
Copyright 2021 Os autores do TF-Agents.
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Introdução
Este exemplo mostra como treinar um Actor Crítico macia agente no Minitaur ambiente.
Se você já trabalhou com o DQN Colab este deve se sentir muito familiar. Mudanças notáveis incluem:
- Mudando o agente de DQN para SAC.
- Treinamento em Minitaur, que é um ambiente muito mais complexo do que CartPole. O ambiente do Minitaur visa treinar um robô quadrúpede para avançar.
- Usando a API TF-Agents Actor-Learner para aprendizado por reforço distribuído.
A API suporta a coleta de dados distribuída usando um buffer de reprodução de experiência e contêiner variável (servidor de parâmetros) e treinamento distribuído em vários dispositivos. A API foi projetada para ser muito simples e modular. Nós utilizamos Reverb tanto para tampão de reprodução e recipiente variável e TF DistributionStrategy API para treinamento distribuído em GPUs e TPU.
Se você não instalou as seguintes dependências, execute:
sudo apt-get updatesudo apt-get install -y xvfb ffmpegpip install 'imageio==2.4.0'pip install matplotlibpip install tf-agents[reverb]pip install pybullet
Configurar
Primeiro, importaremos as diferentes ferramentas de que precisamos.
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import os
import reverb
import tempfile
import PIL.Image
import tensorflow as tf
from tf_agents.agents.ddpg import critic_network
from tf_agents.agents.sac import sac_agent
from tf_agents.agents.sac import tanh_normal_projection_network
from tf_agents.environments import suite_pybullet
from tf_agents.metrics import py_metrics
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import greedy_policy
from tf_agents.policies import py_tf_eager_policy
from tf_agents.policies import random_py_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.train import actor
from tf_agents.train import learner
from tf_agents.train import triggers
from tf_agents.train.utils import spec_utils
from tf_agents.train.utils import strategy_utils
from tf_agents.train.utils import train_utils
tempdir = tempfile.gettempdir()
Hiperparâmetros
env_name = "MinitaurBulletEnv-v0" # @param {type:"string"}
# Use "num_iterations = 1e6" for better results (2 hrs)
# 1e5 is just so this doesn't take too long (1 hr)
num_iterations = 100000 # @param {type:"integer"}
initial_collect_steps = 10000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_capacity = 10000 # @param {type:"integer"}
batch_size = 256 # @param {type:"integer"}
critic_learning_rate = 3e-4 # @param {type:"number"}
actor_learning_rate = 3e-4 # @param {type:"number"}
alpha_learning_rate = 3e-4 # @param {type:"number"}
target_update_tau = 0.005 # @param {type:"number"}
target_update_period = 1 # @param {type:"number"}
gamma = 0.99 # @param {type:"number"}
reward_scale_factor = 1.0 # @param {type:"number"}
actor_fc_layer_params = (256, 256)
critic_joint_fc_layer_params = (256, 256)
log_interval = 5000 # @param {type:"integer"}
num_eval_episodes = 20 # @param {type:"integer"}
eval_interval = 10000 # @param {type:"integer"}
policy_save_interval = 5000 # @param {type:"integer"}
Ambiente
Os ambientes em RL representam a tarefa ou problema que estamos tentando resolver. Ambientes padrão podem ser facilmente criados em TF-agentes usando suites . Temos diferentes suites para carregar ambientes de fontes como o Ginásio OpenAI, Atari, Controle DM, etc., dado um nome de ambiente string.
Agora vamos carregar o ambiente Minituar do pacote Pybullet.
env = suite_pybullet.load(env_name)
env.reset()
PIL.Image.fromarray(env.render())
pybullet build time: Oct 11 2021 20:59:00
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/gym/spaces/box.py:74: UserWarning: WARN: Box bound precision lowered by casting to float32
"Box bound precision lowered by casting to {}".format(self.dtype)
current_dir=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_envs/bullet
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data

Nesse ambiente, o objetivo é que o agente treine uma política que irá controlar o robô Minitaur e fazê-lo avançar o mais rápido possível. Os episódios duram 1000 etapas e o retorno será a soma das recompensas ao longo do episódio.
