
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Este tutorial explora el aprendizaje federada parcial local, donde algunos parámetros del cliente no se agregan en el servidor. Esto es útil para modelos con parámetros específicos del usuario (por ejemplo, modelos de factorización matricial) y para entrenamiento en entornos con comunicación limitada. Nos basamos en conceptos introducidos en el aprendizaje Federados de Clasificación de Imágenes tutorial; como en el tutorial, introducimos las API de alto nivel en tff.learning para la formación y evaluación federado.
Comenzamos por motivar el aprendizaje federado parcialmente local para la factorización de la matriz . Describimos Federados Reconstrucción , un algoritmo práctico para el aprendizaje federada parcial local en escala. Preparamos el conjunto de datos MovieLens 1M, creamos un modelo parcialmente local y lo entrenamos y evaluamos.
!pip install --quiet --upgrade tensorflow-federated-nightly
!pip install --quiet --upgrade nest-asyncio
import nest_asyncio
nest_asyncio.apply()
import collections
import functools
import io
import os
import requests
import zipfile
from typing import List, Optional, Tuple
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_federated as tff
np.random.seed(42)
Antecedentes: factorización matricial
Factorización de la matriz ha sido históricamente una técnica popular para el aprendizaje de las recomendaciones y la incrustación de representaciones elementos basándose en las interacciones del usuario. El ejemplo clásico es la recomendación de la película, donde hay \(n\) usuarios y \(m\) películas, y los usuarios notaron algunas películas. Dado un usuario, usamos su historial de calificaciones y las calificaciones de usuarios similares para predecir las calificaciones de los usuarios para películas que no han visto. Si tenemos un modelo que puede predecir calificaciones, es fácil recomendar a los usuarios nuevas películas que disfrutarán.
Para esta tarea, es útil para representar puntuaciones de los usuarios como un \(n \times m\) matriz \(R\):

Esta matriz es generalmente escasa, ya que los usuarios generalmente solo ven una pequeña fracción de las películas en el conjunto de datos. La salida de matriz de factorización es de dos matrices: una \(n \times k\) matriz \(U\) representa \(k\)incrustaciones de usuario -dimensional para cada usuario, y un \(m \times k\) matriz \(I\) representa \(k\)incrustaciones artículo -dimensional para cada elemento. El objetivo de la capacitación es más simple para asegurar que el producto escalar de incrustaciones de usuario y de los puntos corresponden predictiva de las calificaciones observadas \(O\):
\[argmin_{U,I} \sum_{(u, i) \in O} (R_{ui} - U_u I_i^T)^2\]
Esto es equivalente a minimizar el error cuadrático medio entre las calificaciones observadas y las calificaciones pronosticadas tomando el producto escalar de las incrustaciones correspondientes del usuario y del artículo. Otra forma de interpretar esto es que esto asegura que \(R \approx UI^T\) para las calificaciones conocidos, por lo tanto "factorización matriz". Si esto le resulta confuso, no se preocupe, no necesitaremos conocer los detalles de la factorización matricial durante el resto del tutorial.
Explorando datos de MovieLens
Vamos a empezar por la carga de los MovieLens 1M de datos, que incluye las clasificaciones de películas 1,000,209 de 6040 usuarios en 3706 películas.
def download_movielens_data(dataset_path):
"""Downloads and copies MovieLens data to local /tmp directory."""
if dataset_path.startswith('http'):
r = requests.get(dataset_path)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall(path='/tmp')
else:
tf.io.gfile.makedirs('/tmp/ml-1m/')
for filename in ['ratings.dat', 'movies.dat', 'users.dat']:
tf.io.gfile.copy(
os.path.join(dataset_path, filename),
os.path.join('/tmp/ml-1m/', filename),
overwrite=True)
download_movielens_data('http://files.grouplens.org/datasets/movielens/ml-1m.zip')
def load_movielens_data(
data_directory: str = "/tmp",
) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""Loads pandas DataFrames for ratings, movies, users from data directory."""
