
| |
|
 GitHubでソースを表示 GitHubでソースを表示 |
自動微分と勾配
自動微分は、ニューラルネットワークをトレーニングするバックプロパゲーションなどの機械学習アルゴリズムの実装に有用です。
このガイドでは、特に Eager execution において、TensorFlow を使用して勾配を計算する方法について説明します。
セットアップ
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
2022-12-14 20:39:02.123526: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-14 20:39:02.123617: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-14 20:39:02.123626: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
勾配を計算する
TensorFlow は、自動的に微分するために、フォワードパス中にどのような演算がどの順序で行われたかを覚えておく必要があります。その後、TensorFlow は逆方向パス中にこの演算のリストを逆順に走査し、勾配を計算します。
勾配テープ
TensorFlow には、一部の入力、通常はtf.Variableに関する計算の勾配を計算する、自動微分のための tf.GradientTape API があります。TensorFlow は、tf.GradientTapeのコンテキスト内で実行される関連の演算を「テープ」に「記録」します。その後、TensorFlow はそのテープを使い、リバースモード微分を使用して「記録」された計算の勾配を計算します。
簡単な例を示します。
x = tf.Variable(3.0)
with tf.GradientTape() as tape:
y = x**2
いくつかの演算を記録してから、GradientTape.gradient(target, sources)を使用して、いくつかのソース(多くの場合はモデルの変数)に対するいくつかのターゲット(多くの場合は損失)の勾配を計算します。
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
dy_dx.numpy()
6.0
上記の例ではスカラーを使用していますが、どのテンソルでもtf.GradientTapeは簡単に機能します。
w = tf.Variable(tf.random.normal((3, 2)), name='w')
b = tf.Variable(tf.zeros(2, dtype=tf.float32), name='b')
x = [[1., 2., 3.]]
with tf.GradientTape(persistent=True) as tape:
y = x @ w + b
loss = tf.reduce_mean(y**2)
両方の変数に関する loss 勾配を取得するには、両方をソースとして gradient メソッドに渡すことができます。テープはソースがどのように渡されるかについては柔軟であり、リストまたはディクショナリのネストされた組み合わせを受け入れ、同じ方法で構造化された勾配を返します(tf.nest を参照)。
[dl_dw, dl_db] = tape.gradient(loss, [w, b])
各ソースに関する勾配には、ソースの形状があります。
print(w.shape)
print(dl_dw.shape)
(3, 2) (3, 2)
下記もまた勾配計算ですが、この例では変数のディクショナリを渡します。
my_vars = {
'w': w,
'b': b
}
grad = tape.gradient(loss, my_vars)
grad['b']
<tf.Tensor: shape=(2,), dtype=float32, numpy=array([-7.4161186, -5.151042 ], dtype=float32)>
モデルに関する勾配
チェックポイントとエクスポートをするために、tf.Variablesをtf.Moduleあるいはそのサブクラスの 1 つ(layers.Layer、keras.Model)に収集するのは一般的です。
ほとんどの場合は、モデルのトレーニング可能な変数に対する勾配を計算する必要があります。tf.Moduleのすべてのサブクラスはそれらの変数をModule.trainable_variablesプロパティに集約するため、それらの勾配を数行のコードで計算することができます。
layer = tf.keras.layers.Dense(2, activation='relu')
x = tf.constant([[1., 2., 3.]])
with tf.GradientTape() as tape:
# Forward pass
y = layer(x)
loss = tf.reduce_mean(y**2)
# Calculate gradients with respect to every trainable variable
grad = tape.gradient(loss, layer.trainable_variables)
for var, g in zip(layer.trainable_variables, grad):
print(f'{var.name}, shape: {g.shape}')
dense/kernel:0, shape: (3, 2) dense/bias:0, shape: (2,)
テープの監視対象を制御する
デフォルトの動作では、トレーニング可能なtf.Variableにアクセスした後、全ての演算を記録します。その理由は次の通りです。
- 逆方向パスの勾配を計算するために、テープはフォワードパス中のどの演算を記録するか、知っておく必要があります。
- テープは中間出力への参照を保持するため、不要な演算を記録する必要はありません。
- 最も一般的な使用例として、モデルのトレーニング可能なすべての変数に対する損失の勾配の計算があります。
たとえば、次の例ではデフォルトで tf.Tensor が「監視」されておらず、tf.Variable はトレーニング対象外であるため、勾配の計算ができません。
# A trainable variable
x0 = tf.Variable(3.0, name='x0')
# Not trainable
x1 = tf.Variable(3.0, name='x1', trainable=False)