Vamos olhar as informações que o ambiente oferece como uma observation que a política vai usar para gerar actions .
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(28,), dtype=dtype('float32'), name='observation', minimum=[ -3.1515927 -3.1515927 -3.1515927 -3.1515927 -3.1515927
-3.1515927 -3.1515927 -3.1515927 -167.72488 -167.72488
-167.72488 -167.72488 -167.72488 -167.72488 -167.72488
-167.72488 -5.71 -5.71 -5.71 -5.71
-5.71 -5.71 -5.71 -5.71 -1.01
-1.01 -1.01 -1.01 ], maximum=[ 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927
3.1515927 3.1515927 167.72488 167.72488 167.72488 167.72488
167.72488 167.72488 167.72488 167.72488 5.71 5.71
5.71 5.71 5.71 5.71 5.71 5.71
1.01 1.01 1.01 1.01 ])
Action Spec:
BoundedArraySpec(shape=(8,), dtype=dtype('float32'), name='action', minimum=-1.0, maximum=1.0)
A observação é bastante complexa. Recebemos 28 valores que representam os ângulos, velocidades e torques de todos os motores. Em contrapartida, o ambiente de espera 8 valores para as acções entre [-1, 1] . Estes são os ângulos de motor desejados.
Normalmente criamos dois ambientes: um para coleta de dados durante o treinamento e outro para avaliação. Os ambientes são escritos em Python puro e usam matrizes numpy, que a API Actor Learner consome diretamente.
collect_env = suite_pybullet.load(env_name)
eval_env = suite_pybullet.load(env_name)
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data
Estratégia de distribuição
Usamos a API DistributionStrategy para permitir a execução da computação das etapas do trem em vários dispositivos, como várias GPUs ou TPUs, usando paralelismo de dados. A etapa do trem:
- Recebe um lote de dados de treinamento
- Divide entre os dispositivos
- Calcula o passo à frente
- Agrega e calcula o MEAN da perda
- Calcula o retrocesso e realiza uma atualização da variável gradiente
Com a API TF-Agents Learner e a API DistributionStrategy, é muito fácil alternar entre a execução da etapa do trem em GPUs (usando MirroredStrategy) e TPUs (usando TPUStrategy) sem alterar nenhuma das lógicas de treinamento abaixo.
Habilitando a GPU
Se quiser tentar rodar em uma GPU, primeiro você precisará habilitar as GPUs para o notebook:
- Navegue até Editar → Configurações do Notebook
- Selecione GPU no menu suspenso do Hardware Accelerator
Escolha uma estratégia
Use strategy_utils para gerar uma estratégia. Sob o capô, passando o parâmetro:
-
use_gpu = Falseretornatf.distribute.get_strategy(), que usa CPU -
use_gpu = Trueretornostf.distribute.MirroredStrategy(), que utiliza todos os GPUs que são visíveis para TensorFlow em uma máquina
use_gpu = True
strategy = strategy_utils.get_strategy(tpu=False, use_gpu=use_gpu)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
Todas as variáveis e Agentes precisam ser criados sob strategy.scope() , como você verá a seguir.
Agente
Para criar um Agente SAC, primeiro precisamos criar as redes que ele treinará. O SAC é um agente ator-crítico, então precisaremos de duas redes.
O crítico nos dará estimativas de valor para Q(s,a) . Ou seja, ele receberá como entrada uma observação e uma ação, e nos dará uma estimativa de quão boa essa ação foi para o estado dado.
observation_spec, action_spec, time_step_spec = (
spec_utils.get_tensor_specs(collect_env))
with strategy.scope():
critic_net = critic_network.CriticNetwork(
(observation_spec, action_spec),
observation_fc_layer_params=None,
action_fc_layer_params=None,
joint_fc_layer_params=critic_joint_fc_layer_params,
kernel_initializer='glorot_uniform',
last_kernel_initializer='glorot_uniform')
Usaremos este crítico para treinar um actor rede que nos permitirá gerar ações dadas uma observação.