# Load pandas DataFrames from data directory. Assuming data is formatted as
# specified in http://files.grouplens.org/datasets/movielens/ml-1m-README.txt.
ratings_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "ratings.dat"),
sep="::",
names=["UserID", "MovieID", "Rating", "Timestamp"], engine="python")
movies_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "movies.dat"),
sep="::",
names=["MovieID", "Title", "Genres"], engine="python")
# Create dictionaries mapping from old IDs to new (remapped) IDs for both
# MovieID and UserID. Use the movies and users present in ratings_df to
# determine the mapping, since movies and users without ratings are unneeded.
movie_mapping = {
old_movie: new_movie for new_movie, old_movie in enumerate(
ratings_df.MovieID.astype("category").cat.categories)
}
user_mapping = {
old_user: new_user for new_user, old_user in enumerate(
ratings_df.UserID.astype("category").cat.categories)
}
# Map each DataFrame consistently using the now-fixed mapping.
ratings_df.MovieID = ratings_df.MovieID.map(movie_mapping)
ratings_df.UserID = ratings_df.UserID.map(user_mapping)
movies_df.MovieID = movies_df.MovieID.map(movie_mapping)
# Remove nulls resulting from some movies being in movies_df but not
# ratings_df.
movies_df = movies_df[pd.notnull(movies_df.MovieID)]
return ratings_df, movies_df
Carguemos y exploremos un par de Pandas DataFrames que contienen la clasificación y los datos de la película.
ratings_df, movies_df = load_movielens_data()
Podemos ver que cada ejemplo de calificación tiene una calificación de 1 a 5, un UserID correspondiente, un MovieID correspondiente y una marca de tiempo.
ratings_df.head()
Cada película tiene un título y potencialmente varios géneros.
movies_df.head()
Siempre es una buena idea comprender las estadísticas básicas del conjunto de datos:
print('Num users:', len(set(ratings_df.UserID)))
print('Num movies:', len(set(ratings_df.MovieID)))
Num users: 6040 Num movies: 3706
ratings = ratings_df.Rating.tolist()
plt.hist(ratings, bins=5)
plt.xticks([1, 2, 3, 4, 5])
plt.ylabel('Count')
plt.xlabel('Rating')
plt.show()
print('Average rating:', np.mean(ratings))
print('Median rating:', np.median(ratings))
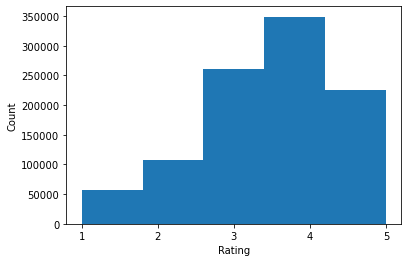
Average rating: 3.581564453029317 Median rating: 4.0
También podemos trazar los géneros de películas más populares.
movie_genres_list = movies_df.Genres.tolist()
# Count the number of times each genre describes a movie.
genre_count = collections.defaultdict(int)
for genres in movie_genres_list:
curr_genres_list = genres.split('|')
for genre in curr_genres_list:
genre_count[genre] += 1
genre_name_list, genre_count_list = zip(*genre_count.items())
plt.figure(figsize=(11, 11))
plt.pie(genre_count_list, labels=genre_name_list)
plt.title('MovieLens Movie Genres')
plt.show()
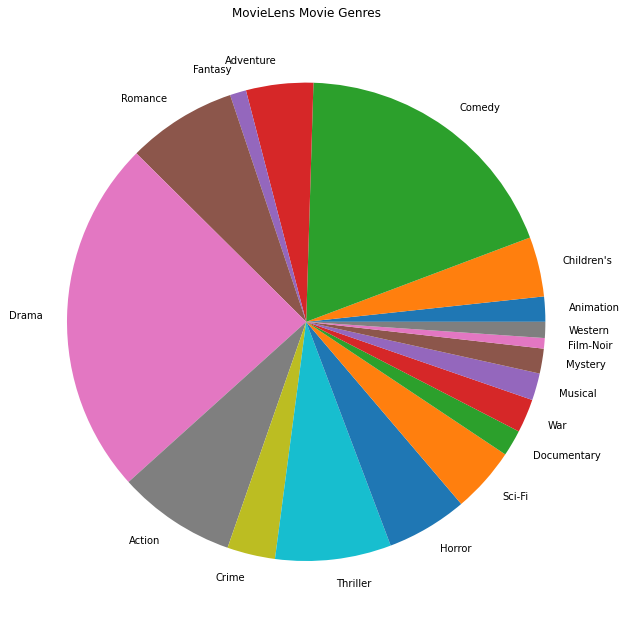
Estos datos se dividen naturalmente en calificaciones de diferentes usuarios, por lo que esperaríamos cierta heterogeneidad en los datos entre los clientes. A continuación, mostramos los géneros de películas más comúnmente calificados para diferentes usuarios. Podemos observar diferencias significativas entre usuarios.
def print_top_genres_for_user(ratings_df, movies_df, user_id):
"""Prints top movie genres for user with ID user_id."""
