
W ciągu ostatnich kilku lat nastąpił wzrost liczby nowatorskich, zróżnicowanych warstw graficznych, które można umieszczać w architekturach sieci neuronowych. Od transformatorów przestrzennych po zróżnicowane renderery grafiki, te nowe warstwy wykorzystują wiedzę zdobytą przez lata badań nad wizją komputerową i grafiką, aby budować nowe i wydajniejsze architektury sieciowe. Wyraźne modelowanie geometrycznych a priori i ograniczeń w sieciach neuronowych otwiera drzwi do architektur, które można solidnie, wydajnie i, co ważniejsze, trenować w sposób samonadzorujący.
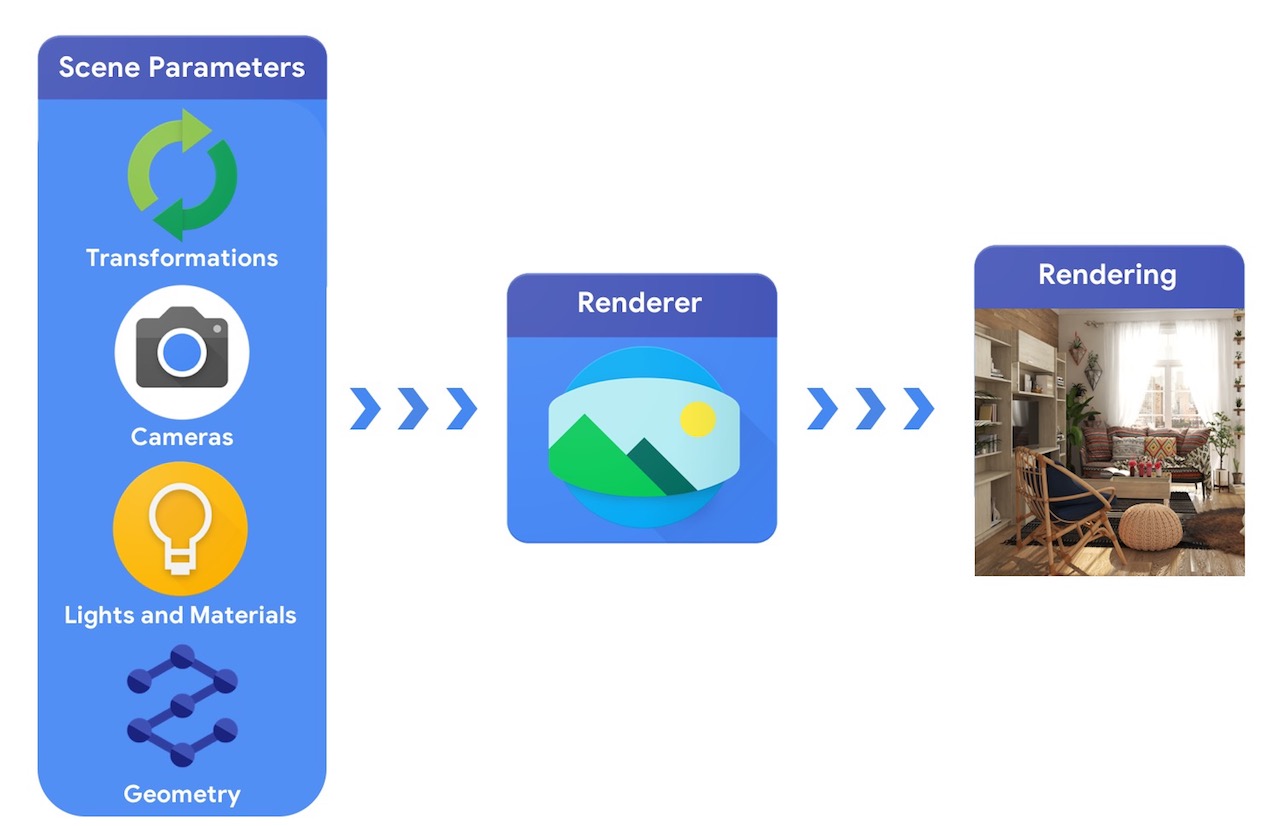
Na wysokim poziomie potok grafiki komputerowej wymaga reprezentacji obiektów 3D i ich bezwzględnego pozycjonowania w scenie, opisu materiału, z którego są wykonane, świateł i kamery. Ten opis sceny jest następnie interpretowany przez renderer w celu wygenerowania renderowania syntetycznego.