O ActorNetwork irá prever parâmetros para um esmagado-tanh MultivariateNormalDiag distribuição. Essa distribuição será então amostrada, condicionada à observação atual, sempre que precisarmos gerar ações.
with strategy.scope():
actor_net = actor_distribution_network.ActorDistributionNetwork(
observation_spec,
action_spec,
fc_layer_params=actor_fc_layer_params,
continuous_projection_net=(
tanh_normal_projection_network.TanhNormalProjectionNetwork))
Com essas redes em mãos, agora podemos instanciar o agente.
with strategy.scope():
train_step = train_utils.create_train_step()
tf_agent = sac_agent.SacAgent(
time_step_spec,
action_spec,
actor_network=actor_net,
critic_network=critic_net,
actor_optimizer=tf.keras.optimizers.Adam(
learning_rate=actor_learning_rate),
critic_optimizer=tf.keras.optimizers.Adam(
learning_rate=critic_learning_rate),
alpha_optimizer=tf.keras.optimizers.Adam(
learning_rate=alpha_learning_rate),
target_update_tau=target_update_tau,
target_update_period=target_update_period,
td_errors_loss_fn=tf.math.squared_difference,
gamma=gamma,
reward_scale_factor=reward_scale_factor,
train_step_counter=train_step)
tf_agent.initialize()
Replay Buffer
A fim de manter o controle dos dados coletados a partir do ambiente, vamos usar Reverb , um sistema de replay eficiente, extensível e de fácil uso por Deepmind. Ele armazena dados de experiência coletados pelos Atores e consumidos pelo Aluno durante o treinamento.
Neste tutorial, isso é menos importante do que max_size - mas em um ambiente distribuído com coleta e formação assíncrona, você provavelmente vai querer experimentar com rate_limiters.SampleToInsertRatio , usando um algum lugar samples_per_insert entre 2 e 1000. Por exemplo:
rate_limiter=reverb.rate_limiters.SampleToInsertRatio(samples_per_insert=3.0, min_size_to_sample=3, error_buffer=3.0)
table_name = 'uniform_table'
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1))
reverb_server = reverb.Server([table])
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpl579aohk. [reverb/cc/platform/tfrecord_checkpointer.cc:386] Loading latest checkpoint from /tmp/tmpl579aohk [reverb/cc/platform/default/server.cc:71] Started replay server on port 15652
O tampão de repetição é construído utilizando características que descrevem os tensores que são para serem armazenados, os quais podem ser obtidos a partir do agente utilizando tf_agent.collect_data_spec .
Desde o Agente SAC precisa tanto o atual e próxima observação para calcular a perda, montamos sequence_length=2 .
reverb_replay = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
sequence_length=2,
table_name=table_name,
local_server=reverb_server)
Agora geramos um conjunto de dados TensorFlow do buffer de reprodução do Reverb. Vamos passar isso para o aluno para que ele experimente experiências para treinamento.
dataset = reverb_replay.as_dataset(
sample_batch_size=batch_size, num_steps=2).prefetch(50)
experience_dataset_fn = lambda: dataset
Políticas
Em TF-agentes, políticas representam a noção padrão de políticas em RL: dado um time_step produzir uma ação ou distribuição sobre ações. O método principal é policy_step = policy.step(time_step) onde policy_step é uma tupla chamado PolicyStep(action, state, info) . O policy_step.action é a action a ser aplicada ao ambiente, state representa o estado para políticas e stateful (RNN) info podem conter informações auxiliares, tais como probabilidades de registo das acções.
Os agentes contêm duas políticas:
-
agent.policy- A principal política que é utilizada para avaliação e implantação. -
agent.collect_policy- A segunda política que é usado para a coleta de dados.
tf_eval_policy = tf_agent.policy
eval_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_eval_policy, use_tf_function=True)
tf_collect_policy = tf_agent.collect_policy
collect_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_collect_policy, use_tf_function=True)
As políticas podem ser criadas independentemente dos agentes. Por exemplo, use tf_agents.policies.random_py_policy para criar uma política que irá selecionar aleatoriamente uma ação para cada time_step.
random_policy = random_py_policy.RandomPyPolicy(
collect_env.time_step_spec(), collect_env.action_spec())
Atores
O ator gerencia as interações entre uma política e um ambiente.
- Os componentes Ator conter uma instância do ambiente (como
py_environment) e uma cópia das variáveis de política. - Cada trabalhador Ator executa uma sequência de etapas de coleta de dados, dados os valores locais das variáveis de política.