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
movie_ids = user_ratings_df.MovieID
genre_count = collections.Counter()
for movie_id in movie_ids:
genres_string = movies_df[movies_df.MovieID == movie_id].Genres.tolist()[0]
for genre in genres_string.split('|'):
genre_count[genre] += 1
print(f'\nFor user {user_id}:')
for (genre, freq) in genre_count.most_common(5):
print(f'{genre} was rated {freq} times')
print_top_genres_for_user(ratings_df, movies_df, user_id=0)
print_top_genres_for_user(ratings_df, movies_df, user_id=10)
print_top_genres_for_user(ratings_df, movies_df, user_id=19)
For user 0: Drama was rated 21 times Children's was rated 20 times Animation was rated 18 times Musical was rated 14 times Comedy was rated 14 times For user 10: Comedy was rated 84 times Drama was rated 54 times Romance was rated 22 times Thriller was rated 18 times Action was rated 9 times For user 19: Action was rated 17 times Sci-Fi was rated 9 times Thriller was rated 9 times Drama was rated 6 times Crime was rated 5 times
Procesamiento previo de datos de MovieLens
Ahora vamos a preparar el conjunto de datos MovieLens como una lista de tf.data.Dataset s que representa datos de cada usuario para su uso con TFF.
Implementamos dos funciones:
-
create_tf_datasets: toma nuestras calificaciones trama de datos y produce una lista de usuarios divididotf.data.Datasets. -
split_tf_datasets: toma una lista de conjuntos de datos y divide los mismos en el tren / val / prueba por el usuario, por lo que los val / juegos de ensayo contienen sólo las calificaciones de los usuarios que no se ven durante el entrenamiento. Normalmente, en la factorización de la matriz centralizada estándar que en realidad dividida de manera que los conjuntos val / ensayo contienen votaciones celebradas de salida de los usuarios se ven, ya que los usuarios no se ven no tienen incrustaciones de usuario. En nuestro caso, veremos más adelante que el enfoque que usamos para habilitar la factorización matricial en FL también permite reconstruir rápidamente las incrustaciones de usuarios para usuarios invisibles.
def create_tf_datasets(ratings_df: pd.DataFrame,
batch_size: int = 1,
max_examples_per_user: Optional[int] = None,
max_clients: Optional[int] = None) -> List[tf.data.Dataset]:
"""Creates TF Datasets containing the movies and ratings for all users."""
num_users = len(set(ratings_df.UserID))
# Optionally limit to `max_clients` to speed up data loading.
if max_clients is not None:
num_users = min(num_users, max_clients)
def rating_batch_map_fn(rating_batch):
"""Maps a rating batch to an OrderedDict with tensor values."""
# Each example looks like: {x: movie_id, y: rating}.
# We won't need the UserID since each client will only look at their own
# data.
return collections.OrderedDict([
("x", tf.cast(rating_batch[:, 1:2], tf.int64)),
("y", tf.cast(rating_batch[:, 2:3], tf.float32))
])
tf_datasets = []
for user_id in range(num_users):
# Get subset of ratings_df belonging to a particular user.
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
tf_dataset = tf.data.Dataset.from_tensor_slices(user_ratings_df)
# Define preprocessing operations.
tf_dataset = tf_dataset.take(max_examples_per_user).shuffle(
buffer_size=max_examples_per_user, seed=42).batch(batch_size).map(
rating_batch_map_fn,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
tf_datasets.append(tf_dataset)
return tf_datasets
def split_tf_datasets(
tf_datasets: List[tf.data.Dataset],
train_fraction: float = 0.8,
val_fraction: float = 0.1,
) -> Tuple[List[tf.data.Dataset], List[tf.data.Dataset], List[tf.data.Dataset]]:
"""Splits a list of user TF datasets into train/val/test by user.
"""
np.random.seed(42)
np.random.shuffle(tf_datasets)
train_idx = int(len(tf_datasets) * train_fraction)
val_idx = int(len(tf_datasets) * (train_fraction + val_fraction))
# Note that the val and test data contains completely different users, not
# just unseen ratings from train users.
return (tf_datasets[:train_idx], tf_datasets[train_idx:val_idx],
tf_datasets[val_idx:])
# We limit the number of clients to speed up dataset creation. Feel free to pass
# max_clients=None to load all clients' data.
tf_datasets = create_tf_datasets(
ratings_df=ratings_df,
batch_size=5,
max_examples_per_user=300,
max_clients=2000)
# Split the ratings into training/val/test by client.
tf_train_datasets, tf_val_datasets, tf_test_datasets = split_tf_datasets(
tf_datasets,
train_fraction=0.8,
val_fraction=0.1)
Como comprobación rápida, podemos imprimir un lote de datos de entrenamiento. Podemos ver que cada ejemplo individual contiene un MovieID debajo de la tecla "x" y una calificación debajo de la tecla "y". Tenga en cuenta que no necesitaremos el ID de usuario ya que cada usuario solo ve sus propios datos.
