme suit.
def compute_avg_return(environment, policy, num_episodes=10):
total_return = 0.0
for _ in range(num_episodes):
time_step = environment.reset()
episode_return = 0.0
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = environment.step(action_step.action)
episode_return += time_step.reward
total_return += episode_return
avg_return = total_return / num_episodes
return avg_return.numpy()[0]
# Please also see the metrics module for standard implementations of different
# metrics.
Tampon de relecture
Afin de garder une trace des données recueillies à partir de l'environnement, nous allons utiliser la réverbération , un système de lecture efficace, extensible et facile à utiliser par Deepmind. Il stocke les données d'expérience lorsque nous collectons des trajectoires et est consommé pendant l'entraînement.
Cette mémoire tampon de lecture est construite en utilisant les spécifications décrivant les tenseurs qui doivent être stockées, qui peuvent être obtenus à partir de l'agent en utilisant tf_agent.collect_data_spec .
table_name = 'uniform_table'
replay_buffer_signature = tensor_spec.from_spec(
tf_agent.collect_data_spec)
replay_buffer_signature = tensor_spec.add_outer_dim(
replay_buffer_signature)
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1),
signature=replay_buffer_signature)
reverb_server = reverb.Server([table])
replay_buffer = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
table_name=table_name,
sequence_length=None,
local_server=reverb_server)
rb_observer = reverb_utils.ReverbAddEpisodeObserver(
replay_buffer.py_client,
table_name,
replay_buffer_capacity
)
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpem6la471. [reverb/cc/platform/tfrecord_checkpointer.cc:385] Loading latest checkpoint from /tmp/tmpem6la471 [reverb/cc/platform/default/server.cc:71] Started replay server on port 19822
Pour la plupart des agents, l' collect_data_spec est un Trajectory nommé tuple contenant l'observation, l' action, récompense etc.
Collecte de données
Au fur et à mesure que RENFORCE apprend à partir d'épisodes entiers, nous définissons une fonction pour collecter un épisode en utilisant la politique de collecte de données donnée et enregistrer les données (observations, actions, récompenses, etc.) en tant que trajectoires dans le tampon de relecture. Ici, nous utilisons 'PyDriver' pour exécuter la boucle de collecte d'expérience. Vous pouvez en apprendre davantage sur le pilote TF Agents dans notre tutoriel pilotes .
def collect_episode(environment, policy, num_episodes):
driver = py_driver.PyDriver(
environment,
py_tf_eager_policy.PyTFEagerPolicy(
policy, use_tf_function=True),
[rb_observer],
max_episodes=num_episodes)
initial_time_step = environment.reset()
driver.run(initial_time_step)
Formation de l'agent
La boucle d'apprentissage consiste à la fois à collecter les données de l'environnement et à optimiser les réseaux de l'agent. En cours de route, nous évaluerons occasionnellement la politique de l'agent pour voir comment nous nous débrouillons.
Ce qui suit prendra environ 3 minutes pour s'exécuter.
try:
%%time
except:
pass
# (Optional) Optimize by wrapping some of the code in a graph using TF function.
tf_agent.train = common.function(tf_agent.train)
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
returns = [avg_return]
for _ in range(num_iterations):
# Collect a few episodes using collect_policy and save to the replay buffer.
collect_episode(
train_py_env, tf_agent.collect_policy, collect_episodes_per_iteration)
# Use data from the buffer and update the agent's network.
iterator = iter(replay_buffer.as_dataset(sample_batch_size=1))
trajectories, _ = next(iterator)
train_loss = tf_agent.train(experience=trajectories)
replay_buffer.clear()
step = tf_agent.train_step_counter.numpy()
if step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, train_loss.loss))
if step % eval_interval == 0:
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
print('step = {0}: Average Return = {1}'.format(step, avg_return))
returns.append(avg_return)
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 25: loss = 0.8549901247024536 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 50: loss = 1.0025296211242676 step = 50: Average Return = 23.200000762939453 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 75: loss = 1.1377763748168945 step = 100: loss = 1.318871021270752 step = 100: Average Return = 159.89999389648438 step = 125: loss = 1.5053682327270508 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 150: loss = 0.8051948547363281 step = 150: Average Return = 184.89999389648438 step = 175: loss = 0.6872963905334473 step = 200: loss = 2.7238712310791016 step = 200: Average Return = 186.8000030517578 step = 225: loss = 0.7495002746582031 step = 250: loss = -0.3333401679992676 step = 250: Average Return = 200.0
Visualisation
Parcelles
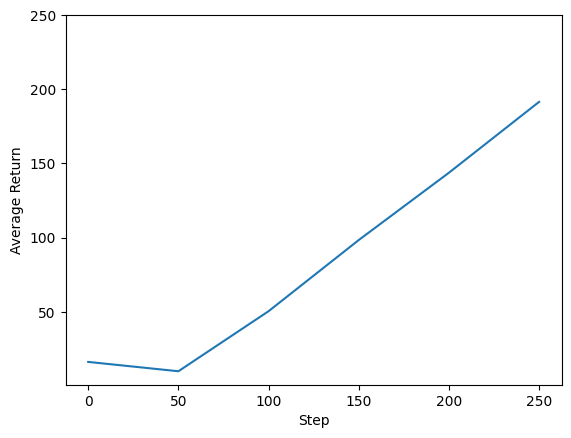
Nous pouvons tracer le retour par rapport aux étapes globales pour voir les performances de notre agent. Dans Cartpole-v0 , l'environnement donne une récompense de +1 pour chaque pas de temps les séjours pôles, et puisque le nombre maximum d'étapes est de 200, le retour maximum possible est de 200.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim(top=250)
(-0.2349997997283939, 250.0)
Vidéos
Il est utile de visualiser les performances d'un agent en restituant l'environnement à chaque étape. Avant de faire cela, créons d'abord une fonction pour intégrer des vidéos dans ce colab.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
Le code suivant visualise la politique de l'agent pour quelques épisodes :
num_episodes = 3
video_filename = 'imageio.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_py_env.render())
while not time_step.is_last():
action_step = tf_agent.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_py_env.render())
embed_mp4(video_filename)
WARNING:root:IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (400, 600) to (400, 608) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to None (risking incompatibility). You may also see a FFMPEG warning concerning speedloss due to data not being aligned. [swscaler @ 0x5604d224f3c0] Warning: data is not aligned! This can lead to a speed loss