
| |  GitHubでソースを表示 GitHubでソースを表示 | |
このチュートリアルでは、いくつかのクライアントパラメータがサーバー上に集約されることはありません、部分的に地元の連合学習を探ります。これは、ユーザー固有のパラメーターを持つモデル(マトリックス因数分解モデルなど)や、通信が制限された設定でのトレーニングに役立ちます。私たちはで導入された概念上に構築画像分類のための連合学習のチュートリアル。そのチュートリアルのように、我々は、高レベルAPIを導入tff.learning連合訓練と評価のために。
私たちは、のために部分的に地元の連合学習を動機づけることから始めマトリックス分解。私たちは、連合復興(記述紙、ブログ記事)、スケールで部分的に地元の連合学習のための実用的なアルゴリズムを。 MovieLens 1Mデータセットを準備し、部分的にローカルモデルを構築し、トレーニングして評価します。
!pip install --quiet --upgrade tensorflow-federated-nightly
!pip install --quiet --upgrade nest-asyncio
import nest_asyncio
nest_asyncio.apply()
import collections
import functools
import io
import os
import requests
import zipfile
from typing import List, Optional, Tuple
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_federated as tff
np.random.seed(42)
背景:行列の因数分解
行列の因数分解は、勧告を学習し、ユーザーとの対話に基づいてアイテムのための表現を埋め込むための歴史的に一般的な技術となっています。標準的な例があります映画の勧告、ある \(n\) ユーザーと \(m\) 映画は、ユーザーがいくつかの映画を評価しています。ユーザーが与えられた場合、私たちは彼らの評価履歴と類似ユーザーの評価を使用して、彼らが見たことがない映画に対するユーザーの評価を予測します。評価を予測できるモデルがあれば、ユーザーが楽しめる新しい映画を簡単に推薦できます。
この作業のために、それはのように、ユーザーの評価を表すのに便利です \(n \times m\) マトリックス \(R\):

ユーザーは通常、データセット内の映画のごく一部しか見ることができないため、このマトリックスは一般的にまばらです。 :マトリックス分解の出力は、2つの行列であり、 \(n \times k\) マトリックス \(U\) 表す \(k\)ユーザ毎次元ユーザ埋め込み、および \(m \times k\) マトリックス \(I\) 表す \(k\)各項目の次元項目埋め込みを。最も簡単なトレーニングの目的は、ユーザーとアイテムの埋め込みのドット積が観測された評価を予測していることを確認することです \(O\):
\[argmin_{U,I} \sum_{(u, i) \in O} (R_{ui} - U_u I_i^T)^2\]
これは、観察された評価と、対応するユーザーとアイテムの埋め込みの内積を取ることによって予測された評価との間の平均二乗誤差を最小化することと同等です。これを解釈するもう一つの方法は、このことを保証することである \(R \approx UI^T\) ので、既知の評価のために、「マトリックス分解」。これが紛らわしい場合でも、心配しないでください。チュートリアルの残りの部分では、行列の因数分解の詳細を知る必要はありません。
MovieLensデータの探索
のは、ロードしてみましょうMovieLens 1Mの3706本の映画に6040人のユーザーから1000209の映画の評価で構成されたデータを、。
def download_movielens_data(dataset_path):
"""Downloads and copies MovieLens data to local /tmp directory."""
if dataset_path.startswith('http'):
r = requests.get(dataset_path)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall(path='/tmp')
else:
tf.io.gfile.makedirs('/tmp/ml-1m/')
for filename in ['ratings.dat', 'movies.dat', 'users.dat']:
tf.io.gfile.copy(
os.path.join(dataset_path, filename),
os.path.join('/tmp/ml-1m/', filename),
overwrite=True)
download_movielens_data('http://files.grouplens.org/datasets/movielens/ml-1m.zip')
def load_movielens_data(
data_directory: str = "/tmp",
) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""Loads pandas DataFrames for ratings, movies, users from data directory."""