print(next(iter(tf_train_datasets[0])))
OrderedDict([('x', <tf.Tensor: shape=(5, 1), dtype=int64, numpy=
array([[1907],
[2891],
[1574],
[2785],
[2775]])>), ('y', <tf.Tensor: shape=(5, 1), dtype=float32, numpy=
array([[3.],
[3.],
[3.],
[4.],
[3.]], dtype=float32)>)])
Podemos trazar un histograma que muestre la cantidad de calificaciones por usuario.
def count_examples(curr_count, batch):
return curr_count + tf.size(batch['x'])
num_examples_list = []
# Compute number of examples for every other user.
for i in range(0, len(tf_train_datasets), 2):
num_examples = tf_train_datasets[i].reduce(tf.constant(0), count_examples).numpy()
num_examples_list.append(num_examples)
plt.hist(num_examples_list, bins=10)
plt.ylabel('Count')
plt.xlabel('Number of Examples')
plt.show()
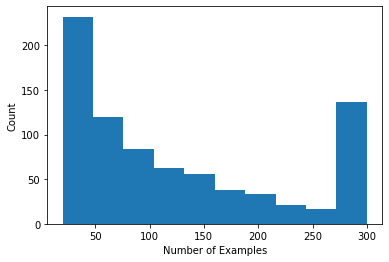
Ahora que hemos cargado y explorado los datos, discutiremos cómo llevar la factorización matricial al aprendizaje federado. En el camino, motivaremos el aprendizaje federado parcialmente local.
Llevando la factorización matricial a FL
Si bien la factorización matricial se ha utilizado tradicionalmente en entornos centralizados, es especialmente relevante en el aprendizaje federado: las calificaciones de los usuarios pueden vivir en dispositivos cliente separados, y es posible que queramos aprender incorporaciones y recomendaciones para usuarios y elementos sin centralizar los datos. Dado que cada usuario tiene una incrustación de usuario correspondiente, es natural que cada cliente almacene su incrustación de usuario; esto se escala mucho mejor que un servidor central que almacena todas las incrustaciones de usuario.
Una propuesta para llevar la factorización matricial a FL es la siguiente:
- El servidor almacena y envía las matrices elemento \(I\) a clientes muestreados cada ronda
- Actualizar a clientes de la matriz de elemento y su usuario personal incrustar \(U_u\) usando SGD en el objetivo anterior
- Cambios a \(I\) se agregan en el servidor, la actualización de la copia del servidor de \(I\) para la siguiente ronda
Este enfoque es parcialmente locales, es decir, algunos parámetros del cliente no son agregados por el servidor. Aunque este enfoque es atractivo, requiere que los clientes mantengan el estado en todas las rondas, es decir, las incrustaciones de sus usuarios. Los algoritmos federados con estado son menos apropiados para configuraciones de FL entre dispositivos: en estas configuraciones, el tamaño de la población es a menudo mucho mayor que el número de clientes que participan en cada ronda, y un cliente generalmente participa como máximo una vez durante el proceso de capacitación. Además de depender de estado que no puede ser inicializado, con estado algoritmos pueden dar lugar a la degradación del rendimiento en los entornos en varios dispositivos, debido a conseguir rancio estado cuando los clientes se muestrean con poca frecuencia. Es importante destacar que en la configuración de factorización matricial, un algoritmo con estado conduce a que todos los clientes invisibles pierdan incorporaciones de usuarios capacitados y, en la capacitación a gran escala, es posible que la mayoría de los usuarios no se vean. Para más información sobre la motivación para algoritmos sin estado en cruzada dispositivo FL, véase Wang et al. 2021 seg. 3.1.1 y Reddi et al. 2020 Sec. 5.1 .
Federated Reconstrucción ( Singhal et al. 2021 ) es una alternativa sin estado para el enfoque antes mencionado. La idea clave es que en lugar de almacenar incrustaciones de usuarios en las rondas, los clientes reconstruyen las incrustaciones de usuarios cuando sea necesario. Cuando se aplica FedRecon a la factorización matricial, el entrenamiento procede de la siguiente manera:
- El servidor almacena y envía las matrices elemento \(I\) a clientes muestreados cada ronda
- Cada cliente congela \(I\) y entrena su usuario incrustación \(U_u\) usando una o más etapas de SGD (reconstrucción)
- A cada cliente se congela \(U_u\) y trenes \(I\) usando una o más etapas de SGD
- Cambios a \(I\) son agregados a través de los usuarios, la actualización de la copia del servidor de \(I\) para la siguiente ronda
Este enfoque no requiere que los clientes mantengan el estado en todas las rondas. Los autores también muestran en el artículo que este método conduce a una reconstrucción rápida de las incorporaciones de usuarios para clientes invisibles (Sec. 4.2, Fig.3 y Tabla 1), lo que permite que la mayoría de los clientes que no participan en la capacitación tengan un modelo capacitado. , permitiendo recomendaciones para estos clientes.
