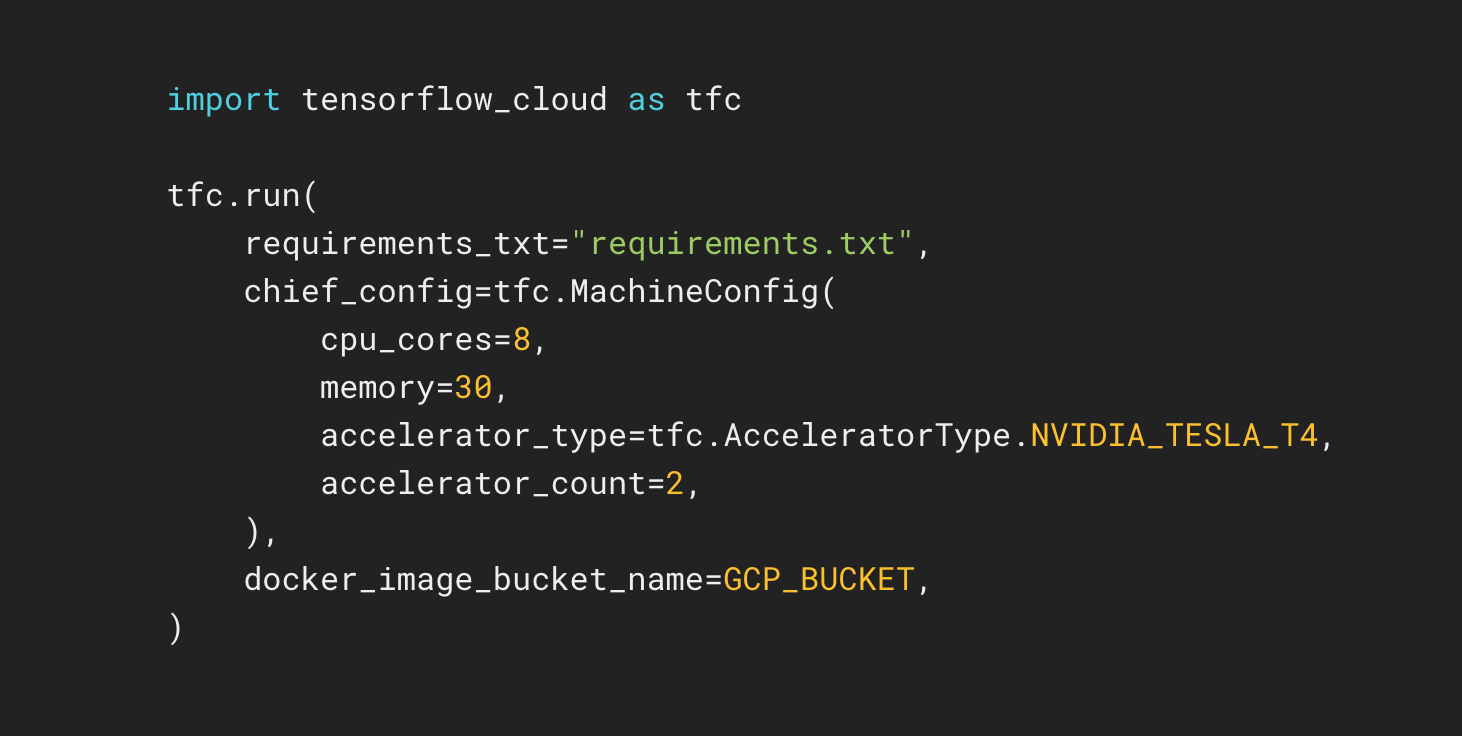
TensorFlow Cloud היא ספרייה לחיבור הסביבה המקומית שלך ל-Google Cloud.
import tensorflow_cloud as tfc TF_GPU_IMAGE = "tensorflow/tensorflow:latest-gpu" run_parameters = { distribution_strategy='auto', requirements_txt='requirements.txt', docker_config=tfc.DockerConfig( parent_image=TF_GPU_IMAGE, image_build_bucket=GCS_BUCKET ), chief_config=tfc.COMMON_MACHINE_CONFIGS['K80_1X'], worker_config=tfc.COMMON_MACHINE_CONFIGS['K80_1X'], worker_count=3, job_labels={'job': "my_job"} } tfc.run(**run_parameters) # Runs your training on Google Cloud!
מאגר הענן של TensorFlow מספק ממשקי API המקלים על המעבר מבניית מודל מקומי ואיתור באגים לאימון מבוזר וכוונון היפרפרמטרים ב-Google Cloud. מתוך Colab או Kaggle Notebook או קובץ סקריפט מקומי, אתה יכול לשלוח את הדגם שלך לכוונון או אימון ישירות בענן, ללא צורך להשתמש ב-Cloud Console.