# Load pandas DataFrames from data directory. Assuming data is formatted as
# specified in http://files.grouplens.org/datasets/movielens/ml-1m-README.txt.
ratings_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "ratings.dat"),
sep="::",
names=["UserID", "MovieID", "Rating", "Timestamp"], engine="python")
movies_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "movies.dat"),
sep="::",
names=["MovieID", "Title", "Genres"], engine="python")
# Create dictionaries mapping from old IDs to new (remapped) IDs for both
# MovieID and UserID. Use the movies and users present in ratings_df to
# determine the mapping, since movies and users without ratings are unneeded.
movie_mapping = {
old_movie: new_movie for new_movie, old_movie in enumerate(
ratings_df.MovieID.astype("category").cat.categories)
}
user_mapping = {
old_user: new_user for new_user, old_user in enumerate(
ratings_df.UserID.astype("category").cat.categories)
}
# Map each DataFrame consistently using the now-fixed mapping.
ratings_df.MovieID = ratings_df.MovieID.map(movie_mapping)
ratings_df.UserID = ratings_df.UserID.map(user_mapping)
movies_df.MovieID = movies_df.MovieID.map(movie_mapping)
# Remove nulls resulting from some movies being in movies_df but not
# ratings_df.
movies_df = movies_df[pd.notnull(movies_df.MovieID)]
return ratings_df, movies_df
評価とムービーデータを含むいくつかのPandasDataFrameをロードして調べてみましょう。
ratings_df, movies_df = load_movielens_data()
各評価例には、1〜5の評価、対応するUserID、対応するMovieID、およびタイムスタンプがあることがわかります。
ratings_df.head()
各映画にはタイトルがあり、複数のジャンルが存在する可能性があります。
movies_df.head()
データセットの基本的な統計を理解することは常に良い考えです。
print('Num users:', len(set(ratings_df.UserID)))
print('Num movies:', len(set(ratings_df.MovieID)))
Num users: 6040 Num movies: 3706
ratings = ratings_df.Rating.tolist()
plt.hist(ratings, bins=5)
plt.xticks([1, 2, 3, 4, 5])
plt.ylabel('Count')
plt.xlabel('Rating')
plt.show()
print('Average rating:', np.mean(ratings))
print('Median rating:', np.median(ratings))
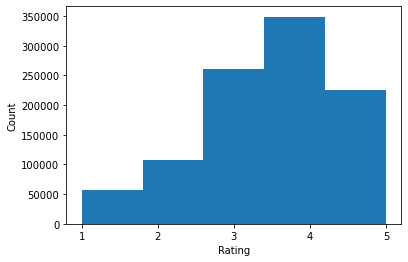
Average rating: 3.581564453029317 Median rating: 4.0
最も人気のある映画のジャンルをプロットすることもできます。
movie_genres_list = movies_df.Genres.tolist()
# Count the number of times each genre describes a movie.
genre_count = collections.defaultdict(int)
for genres in movie_genres_list:
curr_genres_list = genres.split('|')
for genre in curr_genres_list:
genre_count[genre] += 1
genre_name_list, genre_count_list = zip(*genre_count.items())
plt.figure(figsize=(11, 11))
plt.pie(genre_count_list, labels=genre_name_list)
plt.title('MovieLens Movie Genres')
plt.show()
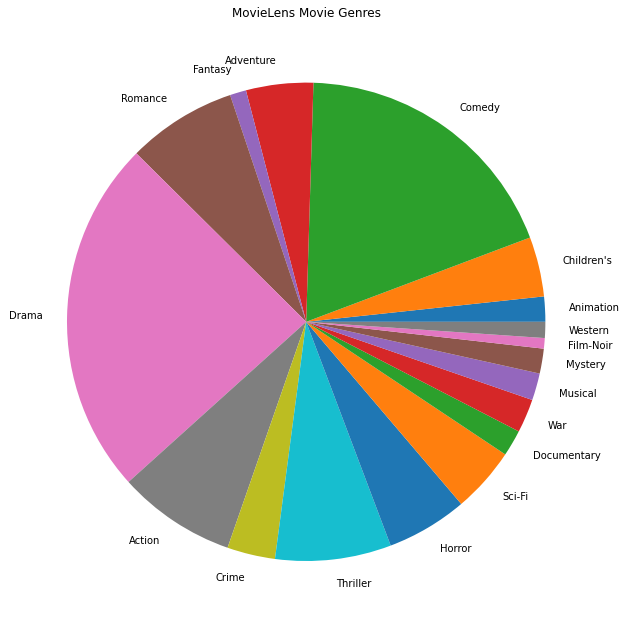
このデータは当然、さまざまなユーザーからの評価に分割されるため、クライアント間のデータにはある程度の異質性が予想されます。以下に、さまざまなユーザーに対して最も一般的に評価されている映画のジャンルを示します。ユーザー間の大きな違いを観察できます。
def print_top_genres_for_user(ratings_df, movies_df, user_id):
"""Prints top movie genres for user with ID user_id."""