Definiendo el modelo
A continuación, definiremos el modelo de factorización matricial local que se entrenará en los dispositivos del cliente. Este modelo incluirá la matriz completo del ítem \(I\) y un solo incrustación usuario \(U_u\) para el cliente \(u\). Tenga en cuenta que no necesitan los clientes para almacenar la matriz de usuario completa \(U\).
Definiremos lo siguiente:
-
UserEmbedding: un simple capa Keras que representa un solonum_latent_factorsusuario -dimensional incrustación. -
get_matrix_factorization_model: una función que devuelve untff.learning.reconstruction.Modelque contiene la lógica del modelo, incluyendo las capas que se agregan a nivel mundial en el servidor y las capas que permanecen local. Necesitamos esta información adicional para inicializar el proceso de formación de Reconstrucción federada. Aquí producimos eltff.learning.reconstruction.Modelde un modelo Keras usandotff.learning.reconstruction.from_keras_model. Al igual que entff.learning.Model, también podemos aplicar una costumbretff.learning.reconstruction.Modelmediante la implementación de la interfaz de la clase.
class UserEmbedding(tf.keras.layers.Layer):
"""Keras layer representing an embedding for a single user, used below."""
def __init__(self, num_latent_factors, **kwargs):
super().__init__(**kwargs)
self.num_latent_factors = num_latent_factors
def build(self, input_shape):
self.embedding = self.add_weight(
shape=(1, self.num_latent_factors),
initializer='uniform',
dtype=tf.float32,
name='UserEmbeddingKernel')
super().build(input_shape)
def call(self, inputs):
return self.embedding
def compute_output_shape(self):
return (1, self.num_latent_factors)
def get_matrix_factorization_model(
num_items: int,
num_latent_factors: int) -> tff.learning.reconstruction.Model:
"""Defines a Keras matrix factorization model."""
# Layers with variables will be partitioned into global and local layers.
# We'll pass this to `tff.learning.reconstruction.from_keras_model`.
global_layers = []
local_layers = []
# Extract the item embedding.
item_input = tf.keras.layers.Input(shape=[1], name='Item')
item_embedding_layer = tf.keras.layers.Embedding(
num_items,
num_latent_factors,
name='ItemEmbedding')
global_layers.append(item_embedding_layer)
flat_item_vec = tf.keras.layers.Flatten(name='FlattenItems')(
item_embedding_layer(item_input))
# Extract the user embedding.
user_embedding_layer = UserEmbedding(
num_latent_factors,
name='UserEmbedding')
local_layers.append(user_embedding_layer)
# The item_input never gets used by the user embedding layer,
# but this allows the model to directly use the user embedding.
flat_user_vec = user_embedding_layer(item_input)
# Compute the dot product between the user embedding, and the item one.
pred = tf.keras.layers.Dot(
1, normalize=False, name='Dot')([flat_user_vec, flat_item_vec])
input_spec = collections.OrderedDict(
x=tf.TensorSpec(shape=[None, 1], dtype=tf.int64),
y=tf.TensorSpec(shape=[None, 1], dtype=tf.float32))
model = tf.keras.Model(inputs=item_input, outputs=pred)
return tff.learning.reconstruction.from_keras_model(
keras_model=model,
global_layers=global_layers,
local_layers=local_layers,
input_spec=input_spec)
Análoga a la interfaz para Federados de promedio, la interfaz para la Reconstrucción Federated espera una model_fn sin argumentos que devuelve un tff.learning.reconstruction.Model .
# This will be used to produce our training process.
# User and item embeddings will be 50-dimensional.
model_fn = functools.partial(
get_matrix_factorization_model,
num_items=3706,
num_latent_factors=50)
Ahora vamos a definir loss_fn y metrics_fn , donde loss_fn es una función sin argumentos devolver una pérdida Keras utilizar para entrenar el modelo y metrics_fn es una función sin argumentos devolver una lista de métrica Keras para su evaluación. Estos son necesarios para construir los cálculos de capacitación y evaluación.