- Atualizações de variáveis são feitas explicitamente usando a instância do cliente recipiente variável no script de treinamento antes de chamar
actor.run(). - A experiência observada é gravada no buffer de reprodução em cada etapa de coleta de dados.
Conforme os Atores executam as etapas de coleta de dados, eles passam trajetórias de (estado, ação, recompensa) para o observador, que os armazena em cache e os grava no sistema de replay do Reverb.
Nós estamos armazenando trajetórias para os quadros [(T0, T1) (T1, T2) (T2, T3), ...] porque stride_length=1 .
rb_observer = reverb_utils.ReverbAddTrajectoryObserver(
reverb_replay.py_client,
table_name,
sequence_length=2,
stride_length=1)
Criamos um ator com a política aleatória e coletamos experiências para alimentar o buffer de reprodução.
initial_collect_actor = actor.Actor(
collect_env,
random_policy,
train_step,
steps_per_run=initial_collect_steps,
observers=[rb_observer])
initial_collect_actor.run()
Instancie um ator com a política de coleta para reunir mais experiências durante o treinamento.
env_step_metric = py_metrics.EnvironmentSteps()
collect_actor = actor.Actor(
collect_env,
collect_policy,
train_step,
steps_per_run=1,
metrics=actor.collect_metrics(10),
summary_dir=os.path.join(tempdir, learner.TRAIN_DIR),
observers=[rb_observer, env_step_metric])
Crie um ator que será usado para avaliar a política durante o treinamento. Passamos em actor.eval_metrics(num_eval_episodes) às métricas de log mais tarde.
eval_actor = actor.Actor(
eval_env,
eval_policy,
train_step,
episodes_per_run=num_eval_episodes,
metrics=actor.eval_metrics(num_eval_episodes),
summary_dir=os.path.join(tempdir, 'eval'),
)
Aprendizes
O componente Learner contém o agente e executa atualizações de gradiente nas variáveis de política usando dados de experiência do buffer de reprodução. Após uma ou mais etapas de treinamento, o aluno pode enviar um novo conjunto de valores de variáveis para o contêiner de variáveis.
saved_model_dir = os.path.join(tempdir, learner.POLICY_SAVED_MODEL_DIR)
# Triggers to save the agent's policy checkpoints.
learning_triggers = [
triggers.PolicySavedModelTrigger(
saved_model_dir,
tf_agent,
train_step,
interval=policy_save_interval),
triggers.StepPerSecondLogTrigger(train_step, interval=1000),
]
agent_learner = learner.Learner(
tempdir,
train_step,
tf_agent,
experience_dataset_fn,
triggers=learning_triggers,
strategy=strategy)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' 2021-12-01 12:19:19.139118: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/policy/assets INFO:tensorflow:Assets written to: /tmp/policies/policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:561: UserWarning: Encoding a StructuredValue with type tf_agents.policies.greedy_policy.DeterministicWithLogProb_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered. "imported and registered." % type_spec_class_name) INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function
Métricas e Avaliação
Nós instanciado o Ator eval com actor.eval_metrics acima, o que cria métricas mais comumente utilizados durante a avaliação política:
- Retorno médio. O retorno é a soma das recompensas obtidas durante a execução de uma política em um ambiente para um episódio, e normalmente fazemos a média disso em alguns episódios.
- Duração média do episódio.
Executamos o Ator para gerar essas métricas.
def get_eval_metrics():
eval_actor.run()
results = {}
for metric in eval_actor.metrics:
results[metric.name] = metric.result()
return results
metrics = get_eval_metrics()
def log_eval_metrics(step, metrics):
eval_results = (', ').join(
'{} = {:.6f}'.format(name, result) for name, result in metrics.items())
print('step = {0}: {1}'.format(step, eval_results))
log_eval_metrics(0, metrics)
step = 0: AverageReturn = -0.963870, AverageEpisodeLength = 204.100006
Confira o módulo de métricas para outras implementações padrão de métricas diferentes.