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
movie_ids = user_ratings_df.MovieID
genre_count = collections.Counter()
for movie_id in movie_ids:
genres_string = movies_df[movies_df.MovieID == movie_id].Genres.tolist()[0]
for genre in genres_string.split('|'):
genre_count[genre] += 1
print(f'\nFor user {user_id}:')
for (genre, freq) in genre_count.most_common(5):
print(f'{genre} was rated {freq} times')
print_top_genres_for_user(ratings_df, movies_df, user_id=0)
print_top_genres_for_user(ratings_df, movies_df, user_id=10)
print_top_genres_for_user(ratings_df, movies_df, user_id=19)
For user 0: Drama was rated 21 times Children's was rated 20 times Animation was rated 18 times Musical was rated 14 times Comedy was rated 14 times For user 10: Comedy was rated 84 times Drama was rated 54 times Romance was rated 22 times Thriller was rated 18 times Action was rated 9 times For user 19: Action was rated 17 times Sci-Fi was rated 9 times Thriller was rated 9 times Drama was rated 6 times Crime was rated 5 times
MovieLensデータの前処理
現在のリストとしてMovieLensデータセットを作成しますtf.data.DatasetのTFFで使用するために、各ユーザのデータを表します。
2つの機能を実装します。
-
create_tf_datasets:データフレームたちの評価を取り、ユーザーが分割のリスト生成tf.data.Dataset秒。 -
split_tf_datasets:データセットのリストを取るとval /テスト・セットは、トレーニング中に目に見えないユーザーからのみ評価が含まれているので、ユーザーが電車/ヴァル/テストにそれらを分割します。一般的に、標準的な集中型のマトリックス分解に、私たちは実際に目に見えないユーザーは、ユーザーの埋め込みを持っていないので、ヴァル/テスト・セットは、見たユーザーから開催されたアウト評価が含まれているので、分割します。私たちの場合、FLで行列分解を有効にするために使用するアプローチにより、見えないユーザーのユーザー埋め込みをすばやく再構築できることも後でわかります。
def create_tf_datasets(ratings_df: pd.DataFrame,
batch_size: int = 1,
max_examples_per_user: Optional[int] = None,
max_clients: Optional[int] = None) -> List[tf.data.Dataset]:
"""Creates TF Datasets containing the movies and ratings for all users."""
num_users = len(set(ratings_df.UserID))
# Optionally limit to `max_clients` to speed up data loading.
if max_clients is not None:
num_users = min(num_users, max_clients)
def rating_batch_map_fn(rating_batch):
"""Maps a rating batch to an OrderedDict with tensor values."""
# Each example looks like: {x: movie_id, y: rating}.
# We won't need the UserID since each client will only look at their own
# data.
return collections.OrderedDict([
("x", tf.cast(rating_batch[:, 1:2], tf.int64)),
("y", tf.cast(rating_batch[:, 2:3], tf.float32))
])
tf_datasets = []
for user_id in range(num_users):
# Get subset of ratings_df belonging to a particular user.
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
tf_dataset = tf.data.Dataset.from_tensor_slices(user_ratings_df)
# Define preprocessing operations.
tf_dataset = tf_dataset.take(max_examples_per_user).shuffle(
buffer_size=max_examples_per_user, seed=42).batch(batch_size).map(
rating_batch_map_fn,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
tf_datasets.append(tf_dataset)
return tf_datasets
def split_tf_datasets(
tf_datasets: List[tf.data.Dataset],
train_fraction: float = 0.8,
val_fraction: float = 0.1,
) -> Tuple[List[tf.data.Dataset], List[tf.data.Dataset], List[tf.data.Dataset]]:
"""Splits a list of user TF datasets into train/val/test by user.
"""
np.random.seed(42)
np.random.shuffle(tf_datasets)
train_idx = int(len(tf_datasets) * train_fraction)
val_idx = int(len(tf_datasets) * (train_fraction + val_fraction))
# Note that the val and test data contains completely different users, not
# just unseen ratings from train users.
return (tf_datasets[:train_idx], tf_datasets[train_idx:val_idx],
tf_datasets[val_idx:])
# We limit the number of clients to speed up dataset creation. Feel free to pass
# max_clients=None to load all clients' data.
tf_datasets = create_tf_datasets(
ratings_df=ratings_df,
batch_size=5,
max_examples_per_user=300,
max_clients=2000)