Usaremos Mean Squared Error como la pérdida, como se mencionó anteriormente. Para la evaluación usaremos la precisión de la calificación (cuando el producto escalar previsto del modelo se redondea al número entero más cercano, ¿con qué frecuencia coincide con la calificación de la etiqueta?).
class RatingAccuracy(tf.keras.metrics.Mean):
"""Keras metric computing accuracy of reconstructed ratings."""
def __init__(self,
name: str = 'rating_accuracy',
**kwargs):
super().__init__(name=name, **kwargs)
def update_state(self,
y_true: tf.Tensor,
y_pred: tf.Tensor,
sample_weight: Optional[tf.Tensor] = None):
absolute_diffs = tf.abs(y_true - y_pred)
# A [batch_size, 1] tf.bool tensor indicating correctness within the
# threshold for each example in a batch. A 0.5 threshold corresponds
# to correctness when predictions are rounded to the nearest whole
# number.
example_accuracies = tf.less_equal(absolute_diffs, 0.5)
super().update_state(example_accuracies, sample_weight=sample_weight)
loss_fn = lambda: tf.keras.losses.MeanSquaredError()
metrics_fn = lambda: [RatingAccuracy()]
Capacitación y evaluación
Ahora tenemos todo lo que necesitamos para definir el proceso de formación. Una diferencia importante de la interfaz para Federados de promedio es que ahora se pasa en un reconstruction_optimizer_fn , que será utilizado en la reconstrucción de parámetros locales (en nuestro caso, las incrustaciones de usuario). Por lo general es razonable utilizar SGD aquí, con una similar o ligeramente más baja tasa de aprendizaje que el cliente optimizador de velocidad de aprendizaje. Proporcionamos una configuración de trabajo a continuación. Esto no se ha ajustado cuidadosamente, así que siéntete libre de jugar con diferentes valores.
Echa un vistazo a la documentación para obtener más detalles y opciones.
# We'll use this by doing:
# state = training_process.initialize()
# state, metrics = training_process.next(state, federated_train_data)
training_process = tff.learning.reconstruction.build_training_process(
model_fn=model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(1.0),
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.5),
reconstruction_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.1))
También podemos definir un cálculo para evaluar nuestro modelo global entrenado.
# We'll use this by doing:
# eval_metrics = evaluation_computation(state.model, tf_val_datasets)
# where `state` is the state from the training process above.
evaluation_computation = tff.learning.reconstruction.build_federated_evaluation(
model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
reconstruction_optimizer_fn=functools.partial(
tf.keras.optimizers.SGD, 0.1))
Podemos inicializar el estado del proceso de entrenamiento y examinarlo. Lo más importante es que podemos ver que este estado del servidor solo almacena variables de elementos (actualmente inicializadas aleatoriamente) y no incrustaciones de usuarios.
state = training_process.initialize()
print(state.model)
print('Item variables shape:', state.model.trainable[0].shape)
ModelWeights(trainable=[array([[-0.02840446, 0.01196523, -0.01864688, ..., 0.03020107,
0.00121176, 0.00146852],
[ 0.01330637, 0.04741272, -0.01487445, ..., -0.03352419,
0.0104811 , 0.03506917],
[-0.04132779, 0.04883525, -0.04799002, ..., 0.00246904,
0.00586842, 0.01506213],
...,
[ 0.0216659 , 0.00734354, 0.00471039, ..., 0.01596491,
-0.00220431, -0.01559857],
[-0.00319657, -0.01740328, 0.02808609, ..., -0.00501985,
-0.03850871, -0.03844522],
[ 0.03791947, -0.00035037, 0.04217024, ..., 0.00365371,
0.00283421, 0.00897921]], dtype=float32)], non_trainable=[])
Item variables shape: (3706, 50)
También podemos intentar evaluar nuestro modelo inicializado aleatoriamente en clientes de validación. La evaluación de la Reconstrucción federada aquí implica lo siguiente:
- El servidor envía la matriz elemento \(I\) a los clientes de evaluación muestreados
- Cada cliente congela \(I\) y entrena su usuario incrustación \(U_u\) usando una o más etapas de SGD (reconstrucción)
- Cada cliente pérdida calcula y métricas utilizando el servidor \(I\) y reconstruida \(U_u\) en una parte invisible de sus datos locales
- Las pérdidas y las métricas se promedian entre los usuarios para calcular las pérdidas y las métricas generales
Tenga en cuenta que los pasos 1 y 2 son los mismos que para el entrenamiento. Esta conexión es importante, ya que la formación de la misma manera que evaluamos conduce a una forma de meta-aprendizaje, o aprender a aprender. En este caso, el modelo está aprendiendo a aprender las variables globales (matriz de elementos) que conducen a una reconstrucción eficaz de las variables locales (incrustaciones de usuarios). Para más información sobre esto, vea la Sec. 4,2 del papel.