Treinando o agente
O loop de treinamento envolve a coleta de dados do ambiente e a otimização das redes do agente. Ao longo do caminho, avaliaremos ocasionalmente a política do agente para ver como estamos nos saindo.
try:
%%time
except:
pass
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = get_eval_metrics()["AverageReturn"]
returns = [avg_return]
for _ in range(num_iterations):
# Training.
collect_actor.run()
loss_info = agent_learner.run(iterations=1)
# Evaluating.
step = agent_learner.train_step_numpy
if eval_interval and step % eval_interval == 0:
metrics = get_eval_metrics()
log_eval_metrics(step, metrics)
returns.append(metrics["AverageReturn"])
if log_interval and step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, loss_info.loss.numpy()))
rb_observer.close()
reverb_server.stop()
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. step = 5000: loss = -50.77360153198242 step = 10000: AverageReturn = -0.734191, AverageEpisodeLength = 299.399994 step = 10000: loss = -57.17308044433594 step = 15000: loss = -31.02552032470703 step = 20000: AverageReturn = -1.243302, AverageEpisodeLength = 432.200012 step = 20000: loss = -20.673084259033203 step = 25000: loss = -12.919441223144531 step = 30000: AverageReturn = -0.205654, AverageEpisodeLength = 280.049988 step = 30000: loss = -5.420497417449951 step = 35000: loss = -4.320608139038086 step = 40000: AverageReturn = -1.193502, AverageEpisodeLength = 378.000000 step = 40000: loss = -4.375732421875 step = 45000: loss = -3.0430049896240234 step = 50000: AverageReturn = -1.299686, AverageEpisodeLength = 482.549988 step = 50000: loss = -0.8907612562179565 step = 55000: loss = 1.2096503973007202 step = 60000: AverageReturn = -0.949927, AverageEpisodeLength = 365.899994 step = 60000: loss = 1.8157628774642944 step = 65000: loss = -4.9070353507995605 step = 70000: AverageReturn = -0.644635, AverageEpisodeLength = 506.399994 step = 70000: loss = -0.33166465163230896 step = 75000: loss = -0.41273507475852966 step = 80000: AverageReturn = 0.331935, AverageEpisodeLength = 604.299988 step = 80000: loss = 1.5354682207107544 step = 85000: loss = -2.058459997177124 step = 90000: AverageReturn = 0.292840, AverageEpisodeLength = 520.450012 step = 90000: loss = 1.2136361598968506 step = 95000: loss = -1.810737133026123 step = 100000: AverageReturn = 0.835265, AverageEpisodeLength = 515.349976 step = 100000: loss = -2.6997461318969727 [reverb/cc/platform/default/server.cc:84] Shutting down replay server
Visualização
Enredos
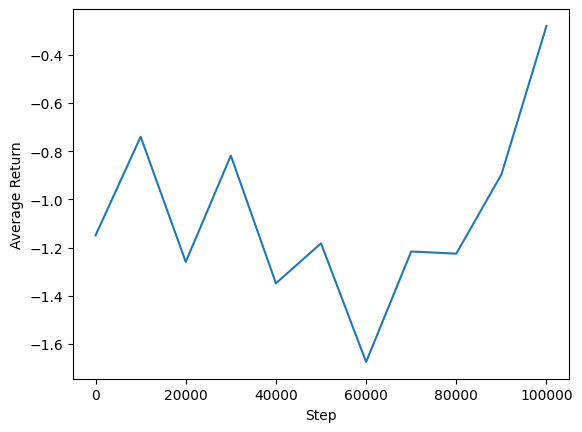
Podemos traçar o retorno médio vs etapas globais para ver o desempenho de nosso agente. Em Minitaur , a função de recompensa é baseada em quão longe o Minitaur caminha em 1000 passos e penaliza o gasto de energia.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim()
(-1.4064332604408265, 0.9420127034187317)
Vídeos
É útil visualizar o desempenho de um agente, renderizando o ambiente em cada etapa. Antes de fazermos isso, vamos primeiro criar uma função para incorporar vídeos neste colab.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
O código a seguir visualiza a política do agente para alguns episódios:
num_episodes = 3
video_filename = 'sac_minitaur.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_env.render())
while not time_step.is_last():
action_step = eval_actor.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_env.render())
embed_mp4(video_filename)