# Split the ratings into training/val/test by client.
tf_train_datasets, tf_val_datasets, tf_test_datasets = split_tf_datasets(
tf_datasets,
train_fraction=0.8,
val_fraction=0.1)
簡単なチェックとして、トレーニングデータのバッチを印刷できます。個々の例には、「x」キーの下にMovieIDが含まれ、「y」キーの下に評価が含まれていることがわかります。各ユーザーには自分のデータしか表示されないため、UserIDは必要ないことに注意してください。
print(next(iter(tf_train_datasets[0])))
OrderedDict([('x', <tf.Tensor: shape=(5, 1), dtype=int64, numpy=
array([[1907],
[2891],
[1574],
[2785],
[2775]])>), ('y', <tf.Tensor: shape=(5, 1), dtype=float32, numpy=
array([[3.],
[3.],
[3.],
[4.],
[3.]], dtype=float32)>)])
ユーザーごとの評価数を示すヒストグラムをプロットできます。
def count_examples(curr_count, batch):
return curr_count + tf.size(batch['x'])
num_examples_list = []
# Compute number of examples for every other user.
for i in range(0, len(tf_train_datasets), 2):
num_examples = tf_train_datasets[i].reduce(tf.constant(0), count_examples).numpy()
num_examples_list.append(num_examples)
plt.hist(num_examples_list, bins=10)
plt.ylabel('Count')
plt.xlabel('Number of Examples')
plt.show()
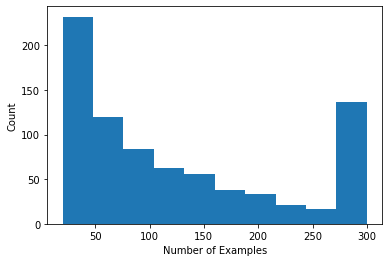
データを読み込んで調査したので、マトリックス因数分解を連合学習に導入する方法について説明します。その過程で、部分的にローカルな連合学習を動機付けます。
行列因数分解をFLにもたらす
行列因数分解は従来、集中型の設定で使用されてきましたが、特に連合学習に関連しています。ユーザーの評価は別々のクライアントデバイスに存在する可能性があり、データを集中化せずにユーザーとアイテムの埋め込みと推奨事項を学習したい場合があります。各ユーザーには対応するユーザー埋め込みがあるため、各クライアントにユーザー埋め込みを保存させるのは自然なことです。これは、すべてのユーザー埋め込みを保存する中央サーバーよりもはるかに優れた拡張性を備えています。
行列因数分解をFLに導入するための1つの提案は、次のとおりです。
- サーバ店やアイテムマトリックス送信 \(I\) サンプリングし、クライアントに各ラウンド
- クライアントは、アイテム行列を更新し、自分の個人ユーザが埋め込み \(U_u\) 上記目的にSGDを使用して
- 更新 \(I\) のサーバーコピーの更新、サーバー上に集約されている \(I\) 次のラウンドのため
このアプローチは、いくつかのクライアントのパラメータはサーバーによって集約されることはありませんさ-つまり、部分的にローカルです。このアプローチは魅力的ですが、クライアントはラウンド間で状態を維持する必要があります。つまり、ユーザーの埋め込みです。ステートフルフェデレーションアルゴリズムは、クロスデバイスFL設定にはあまり適していません。これらの設定では、母集団のサイズは各ラウンドに参加するクライアントの数よりもはるかに大きいことが多く、クライアントは通常、トレーニングプロセス中に最大1回参加します。初期化されなくてもよい状態に依存するほかに、ステートフルなアルゴリズムは、クライアントがまれにサンプリングされるときに失効し得る状態に起因するクロスデバイスの設定で性能低下をもたらすことができます。重要なのは、マトリックス因数分解の設定では、ステートフルアルゴリズムにより、すべての見えないクライアントがトレーニング済みのユーザー埋め込みを見逃し、大規模なトレーニングでは、大多数のユーザーが見えない可能性があることです。クロスデバイスFLにおけるステートレスアルゴリズムの動機の詳細については、 Wangらに。 2021秒3.1.1およびReddiら。 2020秒5.1 。
フェデレーテッド・復興(シングハルら2021 )、前述のアプローチのステートレスな代替です。重要なアイデアは、ラウンド間でユーザー埋め込みを保存する代わりに、クライアントは必要に応じてユーザー埋め込みを再構築することです。 FedReconを行列因数分解に適用すると、トレーニングは次のように進行します。
- サーバ店やアイテムマトリックス送信 \(I\) サンプリングし、クライアントに各ラウンド
- 各クライアントは、フリーズ \(I\) し、そのユーザ埋め込み列車 \(U_u\) SGDの一つ以上のステップを使用して(再構成)
- 各クライアントがフリーズ \(U_u\) や電車を \(I\) SGDの一つ以上の手順を使用して、
- 更新 \(I\) のサーバーコピーの更新、ユーザー全体で集約されている \(I\) 次のラウンドのため
このアプローチでは、クライアントがラウンド間で状態を維持する必要はありません。著者はまた、この方法が目に見えないクライアントのユーザー埋め込みの高速再構築につながり(セクション4.2、図3、および表1)、トレーニングに参加しないクライアントの大多数がトレーニング済みモデルを持つことを可能にすることを論文で示しています、これらのクライアントの推奨事項を有効にします。連合復興を参照してくださいGoogleのAIのブログ記事よりキーの結果を得るために。
モデルの定義
次に、クライアントデバイスでトレーニングするローカルマトリックス因数分解モデルを定義します。このモデルは、完全なアイテム行列含む \(I\) と単一ユーザ埋め込み \(U_u\) クライアント用 \(u\)。クライアントは、完全なユーザー行列格納する必要がないことに注意 \(U\)。
以下を定義します。
-
UserEmbedding:単一表す単純Keras層num_latent_factors次元ユーザ埋め込み。 -