# Not a Variable: A variable + tensor returns a tensor.
x2 = tf.Variable(2.0, name='x2') + 1.0
# Not a variable
x3 = tf.constant(3.0, name='x3')
with tf.GradientTape() as tape:
y = (x0**2) + (x1**2) + (x2**2)
grad = tape.gradient(y, [x0, x1, x2, x3])
for g in grad:
print(g)
tf.Tensor(6.0, shape=(), dtype=float32) None None None
GradientTape.watched_variablesメソッドを使用すると、テープが監視している変数を一覧表示できます。
[var.name for var in tape.watched_variables()]
['x0:0']
tf.GradientTapeは、ユーザーが監視対象や非監視対象を制御できるフックを提供します。
tf.Tensorに関する勾配を記録するには、GradientTape.watch(x)を呼び出す必要があります。
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x**2
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
print(dy_dx.numpy())
6.0
逆に、すべてのtf.Variablesを監視するデフォルトの動作を無効にするには、勾配テープの作成時にwatch_accessed_variables=Falseを設定します。この計算には 2 つの変数を使用しますが、1 つの変数の勾配のみに接続します。
x0 = tf.Variable(0.0)
x1 = tf.Variable(10.0)
with tf.GradientTape(watch_accessed_variables=False) as tape:
tape.watch(x1)
y0 = tf.math.sin(x0)
y1 = tf.nn.softplus(x1)
y = y0 + y1
ys = tf.reduce_sum(y)
GradientTape.watchはx0で呼び出されなかったため、それに関する勾配は計算されません。
# dys/dx1 = exp(x1) / (1 + exp(x1)) = sigmoid(x1)
grad = tape.gradient(ys, {'x0': x0, 'x1': x1})
print('dy/dx0:', grad['x0'])
print('dy/dx1:', grad['x1'].numpy())
dy/dx0: None dy/dx1: 0.9999546
中間結果
tf.GradientTapeコンテキスト中で計算された中間の値に対する出力の勾配をリクエストすることもできます。
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x * x
z = y * y
# Use the tape to compute the gradient of z with respect to the
# intermediate value y.
# dz_dy = 2 * y and y = x ** 2 = 9
print(tape.gradient(z, y).numpy())
18.0
デフォルトでは、ある GradientTape に保持されたリソースは、GradientTape.gradient メソッドが呼び出されるとすぐに解放されます。同じ計算で複数の勾配を計算する場合は、persistent=True を指定した勾配テープを作成します。こうすると、テープオブジェクトのガベージコレクションを実行するときにリソースが解放されるため、gradient メソッドを何度も呼び出すことができます。例を示します。
x = tf.constant([1, 3.0])
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
y = x * x
z = y * y
print(tape.gradient(z, x).numpy()) # [4.0, 108.0] (4 * x**3 at x = [1.0, 3.0])
print(tape.gradient(y, x).numpy()) # [2.0, 6.0] (2 * x at x = [1.0, 3.0])
[ 4. 108.] [2. 6.]
del tape # Drop the reference to the tape
パフォーマンスに関する注記
勾配テープコンテキスト内の演算の実行に伴う、少量のオーバーヘッドがあります。ほとんどの Eager Execution では、これは目立ったコストにはなりませんが、それでもテープコンテキストは必要な領域のみで使用すべきです。
勾配テープは、メモリを使用して入力と出力を含む中間結果を格納し、逆方向パス中に使用します。
ReLUなどの一部の演算は、中間結果を保持する必要がないため、効率を上げるためにフォワードパス中に削除されます。ただし、テープにpersistent=Trueを使用している場合は何も破棄されないため、ピーク時のメモリ使用量が高くなります。
非スカラーのターゲットの勾配
勾配は基本的にスカラーの演算です。
x = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
y0 = x**2
y1 = 1 / x
print(tape.gradient(y0, x).numpy())
print(tape.gradient(y1, x).numpy())
4.0 -0.25
したがって、複数のターゲットの勾配を求める場合、各ソースの結果は次のようになります。
- ターゲットの合計の勾配、あるいは
- 各ターゲットの勾配の合計
x = tf.Variable(2.0)
with tf.GradientTape() as tape:
y0 = x**2
y1 = 1 / x
print(tape.gradient({'y0': y0, 'y1': y1}, x).numpy())
3.75
同様に、ターゲットがスカラーでない場合は、合計の勾配が計算されます。
x = tf.Variable(2.)