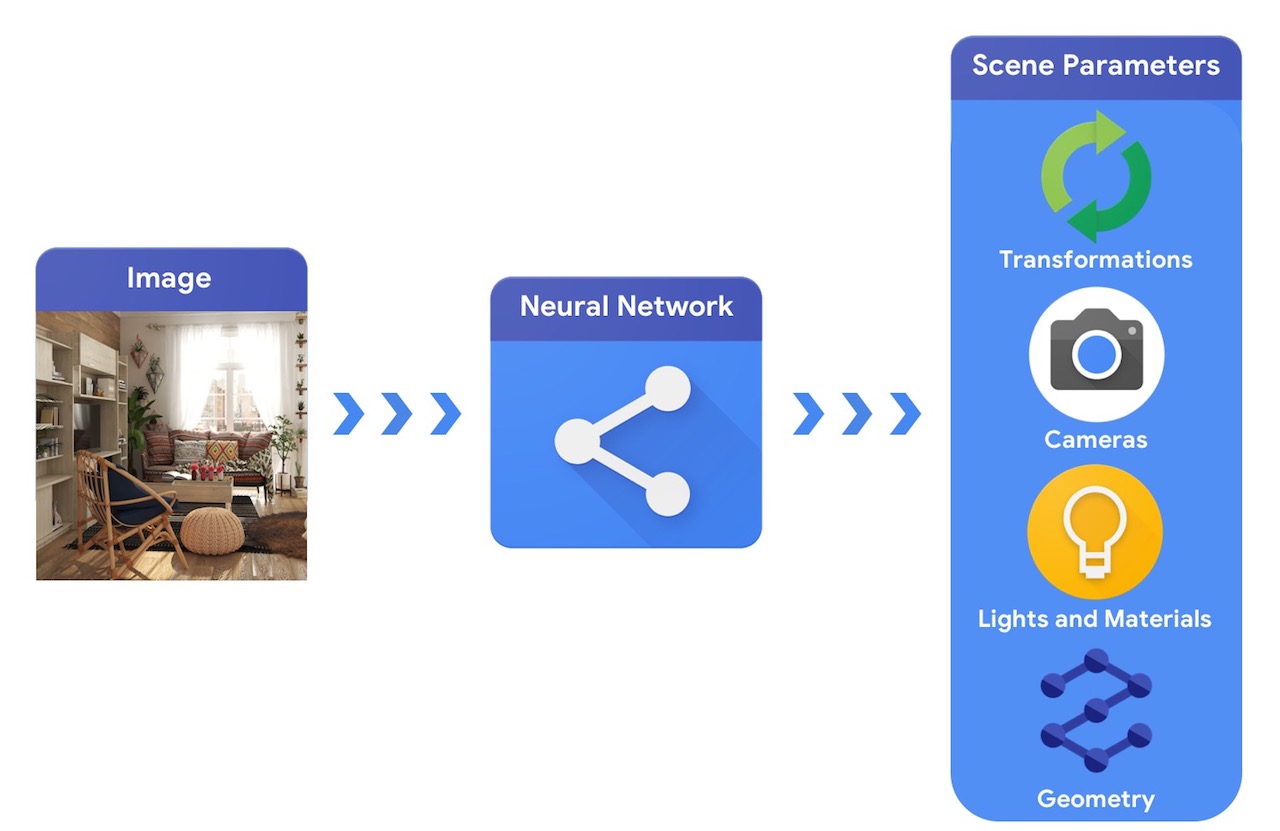
Dla porównania, komputerowy system wizyjny zaczynałby od obrazu i próbowałby wywnioskować parametry sceny. Pozwala to na przewidywanie, które obiekty znajdują się na scenie, z jakich materiałów są wykonane oraz trójwymiarową pozycję i orientację.