get_matrix_factorization_model:返す関数tff.learning.reconstruction.Modelグローバルサーバに集約し、その層を局所残っている層を含む、モデルのロジックを含有します。 Federated Reconstructionトレーニングプロセスを初期化するには、この追加情報が必要です。ここでは、生産tff.learning.reconstruction.Model使用してKerasモデルからtff.learning.reconstruction.from_keras_model。同様にtff.learning.Model、我々はまた、カスタム実装することができますtff.learning.reconstruction.Modelクラスインターフェイスを実装することによって。
class UserEmbedding(tf.keras.layers.Layer):
"""Keras layer representing an embedding for a single user, used below."""
def __init__(self, num_latent_factors, **kwargs):
super().__init__(**kwargs)
self.num_latent_factors = num_latent_factors
def build(self, input_shape):
self.embedding = self.add_weight(
shape=(1, self.num_latent_factors),
initializer='uniform',
dtype=tf.float32,
name='UserEmbeddingKernel')
super().build(input_shape)
def call(self, inputs):
return self.embedding
def compute_output_shape(self):
return (1, self.num_latent_factors)
def get_matrix_factorization_model(
num_items: int,
num_latent_factors: int) -> tff.learning.reconstruction.Model:
"""Defines a Keras matrix factorization model."""
# Layers with variables will be partitioned into global and local layers.
# We'll pass this to `tff.learning.reconstruction.from_keras_model`.
global_layers = []
local_layers = []
# Extract the item embedding.
item_input = tf.keras.layers.Input(shape=[1], name='Item')
item_embedding_layer = tf.keras.layers.Embedding(
num_items,
num_latent_factors,
name='ItemEmbedding')
global_layers.append(item_embedding_layer)
flat_item_vec = tf.keras.layers.Flatten(name='FlattenItems')(
item_embedding_layer(item_input))
# Extract the user embedding.
user_embedding_layer = UserEmbedding(
num_latent_factors,
name='UserEmbedding')
local_layers.append(user_embedding_layer)
# The item_input never gets used by the user embedding layer,
# but this allows the model to directly use the user embedding.
flat_user_vec = user_embedding_layer(item_input)
# Compute the dot product between the user embedding, and the item one.
pred = tf.keras.layers.Dot(
1, normalize=False, name='Dot')([flat_user_vec, flat_item_vec])
input_spec = collections.OrderedDict(
x=tf.TensorSpec(shape=[None, 1], dtype=tf.int64),
y=tf.TensorSpec(shape=[None, 1], dtype=tf.float32))
model = tf.keras.Model(inputs=item_input, outputs=pred)
return tff.learning.reconstruction.from_keras_model(
keras_model=model,
global_layers=global_layers,
local_layers=local_layers,
input_spec=input_spec)
フェデレーテッド平均化のためのインタフェースにAnalagous、連邦復興のためのインターフェースは期待しmodel_fn返す引数なしでtff.learning.reconstruction.Model 。
# This will be used to produce our training process.
# User and item embeddings will be 50-dimensional.
model_fn = functools.partial(
get_matrix_factorization_model,
num_items=3706,
num_latent_factors=50)
私たちは、次の定義しますloss_fnとmetrics_fn 、 loss_fnモデルを訓練するために使用するKeras損失を返す引数なしの関数であり、かつmetrics_fn評価のためのKerasメトリックのリストを返す引数なしの関数です。これらは、トレーニングと評価の計算を構築するために必要です。
上記のように、損失として平均二乗誤差を使用します。評価には、評価の精度を使用します(モデルの予測内積が最も近い整数に丸められる場合、ラベルの評価と一致する頻度はどれくらいですか?)。
class RatingAccuracy(tf.keras.metrics.Mean):
"""Keras metric computing accuracy of reconstructed ratings."""