with tf.GradientTape() as tape:
y = x * [3., 4.]
print(tape.gradient(y, x).numpy())
7.0
これにより、損失を集めた合計の勾配、または要素ごとの損失計算の合計の勾配の取得が容易になります。
アイテムごとに個別の勾配が必要な場合は、Jacobians(ヤコビアン)をご覧ください。
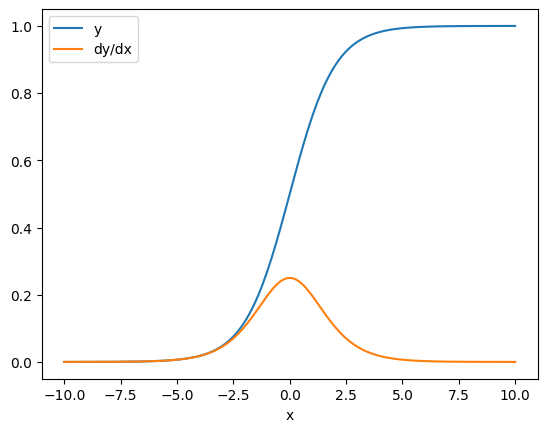
場合によっては、ヤコビアンをスキップすることができます。要素についての計算の場合、各要素は独立しているため、合計の勾配は入力要素に対する各要素の導関数を与えます。
x = tf.linspace(-10.0, 10.0, 200+1)
with tf.GradientTape() as tape:
tape.watch(x)
y = tf.nn.sigmoid(x)
dy_dx = tape.gradient(y, x)
plt.plot(x, y, label='y')
plt.plot(x, dy_dx, label='dy/dx')
plt.legend()
_ = plt.xlabel('x')
制御フロー
勾配テープは実行時に演算を記録するため、Python 制御フローは自然に処理されます(if 文や while 文など)。
ここでは、ifの各ブランチで異なる変数が使用されています。勾配は使用された変数にのみ接続します。
x = tf.constant(1.0)
v0 = tf.Variable(2.0)
v1 = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
if x > 0.0:
result = v0
else:
result = v1**2
dv0, dv1 = tape.gradient(result, [v0, v1])
print(dv0)
print(dv1)
tf.Tensor(1.0, shape=(), dtype=float32) None
制御文自体は微分不可能なため、勾配ベースのオプティマイザから見えないということに注意してください。
上記の例のxの値次第で、テープはresult = v0またはresult = v1**2を記録します。xに対する勾配は常にNoneです。
dx = tape.gradient(result, x)
print(dx)
None
gradientがNoneを返すケース
ターゲットがソースに接続されていない場合、勾配はNoneになります。
x = tf.Variable(2.)
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y * y
print(tape.gradient(z, x))
None
ここでは明らかにzがxに接続されていませんが、これほど明白ではないにしても勾配が非接続になりうる場合がいくつかあります。
1. 変数をテンソルに置換した場合
「テープの監視対象を制御する」のセクションで説明したようにテープは自動的にtf.Variableを監視しますが、tf.Tensorは監視しません。
よくあるエラーの 1 つは、tf.Variableを更新するためにVariable.assignを使用する代わりに、tf.Variableをtf.Tensorで置き換えてしまうことです。例を示します。
x = tf.Variable(2.0)
for epoch in range(2):
with tf.GradientTape() as tape:
y = x+1
print(type(x).__name__, ":", tape.gradient(y, x))
x = x + 1 # This should be `x.assign_add(1)`
ResourceVariable : tf.Tensor(1.0, shape=(), dtype=float32) EagerTensor : None
2. TensorFlowの外で計算をした
計算が TensorFlow から出てしまうと、テープは勾配パスを記録することができません。例を示します。
x = tf.Variable([[1.0, 2.0],
[3.0, 4.0]], dtype=tf.float32)
with tf.GradientTape() as tape:
x2 = x**2
# This step is calculated with NumPy
y = np.mean(x2, axis=0)