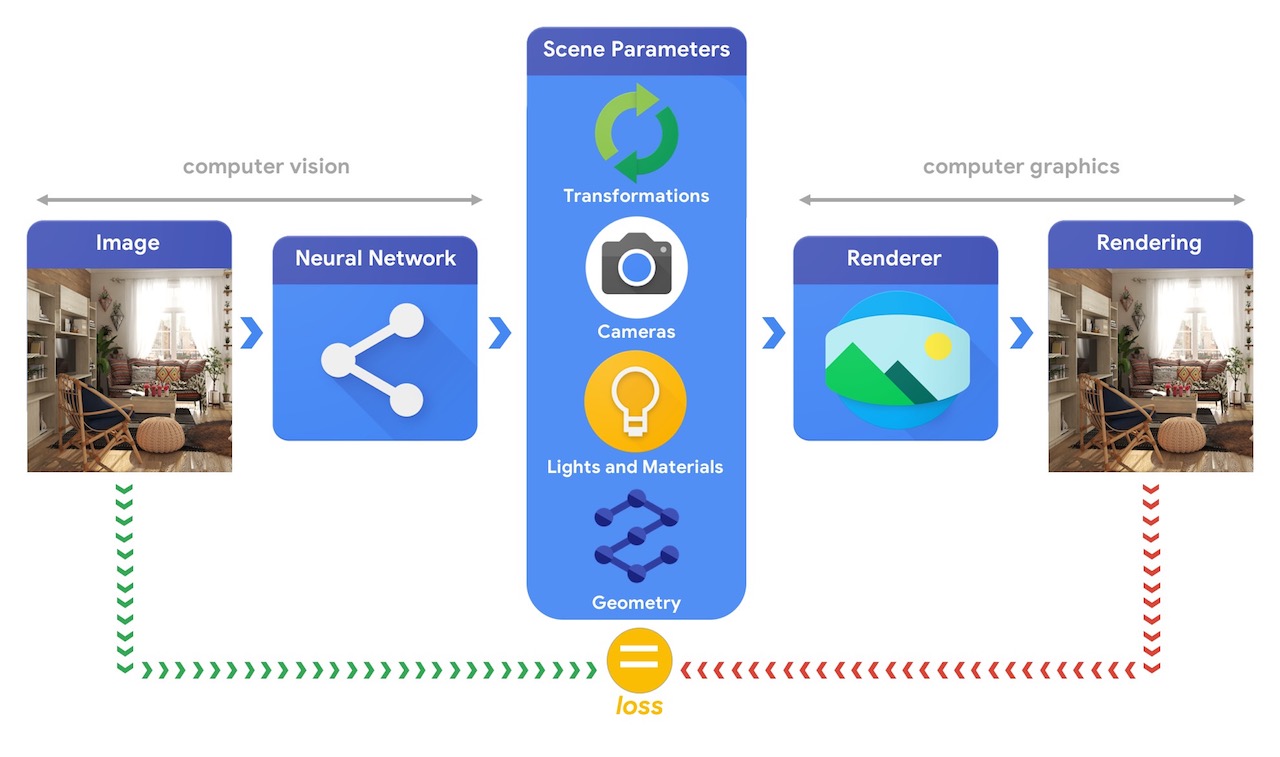
Szkolenie systemów uczenia maszynowego zdolnych do rozwiązywania tych złożonych zadań wizyjnych 3D najczęściej wymaga dużych ilości danych. Ponieważ etykietowanie danych jest procesem kosztownym i złożonym, ważne jest posiadanie mechanizmów do projektowania modeli uczenia maszynowego, które mogą zrozumieć trójwymiarowy świat podczas szkolenia bez większego nadzoru. Połączenie technik widzenia komputerowego i grafiki komputerowej daje wyjątkową możliwość wykorzystania ogromnych ilości łatwo dostępnych nieoznakowanych danych. Jak pokazano na poniższym obrazie, można to osiągnąć na przykład za pomocą analizy przez syntezę, w której system wizyjny wyodrębnia parametry sceny, a system graficzny renderuje obraz na ich podstawie. Jeśli renderowanie pasuje do oryginalnego obrazu, system wizyjny dokładnie wyodrębnił parametry sceny. W tej konfiguracji wizja komputerowa i grafika komputerowa idą w parze, tworząc jeden system uczenia maszynowego podobny do autokodera, który można trenować w sposób samonadzorowany.
Tensorflow Graphics jest opracowywany, aby pomóc w sprostaniu tego typu wyzwaniom, i w tym celu zapewnia zestaw zróżnicowanych warstw graficznych i geometrycznych (np. kamery, modele odbicia, przekształcenia przestrzenne, zwoje siatki) oraz funkcje przeglądarki 3D (np. 3D TensorBoard), które może służyć do trenowania i debugowania wybranych modeli uczenia maszynowego.