def __init__(self,
name: str = 'rating_accuracy',
**kwargs):
super().__init__(name=name, **kwargs)
def update_state(self,
y_true: tf.Tensor,
y_pred: tf.Tensor,
sample_weight: Optional[tf.Tensor] = None):
absolute_diffs = tf.abs(y_true - y_pred)
# A [batch_size, 1] tf.bool tensor indicating correctness within the
# threshold for each example in a batch. A 0.5 threshold corresponds
# to correctness when predictions are rounded to the nearest whole
# number.
example_accuracies = tf.less_equal(absolute_diffs, 0.5)
super().update_state(example_accuracies, sample_weight=sample_weight)
loss_fn = lambda: tf.keras.losses.MeanSquaredError()
metrics_fn = lambda: [RatingAccuracy()]
トレーニングと評価
これで、トレーニングプロセスを定義するために必要なものがすべて揃いました。一つの重要な違い連合平均化のためのインターフェースは、我々が今に渡すということですreconstruction_optimizer_fn (私たちの場合は、ユーザーの埋め込み)ローカルパラメータを再構成するときに使用されます。それは使用することが一般的に合理的だSGD割合を学ぶオプティマイザクライアントよりも類似またはやや低い学習率で、ここに。以下に動作する構成を提供します。これは慎重に調整されていないため、さまざまな値を自由に試してみてください。
チェックアウトのドキュメントを詳細とオプションのために。
# We'll use this by doing:
# state = training_process.initialize()
# state, metrics = training_process.next(state, federated_train_data)
training_process = tff.learning.reconstruction.build_training_process(
model_fn=model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(1.0),
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.5),
reconstruction_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.1))
トレーニング済みのグローバルモデルを評価するための計算を定義することもできます。
# We'll use this by doing:
# eval_metrics = evaluation_computation(state.model, tf_val_datasets)
# where `state` is the state from the training process above.
evaluation_computation = tff.learning.reconstruction.build_federated_evaluation(
model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
reconstruction_optimizer_fn=functools.partial(
tf.keras.optimizers.SGD, 0.1))
トレーニングプロセスの状態を初期化して調べることができます。最も重要なことは、このサーバー状態にはアイテム変数(現在はランダムに初期化されている)のみが格納され、ユーザーの埋め込みは格納されていないことがわかります。
state = training_process.initialize()
print(state.model)
print('Item variables shape:', state.model.trainable[0].shape)
ModelWeights(trainable=[array([[-0.02840446, 0.01196523, -0.01864688, ..., 0.03020107,
0.00121176, 0.00146852],
[ 0.01330637, 0.04741272, -0.01487445, ..., -0.03352419,
0.0104811 , 0.03506917],
[-0.04132779, 0.04883525, -0.04799002, ..., 0.00246904,
0.00586842, 0.01506213],
...,
[ 0.0216659 , 0.00734354, 0.00471039, ..., 0.01596491,
-0.00220431, -0.01559857],
[-0.00319657, -0.01740328, 0.02808609, ..., -0.00501985,
-0.03850871, -0.03844522],
[ 0.03791947, -0.00035037, 0.04217024, ..., 0.00365371,
0.00283421, 0.00897921]], dtype=float32)], non_trainable=[])
Item variables shape: (3706, 50)
検証クライアントでランダムに初期化されたモデルを評価することもできます。ここでの連合再建の評価には、以下が含まれます。
- サーバーは、アイテム行列送信 \(I\) サンプリングし、評価クライアントに
- 各クライアントは、フリーズ \(I\) し、そのユーザ埋め込み列車 \(U_u\) SGDの一つ以上のステップを使用して(再構成)
- 各クライアントは、サーバーの使用して損失とメトリックを計算する \(I\) と再構成 \(U_u\) 自分のローカルデータの目に見えない部分に
- 損失とメトリクスはユーザー全体で平均化され、全体的な損失とメトリクスが計算されます
手順1と2はトレーニングの場合と同じであることに注意してください。この接続は、メタ学習、または学ぶ方法を学ぶのフォームに、我々はリードを評価するのと同じ方法を訓練するので、重要です。この場合、モデルは、ローカル変数(ユーザー埋め込み)のパフォーマンスの高い再構築につながるグローバル変数(アイテムマトリックス)を学習する方法を学習しています。これに関する詳細については、を参照してください秒。 4.2紙の。
公正な評価を確実にするために、ステップ2と3がクライアントのローカルデータのばらばらな部分を使用して実行されることも重要です。デフォルトでは、トレーニングプロセスと評価計算の両方で、再構築に1つおきの例が使用され、再構築後の残りの半分が使用されます。この動作は、使用してカスタマイズすることができdataset_split_fn引数を(我々はこれをさらに後で見ていきます)。