También es importante que los pasos 2 y 3 se lleven a cabo utilizando porciones separadas de los datos locales de los clientes, para garantizar una evaluación justa. De forma predeterminada, tanto el proceso de entrenamiento como el cálculo de evaluación utilizan cualquier otro ejemplo para la reconstrucción y utilizan la otra mitad después de la reconstrucción. Este comportamiento se puede personalizar mediante la dataset_split_fn argumento (vamos a explorar esto más adelante).
# We shouldn't expect good evaluation results here, since we haven't trained
# yet!
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Initial Eval:', eval_metrics['eval'])
Initial Eval: OrderedDict([('loss', 14.340279), ('rating_accuracy', 0.0)])
A continuación, podemos intentar realizar una ronda de entrenamiento. Para hacer las cosas más realistas, probaremos 50 clientes por ronda al azar sin reemplazo. Aún deberíamos esperar que las métricas de trenes sean malas, ya que solo estamos haciendo una ronda de capacitación.
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train metrics:', metrics['train'])
Train metrics: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.317455)])
Ahora configuremos un ciclo de entrenamiento para entrenar en múltiples rondas.
NUM_ROUNDS = 20
train_losses = []
train_accs = []
state = training_process.initialize()
# This may take a couple minutes to run.
for i in range(NUM_ROUNDS):
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train round {i}:', metrics['train'])
train_losses.append(metrics['train']['loss'])
train_accs.append(metrics['train']['rating_accuracy'])
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Final Eval:', eval_metrics['eval'])
Train round 0: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.7013445)])
Train round 1: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.459233)])
Train round 2: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.52466)])
Train round 3: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.087793)])
Train round 4: OrderedDict([('rating_accuracy', 0.011243612), ('loss', 11.110232)])
Train round 5: OrderedDict([('rating_accuracy', 0.06366048), ('loss', 8.267054)])
Train round 6: OrderedDict([('rating_accuracy', 0.12331288), ('loss', 5.2693872)])
Train round 7: OrderedDict([('rating_accuracy', 0.14264487), ('loss', 5.1511016)])
Train round 8: OrderedDict([('rating_accuracy', 0.21046545), ('loss', 3.8246362)])
Train round 9: OrderedDict([('rating_accuracy', 0.21320973), ('loss', 3.303812)])
Train round 10: OrderedDict([('rating_accuracy', 0.21651311), ('loss', 3.4864292)])
Train round 11: OrderedDict([('rating_accuracy', 0.23476052), ('loss', 3.0105433)])
Train round 12: OrderedDict([('rating_accuracy', 0.21981856), ('loss', 3.1807854)])
Train round 13: OrderedDict([('rating_accuracy', 0.27683082), ('loss', 2.3382564)])
Train round 14: OrderedDict([('rating_accuracy', 0.26080742), ('loss', 2.7009728)])
Train round 15: OrderedDict([('rating_accuracy', 0.2733109), ('loss', 2.2993557)])
Train round 16: OrderedDict([('rating_accuracy', 0.29282996), ('loss', 2.5278995)])
Train round 17: OrderedDict([('rating_accuracy', 0.30204678), ('loss', 2.060092)])
Train round 18: OrderedDict([('rating_accuracy', 0.2940266), ('loss', 2.0976772)])
Train round 19: OrderedDict([('rating_accuracy', 0.3086304), ('loss', 2.0626144)])
Final Eval: OrderedDict([('loss', 1.9961331), ('rating_accuracy', 0.30322924)])
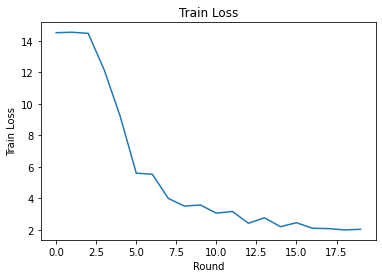
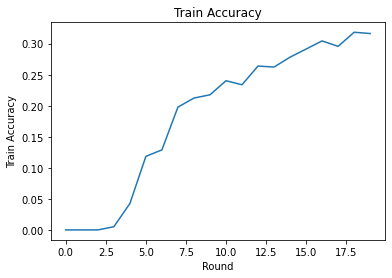
Podemos graficar la pérdida de entrenamiento y la precisión en rondas. Los hiperparámetros de este cuaderno no se han ajustado cuidadosamente, así que siéntase libre de probar diferentes clientes por ronda, tasas de aprendizaje, número de rondas y número total de clientes para mejorar estos resultados.
plt.plot(range(NUM_ROUNDS), train_losses)
plt.ylabel('Train Loss')
plt.xlabel('Round')
plt.title('Train Loss')
plt.show()
plt.plot(range(NUM_ROUNDS), train_accs)
plt.ylabel('Train Accuracy')
plt.xlabel('Round')
plt.title('Train Accuracy')
plt.show()
Finalmente, podemos calcular métricas en un conjunto de prueba invisible cuando hayamos terminado de ajustar.