# Like most ops, reduce_mean will cast the NumPy array to a constant tensor
# using `tf.convert_to_tensor`.
y = tf.reduce_mean(y, axis=0)
print(tape.gradient(y, x))
None
3. 整数または文字列を使用して勾配を取得した
整数と文字列は微分不可能です。計算パスがこれらのデータ型を使用する場合は、勾配を取得できません。
文字列は微分不可能だと知っていても、dtypeを指定していない場合に、うっかりint定数や変数を作成してしまう可能性があります。
x = tf.constant(10)
with tf.GradientTape() as g:
g.watch(x)
y = x * x
print(g.gradient(y, x))
WARNING:tensorflow:The dtype of the watched tensor must be floating (e.g. tf.float32), got tf.int32 None
TensorFlow は、型間で自動的にキャストしないため、実際には、欠損した勾配の代わりに型のエラーが表示されることがよくあります。
4. ステートフルオブジェクトを使用して勾配を取得した
状態は勾配を停止します。ステートフルオブジェクトから読み取る場合、テープはその時点の状態のみを確認し、その状態に至るまでの履歴を確認できません。
tf.Tensor は不変で、一旦作成したテンソルは変更できません。値はありますが、状態はありません。これまでに説明したすべての演算もステートレスで、tf.matmul の出力はその入力のみに依存します。
tf.Variable tf.Variable には内部状態とその値があるため、変数を使用するとその状態が読み取られます。変数に関する勾配を計算するのは通例ですが、変数の状態によって勾配の計算をさかのぼって行うことはできません。次に例を示します。
x0 = tf.Variable(3.0)
x1 = tf.Variable(0.0)
with tf.GradientTape() as tape:
# Update x1 = x1 + x0.
x1.assign_add(x0)
# The tape starts recording from x1.
y = x1**2 # y = (x1 + x0)**2
# This doesn't work.
print(tape.gradient(y, x0)) #dy/dx0 = 2*(x1 + x0)
None
同様に、tf.data.Dataset イテレータと tf.queue はステートフルであるため、それらを通過するテンソルのすべての勾配を停止します。
勾配が登録されていない
一部のtf.Operationは微分不可能として登録されているため、Noneを返します。その他は勾配の登録がされていません。
tf.raw_ops のページには、勾配を登録する低レベルの演算が示されています。
勾配が登録されていない浮動小数点演算を介して勾配を取得しようとすると、テープは暗黙的にNoneを返す代わりにエラーをスローします。これにより、何かが間違っていることが分かります。
たとえば、tf.image.adjust_contrast 関数は、raw_ops.AdjustContrastv2 をラップしており、勾配があっても、その勾配は実装されていません。
image = tf.Variable([[[0.5, 0.0, 0.0]]])
delta = tf.Variable(0.1)
with tf.GradientTape() as tape:
new_image = tf.image.adjust_contrast(image, delta)
try:
print(tape.gradient(new_image, [image, delta]))
assert False # This should not happen.
except LookupError as e:
print(f'{type(e).__name__}: {e}')
LookupError: gradient registry has no entry for: AdjustContrastv2
この演算で微分する必要がある場合は、勾配を実装して登録する(tf.RegisterGradient を使用)か、ほかの演算を使用して関数を再実装する必要があります。
None の代わりにゼロを取得する
場合によっては、接続されていない勾配でNoneではなく 0(ゼロ)を取得すると便利です。unconnected_gradients引数を使用すると、接続されていない勾配がある場合に何を返すかを決めることができます。
x = tf.Variable([2., 2.])
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y**2
print(tape.gradient(z, x, unconnected_gradients=tf.UnconnectedGradients.ZERO))
tf.Tensor([0. 0.], shape=(2,), dtype=float32)