# We shouldn't expect good evaluation results here, since we haven't trained
# yet!
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Initial Eval:', eval_metrics['eval'])
Initial Eval: OrderedDict([('loss', 14.340279), ('rating_accuracy', 0.0)])
次に、トレーニングのラウンドを実行してみることができます。より現実的にするために、ラウンドごとに50のクライアントを置き換えなしでランダムにサンプリングします。トレーニングは1ラウンドしかないため、トレーニングの指標は依然として不十分であると予想する必要があります。
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train metrics:', metrics['train'])
Train metrics: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.317455)])
次に、複数のラウンドでトレーニングするためのトレーニングループを設定しましょう。
NUM_ROUNDS = 20
train_losses = []
train_accs = []
state = training_process.initialize()
# This may take a couple minutes to run.
for i in range(NUM_ROUNDS):
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train round {i}:', metrics['train'])
train_losses.append(metrics['train']['loss'])
train_accs.append(metrics['train']['rating_accuracy'])
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Final Eval:', eval_metrics['eval'])
Train round 0: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.7013445)])
Train round 1: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.459233)])
Train round 2: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.52466)])
Train round 3: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.087793)])
Train round 4: OrderedDict([('rating_accuracy', 0.011243612), ('loss', 11.110232)])
Train round 5: OrderedDict([('rating_accuracy', 0.06366048), ('loss', 8.267054)])
Train round 6: OrderedDict([('rating_accuracy', 0.12331288), ('loss', 5.2693872)])
Train round 7: OrderedDict([('rating_accuracy', 0.14264487), ('loss', 5.1511016)])
Train round 8: OrderedDict([('rating_accuracy', 0.21046545), ('loss', 3.8246362)])
Train round 9: OrderedDict([('rating_accuracy', 0.21320973), ('loss', 3.303812)])
Train round 10: OrderedDict([('rating_accuracy', 0.21651311), ('loss', 3.4864292)])
Train round 11: OrderedDict([('rating_accuracy', 0.23476052), ('loss', 3.0105433)])
Train round 12: OrderedDict([('rating_accuracy', 0.21981856), ('loss', 3.1807854)])
Train round 13: OrderedDict([('rating_accuracy', 0.27683082), ('loss', 2.3382564)])
Train round 14: OrderedDict([('rating_accuracy', 0.26080742), ('loss', 2.7009728)])
Train round 15: OrderedDict([('rating_accuracy', 0.2733109), ('loss', 2.2993557)])
Train round 16: OrderedDict([('rating_accuracy', 0.29282996), ('loss', 2.5278995)])
Train round 17: OrderedDict([('rating_accuracy', 0.30204678), ('loss', 2.060092)])
Train round 18: OrderedDict([('rating_accuracy', 0.2940266), ('loss', 2.0976772)])
Train round 19: OrderedDict([('rating_accuracy', 0.3086304), ('loss', 2.0626144)])
Final Eval: OrderedDict([('loss', 1.9961331), ('rating_accuracy', 0.30322924)])