eval_metrics = evaluation_computation(state.model, tf_test_datasets)
print('Final Test:', eval_metrics['eval'])
Final Test: OrderedDict([('loss', 1.9566978), ('rating_accuracy', 0.30792442)])
Exploraciones adicionales
Buen trabajo al completar este cuaderno. Sugerimos los siguientes ejercicios para explorar más a fondo el aprendizaje federado parcialmente local, ordenados de forma aproximada por dificultad creciente:
Las implementaciones típicas de Promedio federado toman múltiples pasadas locales (épocas) sobre los datos (además de tomar una pasada sobre los datos en múltiples lotes). Para la reconstrucción federada, es posible que deseemos controlar el número de pasos por separado para la reconstrucción y el entrenamiento posterior a la reconstrucción. Pasando el
dataset_split_fnargumento para los constructores de formación y evaluación de cálculo activa el control del número de etapas y épocas más de dos reconstrucción y posterior a la reconstrucción de datos. Como ejercicio, intente realizar 3 épocas locales de entrenamiento de reconstrucción, con un límite de 50 pasos y 1 período local de entrenamiento posterior a la reconstrucción, con un límite de 50 pasos. Sugerencia: encontrarátff.learning.reconstruction.build_dataset_split_fnútil. Una vez que haya hecho esto, intente ajustar estos hiperparámetros y otros relacionados, como las tasas de aprendizaje y el tamaño del lote, para obtener mejores resultados.El comportamiento predeterminado del entrenamiento y la evaluación de la Reconstrucción federada es dividir los datos locales de los clientes a la mitad para cada reconstrucción y posreconstrucción. En los casos en que los clientes tengan muy pocos datos locales, puede ser razonable reutilizar los datos para la reconstrucción y la reconstrucción posterior solo para el proceso de capacitación (no para la evaluación, esto conducirá a una evaluación injusta). Trate de hacer este cambio para el proceso de formación, asegurando la
dataset_split_fnpara la evaluación aún conserva la reconstrucción y la reconstrucción posterior a la desunión de datos. PISTA:tff.learning.reconstruction.simple_dataset_split_fnpodría ser útil.Anterior, se produjo una
tff.learning.Modelde un modelo Keras usandotff.learning.reconstruction.from_keras_model. También podemos aplicar un modelo personalizado utilizando TensorFlow pura 2.0 por la implementación de la interfaz de modelo . Intente modificarget_matrix_factorization_modelpara construir y devolver una clase que extiendetff.learning.reconstruction.Model, la aplicación de sus métodos. Pista: el código fuente detff.learning.reconstruction.from_keras_modelproporciona un ejemplo de extender eltff.learning.reconstruction.Modelclase. Consulte también la aplicación de modelos personalizados en el tutorial de clasificación de imágenes EMNIST para un ejercicio similar en la ampliación de unatff.learning.Model.En este tutorial, hemos motivado el aprendizaje federado parcialmente local en el contexto de la factorización matricial, donde el envío de incrustaciones de usuarios al servidor filtraría trivialmente las preferencias del usuario. También podemos aplicar la Reconstrucción federada en otros entornos como una forma de entrenar modelos más personales (ya que parte del modelo es completamente local para cada usuario) mientras se reduce la comunicación (ya que los parámetros locales no se envían al servidor). En general, utilizando la interfaz que se presenta aquí, podemos tomar cualquier modelo federado que normalmente se entrenaría de forma totalmente global y, en su lugar, dividir sus variables en variables globales y variables locales. El ejemplo explorado en el papel Federados Reconstrucción es personal predicción de la siguiente palabra: aquí, cada usuario tiene su propio conjunto local del inclusiones de palabras para las palabras fuera de vocabulario, lo que permite el modelo de la jerga de los usuarios capturar y lograr la personalización sin comunicación adicional. Como ejercicio, intente implementar (ya sea como un modelo de Keras o un modelo personalizado de TensorFlow 2.0) un modelo diferente para usar con la Reconstrucción federada. Una sugerencia: implementar un modelo de clasificación EMNIST con una incrustación de usuario personal, donde la incrustación de usuario personal se concatena a las características de la imagen de CNN antes de la última capa densa del modelo. Puede volver a utilizar gran parte del código de este tutorial (por ejemplo, el
UserEmbeddingclase) y la imagen de clasificación tutorial .
Si todavía está buscando más en el aprendizaje federado parcialmente locales, revisar el papel Federados Reconstrucción y de código abierto código del experimento .