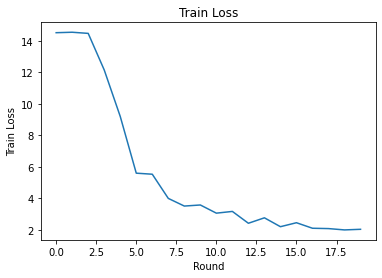
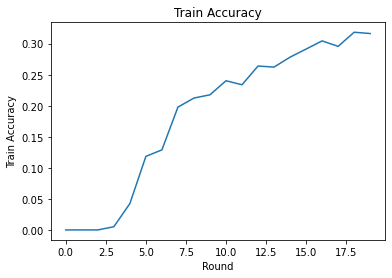
ラウンド全体のトレーニング損失と精度をプロットできます。このノートブックのハイパーパラメータは慎重に調整されていないため、ラウンドごとのさまざまなクライアント、学習率、ラウンド数、およびクライアントの総数を試して、これらの結果を改善してください。
plt.plot(range(NUM_ROUNDS), train_losses)
plt.ylabel('Train Loss')
plt.xlabel('Round')
plt.title('Train Loss')
plt.show()
plt.plot(range(NUM_ROUNDS), train_accs)
plt.ylabel('Train Accuracy')
plt.xlabel('Round')
plt.title('Train Accuracy')
plt.show()
最後に、チューニングが終了したときに、見えないテストセットのメトリックを計算できます。
eval_metrics = evaluation_computation(state.model, tf_test_datasets)
print('Final Test:', eval_metrics['eval'])
Final Test: OrderedDict([('loss', 1.9566978), ('rating_accuracy', 0.30792442)])
さらなる調査
このノートブックを完成させるための素晴らしい仕事。難易度の高い順に大まかに並べて、部分的にローカルな連合学習をさらに調査するために、次の演習をお勧めします。
Federated Averagingの一般的な実装では、データに対して複数のローカルパス(エポック)を使用します(複数のバッチにわたってデータに対して1回のパスを実行することに加えて)。連合再建の場合、再建と再建後のトレーニングのために、ステップ数を別々に制御したい場合があります。渡す
dataset_split_fn訓練と評価の計算ビルダーへの引数は、両方の再建と復興後のデータセットをステップオーバーとエポック数の制御を可能にします。演習として、50ステップを上限とする再建トレーニングの3つのローカルエポックと、50ステップを上限とする再建後トレーニングの1つのローカルエポックを実行してみてください。ヒント:あなたは見つけることができますtff.learning.reconstruction.build_dataset_split_fn役立ちます。これを行ったら、これらのハイパーパラメータと、学習率やバッチサイズなどの他の関連するハイパーパラメータを調整して、より良い結果を取得してみてください。Federated Reconstructionのトレーニングと評価のデフォルトの動作は、再構築と再構築後のそれぞれについて、クライアントのローカルデータを半分に分割することです。クライアントがローカルデータをほとんど持っていない場合、トレーニングプロセスのみの再構築と再構築後のデータを再利用することが合理的です(評価用ではなく、これは不当な評価につながります)。確実に、トレーニングプロセスのためにこの変更を作ってみましょう
dataset_split_fn評価のためには、まだ復興と再構成後のデータ互いに素を保持します。ヒント:tff.learning.reconstruction.simple_dataset_split_fn便利かもしれません。上記は、我々は生産
tff.learning.Model使用してKerasモデルからtff.learning.reconstruction.from_keras_model。我々はまた、純粋でTensorFlow 2.0を使用してカスタムモデルを実装することができモデルインターフェイスを実装します。変更してみget_matrix_factorization_model拡張するクラス構築し、返すようにtff.learning.reconstruction.Modelそのメソッドを実装し、。ヒント:のソースコードtff.learning.reconstruction.from_keras_model延びるの例を提供tff.learning.reconstruction.Modelクラス。参照してくださいEMNISTの画像分類チュートリアルのカスタムモデルの実装延長に似た運動のためtff.learning.Model。このチュートリアルでは、マトリックス因数分解のコンテキストで部分的にローカルな連合学習を動機付けました。この場合、ユーザーの埋め込みをサーバーに送信すると、ユーザーの設定が簡単にリークされます。通信を減らしながら(ローカルパラメーターがサーバーに送信されないため)、より個人的なモデルをトレーニングする方法として(モデルの一部が各ユーザーに対して完全にローカルであるため)、他の設定でフェデレーション再構築を適用することもできます。一般に、ここに示すインターフェースを使用すると、通常は完全にグローバルにトレーニングされる任意のフェデレーションモデルを取得し、代わりにその変数をグローバル変数とローカル変数に分割できます。で検討例連合復興紙は、個人的な次の単語予測である:ここでは、各ユーザーが、語彙外の単語を単語埋め込みの独自のローカルセットがあり、キャプチャユーザーのスラングにモデルを可能にし、追加の通信なしでパーソナライズを行います。演習として、Federated Reconstructionで使用する別のモデルを(KerasモデルまたはカスタムTensorFlow 2.0モデルとして)実装してみてください。提案:パーソナルユーザーの埋め込みを使用してEMNIST分類モデルを実装します。ここで、パーソナルユーザーの埋め込みは、モデルの最後の高密度レイヤーの前にCNN画像の特徴に連結されます。このチュートリアルからコード(たとえば、はるかに再利用することができ
UserEmbeddingクラス)と、画像分類のチュートリアルを。
あなたはまだ部分的に地元の連合学習の詳細を探しているなら、チェックアウト連合復興紙とオープンソースの実験コードを。